Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Lakebase Autoscaling adalah versi terbaru Lakebase, dengan komputasi penskalaan otomatis, skala-ke-nol, percabangan, dan pemulihan instan. Untuk wilayah yang didukung, lihat Ketersediaan wilayah. Jika Anda adalah pengguna Lakebase Provisioned, lihat Lakebase Provisioned.
Proyek adalah kontainer tingkat atas untuk sumber daya Lakebase Anda, termasuk cabang, komputasi, database, dan peran. Halaman ini menjelaskan cara membuat proyek, memahami strukturnya, mengonfigurasi pengaturan, dan mengelola siklus hidupnya.
Jika Anda baru menggunakan Lakebase, mulailah dengan Memulai untuk membuat proyek pertama Anda.
Memahami proyek
Struktur Proyek
Memahami struktur proyek Lakebase membantu Anda mengatur dan mengelola sumber daya Anda secara efektif. Proyek adalah kontainer tingkat atas untuk database, cabang, komputasi, dan sumber daya terkait Anda. Setiap proyek mencakup pengaturan untuk pengaturan komputasi default, jendela pemulihan, dan pembaruan yang diterapkan ke semua cabang dalam proyek.
Di tingkat atas, proyek berisi satu atau beberapa cabang. Dalam proyek, Anda dapat membuat cabang untuk lingkungan yang berbeda seperti pengembangan, pengujian, penahapan, dan produksi. Setiap cabang berisi komputasi, peran, dan databasenya sendiri.
Project
└── Branches (main, development, staging, etc.)
├── Computes (R/W compute)
├── Roles (Postgres roles)
└── Databases (Postgres databases)
Cabang
Data terdapat pada cabang. Setiap proyek Lakebase dibuat dengan cabang akar yang disebut production, yang tidak dapat dihapus. Meskipun Anda dapat membuat cabang tambahan dan menunjuk cabang yang berbeda sebagai cabang default Anda, cabang akar tidak dapat dihapus.
Anda dapat membuat cabang anak dari cabang mana pun di proyek Anda. Saat Anda membuat cabang anak, cabang tersebut mewarisi semua database, peran, dan data dari cabang induknya pada saat pembuatan. Perubahan berikutnya di cabang induk tidak secara otomatis disebarluaskan ke cabang anak, memungkinkan pengembangan, pengujian, atau eksperimen yang terisolasi.
Setiap cabang dapat berisi beberapa database dan peran. Pelajari lebih lanjut: Mengelola cabang
Menghitung
Komputasi adalah sumber daya komputasi virtual yang mencakup vCPU dan memori untuk menjalankan dan mengoperasikan Postgres. Saat Anda membuat proyek, komputasi R/W (baca-tulis) utama dibuat untuk cabang default proyek. Setiap cabang memiliki satu komputer R/W utama. Untuk menyambungkan ke database yang berada di cabang, Anda harus tersambung melalui komputasi R/W yang terkait dengan cabang.
Selain komputasi R/W utama, Anda dapat menambahkan satu atau beberapa komputasi replika baca (baca-saja) ke cabang mana pun. Replika baca memungkinkan Anda untuk mengalihkan beban kerja baca-saja dari komputasi utama Anda untuk kasus penggunaan seperti peningkatan kapasitas baca secara horizontal, analitik dan kueri pelaporan, serta akses baca-saja untuk pengguna atau aplikasi. Pelajari selengkapnya: Mengelola komputasi, Membaca replika
Peran
Peran adalah peran Postgres. Peran diperlukan untuk membuat dan mengakses database. Peran merupakan bagian dari cabang. Saat Anda membuat proyek, peran Postgres secara otomatis dibuat untuk identitas Databricks Anda (misalnya, user@databricks.com), yang merupakan pemilik database default databricks_postgres . Peran apa pun yang dibuat di UI Lakebase dibuat dengan databricks_superuser hak istimewa. Ada batas 500 peran per cabang. Pelajari lebih lanjut: Mengelola peran
Database
Database adalah kontainer untuk objek SQL seperti skema, tabel, tampilan, fungsi, dan indeks. Di Lakebase, database milik cabang. Cabang default proyek Anda dibuat dengan database bernama databricks_postgres. Ada batas 500 database per cabang. Pelajari selengkapnya: Mengelola database
Skema
Semua database di Lakebase dibuat dengan public skema, yang merupakan perilaku default untuk instans Postgres standar apa pun. Objek SQL dibuat dalam public skema secara default.
Batas proyek
Lakebase Postgres memberlakukan batas berikut untuk proyek:
| Sumber Daya | Limit |
|---|---|
| Jumlah maksimum unit komputasi yang aktif bersamaan | 20 |
| Jumlah maksimum replika baca untuk cabang | 6 |
| Jumlah maksimum cabang per proyek | 500 |
| Jumlah maksimum role Postgres per cabang | 500 |
| Jumlah maksimum database Postgres per cabang | 500 |
| Ukuran data logis maksimum per cabang | 8 TB |
| Jumlah maksimum proyek per ruang kerja | 1000 |
| Jumlah maksimum cabang yang dilindungi | 1 |
| Jumlah maksimum cabang akar | 3 |
| Jumlah maksimum cabang yang belum diarsipkan | 10 |
| Jumlah maksimum cuplikan manual | 10 |
| Periode maksimum penyimpanan riwayat | 30 hari |
| Skala minimum untuk nol waktu | 60 detik |
Batas komputasi yang aktif secara bersamaan
Batas komputasi yang aktif secara bersamaan membatasi berapa banyak komputasi yang dapat berjalan secara bersamaan untuk mencegah kelelahan sumber daya. Batas ini melindungi dari lonjakan sumber daya yang tidak disengaja, seperti memulai banyak titik akhir komputasi sekaligus. Batas defaultnya adalah 20 komputasi aktif bersamaan per proyek.
