Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menjelaskan dua pola umum untuk memindahkan artefak ML melalui penahapan dan ke dalam produksi. Sifat perubahan asinkron pada model dan kode berarti bahwa ada beberapa kemungkinan pola yang mungkin diikuti oleh proses pengembangan ML.
Model dibuat oleh kode, tetapi artefak model yang dihasilkan dan kode yang membuatnya dapat beroperasi secara asinkron. Artinya, versi model baru dan perubahan kode mungkin tidak terjadi pada saat yang sama. Misalnya, pertimbangkan skenario berikut:
- Untuk mendeteksi transaksi penipuan, Anda mengembangkan alur ML yang melatih kembali model mingguan. Kode mungkin tidak terlalu sering berubah, tetapi model mungkin dilatih kembali setiap minggu untuk menggabungkan data baru.
- Anda dapat membuat jaringan neural yang besar dan dalam untuk mengklasifikasikan dokumen. Dalam hal ini, melatih model secara komputasi mahal dan memakan waktu, dan melatih kembali model cenderung jarang terjadi. Namun, kode yang menyebarkan, melayani, dan memantau model ini dapat diperbarui tanpa melatih kembali model.
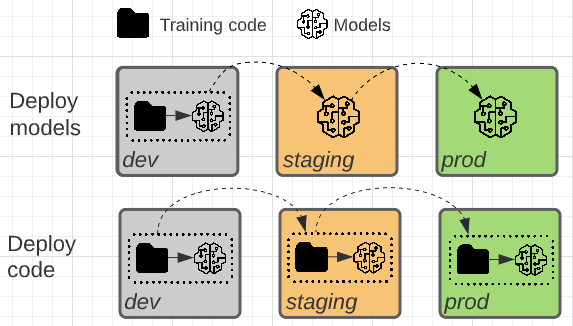
Dua pola berbeda dalam apakah artefak model atau kode pelatihan yang menghasilkan artefak model dipromosikan ke arah produksi.
Menyebarkan kode (disarankan)
Dalam kebanyakan situasi, Databricks merekomendasikan pendekatan "sebarkan kode". Pendekatan ini dimasukkan ke dalam alur kerja MLOps yang direkomendasikan.
Dalam pola ini, kode untuk melatih model dikembangkan di lingkungan pengembangan. Kode yang sama berpindah ke penahapan lalu produksi. Model ini dilatih di setiap lingkungan: awalnya di lingkungan pengembangan sebagai bagian dari pengembangan model, dalam penahapan (pada subset data terbatas) sebagai bagian dari pengujian integrasi, dan di lingkungan produksi (pada data produksi lengkap) untuk menghasilkan model akhir.
Keuntungan:
- Dalam organisasi where akses ke data produksi dibatasi, pola ini memungkinkan model dilatih pada data produksi di lingkungan produksi.
- Pelatihan ulang model otomatis lebih aman, karena kode pelatihan ditinjau, diuji, dan disetujui untuk produksi.
- Kode pendukung mengikuti pola yang sama dengan kode pelatihan model. Keduanya melalui pengujian integrasi dalam penahapan.
Kekurangan:
- Kurva pembelajaran bagi ilmuwan data untuk menyerahkan kode kepada kolaborator bisa curam. Templat dan alur kerja proyek yang telah ditentukan sebelumnya sangat membantu.
Juga dalam pola ini, ilmuwan data harus dapat meninjau hasil pelatihan dari lingkungan produksi, karena mereka memiliki pengetahuan untuk mengidentifikasi dan memperbaiki masalah khusus ML.
Jika situasi Anda mengharuskan model dilatih dalam penahapan melalui himpunan data produksi penuh, Anda dapat menggunakan pendekatan hibrid dengan menyebarkan kode ke penahapan, melatih model, lalu menyebarkan model ke produksi. Pendekatan ini menghemat biaya pelatihan dalam produksi tetapi menambahkan biaya operasi tambahan dalam penahapan.
Terapkan model
Dalam pola ini, artefak model dihasilkan oleh kode pelatihan di lingkungan pengembangan. Artefak kemudian diuji di lingkungan penahapan sebelum disebarkan ke dalam produksi.
Pertimbangkan opsi ini saat satu atau beberapa hal berikut ini berlaku:
- Pelatihan model sangat mahal atau sulit untuk diproduksi ulang.
- Semua pekerjaan dilakukan dalam satu ruang kerja Azure Databricks.
- Anda tidak bekerja dengan repositori eksternal atau proses CI/CD.
Keuntungan:
- Handoff yang lebih sederhana untuk ilmuwan data
- Jika pelatihan model where mahal, Anda hanya perlu melatih model sekali saja.
Kekurangan:
- Jika data produksi tidak dapat diakses dari lingkungan pengembangan (yang mungkin benar karena alasan keamanan), arsitektur ini mungkin tidak layak.
- Pelatihan ulang model otomatis sulit dalam pola ini. Anda dapat mengotomatiskan pelatihan ulang di lingkungan pengembangan, tetapi tim yang bertanggung jawab untuk menyebarkan model dalam produksi mungkin tidak menerima model yang dihasilkan sebagai siap produksi.
- Kode pendukung, seperti alur yang digunakan untuk rekayasa fitur, inferensi, dan pemantauan, perlu disebarkan ke produksi secara terpisah.
Biasanya suatu lingkungan (pengembangan, uji coba, atau produksi) sesuai dengan catalog di Unity Catalog. Untuk detail tentang cara menerapkan pola ini, lihat panduan peningkatan.
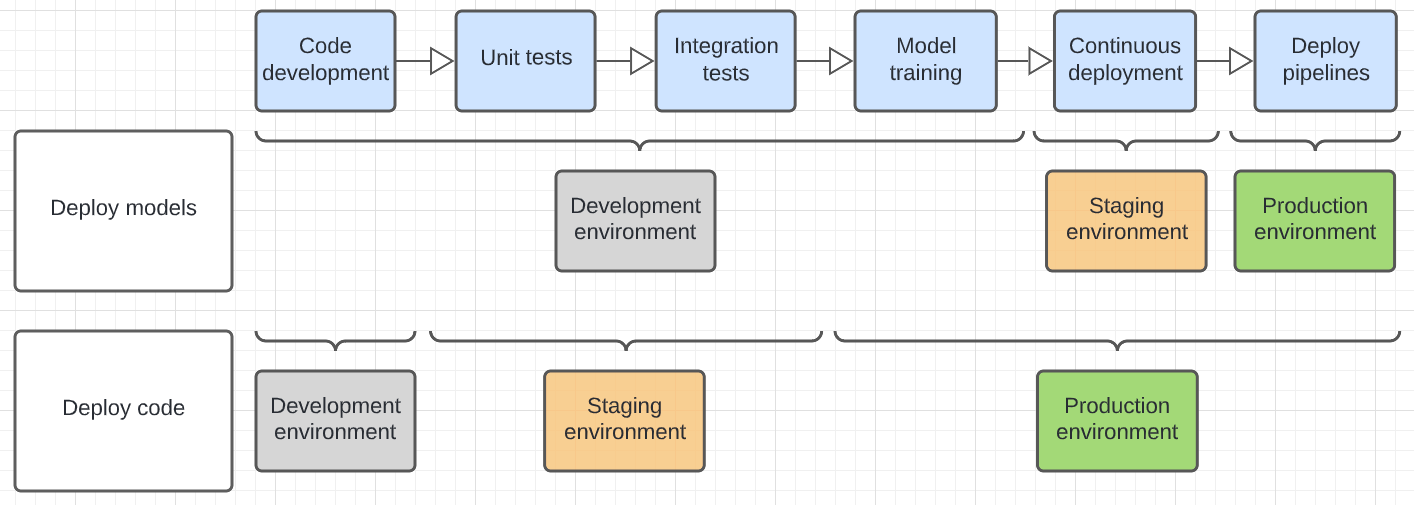
Diagram di bawah ini membedakan siklus hidup kode untuk pola penyebaran di atas di berbagai lingkungan eksekusi.
Lingkungan yang ditunjukkan dalam diagram adalah lingkungan akhir tempat langkah dijalankan. Misalnya, dalam pola model penyebaran, unit akhir dan pengujian integrasi dilakukan di lingkungan pengembangan. Dalam pola kode penyebaran, pengujian unit dan pengujian integrasi dijalankan di lingkungan pengembangan, dan pengujian unit akhir dan integrasi dilakukan di lingkungan penahapan.