Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menjelaskan bagaimana Anda dapat menggunakan MLOps pada platform Databricks untuk mengoptimalkan performa dan efisiensi jangka panjang sistem pembelajaran mesin (ML) Anda. Ini termasuk rekomendasi umum untuk arsitektur MLOps dan menjelaskan alur kerja umum menggunakan platform Databricks yang dapat Anda gunakan sebagai model untuk proses pengembangan-ke-produksi ML Anda. Untuk modifikasi alur kerja ini untuk aplikasi LLMOps, lihat alur kerja LLMOps.
Untuk detail selengkapnya, lihat Buku Besar MLOps.
Apa itu MLOps?
MLOps adalah serangkaian proses dan langkah otomatis untuk mengelola kode, data, dan model untuk meningkatkan performa, stabilitas, dan efisiensi jangka panjang sistem ML. Ini menggabungkan DevOps, DataOps, dan ModelOps.
Aset ML seperti kode, data, dan model dikembangkan secara bertahap yang maju dari tahap pengembangan awal yang tidak memiliki batasan akses yang ketat dan tidak diuji secara ketat, melalui tahap pengujian menengah, hingga tahap produksi akhir yang dikontrol dengan ketat. Platform Databricks memungkinkan Anda mengelola aset ini pada satu platform dengan kontrol akses terpadu. Anda dapat mengembangkan aplikasi data dan aplikasi ML pada platform yang sama, mengurangi risiko dan penundaan yang terkait dengan pemindahan data.
Rekomendasi umum untuk MLOps
Bagian ini mencakup beberapa rekomendasi umum untuk MLOps di Databricks dengan tautan untuk informasi selengkapnya.
Membuat lingkungan terpisah untuk setiap tahap
Lingkungan eksekusi adalah tempat di mana model dan data dibuat atau digunakan oleh kode. Setiap lingkungan eksekusi terdiri dari instance komputasi, runtime dan pustakanya, serta pekerjaan otomatis.
Databricks merekomendasikan pembuatan lingkungan terpisah untuk berbagai tahap kode ML dan pengembangan model dengan transisi yang ditentukan dengan jelas antar tahap. Alur kerja yang dijelaskan dalam artikel ini mengikuti proses ini, menggunakan nama umum untuk tahapan:
Konfigurasi lain juga dapat digunakan untuk memenuhi kebutuhan spesifik organisasi Anda.
Kontrol akses dan penerapan versi
Kontrol akses dan penerapan versi adalah komponen utama dari setiap proses operasi perangkat lunak. Databricks merekomendasikan hal berikut:
- Gunakan Git untuk kontrol versi. Alur dan kode harus disimpan di Git untuk kontrol versi. Memindahkan logika ML antar tahap kemudian dapat ditafsirkan sebagai kode pemindahan dari cabang pengembangan, ke cabang penahapan, ke cabang rilis. Gunakan folder Databricks Git untuk berintegrasi dengan penyedia Git Anda dan menyinkronkan buku catatan dan kode sumber dengan ruang kerja Databricks. Databricks juga menyediakan alat tambahan untuk integrasi Git dan kontrol versi; lihat Alat pengembangan lokal.
- Simpan data dalam arsitektur lakehouse menggunakan tabel Delta. Data harus disimpan dalam arsitektur lakehouse di akun cloud Anda. Data mentah dan tabel fitur harus disimpan sebagai tabel Delta dengan kontrol akses untuk menentukan siapa yang dapat membaca dan memodifikasinya.
- Mengelola pengembangan model dengan MLflow. Anda dapat menggunakan MLflow untuk melacak proses pengembangan model dan menyimpan rekam jepret kode, parameter model, metrik, dan metadata lainnya.
- Gunakan Model di Unity Catalog untuk mengelola siklus hidup model. Gunakan Model di Unity Catalog untuk mengelola penerapan versi model, tata kelola, dan status penyebaran.
Menyebarkan kode, bukan model
Dalam kebanyakan situasi, Databricks merekomendasikan bahwa selama proses pengembangan ML, Anda mempromosikan kode, daripada model, dari satu lingkungan ke lingkungan berikutnya. Memindahkan aset proyek dengan cara ini memastikan bahwa semua kode dalam proses pengembangan ML melalui proses peninjauan kode dan pengujian integrasi yang sama. Ini juga memastikan bahwa versi produksi model dilatih pada kode produksi. Untuk pembahasan lebih rinci tentang opsi dan kompromi, lihat Pola penyebaran model.
Alur kerja MLOps yang direkomendasikan
Bagian berikut menjelaskan alur kerja MLOps yang khas, mencakup masing-masing dari tiga tahap: pengembangan, penahapan, dan produksi.
Bagian ini menggunakan istilah "ilmuwan data" dan "insinyur ML" sebagai persona arketipal; peran dan tanggung jawab tertentu dalam alur kerja MLOps akan bervariasi antara tim dan organisasi.
Tahap pengembangan
Fokus tahap pengembangan adalah eksperimen. Ilmuwan data mengembangkan fitur dan model dan menjalankan eksperimen untuk mengoptimalkan performa model. Output dari proses pengembangan adalah kode alur ML yang dapat mencakup komputasi fitur, pelatihan model, inferensi, dan pemantauan.
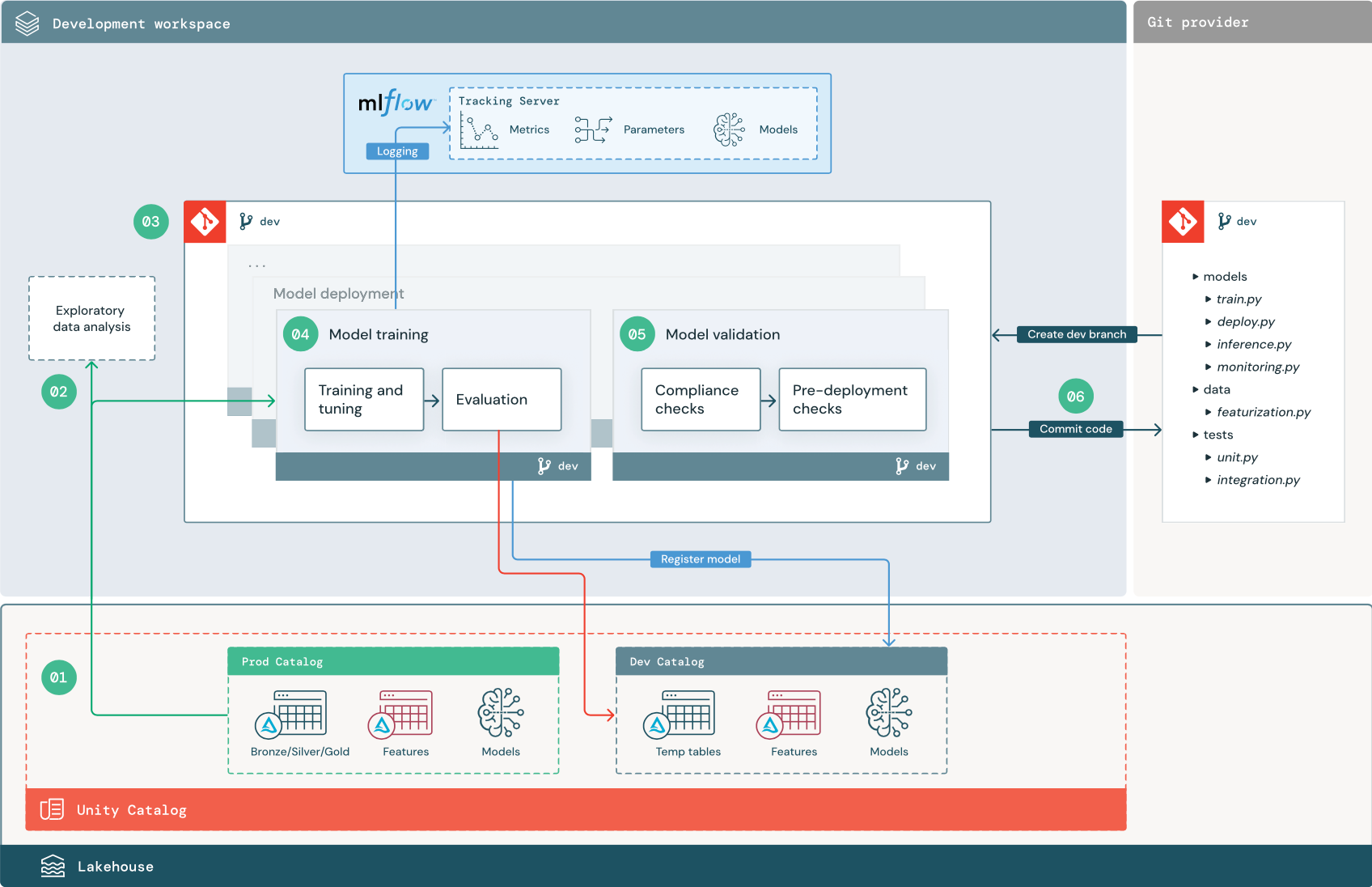
Langkah-langkah bernomor sesuai dengan angka yang diperlihatkan dalam diagram.
1. Sumber data
Lingkungan pengembangan diwakili oleh katalog dev di Unity Catalog. Ilmuwan data memiliki akses baca-tulis ke katalog dev saat mereka membuat data sementara dan tabel fitur di ruang kerja pengembangan. Model yang dibuat dalam tahap pengembangan didaftarkan ke katalog dev.
Idealnya, ilmuwan data yang bekerja di ruang kerja pengembangan juga memiliki akses baca-saja ke data produksi di katalog prod. Memungkinkan ilmuwan data membaca akses ke data produksi, tabel inferensi, dan tabel metrik dalam katalog prod memungkinkan mereka menganalisis prediksi dan performa model produksi saat ini. Ilmuwan data juga harus dapat memuat model produksi untuk eksperimen dan analisis.
Jika tidak memungkinkan untuk memberikan akses baca-saja ke katalog prod, rekam jepret data produksi dapat ditulis ke katalog dev untuk memungkinkan ilmuwan data mengembangkan dan mengevaluasi kode proyek.
2. Analisis data eksploratif (EDA)
Ilmuwan data menjelajahi dan menganalisis data dalam proses interaktif berulang menggunakan notebook. Tujuannya adalah untuk menilai apakah data yang tersedia memiliki potensi untuk menyelesaikan masalah bisnis. Dalam langkah ini, ilmuwan data mulai mengidentifikasi langkah-langkah persiapan dan fiturisasi data untuk pelatihan model. Proses ad hoc ini umumnya bukan bagian dari alur yang akan disebarkan di lingkungan eksekusi lainnya.
AutoML mempercepat proses ini dengan menghasilkan model garis besar untuk himpunan data. AutoML melakukan dan merekam serangkaian uji coba dan menyediakan buku catatan Python dengan kode sumber untuk setiap percobaan yang dijalankan, sehingga Anda dapat meninjau, mereproduksi, dan memodifikasi kode. AutoML juga menghitung statistik ringkasan pada himpunan data Anda dan menyimpan informasi ini dalam buku catatan yang bisa Anda tinjau.
3. Kode
Repositori kode berisi semua alur, modul, dan file proyek lainnya untuk proyek ML. Ilmuwan data membuat alur baru atau yang diperbarui dalam cabang pengembangan ("dev") dari repositori proyek. Mulai dari EDA dan fase awal proyek, ilmuwan data harus bekerja di repositori untuk berbagi kode dan melacak perubahan.
4. Melatih model (pengembangan)
Ilmuwan data mengembangkan alur pelatihan model di lingkungan pengembangan menggunakan tabel dari katalog dev atau prod.
Alur ini mencakup 2 tugas:
Pelatihan dan penyetelan. Proses pelatihan mencatat parameter model, metrik, dan artefak ke server Pelacakan MLflow. Setelah pelatihan dan penyetelan hiperparameter, artefak model akhir dicatat ke server pelacakan untuk merekam tautan antara model, data input yang dilatihnya, dan kode yang digunakan untuk menghasilkannya.
Evaluasi. Evaluasi kualitas model dengan menguji data yang disimpan. Hasil pengujian ini dicatat ke server Pelacakan MLflow. Tujuan evaluasi adalah untuk menentukan apakah model yang baru dikembangkan berkinerja lebih baik daripada model produksi saat ini. Dengan izin yang memadai, model produksi apa pun yang terdaftar ke katalog prod dapat dimuat ke ruang kerja pengembangan dan dibandingkan dengan model yang baru dilatih.
Jika persyaratan tata kelola organisasi Anda menyertakan informasi tambahan tentang model, Anda dapat menyimpannya menggunakan pelacakan MLflow. Artefak umum adalah deskripsi teks biasa dan interpretasi model seperti plot yang diproduksi oleh SHAP. Persyaratan tata kelola tertentu mungkin berasal dari petugas tata kelola data atau pemangku kepentingan bisnis.
Output alur pelatihan model adalah artefak model ML yang disimpan di server Pelacakan MLflow untuk lingkungan pengembangan. Jika alur dijalankan di ruang kerja penahapan atau produksi, artefak model disimpan di server Pelacakan MLflow untuk ruang kerja tersebut.
Ketika pelatihan model selesai, daftarkan model ke Unity Catalog. Siapkan kode alur Anda untuk mendaftarkan model ke katalog yang sesuai dengan lingkungan tempat alur model dijalankan; dalam contoh ini, katalog dev.
Dengan arsitektur yang direkomendasikan, Anda menyebarkan alur kerja Databricks multitugas di mana tugas pertama adalah alur pelatihan model, diikuti oleh tugas validasi model dan penyebaran model. Tugas pelatihan model menghasilkan URI model yang dapat digunakan tugas validasi model. Anda dapat menggunakan nilai tugas untuk meneruskan URI ini ke model.
5. Memvalidasi dan menyebarkan model (pengembangan)
Selain alur pelatihan model, alur lain seperti validasi model dan alur penyebaran model dikembangkan di lingkungan pengembangan.
Validasi model. Alur validasi model mengambil URI model dari alur pelatihan model, memuat model dari Unity Catalog, dan menjalankan pemeriksaan validasi.
Pemeriksaan validasi bergantung pada konteksnya. Mereka dapat mencakup pemeriksaan mendasar seperti mengonfirmasi format dan metadata yang diperlukan, dan pemeriksaan yang lebih kompleks yang mungkin diperlukan untuk industri yang sangat diatur, seperti pemeriksaan kepatuhan yang telah ditentukan sebelumnya dan mengonfirmasi performa model pada potongan data yang dipilih.
Fungsi utama alur validasi model adalah menentukan apakah model harus melanjutkan ke langkah penyebaran. Jika model melewati pemeriksaan pra-penyebaran, model dapat ditetapkan alias "Challenger" di Unity Catalog. Jika pemeriksaan gagal, proses berakhir. Anda dapat mengonfigurasi alur kerja untuk memberi tahu pengguna tentang kegagalan validasi. Lihat Tambahkan pemberitahuan pada pekerjaan.
Penyebaran model. Alur penyebaran model biasanya secara langsung mempromosikan model "Challenger" yang baru dilatih ke status "Champion" menggunakan pembaruan alias, atau memfasilitasi perbandingan antara model "Champion" yang ada dan model "Challenger" baru. Alur ini juga dapat menyiapkan infrastruktur inferensi yang diperlukan, seperti endpoint Model Serving. Untuk diskusi terperinci tentang langkah-langkah yang terlibat dalam alur penyebaran model, lihat Produksi.
6. Menerapkan kode
Setelah mengembangkan kode untuk pelatihan, validasi, penyebaran, dan alur lainnya, ilmuwan data atau insinyur ML melakukan perubahan cabang dev menjadi kontrol sumber.
Tahap pengujian
Fokus dari tahap ini adalah menguji kode alur ML untuk memastikannya siap untuk produksi. Semua kode alur ML diuji dalam tahap ini, termasuk kode untuk pelatihan model serta alur rekayasa fitur, kode inferensi, dan sebagainya.
Teknisi ML membuat alur CI untuk mengimplementasikan unit dan pengujian integrasi yang dijalankan dalam tahap ini. Output dari proses penahapan adalah cabang rilis yang memicu sistem CI/CD untuk memulai tahap produksi.
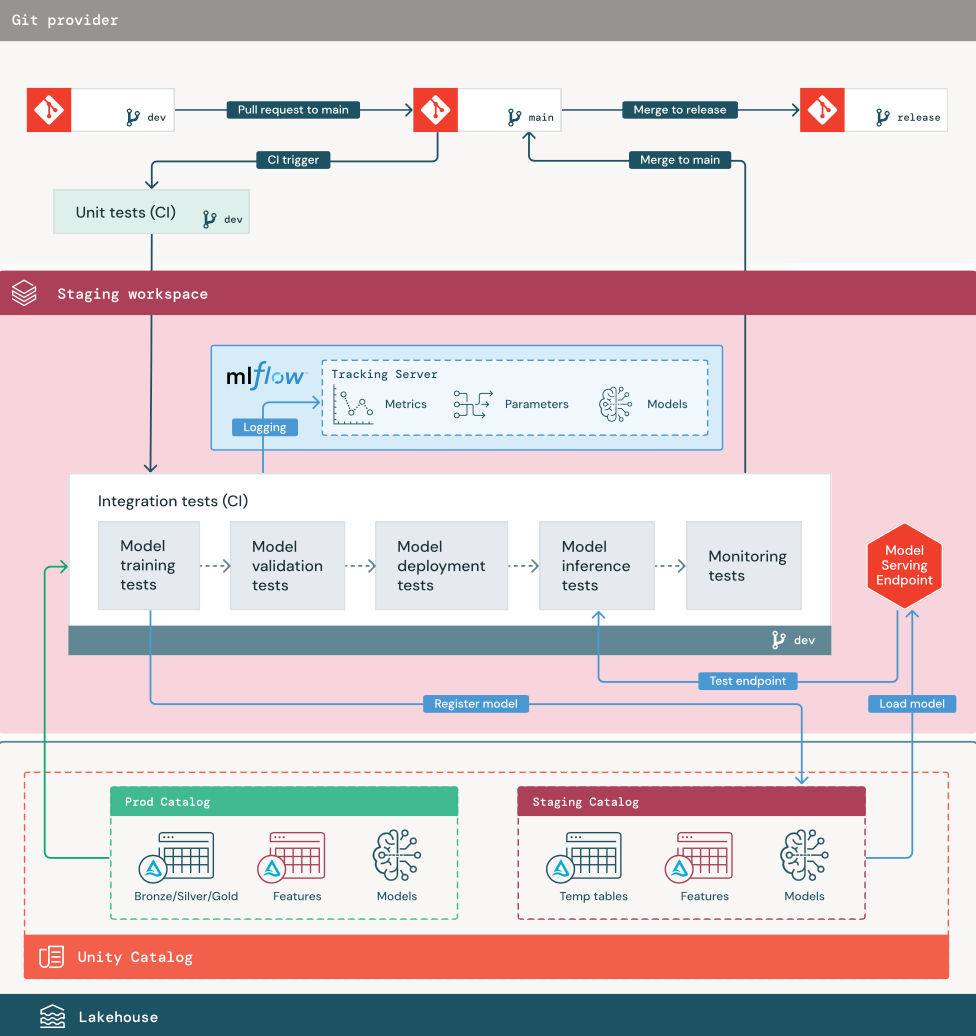
1. Data
Lingkungan penahapan harus memiliki katalog sendiri di Unity Catalog untuk menguji alur ML dan mendaftarkan model ke Unity Catalog. Katalog ini ditampilkan sebagai katalog "penahapan" dalam diagram. Aset yang ditulis ke katalog ini umumnya bersifat sementara dan hanya dipertahankan hingga pengujian selesai. Lingkungan pengembangan mungkin juga memerlukan akses ke staging catalog untuk tujuan debugging.