Penting: Cabang default dikecualikan dari batas ini, memastikannya tetap tersedia setiap saat.
Ketika Anda melebihi batas, komputasi tambahan di luar batas tetap ditangguhkan dan Anda melihat kesalahan saat mencoba menyambungkannya. Untuk mengatasi hal ini:
- Tangguhkan komputasi aktif lainnya dan coba lagi.
- Jika Anda sering mengalami kesalahan ini, hubungi Dukungan Databricks untuk meminta peningkatan batas.
Nota
Komputasi dengan skala ke nol diaktifkan akan secara otomatis ditangguhkan setelah tidak ada aktivitas. Ini membantu Anda tetap berada dalam batas komputasi yang aktif secara bersamaan.
Ketersediaan wilayah
Wilayah yang didukung:
-
eastus(US Timur) -
eastus2(US Timur 2) -
centralus(Amerika Serikat Tengah) -
southcentralus(US Tengah Selatan) -
westus(US Barat) -
westus2(US Barat 2) -
canadacentral(Kanada Tengah) -
brazilsouth(Brasil Selatan) -
northeurope(Eropa Utara) -
uksouth(Inggris Selatan) -
westeurope(Eropa Barat) -
australiaeast(Australia Timur) -
centralindia(India Tengah) -
southeastasia(Asia Tenggara)
Proyek Lakebase Anda dibuat di wilayah ruang kerja Databricks Anda.
Dukungan versi Postgres
Lakebase Postgres Autoscaling mendukung Postgres 16 dan Postgres 17.
Membuat dan mengelola proyek
Membuat proyek
Anda dapat membuat beberapa proyek di Lakebase Postgres untuk menjaga aplikasi atau pelanggan tetap terisolasi sepenuhnya, memastikan pemisahan data dan sumber daya yang bersih.
Untuk membuat proyek:
Antarmuka Pengguna
- Klik pengalih aplikasi di sudut kanan atas untuk membuka Aplikasi Lakebase.
- Klik Proyek baru.
- Konfigurasikan pengaturan proyek Anda:
-
Nama tampilan: Masukkan nama untuk proyek Anda. Anda dapat menggunakan karakter apa pun, termasuk spasi dan karakter khusus. Pola penamaan umum termasuk penamaan setelah aplikasi (misalnya,
My Analytics App) atau pelanggan atau penyewa yang dilayani proyek (misalnya,Acme Corp DB). Nama sumber daya berasal dari nama tampilan Anda secara otomatis dan digunakan untuk mengidentifikasi proyek dalam panggilan API dan SDK. Dialog menunjukkan nama sumber daya yang dihasilkan (misalnya,projects/my-analytics-app) sehingga Anda dapat memverifikasinya sebelum membuat proyek. - Versi Postgres: Pilih versi Postgres yang ingin Anda gunakan.
- Kebijakan penggunaan tanpa server (opsional): Pilih kebijakan penggunaan tanpa server untuk mengaitkan biaya komputasi tanpa server ke kebijakan tertentu. Lihat Kebijakan penggunaan tanpa server.
-
Nama tampilan: Masukkan nama untuk proyek Anda. Anda dapat menggunakan karakter apa pun, termasuk spasi dan karakter khusus. Pola penamaan umum termasuk penamaan setelah aplikasi (misalnya,
Dialog Buat proyek memperlihatkan opsi konfigurasi proyek.
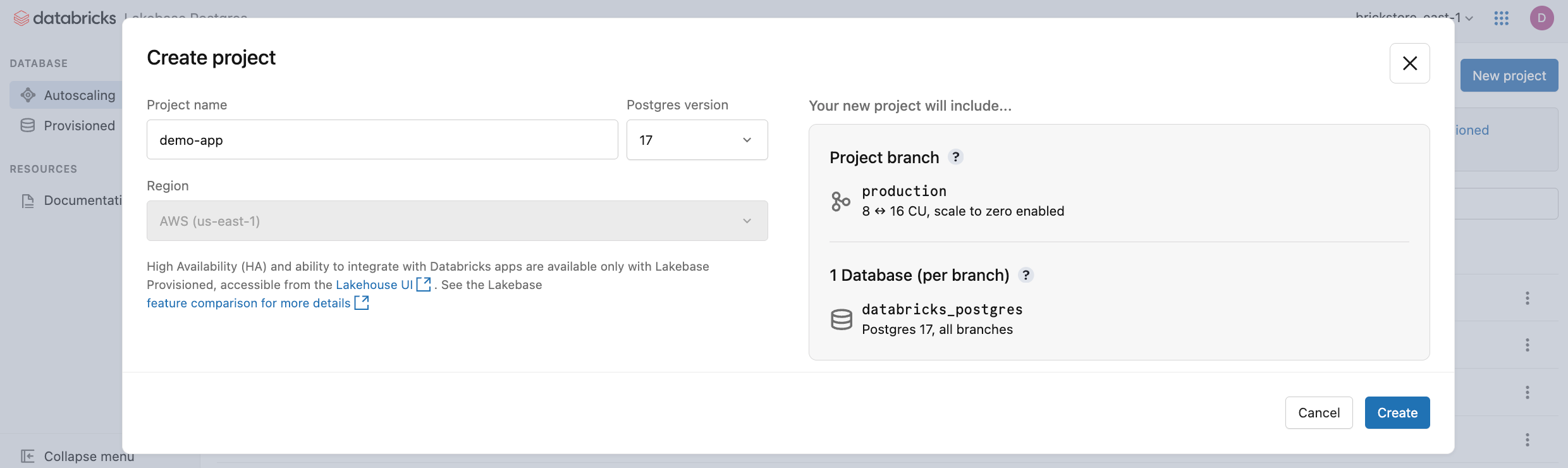
Wilayah untuk proyek Lakebase Anda diatur ke wilayah ruang kerja Databricks Anda dan tidak dapat dimodifikasi.
