Tumpukan MLOps: proses pengembangan model sebagai kode
Artikel ini menjelaskan bagaimana MLOps Stacks memungkinkan Anda menerapkan proses pengembangan dan penyebaran sebagai kode dalam repositori yang dikontrol sumber. Ini juga menjelaskan manfaat pengembangan model pada platform Databricks Data Intelligence, satu platform yang menyaingkan setiap langkah proses pengembangan dan penyebaran model.
Apa itu Tumpukan MLOps?
Dengan MLOps Stacks, seluruh proses pengembangan model diimplementasikan, disimpan, dan dilacak sebagai kode dalam repositori yang dikontrol sumber. Mengotomatiskan proses dengan cara ini memfasilitasi penyebaran yang lebih berulang, dapat diprediksi, dan sistematis dan memungkinkan untuk berintegrasi dengan proses CI/CD Anda. Mewakili proses pengembangan model sebagai kode memungkinkan Anda menyebarkan kode alih-alih menyebarkan model. Menyebarkan kode mengotomatiskan kemampuan untuk membangun model, membuatnya jauh lebih mudah untuk melatih kembali model bila perlu.
Saat Anda membuat proyek menggunakan MLOps Stacks, Anda menentukan komponen proses pengembangan dan penyebaran ML Anda seperti notebook yang akan digunakan untuk rekayasa fitur, pelatihan, pengujian, dan penyebaran, alur untuk pelatihan dan pengujian, ruang kerja yang akan digunakan untuk setiap tahap, dan alur kerja CI/CD menggunakan GitHub Actions atau Azure DevOps untuk pengujian dan penyebaran otomatis kode Anda.
Lingkungan yang dibuat oleh MLOps Stacks mengimplementasikan alur kerja MLOps yang direkomendasikan oleh Databricks. Anda dapat menyesuaikan kode untuk membuat tumpukan agar sesuai dengan proses atau persyaratan organisasi Anda.
Bagaimana cara kerja MLOps Stacks?
Anda menggunakan Databricks CLI untuk membuat Tumpukan MLOps. Untuk instruksi langkah demi langkah, lihat Bundel Aset Databricks untuk Tumpukan MLOps.
Saat Anda memulai proyek MLOps Stacks, perangkat lunak akan memanah Anda memasukkan detail konfigurasi lalu membuat direktori yang berisi file yang menyusun proyek Anda. Direktori ini, atau tumpukan, mengimplementasikan alur kerja MLOps produksi yang direkomendasikan oleh Databricks. Komponen yang ditampilkan dalam diagram dibuat untuk Anda, dan Anda hanya perlu mengedit file untuk menambahkan kode kustom Anda.
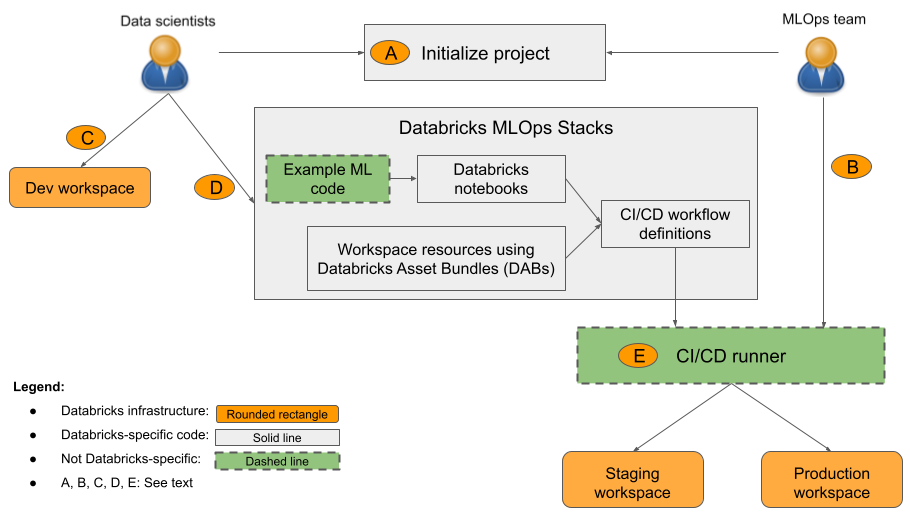
Dalam diagram:
- A: Ilmuwan data atau insinyur ML menginisialisasi proyek menggunakan
databricks bundle init mlops-stacks. Saat menginisialisasi proyek, Anda dapat memilih untuk menyiapkan komponen kode ML (biasanya digunakan oleh ilmuwan data), komponen CI/CD (biasanya digunakan oleh teknisi ML), atau keduanya. - B: Teknisi ML menyiapkan rahasia perwakilan layanan Databricks untuk CI/CD.