2. Gabungkan kode
Ilmuwan data mengembangkan alur pelatihan model di lingkungan pengembangan menggunakan tabel dari katalog pengembangan atau produksi.
Permintaan pull. Proses penyebaran dimulai ketika pull request dibuat terhadap cabang utama proyek dalam manajemen kode sumber.
Pengujian unit (CI). Permintaan pull secara otomatis membangun kode sumber dan memicu pengujian unit. Jika pengujian unit gagal, permintaan penarikan ditolak.
Pengujian unit adalah bagian dari proses pengembangan perangkat lunak dan terus dijalankan dan ditambahkan ke basis kode selama pengembangan kode apa pun. Menjalankan pengujian unit sebagai bagian dari alur CI memastikan bahwa perubahan yang dilakukan di cabang pengembangan tidak merusak fungsionalitas yang ada.
3. Uji integrasi (CI)
Proses CI kemudian menjalankan pengujian integrasi. Pengujian integrasi menjalankan semua alur (termasuk rekayasa fitur, pelatihan model, inferensi, dan pemantauan) untuk memastikan bahwa mereka berfungsi dengan benar bersama-sama. Lingkungan pengujian harus semirip mungkin dan sewajar mungkin dengan lingkungan produksi.
Jika Anda menyebarkan aplikasi ML dengan inferensi real-time, Anda harus membuat dan menguji infrastruktur serving di lingkungan staging. Ini melibatkan pemicu alur penyebaran model, yang membuat titik akhir penyajian di lingkungan penahapan dan memuat model.
Untuk mengurangi waktu yang diperlukan untuk menjalankan pengujian integrasi, beberapa langkah dapat menukar antara keakuratan pengujian dan kecepatan atau biaya. Misalnya, jika model mahal atau memakan waktu untuk dilatih, Anda mungkin menggunakan subset kecil data atau menjalankan lebih sedikit perulangan pelatihan. Untuk penyajian model, tergantung pada persyaratan produksi, Anda mungkin melakukan pengujian beban skala penuh dalam pengujian integrasi, atau Anda mungkin hanya menguji pekerjaan batch kecil atau permintaan ke titik akhir sementara.
4. Gabungkan ke cabang penahapan
Jika semua pengujian lulus, kode baru digabungkan ke cabang utama proyek. Jika pengujian gagal, sistem CI/CD harus memberi tahu pengguna dan memposting hasil pada permintaan pull.
Anda dapat menjadwalkan pengujian integrasi berkala di cabang utama. Ini adalah ide yang baik jika cabang sering diperbarui dengan permintaan pull bersamaan dari beberapa pengguna.
5. Buat cabang rilis
Setelah pengujian CI lulus dan cabang dev digabungkan ke cabang utama, teknisi ML membuat cabang rilis, yang memicu sistem CI/CD untuk memperbarui pekerjaan produksi.
Tahap produksi
Teknisi ML memiliki lingkungan produksi tempat alur ML disebarkan dan dijalankan. Alur ini memicu pelatihan model, memvalidasi dan menyebarkan versi model baru, menerbitkan prediksi ke tabel atau aplikasi hilir, dan memantau seluruh proses untuk menghindari penurunan performa dan ketidakstabilan.
Ilmuwan data biasanya tidak memiliki akses tulis atau komputasi di lingkungan produksi. Namun, penting bahwa mereka memiliki visibilitas untuk menguji hasil, log, artefak model, status alur produksi, dan tabel pemantauan. Visibilitas ini memungkinkan mereka mengidentifikasi dan mendiagnosis masalah dalam produksi dan membandingkan performa model baru dengan model yang saat ini dalam produksi. Anda dapat memberikan ilmuwan data akses baca-saja ke aset dalam katalog produksi untuk tujuan ini.
