Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pelajari cara membuat dan menyebarkan alur ETL (ekstraksi, transformasi, dan pemuatan) dengan change data capture (CDC) menggunakan Lakeflow Spark Declarative Pipelines (SDP) untuk orkestrasi data dan Auto Loader. Alur ETL menerapkan langkah-langkah untuk membaca data dari sistem sumber, mengubah data tersebut berdasarkan persyaratan, seperti pemeriksaan kualitas data dan merekam de-duplikasi, dan menulis data ke sistem target, seperti gudang data atau data lake.
Dalam tutorial ini, Anda akan menggunakan data dari customers tabel dalam database MySQL untuk:
- Ekstrak perubahan dari database transaksi menggunakan Debezium atau alat lain dan simpan ke penyimpanan objek cloud (S3, ADLS, atau GCS). Dalam tutorial ini, Anda melewati pengaturan sistem CDC eksternal dan sebaliknya menghasilkan data palsu untuk menyederhanakan tutorial.
- Gunakan Auto Loader untuk memuat pesan secara bertahap dari penyimpanan objek cloud, dan menyimpan pesan mentah dalam
customers_cdctabel. Auto Loader menyimpulkan skema dan menangani evolusi skema. -
customers_cdc_cleanBuat tabel untuk memeriksa kualitas data menggunakan ekspektasi. Misalnya,idseharusnya tidak bolehnullkarena digunakan untuk menjalankan operasi upsert. - Lakukan
AUTO CDC ... INTOpada data CDC yang dibersihkan untuk mengupsert perubahan ke dalam tabel akhircustomers. - Perlihatkan bagaimana alur dapat membuat tabel dimensi (SCD2) tipe 2 yang berubah perlahan untuk melacak semua perubahan.
Tujuannya adalah untuk menyerap data mentah hampir secara real time dan membangun tabel untuk tim analis Anda sambil memastikan kualitas data.
Tutorial ini menggunakan arsitektur medali Lakehouse, di mana ia menyerap data mentah melalui lapisan perunggu, membersihkan dan memvalidasi data dengan lapisan perak, dan menerapkan pemodelan dimensi dan agregasi menggunakan lapisan emas. Lihat Apa arsitektur medali lakehouse? untuk informasi selengkapnya.
