Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Catatan
Rekomendasi penyetelan manual dalam artikel ini tidak berlaku untuk tabel terkelola Katalog Unity, yang menggunakan penyetelan ukuran file otomatis. Untuk tabel baru, gunakan tabel terkelola Unity Catalog dengan pengaturan default.
Di Databricks Runtime 13.3 ke atas, Databricks merekomendasikan penggunaan pengklusteran untuk tata letak tabel. Lihat Menggunakan pengklusteran cair untuk tabel.
Databricks merekomendasikan penggunaan pengoptimalan prediktif untuk menjalankan OPTIMIZE dan VACUUM untuk tabel secara otomatis. Lihat Pengoptimalan prediktif untuk tabel yang dikelola oleh Unity Catalog.
Dalam Databricks Runtime 10.4 LTS dan versi yang lebih baru, pemadatan otomatis dan penulisan yang dioptimalkan selalu diaktifkan untuk MERGE, UPDATE, dan DELETE operasi. Anda tidak dapat menonaktifkan fungsionalitas ini.
Ada opsi untuk mengonfigurasi ukuran file target secara manual atau otomatis untuk penulisan dan operasi OPTIMIZE. Azure Databricks secara otomatis menyetel banyak pengaturan ini, dan memungkinkan fitur yang secara otomatis meningkatkan performa tabel dengan mencari file dengan ukuran yang tepat.
Untuk tabel terkelola Unity Catalog, Databricks menyetel sebagian besar konfigurasi ini secara otomatis jika Anda menggunakan gudang SQL atau Databricks Runtime 11.3 LTS atau lebih tinggi.
Jika Anda memperbarui beban kerja dari Databricks Runtime 10.4 LTS atau di bawahnya, lihat Beralih ke pemadatan otomatis latar belakang.
Kapan menjalankan OPTIMIZE
Pemadatan otomatis dan penulisan yang dioptimalkan masing-masing mengurangi masalah file kecil, tetapi bukan pengganti penuh untuk OPTIMIZE. Khusus untuk tabel yang lebih besar dari 1 TB, Databricks merekomendasikan untuk berjalan OPTIMIZE sesuai jadwal untuk mengonsolidasikan file lebih lanjut. Databricks merekomendasikan "liquid clustering" untuk meningkatkan kemampuan pengelompokan data. Saat pengklusteran cair diaktifkan, OPTIMIZE secara otomatis mengatur ulang data oleh kunci pengklusteran. Lihat Menggunakan pengklusteran cair untuk tabel.
Untuk tabel terkelola Unity Catalog, pengoptimalan prediktif secara otomatis berjalan OPTIMIZE pada tabel dengan pengoptimalan prediktif diaktifkan.
Apa itu pengoptimalan otomatis pada Azure Databricks?
Istilah pengoptimalan otomatis terkadang digunakan untuk menjelaskan fungsionalitas yang dikontrol oleh pengaturan autoOptimize.autoCompact dan autoOptimize.optimizeWrite. Istilah ini telah dihentikan demi menjelaskan setiap pengaturan satu per satu. Lihat Pemadatan otomatis dan Penulisan yang dioptimalkan.
Pemadatan otomatis
Pemadatan otomatis menggabungkan file kecil dalam partisi tabel untuk mengurangi masalah file kecil. Ini berjalan secara sinkron pada kluster yang melakukan penulisan, setelah penulisan berhasil, dan hanya memadatkan file yang belum dikompresi sebelumnya.
Pemadatan otomatis dan pengoptimalan prediktif adalah fitur independen yang dapat digunakan secara terpisah atau bersama-sama. Pemadatan otomatis berjalan pada kluster yang melakukan penulisan, sementara pengoptimalan prediktif menjalankan operasi pemeliharaan secara asinkron menggunakan komputasi tanpa server.