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec
# Initialize the Workspace client
w = WorkspaceClient()
# Create a project with a custom project ID
operation = w.postgres.create_project(
project=Project(
spec=ProjectSpec(
display_name="My Application",
pg_version=17,
budget_policy_id="<policy-id>"
)
),
project_id="my-app"
)
# Wait for operation to complete
result = operation.wait()
print(f"Created project: {result.name}")
print(f"Display name: {result.status.display_name}")
print(f"Postgres version: {result.status.pg_version}")
Java SDK
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
// Initialize the Workspace client
WorkspaceClient w = new WorkspaceClient();
// Create a project with a custom project ID
CreateProjectOperation operation = w.postgres().createProject(
new CreateProjectRequest()
.setProjectId("my-app")
.setProject(new Project()
.setSpec(new ProjectSpec()
.setDisplayName("My Application")
.setPgVersion(17L)))
);
// Wait for operation to complete
Project result = operation.waitForCompletion();
System.out.println("Created project: " + result.getName());
System.out.println("Display name: " + result.getStatus().getDisplayName());
System.out.println("Postgres version: " + result.getStatus().getPgVersion());
antarmuka baris perintah (CLI)
# Create a project with a custom project ID
databricks postgres create-project my-app \
--json '{
"spec": {
"display_name": "My Application",
"pg_version": 17,
"budget_policy_id": "<policy-id>"
}
}'
melengkung
Buat proyek dengan ID proyek kustom.
project_id ditentukan sebagai parameter kueri dan menjadi bagian dari nama sumber daya proyek (misalnya, projects/my-app).
curl -X POST "$WORKSPACE/api/2.0/postgres/projects?project_id=my-app" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Application",
"pg_version": 17,
"budget_policy_id": "<policy-id>"
}
}' | jq
Ini adalah operasi jangka panjang. Respons menyertakan nama operasi yang dapat Anda gunakan untuk memeriksa status. Operasi biasanya selesai dalam hitungan detik.
Parameter project_id diperlukan.
Proyek baru menyertakan sumber daya berikut secara default:
Satu
productioncabang (cabang utama)Satu komputasi baca-tulis utama yang terkait dengan cabang dengan pengaturan default berikut:
Cabang Unit Komputasi (CU) HA Autoscaling Skala-ke-nol production8 - 16 CU Nonaktif Enabled Nonaktif Saat Anda membuat proyek,
productioncabang dibuat dengan komputasi yang memiliki skala-ke-nol yang dinonaktifkan secara default, yang berarti komputasi tetap aktif setiap saat. Anda dapat mengaktifkan skala-ke-nol untuk komputasi ini jika diperlukan.Database Postgres (bernama
databricks_postgres)Peran Postgres untuk identitas Databricks Anda (misalnya,
user@databricks.com)
Untuk mengubah pengaturan komputasi untuk proyek yang sudah ada, lihat Mengonfigurasi pengaturan proyek. Untuk mengubah pengaturan komputasi bawaan untuk proyek baru, lihat Pengaturan Komputasi Bawaan di Mengonfigurasi Pengaturan Proyek.
Dapatkan detail proyek
Ambil detail untuk proyek tertentu.
Antarmuka Pengguna
- Klik pengalih aplikasi di sudut kanan atas untuk membuka Aplikasi Lakebase.
- Pilih proyek Anda dari daftar proyek untuk melihat detailnya.
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Get project details
project = w.postgres.get_project(name="projects/my-project")
print(f"Project: {project.name}")
print(f"Display name: {project.status.display_name}")
print(f"Postgres version: {project.status.pg_version}")
Java SDK
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.Project;
WorkspaceClient w = new WorkspaceClient();
// Get project details
Project project = w.postgres().getProject("projects/my-project");
System.out.println("Project: " + project.getName());
System.out.println("Display name: " + project.getStatus().getDisplayName());
System.out.println("Postgres version: " + project.getStatus().getPgVersion());
antarmuka baris perintah (CLI)
# Get project details
databricks postgres get-project projects/my-project
melengkung
curl -X GET "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Respon meliputi:
-
name: Nama sumber daya (projects/my-project) -
status: konfigurasi Project dan status saat ini (display_name, pg_version, dll.)
