HorovodRunner: pembelajaran mendalam terdistribusi dengan Horovod
Pelajari cara melakukan pelatihan terdistribusi model pembelajaran mesin menggunakan HorovodRunner untuk meluncurkan pekerjaan pelatihan Horovod sebagai pekerjaan Spark di Azure Databricks.
Apa itu HorovodRunner?
HorovodRunner adalah API umum untuk menjalankan beban kerja pembelajaran mendalam terdistribusi di Azure Databricks menggunakan kerangka kerja horovod. Dengan mengintegrasikan Horovod dengan mode penghalang Spark, Azure Databricks mampu memberikan stabilitas yang lebih tinggi untuk pekerjaan pelatihan pembelajaran mendalam yang telah lama berjalan di Spark. HorovodRunner mengambil metode Python yang berisi kode pelatihan pembelajaran mendalam dengan kait Horovod. HorovodRunner mengamankan metode pada driver dan mendistribusikannya ke pekerja Spark. Pekerjaan MPI Horovod disematkan sebagai pekerjaan Spark menggunakan mode eksekusi penghalang. Pelaksana pertama mengumpulkan alamat IP dari semua pelaksana tugas menggunakan BarrierTaskContext dan memicu pekerjaan Horovod menggunakan mpirun. Setiap proses MPI Python memuat program pengguna mengamankan, mendeserialisasi, dan menjalankannya.
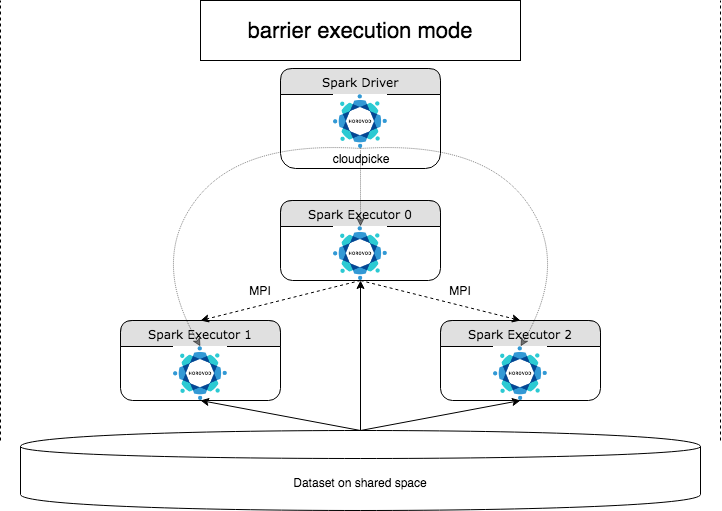
Pelatihan terdistribusi dengan HorovodRunner
HorovodRunner memungkinkan Anda meluncurkan pekerjaan pelatihan Horovod sebagai pekerjaan Spark. API HorovodRunner mendukung metode yang ditunjukkan dalam tabel. Untuk detailnya, lihat dokumentasi API HorovodRunner.
| Metode dan tanda tangan | Deskripsi |
|---|---|
init(self, np) |
Buat instans HorovodRunner. |
run(self, main, **kwargs) |
Jalankan pemanggilan pekerjaan pelatihan Horovod main(**kwargs). Fungsi utama dan argumen kata kunci diserialisasi menggunakan cloudpickle dan didistribusik ke pekerja cluster. |
Pendekatan umum untuk mengembangkan program pelatihan terdistribusi menggunakan HorovodRunner adalah:
- Buat
HorovodRunnerinstans yang diinsialisasi dengan jumlah node. - Tentukan metode pelatihan Horovod sesuai dengan metode yang dijelaskan dalam penggunaan Horovod, pastikan untuk menambahkan pernyataan impor apa pun di dalam metode.
- Berikan metode pelatihan ke
HorovodRunnerinstans.
Contohnya:
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
Untuk menjalankan HorovodRunner pada driver hanya dengan n subproses, gunakan hr = HorovodRunner(np=-n). Misalnya, jika ada 4 GPU pada node driver, Anda dapat memilih n hingga 4. Untuk detail tentang parameter np, lihat dokumentasi API HorovodRunner. Untuk detail tentang cara menyematkan satu GPU per subproses, lihat panduan penggunaan Horovod.
Kesalahan umum adalah bahwa objek TensorFlow tidak dapat ditemukan atau diamankan. Ini terjadi ketika pernyataan impor pustaka tidak didistribusikan ke pelaksana lainnya. Untuk menghindari masalah ini, sertakan semua pernyataan impor (misalnya, import tensorflow as tf) keduanya baik di bagian atas metode pelatihan Horovod dan di dalam fungsi lain yang disebut dalam metode pelatihan Horovod.
Rekam pelatihan Horovod dengan garis waktu Horovod
Horovod memiliki kemampuan untuk merekam garis waktu aktivitasnya, yang disebut Garis waktu Horovod.