Gunakan pengaturan berikut untuk mengonfigurasi pemadatan otomatis:
| Setting | Delta | Iceberg | Description |
|---|---|---|---|
| Aktifkan pemadatan otomatis (properti tabel) | autoOptimize.autoCompact |
autoOptimize.autoCompact |
Mengaktifkan pemadatan otomatis pada tingkat tabel. |
| Mengaktifkan pemadatan otomatis (sesi Spark) | spark.databricks.delta.autoCompact.enabled |
spark.databricks.iceberg.autoCompact.enabled |
Mengaktifkan pemadatan otomatis pada tingkat sesi. |
| Ukuran file output maksimum | spark.databricks.delta.autoCompact.maxFileSize |
spark.databricks.iceberg.autoCompact.maxFileSize |
Mengontrol ukuran file output target. |
| Jumlah file minimum untuk memicu pemadatan | spark.databricks.delta.autoCompact.minNumFiles |
spark.databricks.iceberg.autoCompact.minNumFiles |
Mengatur jumlah minimum file kecil yang diperlukan dalam partisi atau tabel untuk memicu pemadatan otomatis. |
Pengaturan ini menerima opsi berikut:
| Opsi | Perilaku |
|---|---|
auto (disarankan) |
Menyetel ukuran file target sambil menghormati fungsionalitas penyetelan otomatis lainnya. Memerlukan Databricks Runtime 10.4 LTS atau lebih tinggi. |
legacy |
Alias untuk true. Memerlukan Databricks Runtime 10.4 LTS atau lebih tinggi. |
true |
Gunakan 128 MB sebagai ukuran file target. Tidak ada ukuran dinamis. |
false |
Menonaktifkan pemadatan otomatis. Dapat diatur pada tingkat sesi untuk mengesampingkan pemadatan otomatis untuk semua tabel yang dimodifikasi dalam beban kerja. |
Catatan
Azure Databricks merekomendasikan penggunaan penyetelan otomatis untuk mengontrol ukuran file output berdasarkan ukuran tabel. Lihat Ukuran file Autotune berdasarkan ukuran tabel.
Penulisan yang dioptimalkan
Optimalisasi penulisan mengurangi ukuran file saat data ditulis dan meningkatkan keuntungan dari pembacaan berikutnya pada tabel.
Penulisan yang dioptimalkan paling efektif untuk tabel yang dipartisi, karena mengurangi jumlah file kecil yang ditulis ke setiap partisi. Menulis lebih sedikit file besar lebih efisien daripada menulis banyak file kecil, tetapi Anda mungkin masih melihat peningkatan latensi tulis karena data diacak sebelum ditulis.
Gambar berikut menunjukkan cara kerja penulisan yang dioptimalkan:
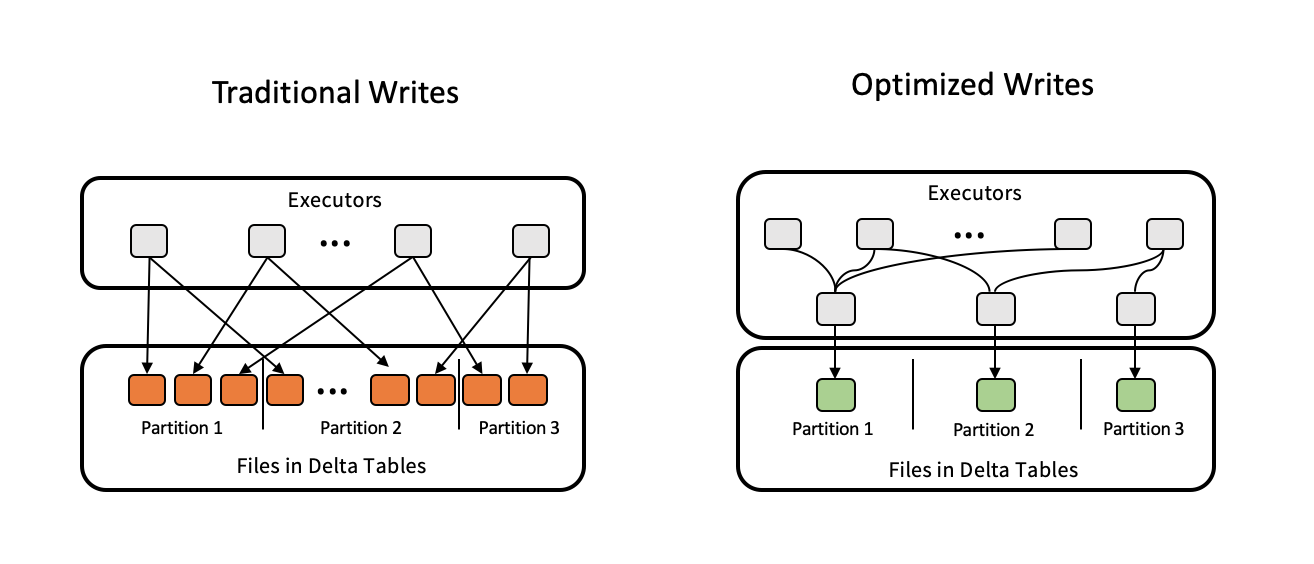
Catatan
Anda mungkin memiliki kode yang berjalan coalesce(n) atau repartition(n) tepat sebelum menulis data Anda untuk mengontrol jumlah file yang ditulis. Penulisan yang dioptimalkan menghilangkan kebutuhan untuk menggunakan pola ini.
Penulisan yang dioptimalkan diaktifkan secara default untuk operasi berikut di Databricks Runtime 9.1 LTS ke atas:
MERGE-
UPDATEdengan subkueri -
DELETEdengan subkueri
Penulisan yang dioptimalkan juga diaktifkan untuk CTAS pernyataan dan INSERT operasi saat menggunakan gudang SQL. Dalam Databricks Runtime 13.3 LTS ke atas, semua tabel yang terdaftar di Unity Catalog telah mengoptimalkan penulisan yang diaktifkan untuk CTAS pernyataan dan INSERT operasi untuk tabel yang dipartisi.
Penulisan yang dioptimalkan dapat diaktifkan pada tingkat tabel atau sesi menggunakan pengaturan berikut:
- Properti tabel:
autoOptimize.optimizeWrite - Pengaturan SparkSession:
spark.databricks.delta.optimizeWrite.enabled(Delta) atauspark.databricks.iceberg.optimizeWrite.enabled(Iceberg)
Pengaturan ini menerima opsi berikut:
| Opsi | Perilaku |
|---|---|
true |
Gunakan 128 MB sebagai ukuran file target. |
false |
Menonaktifkan penulisan yang dioptimalkan. Dapat diatur pada tingkat sesi untuk mengesampingkan pemadatan otomatis untuk semua tabel yang dimodifikasi dalam beban kerja. |
Mengatur ukuran file target
Jika Anda ingin menyetel ukuran file dalam tabel Anda, atur propertitargetFileSize tabel ke ukuran yang diinginkan. Ketika diatur, semua operasi pengoptimalan tata letak data melakukan upaya terbaik untuk menghasilkan file dengan ukuran yang ditentukan, termasuk pengoptimalan, pengklusteran cairan, pemadatan otomatis, dan penulisan yang dioptimalkan.
Catatan
Saat menggunakan tabel terkelola Unity Catalog dan gudang SQL atau Databricks Runtime 11.3 LTS ke atas, hanya OPTIMIZE perintah yang targetFileSize menghormati pengaturan.
| Harta benda | Description |
|---|---|
delta.targetFileSize (Delta)iceberg.targetFileSize (Gunung Es) |
Jenis: Ukuran dalam byte atau unit yang lebih tinggi. Deskripsi: Ukuran file target. Misalnya, 104857600 (byte) atau 100mb.Nilai default: Tidak ada |
Untuk tabel yang sudah ada, Anda dapat mengatur dan membatalkan properti menggunakan perintah SQL ALTER TABLESET PROPERTI TBL. Anda juga dapat mengatur properti ini secara otomatis saat membuat tabel baru menggunakan konfigurasi sesi Spark. Lihat Referensi properti tabel untuk detailnya.
Menyetel otomatis ukuran file berdasarkan ukuran tabel
Untuk meminimalkan kebutuhan penyetelan manual, Azure Databricks secara otomatis menyetel ukuran file tabel berdasarkan ukuran tabel. Azure Databricks menggunakan ukuran file yang lebih kecil untuk tabel yang lebih kecil dan ukuran file yang lebih besar untuk tabel yang lebih besar sehingga jumlah file dalam tabel tidak tumbuh terlalu besar. Azure Databricks tidak menyetel secara otomatis tabel yang telah Anda sesuaikan dengan ukuran target tertentu.
Ukuran file target didasarkan pada ukuran tabel saat ini. Untuk tabel yang lebih kecil dari 2,56 TB, ukuran file target yang diatur otomatis adalah 256 MB. Untuk tabel dengan ukuran antara 2,56 TB serta 10 TB, ukuran target akan tumbuh secara linier dari 256 MB menjadi 1 GB. Untuk tabel yang lebih besar dari 10 TB, ukuran file target adalah sebesar 1 GB.
Catatan
Ketika ukuran file target untuk tabel tumbuh, file yang ada tidak dioptimalkan kembali menjadi file yang lebih besar oleh perintah OPTIMIZE. Oleh karena itu, tabel besar selalu dapat memiliki beberapa file yang lebih kecil dari ukuran target. Jika diperlukan untuk mengoptimalkan file yang lebih kecil menjadi file yang lebih besar juga, Anda dapat mengonfigurasi ukuran file target tetap untuk tabel menggunakan properti tabel targetFileSize.
Ketika tabel ditulis secara bertahap, ukuran file target serta jumlah file akan menjadi kurang lebih seperti berikut berdasarkan ukuran tabel. Jumlah file dalam tabel ini hanyalah sebuah contoh. Hasil aktual akan berbeda tergantung pada banyak faktor.
| Ukuran tabel | Ukuran file target | Perkiraan jumlah file dalam tabel |
|---|---|---|
| 10 GB | 256 MB | 40 |
| 1 Terabyte (TB) | 256 MB | 4096 |
| 2,56 TB | 256 MB | 10240 |
| 3 Terabita | 307 MB | 12108 |
| 5 Terabita (TB) | 512 MB | 17339 |
| 7 TB | 716 MB | 20784 |
| 10 Terabyte | 1 GB | 24437 |
| 20 TB | 1 GB | 34437 |
| 50 TB | 1 GB | 64437 |
| 100 TB | 1 GB | 114437 |
Membatasi baris yang ditulis dalam file data
Terkadang, tabel dengan data sempit mungkin mengalami kesalahan di mana jumlah baris dalam file data tertentu melebihi batas dukungan format Parquet. Untuk menghindari kesalahan ini, Anda dapat menggunakan konfigurasi spark.sql.files.maxRecordsPerFile sesi SQL untuk menentukan jumlah maksimum rekaman yang akan ditulis ke satu file untuk tabel. Menentukan nilai nol atau nilai negatif tidak menunjukkan batas.
Di Databricks Runtime 11.3 LTS ke atas, Anda juga dapat menggunakan opsi maxRecordsPerFile DataFrameWriter saat menggunakan API DataFrame untuk menulis ke tabel. Ketika maxRecordsPerFile ditentukan, nilai konfigurasi sesi SQL spark.sql.files.maxRecordsPerFile diabaikan.
Catatan
Databricks tidak merekomendasikan penggunaan opsi ini kecuali perlu untuk menghindari kesalahan yang disebutkan di atas. Pengaturan ini mungkin masih diperlukan untuk beberapa tabel terkelola Unity Catalog dengan data yang sangat sempit.
Tingkatkan ke pemadatan otomatis di latar belakang
Pemadatan otomatis latar belakang tersedia untuk tabel terkelola Unity Catalog di Databricks Runtime 11.3 LTS ke atas. Pemadatan otomatis latar belakang tidak memerlukan pengoptimalan prediktif. Saat memigrasikan beban kerja atau tabel warisan, lakukan hal berikut:
- Hapus konfigurasi
spark.databricks.delta.autoCompact.enabledSpark (Delta) atauspark.databricks.iceberg.autoCompact.enabled(Iceberg) dari pengaturan konfigurasi kluster atau notebook. - Untuk setiap tabel, jalankan
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)(Delta) atauALTER TABLE <table_name> UNSET TBLPROPERTIES (iceberg.autoOptimize.autoCompact)(Iceberg) untuk menghapus pengaturan pemadatan otomatis warisan apa pun.
Setelah menghapus konfigurasi warisan ini, Anda akan melihat pemadatan otomatis latar belakang yang dipicu secara otomatis untuk semua tabel terkelola Katalog Unity.