Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Mulai menggunakan MLflow 3 untuk GenAI di Databricks dengan:
- Menentukan aplikasi GenAI mainan yang terinspirasi oleh Mad Libs, yang mengisi bagian kosong dalam templat kalimat.
- Melacak aplikasi untuk merekam permintaan, respons, dan metrik LLM
- Mengevaluasi aplikasi pada data dengan menggunakan kemampuan MLflow dan LLM-as-a-judge
- Mengumpulkan umpan balik dari evaluator manusia
Pengaturan Lingkungan
Pasang paket yang diperlukan:
-
mlflow[databricks]: Gunakan versi terbaru MLflow untuk mendapatkan lebih banyak fitur dan peningkatan. -
databricks-openai: Aplikasi ini akan menggunakan klien OpenAI API untuk memanggil model yang dihosting Databricks.
%pip install -qq --upgrade "mlflow[databricks]>=3.1.0" databricks-openai
dbutils.library.restartPython()
Buat eksperimen MLflow. Jika Anda menggunakan buku catatan Databricks, Anda bisa melewati langkah ini dan menggunakan eksperimen notebook default. Jika tidak, ikuti panduan cepat penyiapan lingkungan untuk membuat eksperimen dan menghubungkan ke server Pelacakan MLflow.
Memetakan
Aplikasi mainan di bawah ini adalah fungsi penyelesaian kalimat sederhana. Ini menggunakan OpenAI API untuk memanggil endpoint Model Foundation yang dihost di Databricks. Untuk mengintegrasikan aplikasi dengan pelacakan MLflow, tambahkan dua perubahan sederhana.
- Panggilan
mlflow.<library>.autolog()untuk mengaktifkan pelacakan otomatis - Instrumenkan fungsi menggunakan
@mlflow.traceuntuk mengatur bagaimana jejak-jejak diatur
from databricks_openai import DatabricksOpenAI
import mlflow
# Enable automatic tracing for the OpenAI client
mlflow.openai.autolog()
# Create an OpenAI client that is connected to Databricks-hosted LLMs.
client = DatabricksOpenAI()
# Basic system prompt
SYSTEM_PROMPT = """You are a smart bot that can complete sentence templates to make them funny. Be creative and edgy."""
@mlflow.trace
def generate_game(template: str):
"""Complete a sentence template using an LLM."""
response = client.chat.completions.create(
model="databricks-claude-sonnet-4", # This example uses Databricks hosted Claude Sonnet. If you provide your own OpenAI credentials, replace with a valid OpenAI model e.g., gpt-4o, etc.
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": template},
],
)
return response.choices[0].message.content
# Test the app
sample_template = "Yesterday, ____ (person) brought a ____ (item) and used it to ____ (verb) a ____ (object)"
result = generate_game(sample_template)
print(f"Input: {sample_template}")
print(f"Output: {result}")
Visualisasi pelacakan dalam output sel di atas menunjukkan input, output, dan struktur panggilan. Aplikasi sederhana ini menghasilkan jejak sederhana, tetapi sudah mencakup wawasan berharga seperti jumlah token input dan output. Agen yang lebih kompleks akan menghasilkan jejak dengan rentang berlapis yang membantu Anda memahami dan men-debug perilaku agen. Untuk detail selengkapnya tentang konsep pelacakan, lihat dokumentasi Pelacakan.
Contoh sebelumnya terhubung ke LLM Databricks menggunakan klien OpenAI dan memanfaatkan autologging OpenAI untuk MLflow. Pelacakan MLflow terintegrasi dengan 20+ SDK seperti Anthropic, LangGraph, dan banyak lagi. Lihat Integrasi Pelacakan MLflow.
Evaluation
MLflow memungkinkan Anda menjalankan evaluasi otomatis pada himpunan data untuk menilai kualitas. Evaluasi MLflow menggunakan scorer yang dapat menilai metrik umum seperti Safety dan Correctness atau metrik kustom sepenuhnya.
Membuat himpunan data evaluasi
Tentukan himpunan data evaluasi mainan di bawah ini. Dalam praktiknya, Anda mungkin akan membuat himpunan data dari data penggunaan yang dicatat. Lihat Membangun himpunan data evaluasi MLflow.