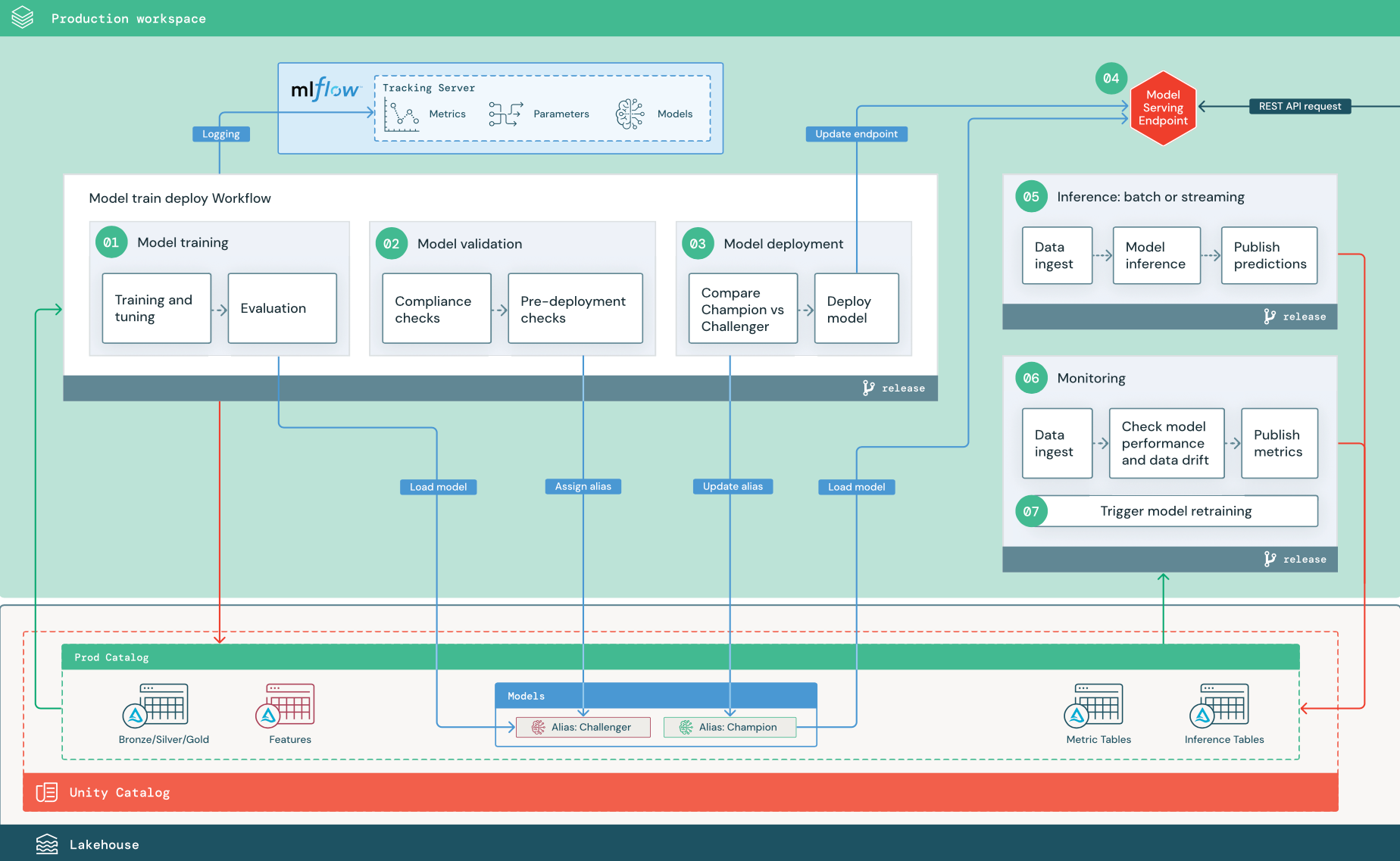
Langkah-langkah bernomor sesuai dengan angka yang diperlihatkan dalam diagram.
Melatih model
Alur ini dapat dipicu oleh perubahan kode atau dengan pekerjaan pelatihan ulang otomatis. Dalam langkah ini, tabel dari katalog produksi digunakan untuk langkah-langkah berikut.
Pelatihan dan penyetelan. Selama proses pelatihan, log direkam ke server Pelacakan MLflow lingkungan produksi. Log ini mencakup metrik model, parameter, tag, dan model itu sendiri. Jika Anda menggunakan tabel fitur, model dicatat ke MLflow menggunakan klien Penyimpanan Fitur Databricks, yang mengemas model dengan informasi pencarian fitur yang digunakan pada waktu inferensi.
Selama pengembangan, ilmuwan data dapat menguji banyak algoritma dan hiperparameter. Dalam kode pelatihan produksi, adalah umum untuk mempertimbangkan hanya opsi berkinerja teratas. Membatasi penyetelan ulang dengan cara ini menghemat waktu dan dapat mengurangi variasi dalam pelatihan ulang otomatis.
Jika ilmuwan data memiliki akses baca-saja ke katalog produksi, mereka mungkin dapat menentukan set hiperparameter yang optimal untuk model. Dalam hal ini, alur pelatihan model yang disebarkan dalam produksi dapat dijalankan menggunakan set hiperparameter yang dipilih, biasanya disertakan dalam alur sebagai file konfigurasi.