Penting
Garis waktu Horovod memiliki dampak signifikan pada performa. Throughput 3 awal dapat menurun ~ 40% saat Garis waktu Horovod diaktifkan. Untuk mempercepat pekerjaan HorovodRunner, jangan gunakan Garis waktu Horovod.
Anda tidak dapat melihat Garis waktu Horovod saat pelatihan sedang berlangsung.
Untuk merekam Garis waktu Horovod, atur HOROVOD_TIMELINE variabel lingkungan ke lokasi di mana Anda ingin menyimpan file timeline. Databricks merekomendasikan menggunakan lokasi pada penyimpanan bersama sehingga file garis waktu dapat dengan mudah diambil. Misalnya, Anda dapat menggunakan API file lokal DBFS seperti yang ditunjukkan:
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
Kemudian, tambahkan kode spesifik garis waktu ke awal dan akhir fungsi pelatihan. Contoh buku catatan berikut menyertakan contoh kode yang bisa Anda gunakan sebagai solusi untuk melihat kemajuan pelatihan.
Buku catatan contoh garis waktu Horovod
Untuk mengunduh file garis waktu, gunakan Databricks CLI, lalu gunakan fasilitas browser chrome://tracing Chrome untuk melihatnya. Contohnya:
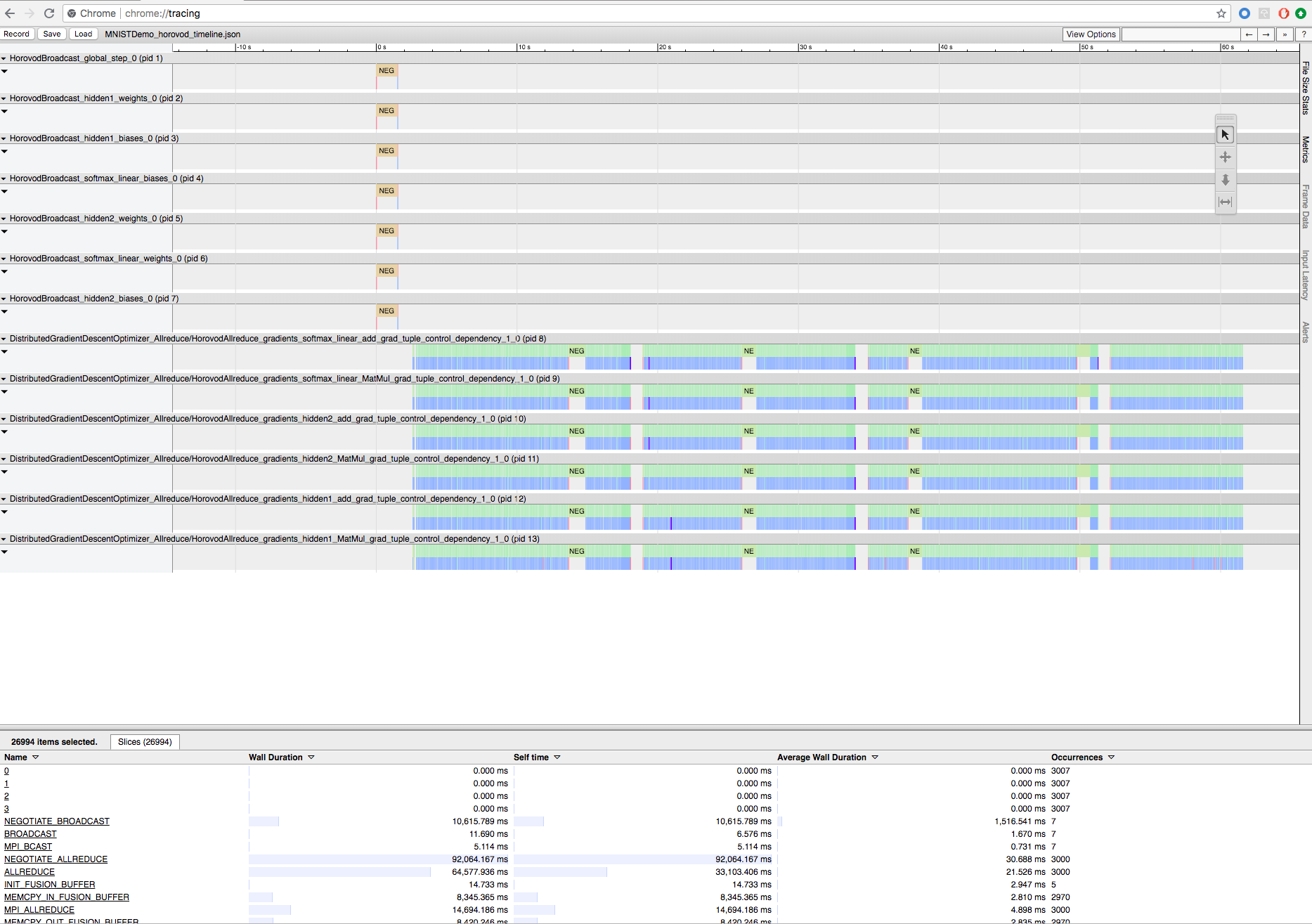
Alur kerja pengembangan
Ini adalah langkah-langkah umum dalam memigrasikan kode pembelajaran mendalam node tunggal ke pelatihan terdistribusi. Contoh : Bermigrasi ke pembelajaran mendalam terdistribusi dengan HorovodRunner di bagian ini menggambarkan langkah-langkah ini.
- Siapkan kode node tunggal: Siapkan dan uji kode node tunggal dengan TensorFlow, Keras, atau PyTorch.
- Migrasi ke Horovod: Ikuti instruksi dari penggunaan Horovod untuk memigrasikan kode dengan Horovod dan mengujinya pada driver:
- Tambahkan
hvd.init()untuk menginisialisasi Horovod. - Sematkan GPU server untuk digunakan oleh proses ini menggunakan
config.gpu_options.visible_device_list. Dengan pengaturan khas satu GPU per proses, ini dapat diatur ke peringkat lokal. Dalam hal ini, proses pertama di server akan dialokasikan GPU pertama, proses kedua akan dialokasikan GPU kedua dan sebagainya. - Sertakan pecahan himpunan data. Operator himpunan data ini sangat berguna saat menjalankan pelatihan terdistribusi, karena memungkinkan setiap pekerja untuk membaca subset yang unik.
- Skala tingkat pembelajaran berdasarkan jumlah pekerja. Ukuran batch yang efektif dalam pelatihan terdistribusi sinkron diskalakan oleh jumlah pekerja. Meningkatkan tingkat pembelajaran mengompensasi peningkatan ukuran batch.
- Bungkus pengoptimal di
hvd.DistributedOptimizer. Pengoptimal terdistribusi mendelegasikan perhitungan gradien ke pengoptimal asli, gradien rata-rata menggunakan mengurangi atau menambah, dan kemudian menerapkan gradien rata-rata. - Tambahkan
hvd.BroadcastGlobalVariablesHook(0)untuk menyiarkan status variabel awal dari peringkat 0 ke semua proses lainnya. Untuk memastikan inisialisasi semua pekerja secara konsisten saat pelatihan dimulai dengan bobot acak atau dipulihkan dari titik pemeriksaan. Atau, jika Anda tidak menggunakanMonitoredTrainingSession, Anda dapat menjalankanhvd.broadcast_global_variablesoperasi setelah variabel global diinisialisasi. - Ubah kode Anda untuk menyimpan titik pemeriksaan hanya pada pekerja 0 untuk mencegah pekerja lain merusaknya.
- Tambahkan
- Migrasikan ke HorovodRunner: HorovodRunner menjalankan pekerjaan pelatihan Horovod dengan menerapkan fungsi Python. Anda harus membungkus prosedur pelatihan utama menjadi satu fungsi Python. Kemudian Anda dapat menguji HorovodRunner dalam mode lokal dan mode terdistribusi.
Memperbarui pustaka pembelajaran mendalam
Catatan
Artikel ini berisi referensi mengenai istilah slave, suatu istilah yang tidak lagi digunakan oleh Azure Databricks. Ketika istilah ini dihapus dari perangkat lunak, kami akan menghapusnya dari artikel ini.
Jika Anda meningkatkan atau menurunkan versi TensorFlow, Keras, atau PyTorch, Anda harus menginstal ulang Horovod sehingga dikompilasi terhadap pustaka yang baru diinstal. Misalnya, jika Anda ingin meningkatkan TensorFlow, Databricks merekomendasikan untuk menggunakan skrip init dari instruksi penginstalan TensorFlow dan menambahkan kode penginstalan Horovod khusus TensorFlow berikut ke akhir. Lihat instruksi penginstalan Horovod untuk bekerja dengan kombinasi yang berbeda, seperti memutakhirkan atau menurunkan PyTorch dan pustaka lainnya.
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60 --slave /usr/bin/g++ g++ /usr/bin/g++-7
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
Contoh: Bermigrasi ke pembelajaran mendalam terdistribusi dengan HorovodRunner
Contoh berikut, berdasarkan himpunan data MNIST, menunjukkan cara memigrasikan program pembelajaran mendalam satu simpul untuk mendistribusikan pembelajaran mendalam dengan HorovodRunner.
- Pembelajaran mendalam menggunakan TensorFlow dengan HorovodRunner untuk MNIST
- Mengadaptasi node tunggal PyTorch ke pembelajaran mendalam terdistribusi
Batasan
- Saat bekerja dengan file ruang kerja, HorovodRunner tidak akan berfungsi jika
npdiatur ke lebih besar dari 1 dan buku catatan mengimpor dari file relatif lainnya. Pertimbangkan untuk menggunakan horovod.spark daripadaHorovodRunner.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk