Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Lakebase Autoscaling adalah versi terbaru Lakebase, dengan komputasi penskalaan otomatis, skala-ke-nol, percabangan, dan pemulihan instan. Untuk wilayah yang didukung, lihat Ketersediaan wilayah. Jika Anda adalah pengguna Lakebase Provisioned, lihat Lakebase Provisioned.
Pada akhir panduan ini, Anda akan memiliki database Postgres yang sedang berjalan dengan data sampel, terhubung ke Unity Catalog, dengan data yang mengalir antara Lakebase dan databricks lakehouse.
Langkah-langkah: (1) Membuat proyek → (2) Menyambungkan → (3) Membuat tabel → (4) Mendaftar di Unity Catalog → (5) Melayani data
Langkah 1: Buat proyek pertama Anda
Buka Aplikasi Lakebase dari pengalih aplikasi.
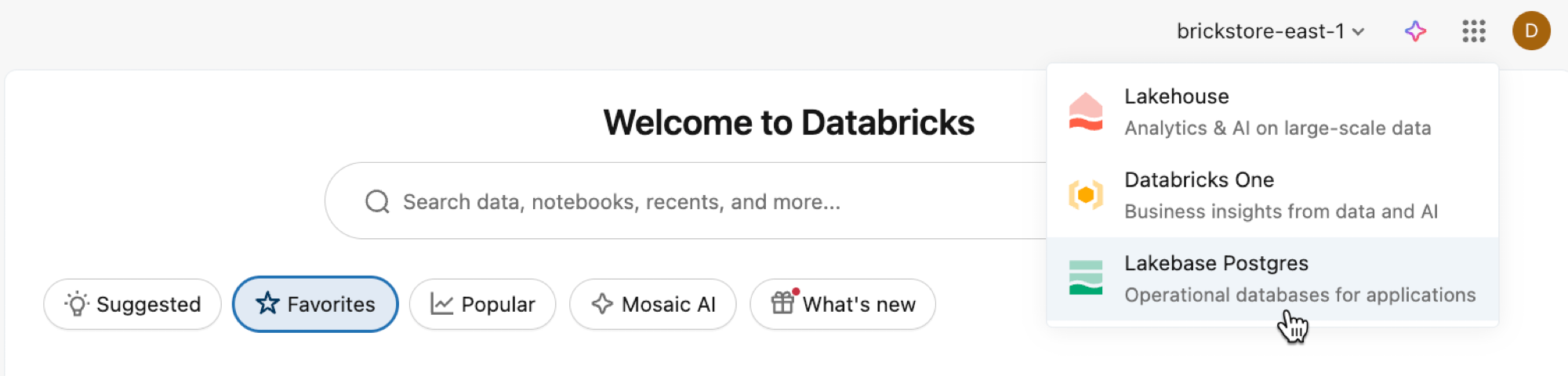
Pilih Autoscaling untuk mengakses UI Lakebase Autoscaling.
Klik Proyek baru. Beri nama proyek Anda dan pilih versi Postgres Anda. Proyek Anda dibuat dengan satu production cabang, database default databricks_postgres , dan sumber daya komputasi yang dikonfigurasi untuk cabang.