Evaluasi. Kualitas model dievaluasi dengan menguji pada data produksi yang disisihkan untuk pengujian. Hasil pengujian ini dicatat ke server pelacakan MLflow. Langkah ini menggunakan metrik evaluasi yang ditentukan oleh ilmuwan data dalam tahap pengembangan. Metrik ini dapat mencakup kode kustom.
Daftarkan model. Ketika pelatihan model selesai, artefak model disimpan sebagai versi model terdaftar di jalur model yang ditentukan dalam katalog produksi di Unity Catalog. Tugas pelatihan model menghasilkan URI model yang dapat digunakan tugas validasi model. Anda dapat menggunakan nilai tugas untuk meneruskan URI ini ke model.
2. Memvalidasi model
Alur ini menggunakan model URI dari Langkah 1 dan memuat model dari Unity Catalog. Kemudian menjalankan serangkaian pemeriksaan validasi. Pemeriksaan ini bergantung pada organisasi dan kasus penggunaan Anda, dan dapat mencakup hal-hal seperti format dasar dan validasi metadata, evaluasi performa pada potongan data yang dipilih, dan kepatuhan terhadap persyaratan organisasi seperti pemeriksaan kepatuhan untuk tag atau dokumentasi.
Jika model berhasil melewati semua pemeriksaan validasi, Anda dapat menetapkan alias "Challenger" ke versi model di Unity Catalog. Jika model tidak lulus semua pemeriksaan validasi, proses keluar dan pengguna dapat diberi tahu secara otomatis. Anda dapat menggunakan tag untuk menambahkan atribut kunci-nilai tergantung pada hasil pemeriksaan validasi ini. Misalnya, Anda dapat membuat tag "model_validation_status" dan mengatur nilai ke "PENDING" saat pengujian dijalankan, lalu memperbaruinya ke "PASSED" atau "FAILED" saat alur selesai.
Karena model terdaftar ke Unity Catalog, ilmuwan data yang bekerja di lingkungan pengembangan dapat memuat versi model ini dari katalog produksi untuk menyelidiki apakah model gagal validasi. Terlepas dari hasil, hasil dicatat pada model yang terdaftar dalam katalog produksi dengan menambahkan anotasi pada versi model.
3. Memublikasikan model
Seperti alur validasi, alur penyebaran model bergantung pada organisasi dan kasus penggunaan Anda. Bagian ini mengasumsikan bahwa Anda telah menetapkan alias "Challenger" untuk model yang baru divalidasi, dan bahwa model produksi yang ada telah ditetapkan alias "Champion". Langkah pertama sebelum menerapkan model baru adalah mengonfirmasi bahwa model tersebut berkinerja paling tidak sama baiknya dengan model produksi saat ini.
Bandingkan model "CHALLENGER" dengan "CHAMPION". Anda dapat melakukan perbandingan ini secara offline atau online. Perbandingan offline mengevaluasi kedua model terhadap himpunan data yang disimpan dan melacak hasil menggunakan server Pelacakan MLflow. Untuk penyajian model real time, Anda mungkin ingin melakukan perbandingan online yang berjalan lebih lama, seperti pengujian A/B atau peluncuran bertahap model baru. Jika versi model "Challenger" berkinerja lebih baik dalam perbandingan, itu menggantikan alias "Juara" saat ini.
Penyajian Model AI Mosaik dan pembuatan profil data memungkinkan Anda mengumpulkan dan memantau tabel inferensi secara otomatis yang berisi data permintaan dan respons untuk titik akhir.
Jika tidak ada model "Champion" yang ada, Anda mungkin membandingkan model "Challenger" dengan heuristik bisnis atau ambang batas lainnya sebagai garis besar.
Proses yang dijelaskan di sini sepenuhnya otomatis. Jika langkah-langkah persetujuan manual diperlukan, Anda dapat mengaturnya menggunakan pemberitahuan alur kerja atau panggilan balik CI/CD dari alur penyebaran model.
Menerapkan model. Alur inferensi batch atau streaming dapat diatur untuk menggunakan model dengan alias "Champion". Untuk kasus penggunaan real time, Anda harus menyiapkan infrastruktur untuk menyebarkan model sebagai titik akhir REST API. Anda dapat membuat dan mengelola titik akhir ini menggunakan Mosaic AI Model Serving. Jika titik akhir sudah digunakan untuk model saat ini, Anda dapat memperbarui titik akhir dengan model baru. Mosaic AI Model Serving menjalankan pembaruan tanpa waktu henti dengan mempertahankan konfigurasi yang ada tetap berjalan hingga yang baru siap.
4. Model Melayani
Saat mengonfigurasi titik akhir Model Serving, Anda menentukan nama model di Unity Catalog dan versi yang akan ditayangkan. Jika versi model dilatih menggunakan fitur dari tabel di Unity Catalog, model menyimpan dependensi untuk fitur dan fungsi. Servis Model secara otomatis menggunakan graf dependensi ini untuk mencari fitur dari toko online yang sesuai saat inferensi. Pendekatan ini juga dapat digunakan untuk menerapkan fungsi untuk pra-pemrosesan data atau untuk menghitung fitur sesuai permintaan selama penilaian model.