- C: Ilmuwan data mengembangkan model pada Databricks atau pada sistem lokal mereka.
- D: Ilmuwan data membuat permintaan pull untuk memperbarui kode ML.
- E: Pelari CI/CD menjalankan notebook, membuat pekerjaan, dan melakukan tugas lain di ruang kerja penahapan dan produksi.
Organisasi Anda dapat menggunakan tumpukan default, atau menyesuaikannya sesuai kebutuhan untuk menambahkan, menghapus, atau merevisi komponen agar sesuai dengan praktik organisasi Anda. Lihat readme repositori GitHub untuk detailnya.
MLOps Stacks dirancang dengan struktur modular untuk memungkinkan tim ML yang berbeda bekerja secara independen pada proyek sambil mengikuti praktik terbaik rekayasa perangkat lunak dan mempertahankan CI/CD tingkat produksi. Teknisi produksi mengonfigurasi infrastruktur ML yang memungkinkan ilmuwan data mengembangkan, menguji, dan menyebarkan alur dan model ML ke produksi.
Seperti yang ditunjukkan dalam diagram, MLOps Stack default menyertakan tiga komponen berikut:
- Kode ML. MLOps Stacks membuat sekumpulan templat untuk proyek ML termasuk notebook untuk pelatihan, inferensi batch, dan sebagainya. Templat standar memungkinkan ilmuwan data untuk memulai dengan cepat, menyaring struktur proyek di seluruh tim, dan memberlakukan kode modularisasi yang siap untuk pengujian.
- Sumber daya ML sebagai kode. MLOps Stacks mendefinisikan sumber daya seperti ruang kerja dan alur untuk tugas seperti pelatihan dan inferensi batch. Sumber daya didefinisikan dalam Bundel Aset Databricks untuk memfasilitasi pengujian, pengoptimalan, dan kontrol versi untuk lingkungan ML. Misalnya, Anda dapat mencoba jenis instans yang lebih besar untuk pelatihan ulang model otomatis, dan perubahan secara otomatis dilacak untuk referensi di masa mendatang.
- CI/CD. Anda dapat menggunakan GitHub Actions atau Azure DevOps untuk menguji dan menyebarkan kode dan sumber daya ML, memastikan bahwa semua perubahan produksi dilakukan melalui otomatisasi dan hanya kode yang diuji yang disebarkan ke prod.
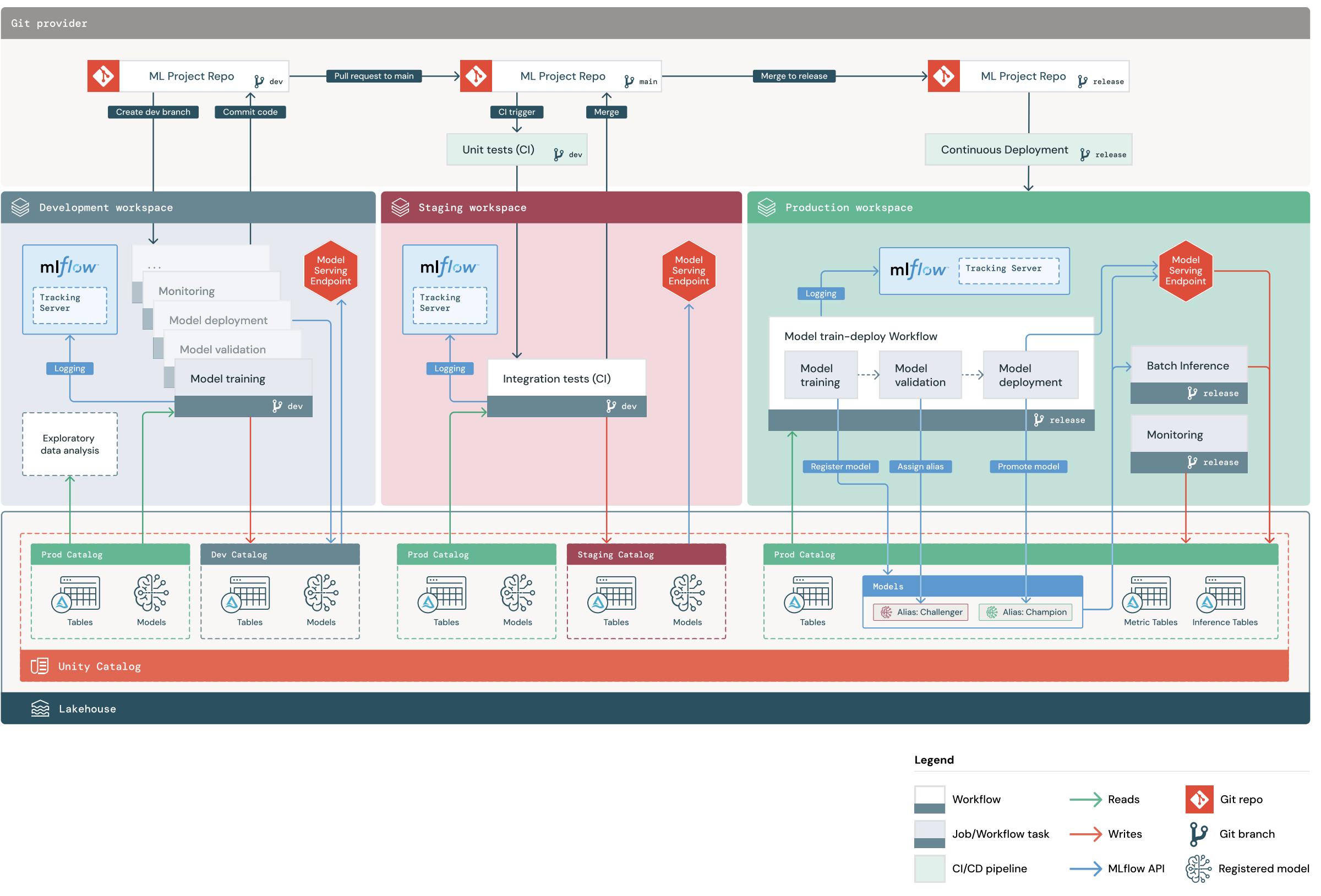
Alur proyek MLOps
Proyek MLOps Stacks default mencakup alur ML dengan alur kerja CI/CD untuk menguji dan menyebarkan pelatihan model otomatis dan pekerjaan inferensi batch di seluruh ruang kerja Databricks pengembangan, penahapan, dan produksi. MLOps Stacks dapat dikonfigurasi, sehingga Anda dapat memodifikasi struktur proyek untuk memenuhi proses organisasi Anda.
Diagram menunjukkan proses yang diimplementasikan oleh MLOps Stack default. Di ruang kerja pengembangan, ilmuwan data melakukan iterasi pada kode ML dan permintaan tarik file (PR). Pengujian unit pemicu PR dan pengujian integrasi di ruang kerja Databricks pementasan terisolasi. Ketika PR digabungkan ke pekerjaan utama pelatihan model dan inferensi batch yang berjalan dalam penahapan segera diperbarui untuk menjalankan kode terbaru. Setelah menggabungkan PR ke utama, Anda dapat memotong cabang rilis baru sebagai bagian dari proses rilis terjadwal Anda dan menyebarkan perubahan kode ke produksi.
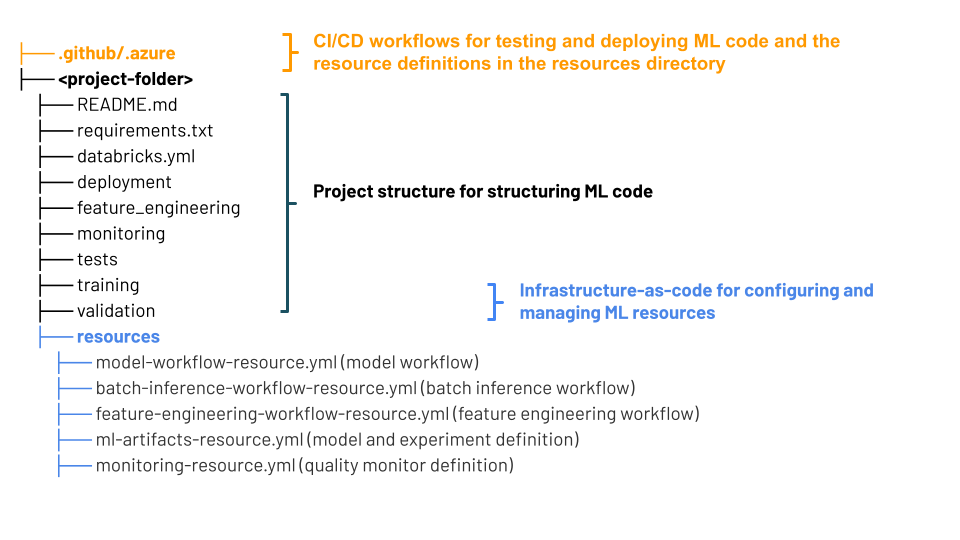
Struktur proyek MLOps Stacks
MLOps Stack menggunakan Bundel Aset Databricks – kumpulan file sumber yang berfungsi sebagai definisi end-to-end proyek. File sumber ini mencakup informasi tentang bagaimana file tersebut akan diuji dan disebarkan. Mengumpulkan file sebagai bundel memudahkan perubahan versi bersama dan menggunakan praktik terbaik rekayasa perangkat lunak seperti kontrol sumber, tinjauan kode, pengujian, dan CI/CD.
Diagram menunjukkan file yang dibuat untuk Tumpukan MLOps default. Untuk detail tentang file yang disertakan dalam tumpukan, lihat dokumentasi tentang repositori GitHub atau Bundel Aset Databricks untuk Tumpukan MLOps.
Komponen Tumpukan MLOps
"Tumpukan" mengacu pada sekumpulan alat yang digunakan dalam proses pengembangan. MLOps Stack default memanfaatkan platform Databricks terpadu dan menggunakan alat berikut:
| Komponen | Alat di Databricks |
|---|---|
| Kode pengembangan model ML | Buku catatan Databricks, MLflow |
| Pengembangan dan manajemen fitur | Rekayasa fitur |
| Repositori model ML | Model di Unity Catalog |
| Penyajian model ML | Penyajian Model AI Mosaik |
| Infrastruktur sebagai kode | Bundel Aset Databricks |
| Orchestrator | Pekerjaan Databricks |
| CI/CD | GitHub Actions, Azure DevOps |
| Pemantauan performa data dan model | Pemantauan Lakehouse |
Langkah berikutnya
Untuk memulai, lihat Bundel Aset Databricks untuk Tumpukan MLOps atau repositori Tumpukan Databricks MLOps di GitHub.