Alur yang diimplementasikan terlihat seperti ini:
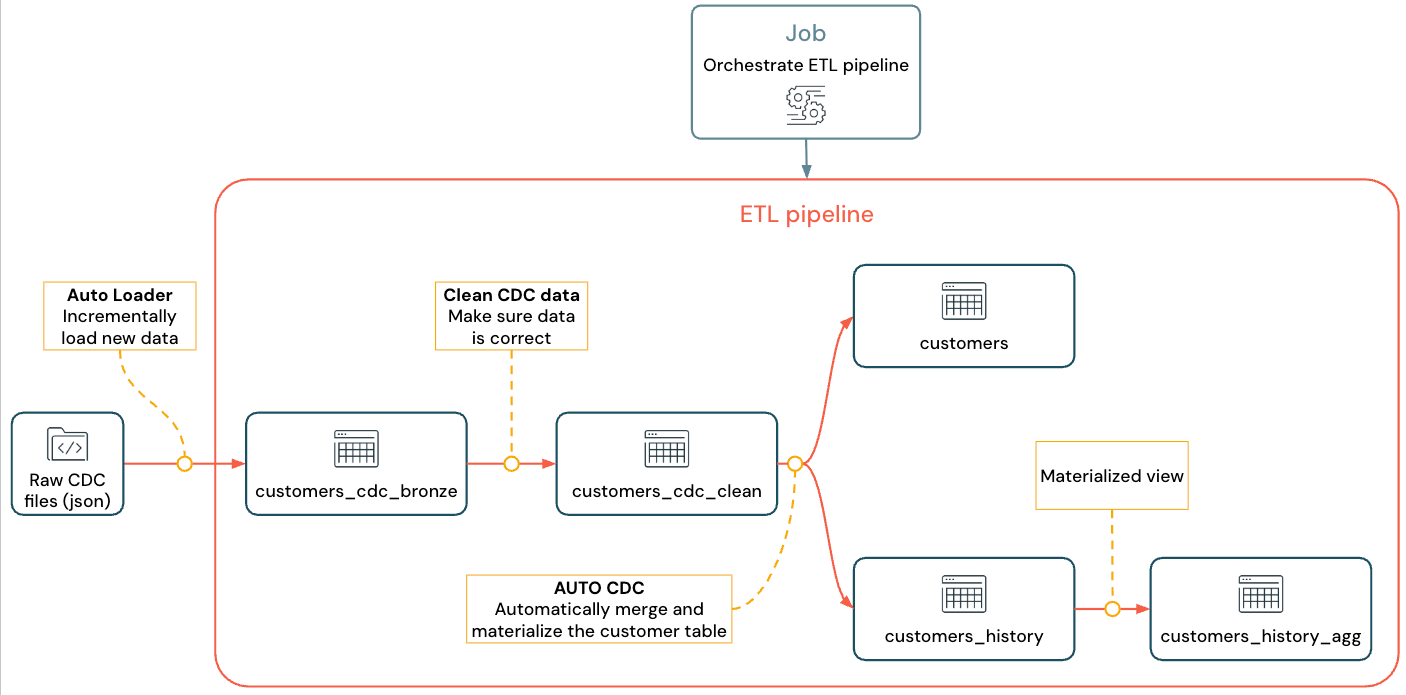
Untuk informasi selengkapnya tentang alur, Auto Loader, dan CDC lihat Alur Deklaratif Lakeflow Spark, Apa itu Auto Loader?, dan Mengubah tangkapan data dan rekam jepret
Persyaratan
Untuk menyelesaikan tutorial ini, Anda harus memenuhi persyaratan berikut:
- Masuk ke ruang kerja Azure Databricks.
- Mengaktifkan Unity Catalog untuk ruang kerja Anda.
- Memiliki komputasi tanpa server yang tersedia di ruang kerja Anda (diaktifkan secara default di ruang kerja dengan Katalog Unity). Alur Deklaratif Lakeflow Spark tanpa server tidak tersedia di semua wilayah ruang kerja. Lihat Fitur dengan ketersediaan regional terbatas untuk wilayah yang tersedia. Jika komputasi tanpa server tidak tersedia, langkah-langkahnya harus berfungsi dengan komputasi default untuk ruang kerja Anda.
- Memiliki izin untuk membuat sumber daya komputasi atau akses ke sumber daya komputasi.
- Memiliki izin untuk membuat skema baru dalam katalog. Izin yang diperlukan adalah
USE CATALOGdanCREATE SCHEMA. - Memiliki izin untuk membuat volume baru dalam skema yang ada. Izin yang diperlukan adalah
USE SCHEMAdanCREATE VOLUME.
Mengubah pengambilan data dalam alur ETL
Penangkapan perubahan data (CDC) adalah proses yang menangkap perubahan dalam catatan yang terjadi pada database transaksional (misalnya, MySQL atau PostgreSQL) atau gudang data. CDC menangkap operasi seperti penghapusan data, penambahan, dan pembaruan, biasanya sebagai aliran untuk membentuk kembali tabel di sistem eksternal. CDC memungkinkan pemuatan inkremental sambil menghilangkan kebutuhan akan pembaruan beban massal.
Nota
Untuk menyederhanakan tutorial ini, lewati pengaturan sistem CDC eksternal. Asumsikan ia menjalankan dan menyimpan data CDC sebagai file JSON di penyimpanan objek cloud (S3, ADLS, atau GCS). Tutorial ini menggunakan Faker pustaka untuk menghasilkan data yang digunakan dalam tutorial.