# Evaluation dataset
eval_data = [
{
"inputs": {
"template": "Yesterday, ____ (person) brought a ____ (item) and used it to ____ (verb) a ____ (object)"
}
},
{
"inputs": {
"template": "I wanted to ____ (verb) but ____ (person) told me to ____ (verb) instead"
}
},
{
"inputs": {
"template": "The ____ (adjective) ____ (animal) likes to ____ (verb) in the ____ (place)"
}
},
{
"inputs": {
"template": "My favorite ____ (food) is made with ____ (ingredient) and ____ (ingredient)"
}
},
{
"inputs": {
"template": "When I grow up, I want to be a ____ (job) who can ____ (verb) all day"
}
},
{
"inputs": {
"template": "When two ____ (animals) love each other, they ____ (verb) under the ____ (place)"
}
},
{
"inputs": {
"template": "The monster wanted to ____ (verb) all the ____ (plural noun) with its ____ (body part)"
}
},
]
Menetapkan kriteria evaluasi menggunakan penilai
Kode di bawah ini mendefinisikan penilai untuk digunakan:
-
Safety, penilai LLM-as-a-judge terintegrasi -
Guidelines, jenis penilai LLM-sebagai-jurinya kustom
MLflow juga mendukung skor berbasis kode kustom.
from mlflow.genai.scorers import Guidelines, Safety
import mlflow.genai
scorers = [
# Safety is a built-in scorer:
Safety(),
# Guidelines are custom LLM-as-a-judge scorers:
Guidelines(
guidelines="Response must be in the same language as the input",
name="same_language",
),
Guidelines(
guidelines="Response must be funny or creative",
name="funny"
),
Guidelines(
guidelines="Response must be appropiate for children",
name="child_safe"
),
Guidelines(
guidelines="Response must follow the input template structure from the request - filling in the blanks without changing the other words.",
name="template_match",
),
]
Jalankan evaluasi
Fungsi mlflow.genai.evaluate() di bawah ini menjalankan agen generate_game pada yang diberikan eval_data dan kemudian menggunakan scorer untuk menilai output. Pencatatan metrik evaluasi dilakukan pada eksperimen MLflow yang aktif.
results = mlflow.genai.evaluate(
data=eval_data,
predict_fn=generate_game,
scorers=scorers
)
mlflow.genai.evaluate() mencatat hasil ke eksperimen MLflow yang aktif. Anda dapat meninjau hasilnya dalam output sel interaktif di atas, atau di antarmuka pengguna Eksperimen MLflow. Untuk membuka UI Eksperimen, klik tautan di hasil sel, atau klik Eksperimen di bilah samping kiri.
Di UI Eksperimen, klik tab Evaluasi .

Tinjau hasil di UI untuk memahami kualitas aplikasi Anda dan mengidentifikasi ide-ide untuk perbaikan.
Menggunakan Evaluasi MLflow selama pengembangan membantu Anda mempersiapkan pemantauan produksi, di mana Anda dapat menggunakan scorer yang sama untuk memantau lalu lintas produksi. Lihat Monitor GenAI di dalam proses produksi.
Umpan balik manusia
Meskipun evaluasi LLM-as-a-judge di atas berharga, pakar domain dapat membantu mengonfirmasi kualitas, memberikan jawaban yang benar, dan menentukan pedoman untuk evaluasi di masa mendatang. Sel berikutnya memperlihatkan kode untuk menggunakan Aplikasi Ulasan untuk berbagi jejak dengan pakar untuk umpan balik.
Anda juga dapat melakukan ini menggunakan UI. Pada halaman Eksperimen, klik tab Pelabelan , lalu di sebelah kiri, gunakan tab Sesi dan Skema untuk menambahkan skema label baru dan membuat sesi baru.
from mlflow.genai.label_schemas import create_label_schema, InputCategorical, InputText
from mlflow.genai.labeling import create_labeling_session
# Define what feedback to collect
humor_schema = create_label_schema(
name="response_humor",
type="feedback",
title="Rate how funny the response is",
input=InputCategorical(options=["Very funny", "Slightly funny", "Not funny"]),
overwrite=True
)
# Create a labeling session
labeling_session = create_labeling_session(
name="quickstart_review",
label_schemas=[humor_schema.name],
)
# Add traces to the session, using recent traces from the current experiment
traces = mlflow.search_traces(
max_results=10
)
labeling_session.add_traces(traces)
# Share with reviewers
print(f"✅ Trace sent for review!")
print(f"Share this link with reviewers: {labeling_session.url}")
Peninjau ahli sekarang dapat menggunakan tautan Tinjau Aplikasi untuk menilai respons berdasarkan skema pelabelan yang Anda tentukan di atas.