Catatan: Kolom spec tidak diisi untuk operasi GET. Semua properti sumber daya dikembalikan dalam bidang status.
Mencantumkan proyek
Cantumkan semua proyek di ruang kerja Anda.
Antarmuka Pengguna
- Klik pengalih aplikasi di sudut kanan atas untuk membuka Aplikasi Lakebase.
- Daftar proyek menampilkan semua proyek yang dapat Anda akses.
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# List all projects
projects = w.postgres.list_projects()
for project in projects:
print(f"Project: {project.name}")
print(f" Display name: {project.status.display_name}")
print(f" Postgres version: {project.status.pg_version}")
Java SDK
import com.databricks.sdk.WorkspaceClient;
import com.databricks.sdk.service.postgres.*;
WorkspaceClient w = new WorkspaceClient();
// List all projects
for (Project project : w.postgres().listProjects(new ListProjectsRequest())) {
System.out.println("Project: " + project.getName());
System.out.println(" Display name: " + project.getStatus().getDisplayName());
System.out.println(" Postgres version: " + project.getStatus().getPgVersion());
}
antarmuka baris perintah (CLI)
# List all projects
databricks postgres list-projects
melengkung
curl -X GET "$WORKSPACE/api/2.0/postgres/projects" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Format respons:
{
"projects": [
{
"name": "projects/my-project",
"status": {
"display_name": "My Project",
"pg_version": 17
}
}
]
}
Mengonfigurasi pengaturan proyek
Setelah membuat proyek, Anda dapat memodifikasi berbagai pengaturan dari dasbor proyek dengan menavigasi ke Pengaturan:
Pengaturan umum
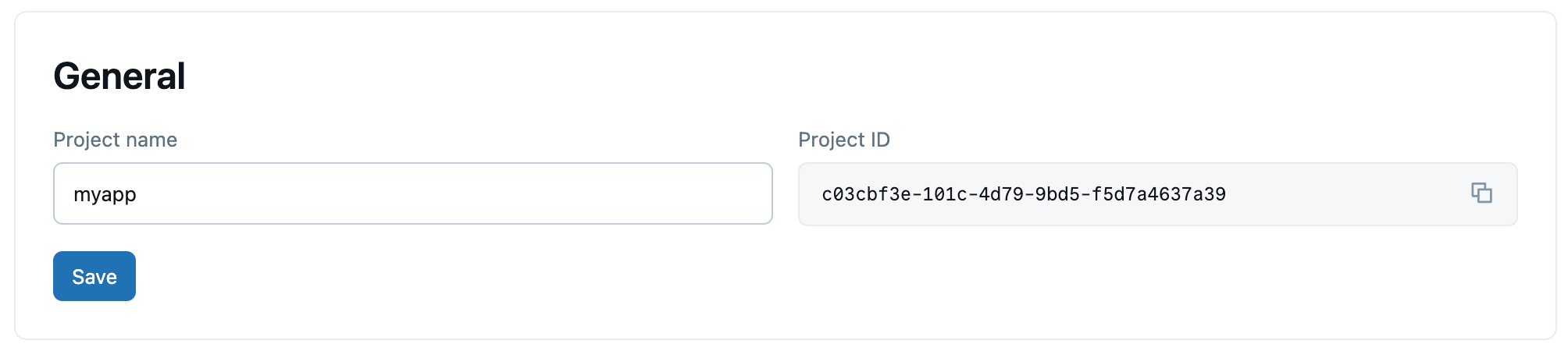
Halaman pengaturan umum menampilkan bidang berikut:
- Nama tampilan: Nama tampilan yang dapat diedit untuk proyek Anda.
-
Nama sumber daya: Baca-saja. Jalur sumber daya lengkap untuk proyek Anda (format:
projects/{project_id}). Gunakan nilai ini dalam panggilan API dan SDK untuk mengidentifikasi proyek. - UID: Baca-saja. Pengidentifikasi unik yang dihasilkan sistem untuk proyek Anda.
- Kebijakan penggunaan tanpa server: Kaitkan kebijakan penggunaan tanpa server dengan proyek Anda untuk mengaitkan biaya komputasi tanpa server ke kebijakan tertentu. Lihat Kebijakan penggunaan tanpa server.
-
Tag kustom: Tambahkan tag kunci-nilai ke proyek Anda. Tag dicatat dalam catatan penggunaan akun Anda yang dapat ditagih (
system.billing.usage) dan dapat digunakan untuk melacak biaya berdasarkan tim, proyek, atau pusat biaya. Lihat Tag kustom. Saat Anda memperbarui tag kustom menggunakan API atau CLI, daftar baru menggantikan semua tag yang ada.
Antarmuka Pengguna
Python SDK
from databricks.sdk import WorkspaceClient
from databricks.sdk.service.postgres import Project, ProjectSpec, ProjectCustomTag, FieldMask
w = WorkspaceClient()
# Update project display name
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.display_name"]),
project=Project(spec=ProjectSpec(display_name="My Updated Project Name"))
).wait()
# Update serverless usage policy
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.budget_policy_id"]),
project=Project(spec=ProjectSpec(budget_policy_id="<policy-id>"))
).wait()
# Update custom tags (replaces all existing tags)
w.postgres.update_project(
name="projects/my-project",
update_mask=FieldMask(field_mask=["spec.custom_tags"]),
project=Project(spec=ProjectSpec(custom_tags=[
ProjectCustomTag(key="team", value="data-eng"),
ProjectCustomTag(key="cost-center", value="1234")
]))
).wait()
antarmuka baris perintah (CLI)
# Update project display name
databricks postgres update-project projects/my-project spec.display_name \
--json '{
"spec": {
"display_name": "My Updated Project Name"
}
}'
# Update serverless usage policy
databricks postgres update-project projects/my-project spec.budget_policy_id \
--json '{
"spec": {
"budget_policy_id": "<policy-id>"
}
}'
# Update custom tags
databricks postgres update-project projects/my-project spec.custom_tags \
--json '{
"spec": {
"custom_tags": [
{"key": "team", "value": "data-eng"},
{"key": "cost-center", "value": "1234"}
]
}
}'
melengkung
# Update project display name
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.display_name" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"display_name": "My Updated Project Name"
}
}' | jq
# Update serverless usage policy
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.budget_policy_id" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"budget_policy_id": "<policy-id>"
}
}' | jq
# Update custom tags
curl -X PATCH "$WORKSPACE/api/2.0/postgres/projects/my-project?update_mask=spec.custom_tags" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" \
-H "Content-Type: application/json" \
-d '{
"spec": {
"custom_tags": [
{"key": "team", "value": "data-eng"},
{"key": "cost-center", "value": "1234"}
]
}
}' | jq
Ini adalah operasi jangka panjang. Respons menyertakan nama operasi yang dapat Anda gunakan untuk memeriksa status.
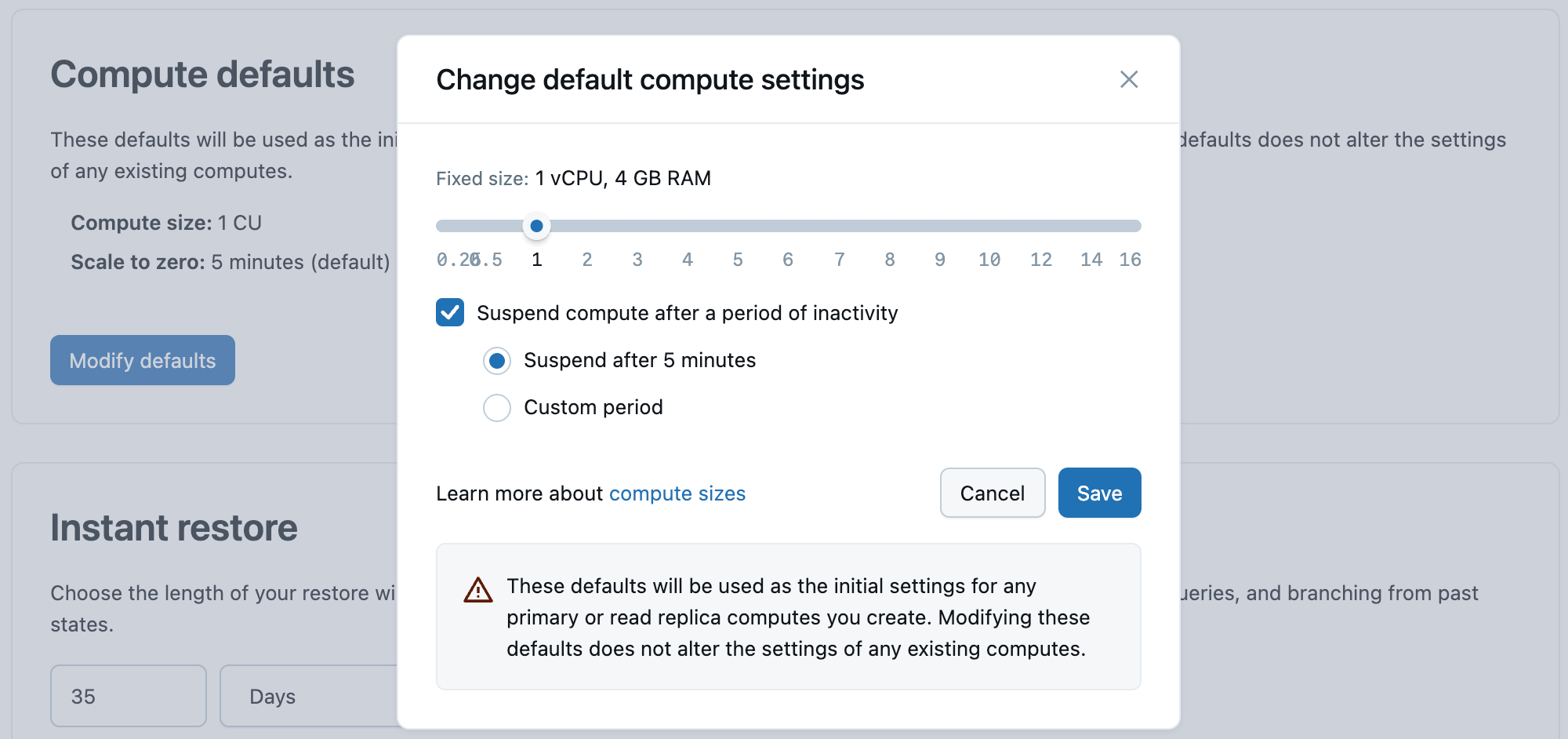
Komputasi default
Pengaturan default ini digunakan sebagai konfigurasi awal untuk unit komputasi utama atau replika baca apa pun yang Anda buat. Mengubah default ini tidak mengubah pengaturan komputasi yang ada.
Nilai default:
- Ukuran komputasi: 2 ↔ 4 CU (rentang penskalaan otomatis; ~RAM 4–8 GB)
- Skalakan ke nol: Diaktifkan secara default—Menangguhkan komputasi setelah periode tidak aktif dicentang , dengan Tangguhkan setelah 5 menit dipilih
Klik Ubah default untuk membuka dialog dan mengubah nilai-nilai ini.
Nota
Untuk mengubah pengaturan komputasi yang sudah ada, lihat Mengelola komputasi.
Lakebase Postgres mendukung ukuran komputasi dari 0,5 CU hingga 112 CU. Penskalaan otomatis tersedia untuk komputasi hingga 32 CU (0,5, lalu kenaikan bilangan bulat: 1, 2, 3... 16, lalu 24, 28, 32). Komputasi ukuran tetap yang lebih besar tersedia dari 36 CU hingga 112 CU (36, 40, 44, 48, 52, 56, 60, 64, 72, 80, 88, 96, 104, 112). Setiap Unit Komputasi (CU) menyediakan RAM 2 GB.
Nota
Lakebase Provisioned vs Autoscaling: Di Lakebase Provisioned, setiap Unit Komputasi mengalokasikan sekitar 16 GB RAM. Pada Lakebase Autoscaling, setiap CU mengalokasikan 2 GB RAM. Perubahan ini menyediakan opsi penskalakan dan kontrol biaya yang lebih terperinci.
Ukuran perwakilan:
| Unit Komputasi | MAA |
|---|---|
| 0,5 CU | 1 GB |
| 1 CU | 2 GB |
| 4 CU | 8 GB |
| 8 CU | 16 GB |
| 16 CU | 32 GB |
| 32 CU | 64 GB |
| 64 CU | 128 GB |
| 112 CU | 224 GB |
- Untuk mengaktifkan penskalaan otomatis, atur rentang ukuran komputasi menggunakan penggelis. Penyesuaian skala otomatis secara dinamis mengatur sumber daya komputasi berdasarkan permintaan beban kerja. Pelajari lebih lanjut: Autoscaling
- Sesuaikan pengaturan skala-ke-nol untuk menambah atau mengurangi jumlah waktu komputasi yang tidak aktif sebelum komputasi ditangguhkan. Anda juga dapat menonaktifkan scale-to-zero untuk komputasi yang selalu menyala. Pelajari lebih lanjut: Pengurangan hingga nol
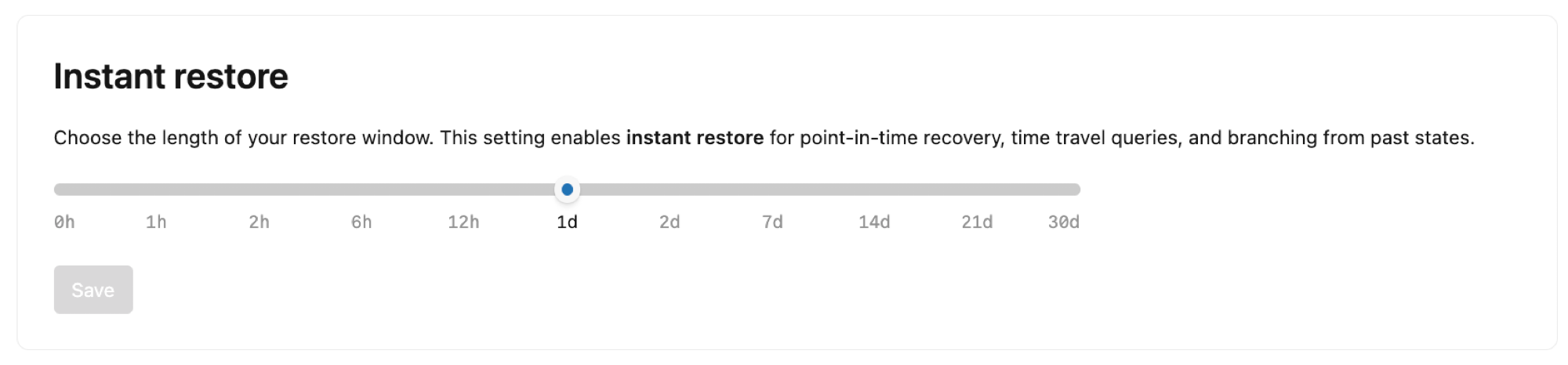
Pemulihan instan
Konfigurasikan panjang jendela pemulihan untuk proyek Anda. Secara default, Lakebase menyimpan riwayat perubahan untuk cabang akar dalam proyek Anda, memungkinkan pemulihan titik waktu untuk memulihkan data yang hilang, mengkueri data pada titik waktu untuk menyelidiki masalah data, dan percabangan dari status sebelumnya untuk alur kerja pengembangan.
Anda dapat mengatur jendela pemulihan dari 2 hari hingga 30 hari. Perhatikan bahwa:
- Memperluas jendela pemulihan akan meningkatkan penyimpanan Anda
- Pengaturan jendela pemulihan memengaruhi semua cabang dalam proyek Anda
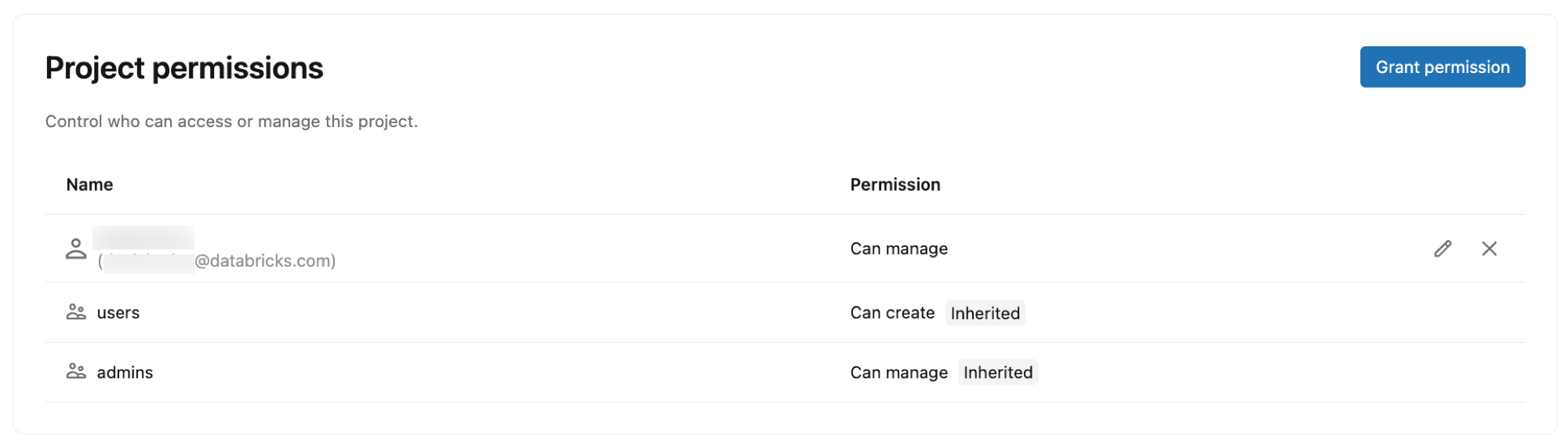
Izin proyek
Kontrol siapa yang dapat mengakses dan mengelola proyek Lakebase Anda dengan memberikan izin untuk Azure Databricks identitas, grup, dan perwakilan layanan. Project izin menentukan tindakan apa yang dapat dilakukan pengguna dalam project, seperti membuat cabang, mengelola komputasi, dan melihat detail koneksi.
Jenis izin:
- CAN CREATE: Menampilkan dan membuat sumber daya proyek
- CAN USE: Melihat dan menggunakan sumber daya proyek (mencantumkan, melihat, menyambungkan, dan melakukan operasi cabang tertentu) tanpa membuat atau menghapus proyek atau cabang
- DAPAT MENGELOLA: Kontrol penuh atas konfigurasi proyek dan sumber daya
Izin default:
Saat Anda membuat proyek, izin berikut secara otomatis ditetapkan:
- Pemilik proyek (pengguna yang membuat proyek): DAPAT MENGELOLA (kontrol penuh)
- Pengguna ruang kerja: DAPAT MEMBUAT (dapat melihat dan membuat proyek)
- Admin ruang kerja: DAPAT MENGELOLA (kontrol penuh)
Untuk memberikan akses ke pengguna lain, lihat Mengelola izin proyek.
Nota
Izin Project dan akses database adalah dua hal yang terpisah
Izin proyek mengontrol aksi pada platform Lakebase, sementara akses database dikontrol oleh peran Postgres dan izin terkait. Lihat Membuat peran Postgres dan Mengelola izin database.
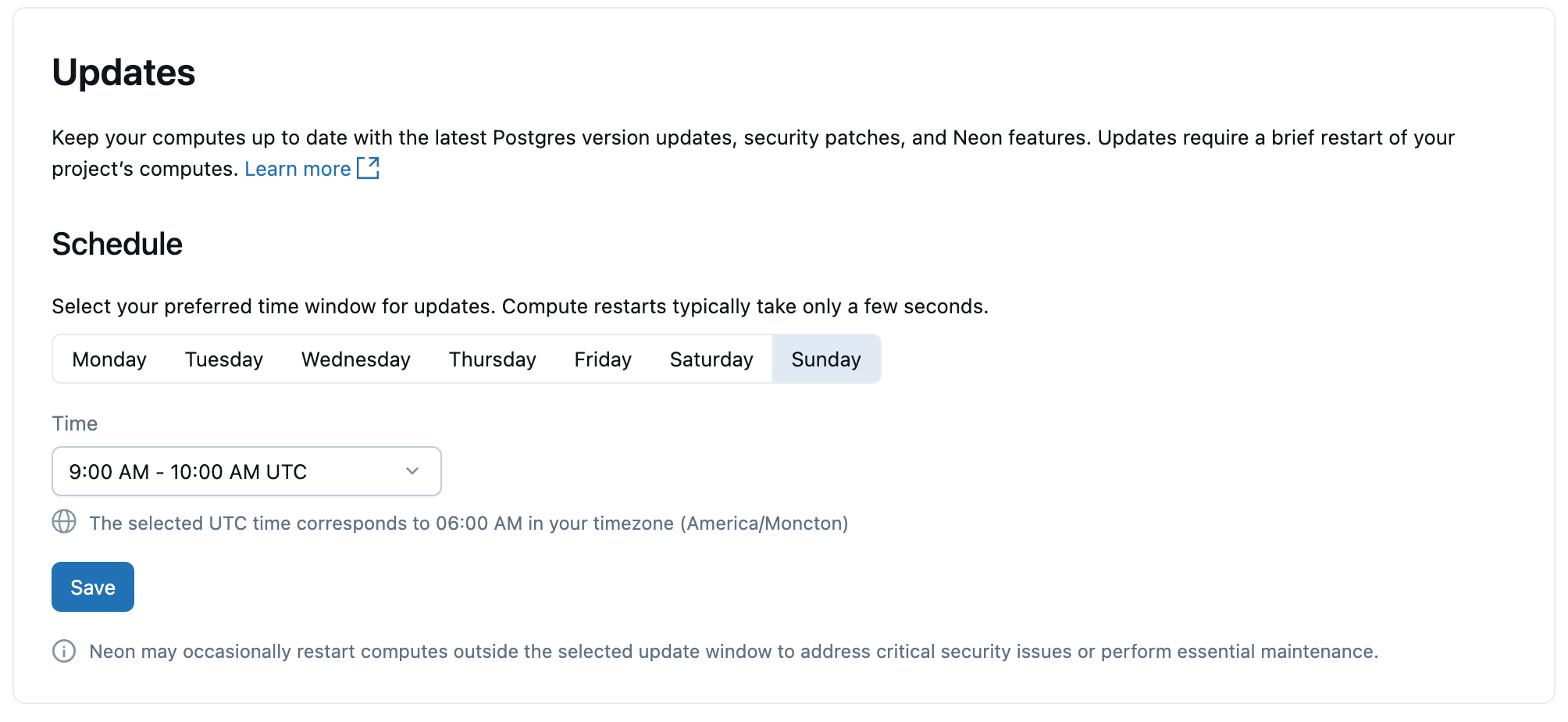
Pembaruan
Untuk menjaga komputasi Lakebase dan instans Postgres Anda tetap terbarui, Lakebase secara otomatis menerapkan pembaruan terjadwal yang mencakup peningkatan versi minor Postgres, patch keamanan, dan fitur platform. Pembaruan diterapkan ke komputasi dalam proyek Anda dan memerlukan mulai ulang komputasi singkat yang membutuhkan waktu beberapa detik.
Pembaruan diterapkan secara otomatis, tetapi Anda dapat mengatur hari dan waktu pilihan untuk pembaruan. Mulai ulang terjadi dalam jendela waktu yang Anda pilih.
Untuk informasi mendetail tentang pembaruan, lihat Mengelola pembaruan.
Menghapus proyek
Menghapus proyek adalah tindakan permanen yang juga menghapus komputasi, cabang, database, peran, dan data apa pun yang termasuk dalam proyek.
Penting
Tindakan ini tidak dapat dibatalkan. Berhati-hatilah saat menghapus proyek, karena melakukannya akan menghapus semua cabang dan data terkait.
Sebelum menghapus
Databricks merekomendasikan untuk menghapus semua katalog Unity Catalog terkait dan tabel yang disinkronkan sebelum menghapus proyek. Jika tidak, mencoba melihat katalog atau menjalankan kueri SQL yang mereferensikannya menghasilkan kesalahan.
Jika Anda bukan pemilik tabel atau katalog, Anda harus menetapkan ulang kepemilikan kepada diri Anda sendiri sebelum penghapusan.
Nota
Hanya pengguna dengan izin CAN MANAGE pada proyek Lakebase yang dapat menghapusnya. Lihat Project ACL dan Kelola izin project untuk detailnya.
Menghapus proyek
Untuk menghapus proyek:
Antarmuka Pengguna
- Buka Pengaturan proyek Anda di Aplikasi Lakebase.
- Di bagian Hapus proyek , klik Hapus dan masukkan nama proyek untuk mengonfirmasi penghapusan.
Python SDK
from databricks.sdk import WorkspaceClient
w = WorkspaceClient()
# Delete a project
operation = w.postgres.delete_project(name="projects/my-project")
print(f"Delete operation started: {operation.name()}")
Ini adalah operasi jangka panjang. Proyek dan semua sumber dayanya (cabang, titik akhir, database, peran, data) akan dihapus.
Java SDK
import com.databricks.sdk.WorkspaceClient;
WorkspaceClient w = new WorkspaceClient();
// Delete a project
w.postgres().deleteProject("projects/my-project");
System.out.println("Delete operation started");
Ini adalah operasi jangka panjang. Proyek dan semua sumber dayanya (cabang, titik akhir, database, peran, data) akan dihapus.
antarmuka baris perintah (CLI)
# Delete a project
databricks postgres delete-project projects/my-project
Perintah ini menghasilkan respons seketika. Proyek dan semua sumber dayanya akan dihapus.
melengkung
curl -X DELETE "$WORKSPACE/api/2.0/postgres/projects/my-project" \
-H "Authorization: Bearer ${DATABRICKS_TOKEN}" | jq
Ini adalah operasi jangka panjang. Respons menyertakan nama operasi yang dapat Anda gunakan untuk memeriksa status penghapusan.