Menangkap CDC
Berbagai alat CDC tersedia. Salah satu solusi open source terkemuka adalah Debezium, tetapi implementasi lain yang menyederhanakan sumber data ada, seperti Fivetran, Qlik Replicate, StreamSets, Talend, Oracle GoldenGate, dan AWS DMS.
Dalam tutorial ini, Anda menggunakan data CDC dari sistem eksternal seperti Debezium atau DMS. Debezium menangkap setiap baris data yang diubah. Biasanya mengirimkan riwayat perubahan data ke topik Kafka atau menyimpannya sebagai file.
Anda harus memuat informasi CDC dari customers tabel (format JSON), memeriksa keakuratannya, lalu mematerialisasi tabel pelanggan di Lakehouse.
Input CDC dari Debezium
Untuk setiap perubahan, Anda menerima pesan JSON yang berisi semua bidang baris yang sedang diperbarui (id, , firstnamelastname, email, address). Pesan ini juga menyertakan metadata tambahan:
-
operation: Kode operasi, biasanya (DELETE,APPEND,UPDATE). -
operation_date: Tanggal dan cap waktu dari catatan untuk setiap aksi operasi.
Alat seperti Debezium dapat menghasilkan output yang lebih canggih, seperti nilai baris sebelum perubahan, tetapi tutorial ini menghilangkannya untuk kesederhanaan.
Langkah 1: Membuat alur
Buat alur ETL baru untuk mengkueri sumber data CDC Anda dan membuat tabel di ruang kerja Anda.
Di ruang kerja Anda, klik
 Baru di sudut kiri atas.
Baru di sudut kiri atas.Klik Pipeline ETL.
Ubah judul alur menjadi
Pipelines with CDC tutorialatau nama yang Anda inginkan.Di bawah judul, pilih katalog dan skema di mana Anda memiliki izin menulis.
Katalog dan skema ini digunakan secara default, jika Anda tidak menentukan katalog atau skema dalam kode Anda. Kode Anda dapat menulis ke katalog atau skema apa pun dengan menentukan jalur lengkap. Tutorial ini menggunakan default yang Anda tentukan di sini.
Dari Opsi tingkat lanjut, pilih Mulai dengan file kosong.
Pilih folder untuk kode Anda. Anda dapat memilih Telusuri untuk menelusuri daftar folder di ruang kerja. Anda dapat memilih folder apa pun yang memiliki izin tulis.
Untuk menggunakan kontrol versi, pilih folder Git. Jika Anda perlu membuat folder baru, pilih tombol
Pilih Python atau SQL untuk bahasa file Anda, berdasarkan bahasa yang ingin Anda gunakan untuk tutorial.
Klik Pilih untuk membuat alur dengan pengaturan ini dan buka Editor Alur Lakeflow.
Anda sekarang memiliki jalur tanpa isi dengan katalog dan skema default. Selanjutnya, siapkan data sampel untuk diimpor dalam tutorial.
Langkah 2: Buat data sampel untuk diimpor dalam tutorial ini
Langkah ini tidak diperlukan jika Anda mengimpor data Anda sendiri dari sumber yang ada. Untuk tutorial ini, hasilkan data palsu sebagai contoh untuk tutorial. Buat buku catatan untuk menjalankan skrip pembuatan data Python. Kode ini hanya perlu dijalankan sekali untuk menghasilkan data sampel, jadi buat dalam folder alur explorations , yang tidak dijalankan sebagai bagian dari pembaruan alur.
Nota
Kode ini menggunakan Faker untuk menghasilkan data CDC sampel. Faker tersedia untuk diinstal secara otomatis, sehingga tutorial menggunakan %pip install faker. Anda juga dapat mengatur ketergantungan pada faker untuk notebook. Lihat Menambahkan dependensi ke buku catatan.
Dari dalam Editor Alur Lakeflow, di bar samping browser aset di sebelah kiri editor, klik
Tambahkan, lalu pilih Eksplorasi.Beri Name, seperti
Setup data, pilih Python. Anda dapat meninggalkan folder tujuan default, yang merupakan folder baruexplorations.Klik Buat. Ini membuat buku catatan di folder baru.
Masukkan kode berikut di sel pertama. Anda harus mengubah definisi
<my_catalog>dan<my_schema>agar sesuai dengan katalog dan skema default yang Anda pilih di prosedur sebelumnya:%pip install faker # Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = dbName = db = "<my_schema>" spark.sql(f'USE CATALOG `{catalog}`') spark.sql(f'USE SCHEMA `{schema}`') spark.sql(f'CREATE VOLUME IF NOT EXISTS `{catalog}`.`{db}`.`raw_data`') volume_folder = f"/Volumes/{catalog}/{db}/raw_data" try: dbutils.fs.ls(volume_folder+"/customers") except: print(f"folder doesn't exist, generating the data under {volume_folder}...") from pyspark.sql import functions as F from faker import Faker from collections import OrderedDict import uuid fake = Faker() import random fake_firstname = F.udf(fake.first_name) fake_lastname = F.udf(fake.last_name) fake_email = F.udf(fake.ascii_company_email) fake_date = F.udf(lambda:fake.date_time_this_month().strftime("%m-%d-%Y %H:%M:%S")) fake_address = F.udf(fake.address) operations = OrderedDict([("APPEND", 0.5),("DELETE", 0.1),("UPDATE", 0.3),(None, 0.01)]) fake_operation = F.udf(lambda:fake.random_elements(elements=operations, length=1)[0]) fake_id = F.udf(lambda: str(uuid.uuid4()) if random.uniform(0, 1) < 0.98 else None) df = spark.range(0, 100000).repartition(100) df = df.withColumn("id", fake_id()) df = df.withColumn("firstname", fake_firstname()) df = df.withColumn("lastname", fake_lastname()) df = df.withColumn("email", fake_email()) df = df.withColumn("address", fake_address()) df = df.withColumn("operation", fake_operation()) df_customers = df.withColumn("operation_date", fake_date()) df_customers.repartition(100).write.format("json").mode("overwrite").save(volume_folder+"/customers")Untuk menghasilkan himpunan data yang digunakan dalam tutorial, ketik Shift + Enter untuk menjalankan kode:
Optional. Untuk mempratinjau data yang digunakan dalam tutorial ini, masukkan kode berikut di sel berikutnya dan jalankan kode. Perbarui katalog dan skema agar sesuai dengan jalur dari kode sebelumnya.
# Update these to match the catalog and schema # that you used for the pipeline in step 1. catalog = "<my_catalog>" schema = "<my_schema>" display(spark.read.json(f"/Volumes/{catalog}/{schema}/raw_data/customers"))
Ini menghasilkan himpunan data besar (dengan data CDC palsu) yang dapat Anda gunakan di sisa tutorial. Pada langkah berikutnya, serap data menggunakan Auto Loader.
Langkah 3: Menyerap data secara bertahap dengan Auto Loader
Langkah selanjutnya adalah menyerap data mentah dari penyimpanan cloud (palsu) ke dalam lapisan perunggu.
Ini bisa menjadi tantangan karena beberapa alasan, karena Anda harus:
- Beroperasi dalam skala besar, berpotensi menyerap jutaan file kecil.
- Menentukan skema dan jenis JSON.
- Tangani rekaman buruk dengan skema JSON yang tidak benar.
- Mengurus evolusi skema (misalnya, kolom baru di tabel pelanggan).
Auto Loader menyederhanakan penyerapan ini, termasuk inferensi skema dan evolusi skema, sambil menskalakan ke jutaan file masuk. Auto Loader tersedia di Python menggunakan cloudFiles dan di SQL menggunakan SELECT * FROM STREAM read_files(...) dan dapat digunakan dengan berbagai format (JSON, CSV, Apache Avro, dll.):
Menentukan tabel sebagai tabel streaming menjamin bahwa Anda hanya menggunakan data masuk baru. Jika Anda tidak mendefinisikannya sebagai tabel streaming, ia memindai dan menyerap semua data yang tersedia. Lihat Tabel streaming untuk informasi selengkapnya.
Untuk menyerap data CDC masuk menggunakan Auto Loader, salin dan tempel kode berikut ke dalam file kode yang dibuat dengan alur Anda (disebut
my_transformation.pyataumy_transformation.sql). Anda dapat menggunakan Python atau SQL, berdasarkan bahasa yang Anda pilih saat membuat alur. Pastikan untuk mengganti<catalog>dan<schema>dengan yang telah Anda tetapkan sebagai default untuk alur pekerjaan.Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # Replace with the catalog and schema name that # you are using: path = "/Volumes/<catalog>/<schema>/raw_data/customers" # Create the target bronze table dp.create_streaming_table("customers_cdc_bronze", comment="New customer data incrementally ingested from cloud object storage landing zone") # Create an Append Flow to ingest the raw data into the bronze table @dp.append_flow( target = "customers_cdc_bronze", name = "customers_bronze_ingest_flow" ) def customers_bronze_ingest_flow(): return ( spark.readStream .format("cloudFiles") .option("cloudFiles.format", "json") .option("cloudFiles.inferColumnTypes", "true") .load(f"{path}") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_bronze COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_bronze_ingest_flow AS INSERT INTO customers_cdc_bronze BY NAME SELECT * FROM STREAM read_files( -- replace with the catalog/schema you are using: "/Volumes/<catalog>/<schema>/raw_data/customers", format => "json", inferColumnTypes => "true" )Klik
 Jalankan file atau Jalankan alur untuk memulai pembaruan untuk alur yang tersambung. Dengan hanya satu file sumber dalam alur Anda, ini setara secara fungsional.
Jalankan file atau Jalankan alur untuk memulai pembaruan untuk alur yang tersambung. Dengan hanya satu file sumber dalam alur Anda, ini setara secara fungsional.
Setelah pembaruan selesai, editor diperbarui dengan informasi tentang pipa Anda.
- Grafik alur (DAG), di bar samping di sebelah kanan kode Anda, memperlihatkan satu tabel,
customers_cdc_bronze. - Ringkasan pembaruan ditampilkan di bagian atas penjelajah sumber daya jalur.
- Detail tabel yang dihasilkan diperlihatkan di panel bawah, dan Anda bisa menelusuri data dari tabel dengan memilihnya.
Ini adalah data lapisan perunggu mentah yang diimpor dari penyimpanan cloud. Pada langkah berikutnya, bersihkan data untuk membuat tabel lapisan perak.
Langkah 4: Pembersihan dan harapan untuk melacak kualitas data
Setelah lapisan perunggu ditentukan, buat lapisan perak dengan menambahkan harapan untuk mengontrol kualitas data. Periksa kondisi berikut:
- ID tidak boleh berupa
null. - Jenis operasi CDC harus valid.
- JSON harus dibaca dengan benar oleh Auto Loader.
Baris yang tidak memenuhi kondisi ini dihapus.
Lihat Mengelola kualitas data dengan ekspektasi alur untuk informasi selengkapnya.
Dari panel samping penjelajah aset pipeline, klik
Tambah, kemudian Transformasi.Masukkan Name (misalnya,
customers_silver) dan pilih bahasa (Python atau SQL) untuk file kode sumber. Ekstensi.pyatau.sqlditambahkan berdasarkan pilihan bahasa Anda. Anda dapat mencampur dan mencocokkan bahasa dalam alur, sehingga Anda dapat memilih salah satu untuk langkah ini.Untuk membuat lapisan perak dengan tabel yang dibersihkan dan memberlakukan batasan, salin dan tempel kode berikut ke dalam file baru (pilih Python atau SQL berdasarkan bahasa file).
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table( name = "customers_cdc_clean", expect_all_or_drop = {"no_rescued_data": "_rescued_data IS NULL","valid_id": "id IS NOT NULL","valid_operation": "operation IN ('APPEND', 'DELETE', 'UPDATE')"} ) @dp.append_flow( target = "customers_cdc_clean", name = "customers_cdc_clean_flow" ) def customers_cdc_clean_flow(): return ( spark.readStream.table("customers_cdc_bronze") .select("address", "email", "id", "firstname", "lastname", "operation", "operation_date", "_rescued_data") )SQL
CREATE OR REFRESH STREAMING TABLE customers_cdc_clean ( CONSTRAINT no_rescued_data EXPECT (_rescued_data IS NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_id EXPECT (id IS NOT NULL) ON VIOLATION DROP ROW, CONSTRAINT valid_operation EXPECT (operation IN ('APPEND', 'DELETE', 'UPDATE')) ON VIOLATION DROP ROW ) COMMENT "New customer data incrementally ingested from cloud object storage landing zone"; CREATE FLOW customers_cdc_clean_flow AS INSERT INTO customers_cdc_clean BY NAME SELECT * FROM STREAM customers_cdc_bronze;Klik
Jalankan file atau Jalankan alur untuk memulai pembaruan untuk alur yang tersambung.Karena sekarang ada dua file sumber, ini tidak melakukan hal yang sama, tetapi dalam hal ini, outputnya sama.
- Jalankan alur menjalankan seluruh alur Anda, termasuk kode dari langkah 3. Jika data input Anda sedang diperbarui, ini dapat menarik perubahan apa pun dari sumber tersebut ke lapisan perunggu Anda. Ini tidak menjalankan kode dari langkah penyiapan data, karena itu ada di folder eksplorasi, dan bukan bagian dari sumber untuk alur Anda.
- Jalankan file hanya menjalankan file sumber saat ini. Dalam hal ini, tanpa data input Anda diperbarui, ini menghasilkan data perak dari tabel perunggu yang di-cache. Akan berguna untuk menjalankan hanya file ini untuk iterasi yang lebih cepat saat membuat atau mengedit kode alur Anda.
Ketika pembaruan selesai, Anda dapat melihat bahwa grafik alur sekarang menunjukkan dua tabel (dengan lapisan perak tergantung pada lapisan perunggu), dan panel bawah menunjukkan detail untuk kedua tabel. Bagian atas penjelajah aset alur kerja sekarang menunjukkan waktu eksekusi untuk beberapa kali pengulangan, tetapi hanya menampilkan detail untuk eksekusi terbaru.
Selanjutnya, buat versi akhir dari lapisan emas tabel customers Anda.
Langkah 5: Mematerialisasi tabel pelanggan dengan alur CDC otomatis
Hingga saat ini, tabel hanya meneruskan data CDC di setiap langkah. Sekarang, buat tabel customers yang berisi tampilan paling mutakhir dan menjadi replika tabel asli, bukan daftar operasi CDC yang digunakan untuk membuatnya.
Ini tidak mudah untuk diterapkan secara manual. Anda harus mempertimbangkan hal-hal seperti deduplikasi data untuk menyimpan data terbaru.
Namun, Lakeflow Spark Declarative Pipelines memecahkan tantangan ini dengan operasi AUTO CDC.
Dari bilah sisi penjelajah aset pipeline, klik
Tambahkan dan Transformasi.Masukkan Name dan pilih bahasa (Python atau SQL) untuk file kode sumber baru. Anda dapat kembali memilih salah satu bahasa untuk langkah ini, tetapi menggunakan kode yang benar, di bawah ini.
Untuk memproses data CDC menggunakan
AUTO CDCdi Lakeflow Spark Declarative Pipelines, salin dan tempel kode berikut ke dalam file baru.Python
from pyspark import pipelines as dp from pyspark.sql.functions import * dp.create_streaming_table(name="customers", comment="Clean, materialized customers") dp.create_auto_cdc_flow( target="customers", # The customer table being materialized source="customers_cdc_clean", # the incoming CDC keys=["id"], # what we'll be using to match the rows to upsert sequence_by=col("operation_date"), # de-duplicate by operation date, getting the most recent value ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), # DELETE condition except_column_list=["operation", "operation_date", "_rescued_data"], )SQL
CREATE OR REFRESH STREAMING TABLE customers; CREATE FLOW customers_cdc_flow AS AUTO CDC INTO customers FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 1;Klik
Jalankan file untuk memulai pembaruan untuk alur yang tersambung.
Ketika pembaruan selesai, Anda dapat melihat bahwa grafik alur Anda menunjukkan 3 tabel, berkembang dari perunggu ke perak ke emas.
Langkah 6: Lacak riwayat pembaruan dengan dimensi tipe 2 (SCD2) yang berubah perlahan
Sering kali diperlukan untuk membuat tabel yang melacak semua perubahan yang dihasilkan dari APPEND, , UPDATEdan DELETE:
- Riwayat: Anda ingin menyimpan riwayat semua perubahan pada tabel Anda.
- Keterlacakan: Anda ingin melihat operasi mana yang terjadi.
SCD2 dengan Lakeflow SDP
Delta mendukung perubahan aliran data (CDF), dan table_change dapat meminta modifikasi tabel di SQL dan Python. Namun, kasus penggunaan utama CDF adalah menangkap perubahan dalam alur, bukan untuk membuat tampilan penuh perubahan tabel dari awal.
Hal-hal menjadi sangat kompleks untuk diterapkan jika Anda memiliki peristiwa yang tidak berurutan. Jika Anda harus mengurutkan perubahan dengan tanda waktu dan menerima modifikasi yang terjadi di masa lalu, Anda harus menambahkan entri baru dalam tabel SCD Anda dan memperbarui entri sebelumnya.
Lakeflow SDP menghilangkan kompleksitas ini. Anda dapat membuat tabel terpisah yang berisi semua modifikasi dari awal waktu, yang dikelola Lakeflow SDP secara otomatis. Tabel ini mendukung pengoptimalan tata letak data seperti pengklusteran cairan dan menangani rekaman yang tidak berurutan secara otomatis berdasarkan _sequence_by. Lihat Menggunakan pengklusteran cair untuk tabel.
Untuk membuat tabel SCD2, gunakan opsi STORED AS SCD TYPE 2 di SQL atau stored_as_scd_type="2" di Python.
Nota
Anda juga dapat membatasi kolom mana yang dilacak fitur menggunakan opsi : TRACK HISTORY ON {columnList | EXCEPT(exceptColumnList)}
Dari bilah sisi penjelajah aset pipeline, klik
Tambahkan dan Transformasi.Masukkan Name dan pilih bahasa (Python atau SQL) untuk file kode sumber baru.
Salin dan tempel kode berikut ke dalam file baru.
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * # create the table dp.create_streaming_table( name="customers_history", comment="Slowly Changing Dimension Type 2 for customers" ) # store all changes as SCD2 dp.create_auto_cdc_flow( target="customers_history", source="customers_cdc_clean", keys=["id"], sequence_by=col("operation_date"), ignore_null_updates=False, apply_as_deletes=expr("operation = 'DELETE'"), except_column_list=["operation", "operation_date", "_rescued_data"], stored_as_scd_type="2", ) # Enable SCD2 and store individual updatesSQL
CREATE OR REFRESH STREAMING TABLE customers_history; CREATE FLOW customers_history_cdc AS AUTO CDC INTO customers_history FROM stream(customers_cdc_clean) KEYS (id) APPLY AS DELETE WHEN operation = "DELETE" SEQUENCE BY operation_date COLUMNS * EXCEPT (operation, operation_date, _rescued_data) STORED AS SCD TYPE 2;Klik
Jalankan file untuk memulai pembaruan untuk alur yang tersambung.
Ketika pembaruan selesai, grafik alur menyertakan tabel baru customers_history, yang juga bergantung pada tabel lapisan perak, dan panel bawah menunjukkan detail untuk semua 4 tabel.
Langkah 7: Buat tampilan materialisasi yang melacak siapa yang paling sering mengubah informasi mereka.
Tabel customers_history berisi semua perubahan historis yang telah dilakukan pengguna pada informasi mereka. Buat tampilan materialisasi sederhana di lapisan emas yang melacak siapa yang paling banyak mengubah informasi mereka. Ini dapat digunakan untuk analisis deteksi penipuan atau rekomendasi pengguna dalam skenario dunia nyata. Selain itu, menerapkan perubahan dengan SCD2 telah menghapus duplikat, sehingga Anda dapat langsung menghitung baris per ID pengguna.
Dari bilah sisi penjelajah aset pipeline, klik
Tambahkan dan Transformasi.Masukkan Name dan pilih bahasa (Python atau SQL) untuk file kode sumber baru.
Salin dan tempel kode berikut ke dalam file sumber baru.
Python
from pyspark import pipelines as dp from pyspark.sql.functions import * @dp.table( name = "customers_history_agg", comment = "Aggregated customer history" ) def customers_history_agg(): return ( spark.read.table("customers_history") .groupBy("id") .agg( count("address").alias("address_count"), count("email").alias("email_count"), count("firstname").alias("firstname_count"), count("lastname").alias("lastname_count") ) )SQL
CREATE OR REPLACE MATERIALIZED VIEW customers_history_agg AS SELECT id, count("address") as address_count, count("email") AS email_count, count("firstname") AS firstname_count, count("lastname") AS lastname_count FROM customers_history GROUP BY idKlik
Jalankan file untuk memulai pembaruan untuk alur yang tersambung.
Setelah pembaruan selesai, ada tabel baru dalam grafik alur yang bergantung pada customers_history tabel, dan Anda dapat melihatnya di panel bawah. Pipeline Anda sekarang telah selesai. Anda dapat mengujinya dengan melakukan Jalankan pipeline penuh. Satu-satunya langkah yang tersisa adalah menjadwalkan alur untuk diperbarui secara teratur.
Langkah 8: Buat pekerjaan untuk menjalankan alur ETL
Selanjutnya, buat alur kerja untuk mengotomatiskan langkah-langkah penyerapan, pemrosesan, dan analisis data di alur Anda menggunakan pekerjaan Databricks.
- Di bagian atas editor, pilih tombol Jadwalkan .
- Jika dialog Jadwal muncul, pilih Tambahkan jadwal.
- Ini membuka dialog Jadwal baru , di mana Anda dapat membuat pekerjaan untuk menjalankan alur Anda sesuai jadwal.
- Secara opsional, beri nama pekerjaan.
- Secara default, jadwal diatur untuk berjalan sekali per hari. Anda dapat menerima default ini, atau mengatur jadwal Anda sendiri. Memilih Tingkat Lanjut memberi Anda opsi untuk mengatur waktu tertentu yang akan dijalankan pekerjaan. Memilih Opsi lainnya memungkinkan Anda membuat pemberitahuan saat pekerjaan berjalan.
- Pilih Buat untuk menerapkan perubahan dan membuat pekerjaan.
Sekarang pekerjaan akan berjalan setiap hari untuk menjaga alur Anda tetap terbarui. Anda dapat memilih Jadwalkan lagi untuk melihat daftar jadwal. Anda dapat mengelola jadwal untuk alur Anda dari dialog tersebut, termasuk menambahkan, mengedit, atau menghapus jadwal.
Mengklik nama jadwal (atau pekerjaan) akan membawa Anda ke halaman pekerjaan di daftar Pekerjaan & alur . Dari sana Anda dapat melihat detail tentang eksekusi pekerjaan, termasuk riwayat eksekusi, atau segera menjalankan pekerjaan dengan tombol Jalankan sekarang .
Lihat Pemantauan dan observabilitas untuk Pekerjaan Lakeflow untuk informasi selengkapnya tentang pelaksanaan pekerjaan.