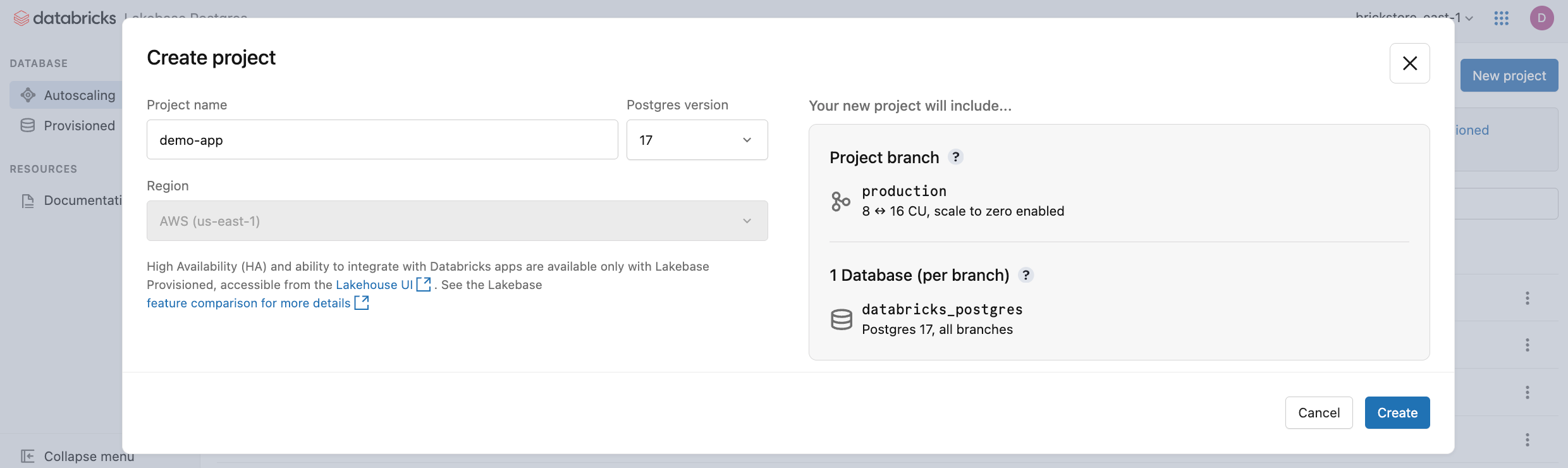
Mungkin perlu beberapa saat agar komputasi Anda diaktifkan. Komputasi untuk production cabang selalu aktif secara default (skala-ke-nol dinonaktifkan), tetapi Anda dapat mengonfigurasi pengaturan ini jika diperlukan.
Wilayah untuk proyek Anda secara otomatis diatur ke wilayah ruang kerja Anda.
Pelajari lebih lanjut: Membuat Proyek | Penskalaan Otomatis | Skalakan ke nol
Langkah 2: Menyambungkan ke database Anda
Dari proyek Anda, pilih cabang produksi dan klik Sambungkan. String koneksi berfungsi dengan klien Postgres standar apa pun (psql, pgAdmin, DBeaver, atau kerangka kerja aplikasi).
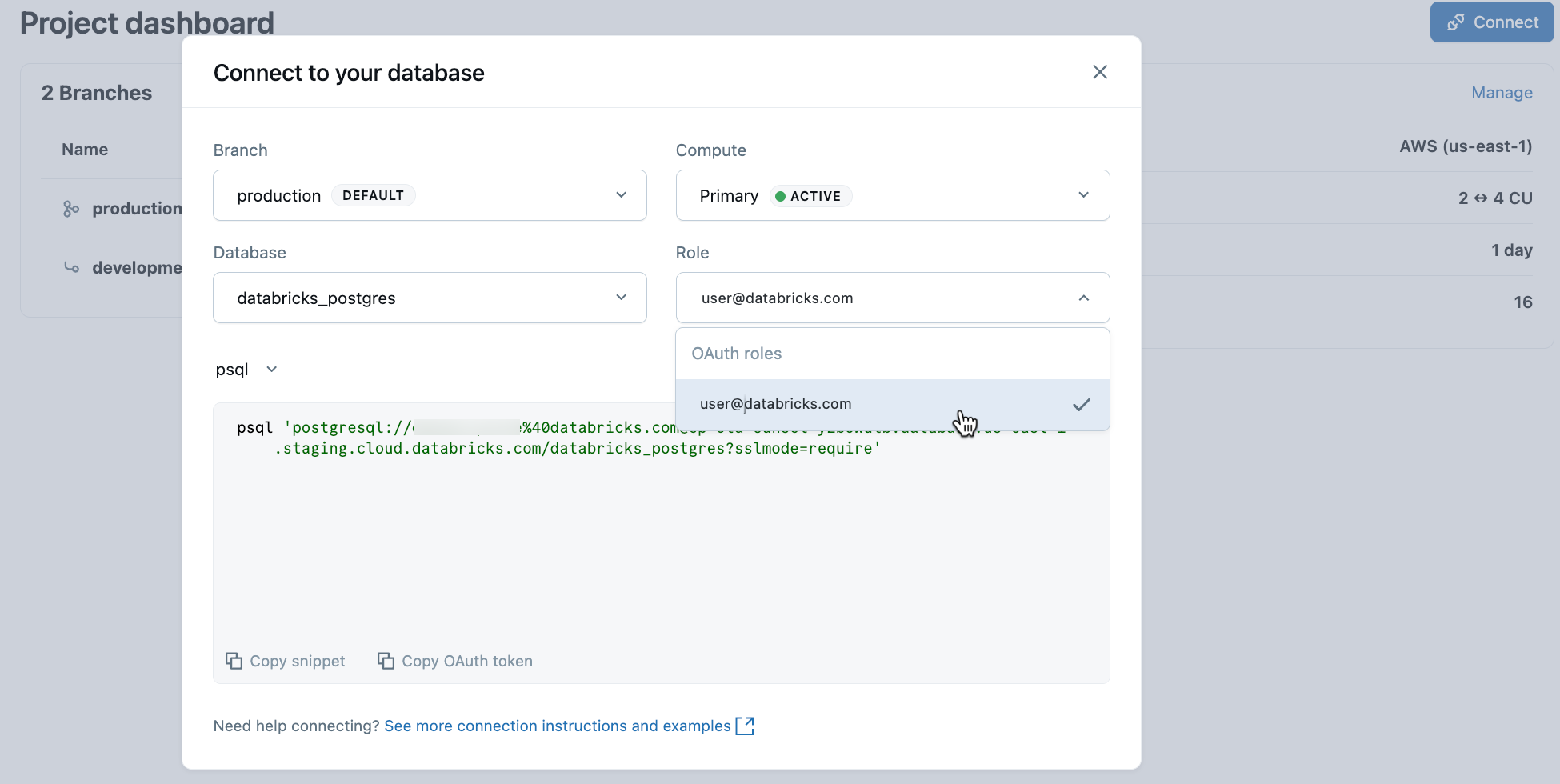
Untuk terhubung dengan identitas Databricks Anda, salin psql cuplikan dari dialog koneksi dan tempelkan token OAuth saat diminta:
psql 'postgresql://your-email@databricks.com@ep-abc-123.databricks.com/databricks_postgres?sslmode=require'
Pelajari lebih lanjut: Panduan cepat koneksi | psql | pgAdmin | klien Postgres
Langkah 3: Buat tabel pertama Anda
Editor Lakebase SQL dilengkapi dengan sampel SQL. Dari proyek Anda, pilih cabang produksi , buka Editor SQL, dan jalankan pernyataan yang disediakan untuk membuat playing_with_lakebase tabel dan menyisipkan data sampel.
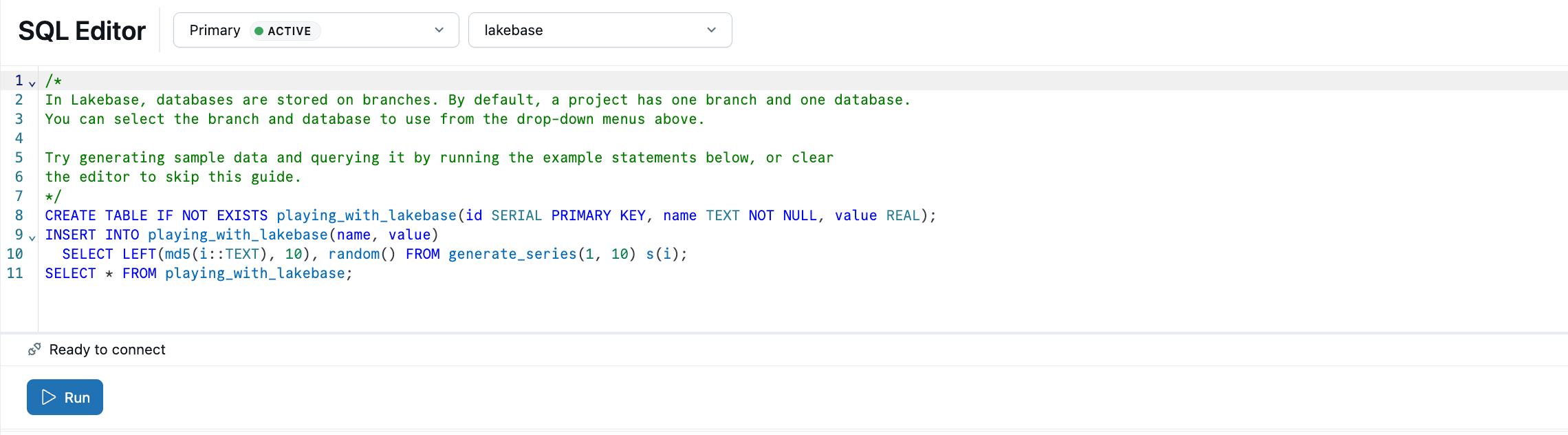
Pelajari lebih lanjut: Editor SQL | Editor Tabel | Klien Postgres
Langkah 4: Daftar di Katalog Unity
Database Lakebase Anda berjalan, tetapi tidak terlihat oleh platform Databricks lainnya sampai Anda mendaftarkannya di Unity Catalog. Setelah terdaftar, Anda dapat mengkueri tabel Lakebase dari Databricks SQL, menggabungkan data operasional dengan analitik lakehouse, dan menerapkan tata kelola terpadu.
Di Catalog Explorer, buat katalog baru dengan Lakebase Autoscaling sebagai jenisnya, menunjuk ke cabang production dan database databricks_postgres proyek Anda.
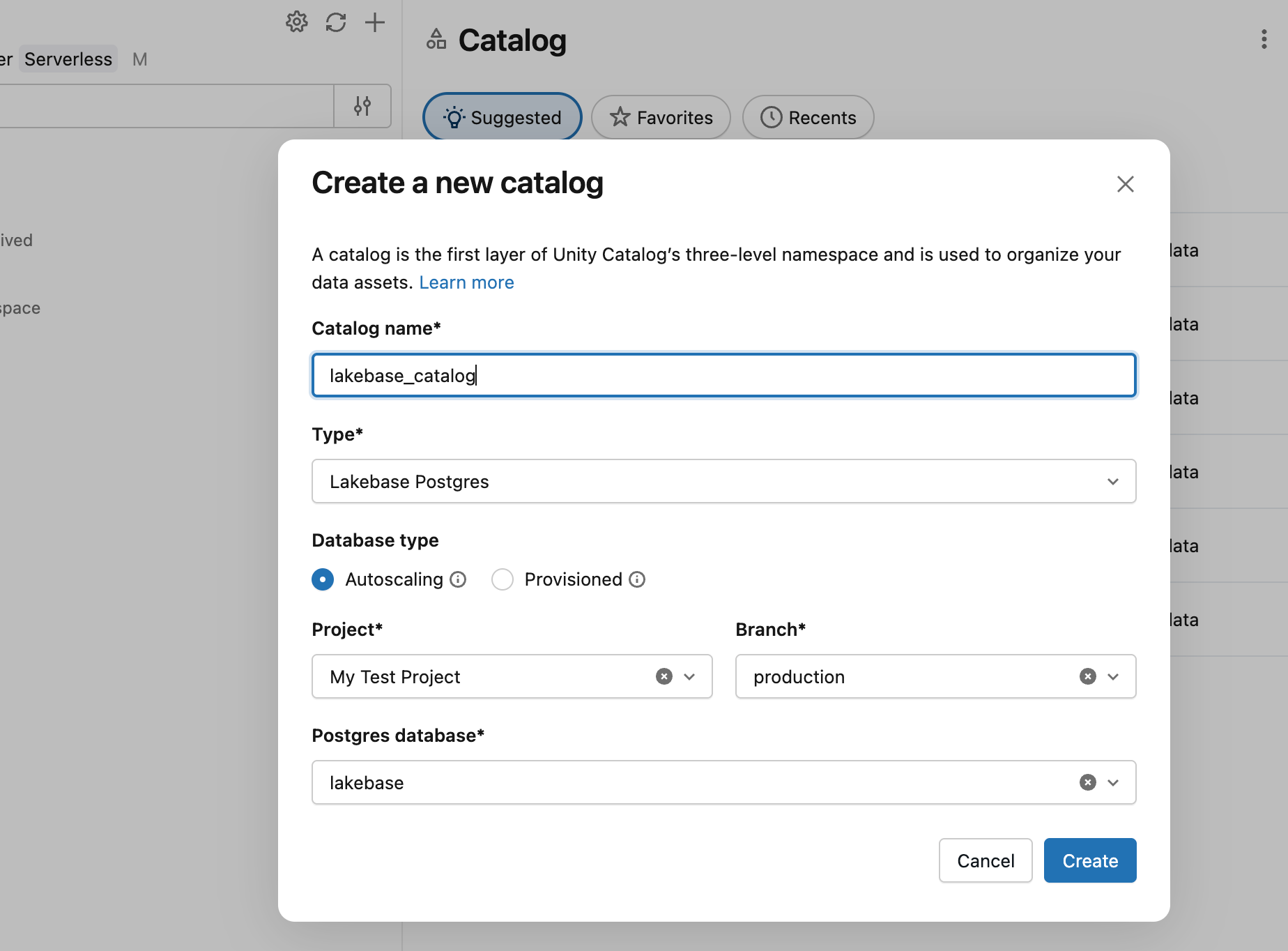
Sekarang Anda dapat mengkueri dari gudang SQL:
SELECT * FROM lakebase_catalog.public.playing_with_lakebase;
Pelajari lebih lanjut: Mendaftar di Unity Catalog
Langkah 5: Melayani data lakehouse di aplikasi Anda
Tabel yang disinkronkan membawa data analitik dari Unity Catalog ke database Lakebase Anda sehingga aplikasi dapat mengkuerinya dengan pembacaan transaksi latensi rendah. Buat contoh tabel Unity Catalog, lalu sinkronkan ke Lakebase.
Di gudang atau buku catatan SQL, buat tabel sumber:
CREATE TABLE main.default.user_segments AS
SELECT * FROM VALUES
(1001, 'premium', 2500.00, 'high'),
(1002, 'standard', 450.00, 'medium'),
(1003, 'premium', 3200.00, 'high'),
(1004, 'basic', 120.00, 'low')
AS segments(user_id, tier, lifetime_value, engagement);
Sekarang sinkronkan tabel ini ke Lakebase. Di Catalog Explorer, buat tabel yang disinkronkan dari user_segments dengan mode Snapshot , yang menargetkan database proyek databricks_postgres Anda. Mode cuplikan menyalin data satu kali. Untuk pembaruan berkelanjutan, gunakan mode Dipicu atau Berkelanjutan.
Setelah sinkronisasi selesai, data tersedia di Lakebase sebagai default.user_segments_synced. Kuerikan di Editor Lakebase SQL:
SELECT * FROM "default".user_segments_synced WHERE engagement = 'high';
Nota
default harus dikutip karena merupakan kata kunci cadangan PostgreSQL. Skema tabel yang disinkronkan mewarisi nama skema Katalog Unity, jadi jika skema Anda diberi nama default, Anda harus selalu mengutipnya dalam kueri. Kutipan di sekitar pengidentifikasi lain bersifat opsional.
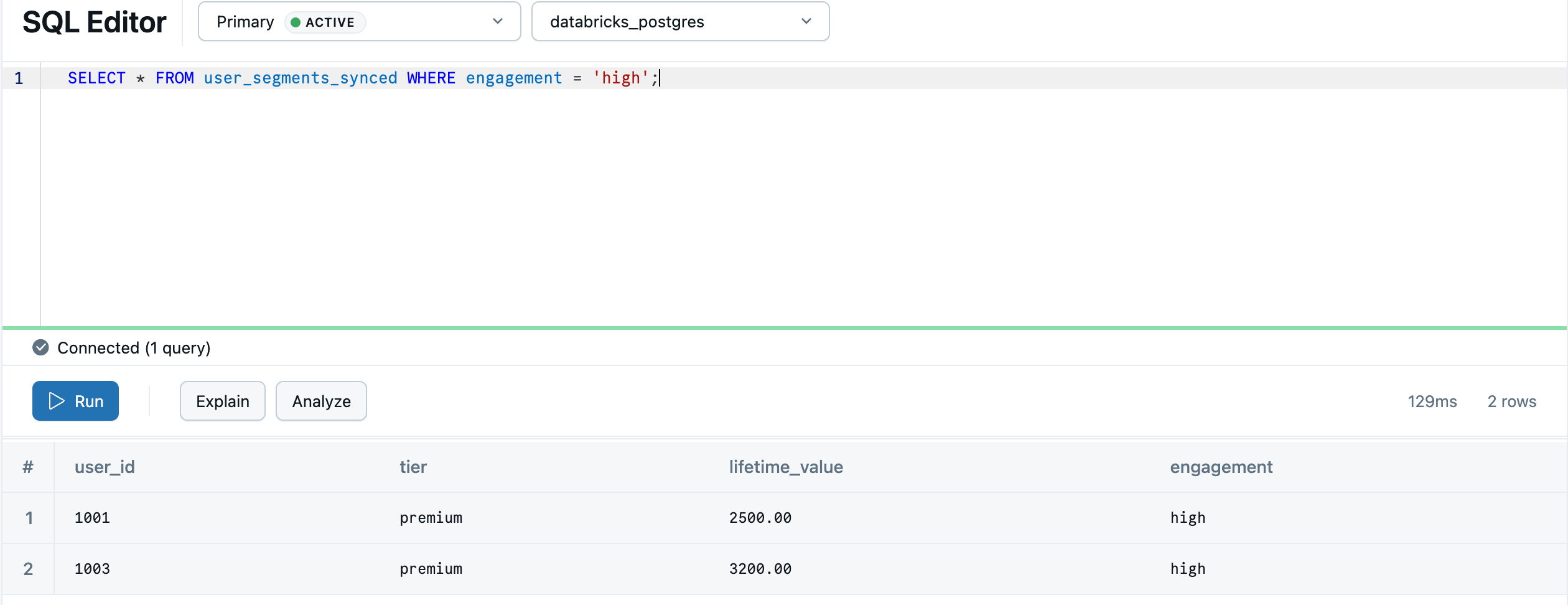
Analitik lakehouse Anda sekarang siap untuk dilayani dari database transaksi anda.
Pelajari lebih lanjut:Pemetaan tipe Data mode Sinkronisasi | |
Langkah selanjutnya
- Membuat aplikasi:Aplikasi Databricks tutorial | Aplikasi eksternal
- Pengembangan dengan cabang:Tutorial pengembangan berbasis cabang
- Menyiapkan tim Anda:Memberikan proyek dan akses database
- Jelajahi platform:Konsep inti | Ikhtisar proyek | Semua tutorial