Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menyediakan langkah-langkah dasar untuk menyebarkan dan mengkueri model kustom, yaitu model ML tradisional, menggunakan Mosaic AI Model Serving. Model harus terdaftar di Unity Catalog atau di registri model ruang kerja.
Untuk mempelajari tentang melakukan penyajian dan penyebaran model AI generatif, lihat artikel berikut ini:
Langkah 1: Catat model
Ada berbagai cara untuk mencatat model Anda untuk penyajian model:
| Teknik pengelogan | Deskripsi |
|---|---|
| Autologging | Ini secara otomatis diaktifkan saat Anda menggunakan Databricks Runtime untuk pembelajaran mesin. Ini adalah cara term mudah tetapi memberi Anda kontrol yang lebih sedikit. |
| Pencatatan menggunakan flavor bawaan MLflow | Anda dapat mencatat secara manual dengan jenis model bawaan MLflow. |
Pengelogan kustom dengan pyfunc |
Gunakan ini jika Anda memiliki model kustom atau jika Anda memerlukan langkah tambahan sebelum atau sesudah inferensi. |
Contoh berikut menunjukkan cara merekam model MLflow Anda menggunakan cita rasa transformer dan menentukan parameter yang Anda butuhkan untuk model tersebut.
with mlflow.start_run():
model_info = mlflow.transformers.log_model(
transformers_model=text_generation_pipeline,
artifact_path="my_sentence_generator",
inference_config=inference_config,
registered_model_name='gpt2',
input_example=input_example,
signature=signature
)
Setelah model Anda dicatat, pastikan untuk memeriksa apakah model Anda terdaftar di
Langkah 2: Membuat endpoint menggunakan UI Penyajian
Setelah model terdaftar Anda dicatat dan Anda siap untuk menyajikannya, Anda dapat membuat endpoint penyajian model menggunakan UI Penyajian.
Klik Serving di bar samping untuk menampilkan UI Serving.
Klik Buat titik akhir penyajian.
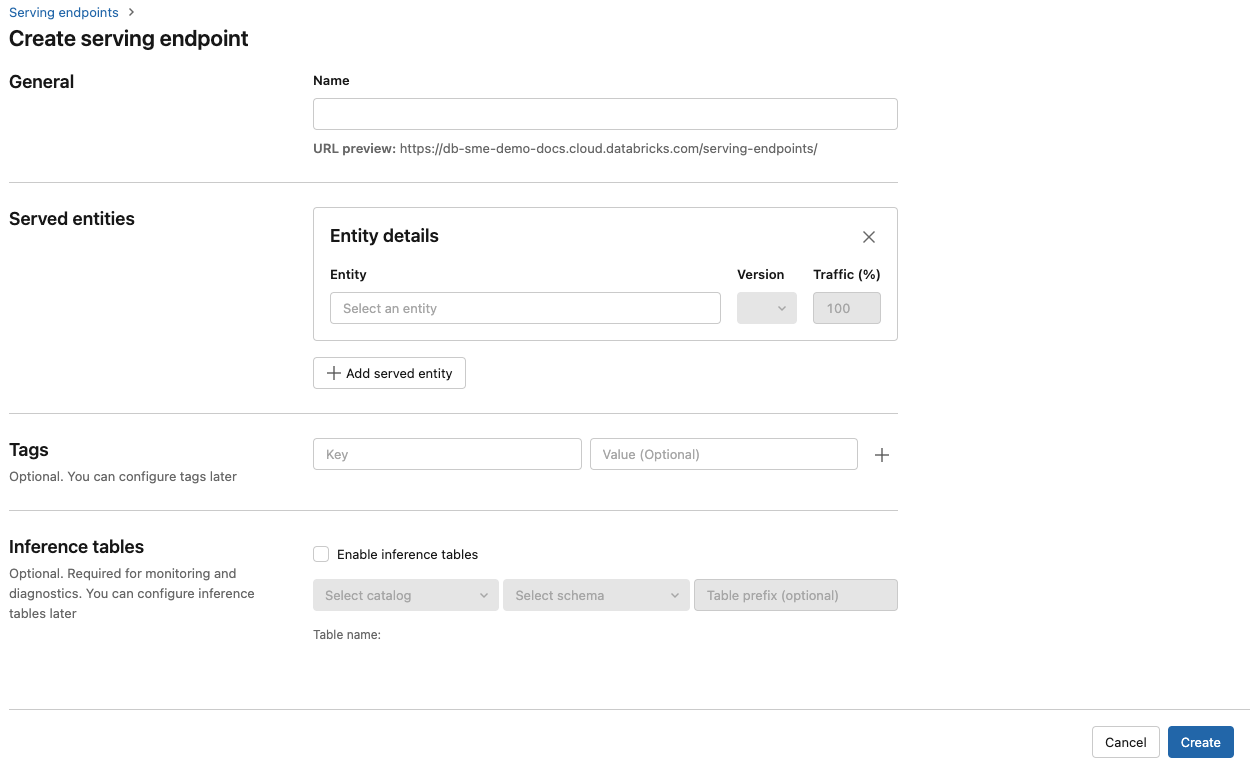
Di bidang Nama , berikan nama untuk titik akhir Anda.
Di bagian Entitas yang dilayani
- Klik bidang Entitas untuk membuka formulir Pilih entitas yang dilayani .
- Pilih jenis model yang ingin Anda layani. Formulir diperbarui secara dinamis berdasarkan pilihan Anda.
- Pilih model dan versi model mana yang ingin Anda layani.
- Pilih persentase lalu lintas yang akan dirutekan ke model yang dilayani.
- Pilih komputasi ukuran apa yang akan digunakan.
- Di bawah Peluasan Skala Komputasi, pilih ukuran peluasan skala komputasi yang sesuai dengan jumlah permintaan yang dapat diproses model yang dilayani ini secara bersamaan. Angka ini harus kira-kira sama dengan waktu eksekusi model QPS x.
- Ukuran yang tersedia adalah Kecil untuk 0-4 permintaan, permintaan Sedang 8-16, dan Besar untuk 16-64 permintaan.
- Tentukan apakah titik akhir harus diskalakan ke nol saat tidak digunakan.
Klik Buat. Halaman Titik akhir penayangan muncul dengan status Titik akhir penayangan ditampilkan sebagai Belum Siap.
Jika Anda lebih suka membuat titik akhir secara terprogram dengan Databricks Serving API, lihat Membuat model kustom yang melayani titik akhir.
Langkah 3: Mengkueri titik akhir
Cara termudah dan tercepat untuk menguji dan mengirim permintaan penilaian ke model yang Anda layani adalah dengan menggunakan Antarmuka Pengguna Pelayanan.
Dari halaman endpoint Pelayanan , pilih endpoint Kueri .
Sisipkan data input model dalam format JSON dan klik Kirim Permintaan. Jika model telah dicatat dengan contoh input, klik Tampilkan Contoh untuk memuat contoh input.
{ "inputs" : ["Hello, I'm a language model,"], "params" : {"max_new_tokens": 10, "temperature": 1} }
Untuk mengirim permintaan penilaian, buat JSON dengan salah satu kunci yang didukung dan objek JSON yang sesuai dengan format input. Lihat Titik akhir layanan kueri untuk model kustom untuk format yang didukung dan panduan tentang cara mengirim permintaan penilaian menggunakan API.
Jika Anda berencana untuk mengakses titik akhir penyajian anda di luar antarmuka pengguna Azure Databricks Serving, Anda memerlukan DATABRICKS_API_TOKEN.
Penting
Sebagai praktik terbaik keamanan untuk skenario produksi, Databricks merekomendasikan agar Anda menggunakan token OAuth mesin-ke-mesin untuk autentikasi selama produksi.
Untuk pengujian dan pengembangan, Databricks merekomendasikan penggunaan token akses pribadi milik perwakilan layanan alih-alih pengguna ruang kerja. Untuk membuat token untuk perwakilan layanan, lihat Mengelola token untuk perwakilan layanan.
Contoh buku catatan
Lihat notebook berikut untuk menyajikan model MLflow transformers dengan Model Serving.
Menyebarkan buku catatan model transformers dari Hugging Face
Lihat notebook berikut untuk menyajikan model MLflow pyfunc dengan Model Serving. Untuk detail tambahan tentang menyesuaikan penyebaran model Anda, lihat Menyebarkan kode Python dengan Model Serving.