Anda dapat membuat satu titik akhir dengan beberapa model dan menentukan pemisahan lalu lintas titik akhir antara model tersebut, memungkinkan Anda melakukan perbandingan "Champion" online versus "Challenger".
5. Inferensi: batch atau streaming
Alur inferensi membaca data terbaru dari katalog produksi, menjalankan fungsi untuk menghitung fitur sesuai permintaan, memuat model "Champion", menilai data, dan mengembalikan prediksi. Inferensi batch atau streaming umumnya adalah opsi yang paling hemat biaya dalam skenario dengan throughput dan latensi yang lebih tinggi. Untuk skenario di mana prediksi latensi rendah diperlukan, tetapi prediksi dapat dihitung secara offline, prediksi batch ini dapat diterbitkan ke penyimpanan nilai kunci online seperti DynamoDB atau Cosmos DB.
Model terdaftar di Unity Catalog direferensikan oleh aliasnya. Alur inferensi dikonfigurasi untuk memuat dan menerapkan versi model "Champion". Jika versi "Champion" diperbarui ke versi model baru, alur inferensi secara otomatis menggunakan versi baru untuk eksekusi berikutnya. Dengan cara ini langkah penyebaran model dipisahkan dari alur inferensi.
Pekerjaan batch biasanya menerbitkan prediksi ke tabel dalam katalog produksi, ke file datar, atau melalui koneksi JDBC. Job streaming biasanya menghasilkan prediksi dan menerbitkannya baik ke tabel Unity Catalog atau ke message queue seperti Apache Kafka.
6. Pembuatan profil data
Pembuatan profil data memantau properti statistik, seperti penyimpangan data dan performa model, data input dan prediksi model. Anda dapat membuat pemberitahuan berdasarkan metrik ini atau menerbitkannya di dasbor.
- Penyerapan data. Alur ini membaca log dari batch, streaming, atau inferensi online.
- Periksa akurasi dan penyimpangan data. Alur menghitung metrik tentang data input, prediksi model, dan performa infrastruktur. Ilmuwan data menentukan metrik data dan model selama pengembangan, dan teknisi ML menentukan metrik infrastruktur. Anda juga dapat menentukan metrik kustom.
- Terbitkan metrik dan siapkan pemberitahuan. Jalur pipa menulis ke tabel dalam katalog produksi untuk analisis dan pelaporan. Anda harus mengonfigurasi tabel ini agar dapat dibaca dari lingkungan pengembangan sehingga ilmuwan data memiliki akses untuk analisis. Anda dapat menggunakan Databricks SQL untuk membuat dasbor pemantauan untuk melacak performa model, dan menyiapkan pekerjaan pemantauan atau alat dasbor untuk mengeluarkan pemberitahuan saat metrik melebihi ambang yang ditentukan.
- Memicu pelatihan ulang model. Saat memantau metrik menunjukkan masalah performa atau perubahan dalam data input, ilmuwan data mungkin perlu mengembangkan versi model baru. Anda dapat menyiapkan pemberitahuan SQL untuk memberi tahu ilmuwan data ketika hal ini terjadi.
7. Pelatihan ulang
Arsitektur ini mendukung pelatihan ulang otomatis menggunakan alur pelatihan model yang sama di atas. Databricks merekomendasikan dimulai dengan pelatihan ulang terjadwal dan berkala dan pindah ke pelatihan ulang yang dipicu saat diperlukan.
- Dijadwalkan. Jika data baru tersedia secara teratur, Anda dapat membuat pekerjaan terjadwal untuk menjalankan kode pelatihan model pada data terbaru yang tersedia. Lihat Mengotomatiskan pekerjaan dengan jadwal dan pemicu
- Dipicu. Jika alur pemantauan dapat mengidentifikasi masalah performa model dan mengirim pemberitahuan, alur tersebut juga dapat memicu pelatihan ulang. Misalnya, jika distribusi data masuk berubah secara signifikan atau jika performa model menurun, pelatihan ulang dan penyebaran ulang otomatis dapat meningkatkan performa model dengan intervensi manusia minimal. Ini dapat dicapai melalui pemberitahuan SQL untuk memeriksa apakah metrik menunjukkan anomali (misalnya, memeriksa drift atau kualitas model terhadap ambang). Pemberitahuan dapat dikonfigurasi untuk menggunakan tujuan webhook, yang kemudian dapat memicu alur kerja pelatihan.
Jika alur pelatihan ulang atau alur lainnya menunjukkan masalah performa, ilmuwan data mungkin perlu kembali ke lingkungan pengembangan untuk eksperimen tambahan untuk mengatasi masalah.