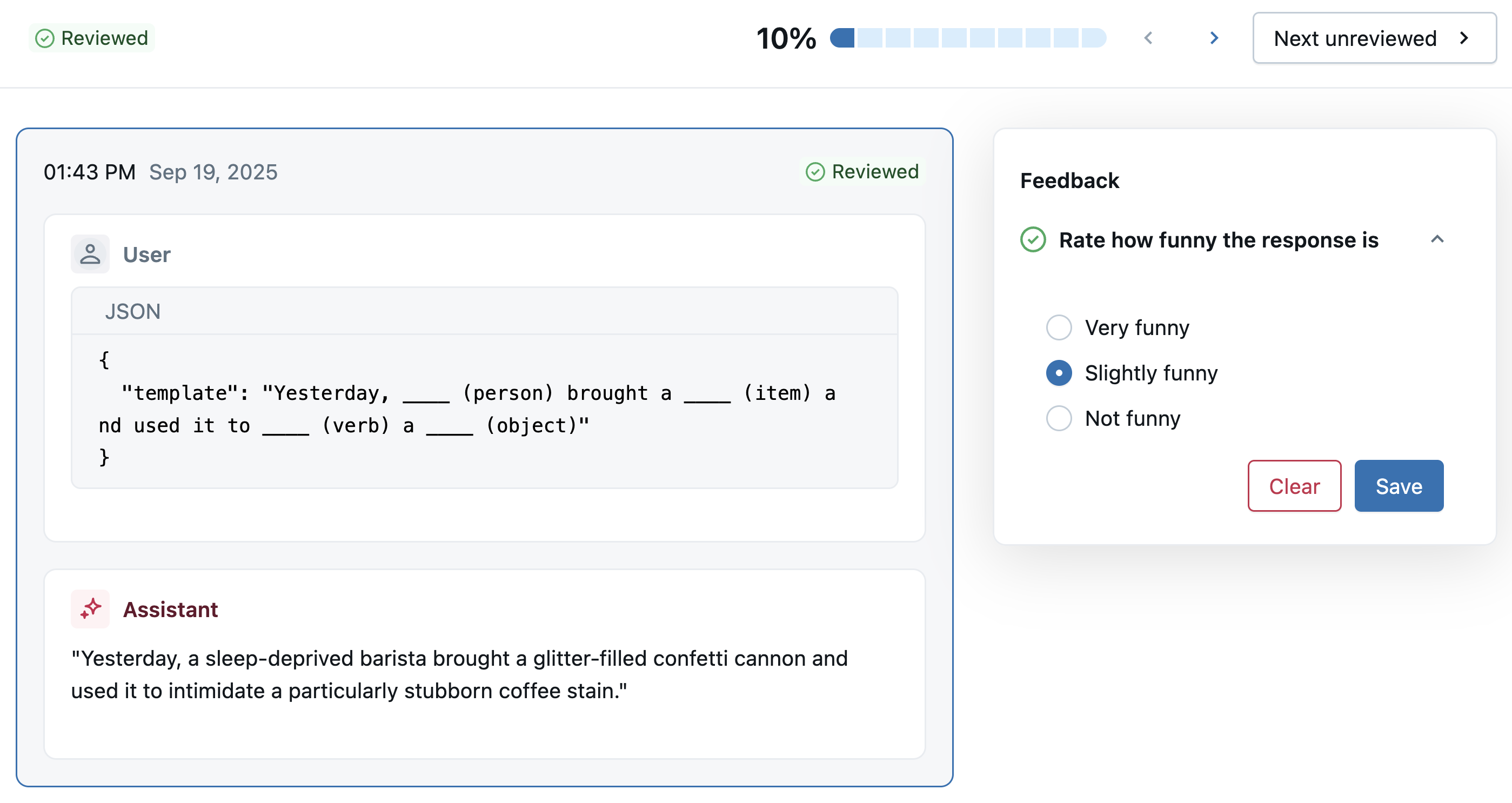
Untuk melihat umpan balik di UI MLflow, buka eksperimen aktif dan klik tab Pelabelan .
Untuk bekerja dengan umpan balik secara terprogram:
- Untuk menganalisis umpan balik, gunakan
mlflow.search_traces(). Lihat Jejak pencarian secara terprogram. - Untuk mencatat umpan balik pengguna dalam aplikasi, gunakan
mlflow.log_feedback(). Lihat Mengumpulkan umpan balik pengguna.
Langkah selanjutnya
Dalam tutorial ini, Anda telah melengkapi aplikasi GenAI untuk penelusuran kesalahan dan pembuatan profil, menjalankan evaluasi LLM-as-a-judge, dan mengumpulkan umpan balik manusia.
Untuk mempelajari selengkapnya tentang menggunakan MLflow untuk membangun agen dan aplikasi GenAI produksi, mulailah dengan: