Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Halaman ini menjelaskan cara menggunakan tabel Delta sebagai sumber dan sink untuk Spark Structured Streaming dengan readStream dan writeStream. Delta Lake memecahkan masalah performa dan keandalan umum untuk sistem dan file streaming. Manfaatnya mencakup:
- Menggabungkan file kecil yang dihasilkan oleh penyerapan latensi rendah untuk meningkatkan performa.
- Pertahankan pemrosesan *"exactly-once"* dengan lebih dari satu aliran (atau pekerjaan batch yang berjalan secara bersamaan).
- Temukan file baru secara efisien saat menggunakan file sebagai sumber aliran.
Untuk mempelajari cara memuat data menggunakan tabel streaming di Databricks SQL, lihat Menggunakan tabel streaming di Databricks SQL.
Untuk gabungan antara streaming dan statis dengan Delta Lake, lihat Gabungan antara Streaming dan Statis.
Menggunakan tabel Delta sebagai sink
Anda dapat menulis data ke dalam tabel Delta menggunakan Streaming Terstruktur. Log transaksi Delta Lake menjamin eksekusi tepat satu kali, bahkan ketika ada aliran atau kueri batch lain yang berjalan bersamaan dalam tabel.
Saat Anda menulis ke tabel Delta menggunakan sink Structured Streaming, Anda mungkin melihat komit kosong dengan epochId = -1. Ini diharapkan dan biasanya terjadi:
- Pada batch pertama dari setiap eksekusi kueri streaming (ini terjadi setiap batch untuk
Trigger.AvailableNow). - Saat skema diubah (seperti menambahkan kolom).
Komit kosong ini disengaja dan tidak menunjukkan adanya kesalahan. Mereka tidak memengaruhi kebenaran atau performa kueri dengan cara yang signifikan.
Note
Fungsi Delta Lake VACUUM menghapus semua file yang tidak dikelola oleh Delta Lake tetapi melewati semua direktori yang dimulai dengan _. Anda dapat menyimpan titik pemeriksaan dengan aman bersama data dan metadata lain untuk tabel Delta menggunakan struktur direktori seperti <table-name>/_checkpoints.
Memantau backlog dengan metrik
Gunakan metrik berikut untuk memantau backlog proses kueri streaming:
-
numBytesOutstanding: Jumlah byte yang belum diproses di backlog. -
numFilesOutstanding: Jumlah file yang belum diproses di backlog. -
numNewListedFiles: Jumlah file Delta Lake yang tercantum untuk menghitung backlog untuk batch ini. -
backlogEndOffset: Versi tabel Delta yang digunakan untuk menghitung backlog.
Di buku catatan, tampilkan metrik ini di bawah tab Data Mentah di dasbor kemajuan kueri streaming:
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
Mode penambahan
Secara default, aliran berjalan dalam mode penambahan dan hanya menambahkan rekaman baru ke tabel.
toTable Gunakan metode toTable saat streaming ke tabel:
Python
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Mode lengkap
Gunakan Streaming Terstruktur dengan mode lengkap untuk mengganti seluruh tabel setelah setiap batch. Misalnya, Anda dapat terus memperbarui tabel ringkasan agregat peristiwa oleh pelanggan:
Python
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
Scala
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
Untuk aplikasi tanpa persyaratan latensi yang ketat, Anda dapat menghemat sumber daya dan biaya komputasi dengan pemicu satu kali seperti AvailableNow. Misalnya, gunakan pemicu ini untuk memperbarui tabel agregasi ringkasan pada jadwal tertentu, hanya memproses data baru yang telah tiba sejak pembaruan terakhir. Lihat AvailableNow: Pemrosesan batch bertahap.
Menangani perubahan pada tabel Delta sumber
Streaming Terstruktur secara bertahap membaca tabel Delta. Saat kueri streaming dibaca dari tabel Delta, rekaman baru diproses secara idempotensi saat versi tabel baru diterapkan ke tabel sumber. Streaming Terstruktur hanya menerima input tambahan dan melemparkan pengecualian jika ada modifikasi yang terjadi pada tabel Delta sumber. Misalnya, jika operasi UPDATE, DELETE, MERGE INTO, atau OVERWRITE memodifikasi tabel Delta sumber yang dibaca oleh kueri streaming, maka proses streaming tersebut gagal dengan kesalahan.
Ada empat pendekatan umum untuk menangani perubahan upstream pada tabel Delta sumber data, tergantung pada kasus penggunaan Anda. Tabel referensi dan detail pada masing-masing disediakan di bawah ini:
| Pendekatan | Pros | Cons |
|---|---|---|
skipChangeCommits |
Sederhana, tidak mengharuskan Anda menulis logika yang kompleks. Berguna untuk pemrosesan khusus tambahan di mana perubahan hulu ditangani secara terpisah, atau untuk menangani rekaman yang buruk untuk sementara. | Tidak menyebarluaskan perubahan dan hanya memproses penambahan. |
| Pembaruan penuh | Juga sederhana, tidak mengharuskan Anda menulis logika yang kompleks. Berguna untuk himpunan data kecil dengan perubahan hulu yang jarang terjadi. | Mahal untuk himpunan data besar. Memerlukan pemrosesan ulang semua tabel hilir. |
| Mengubah aliran data | Memproses semua jenis perubahan (menyisipkan, memperbarui, dan menghapus). Databricks merekomendasikan streaming dari aliran data CDC tabel Delta alih-alih langsung dari tabel jika memungkinkan. | Mengharuskan Anda menulis logika yang lebih kompleks untuk menangani setiap jenis perubahan. |
| Pandangan termaterialisasi | Alternatif sederhana untuk Streaming Terstruktur yang memiliki penyebaran perubahan otomatis. | Latensi yang lebih tinggi. Hanya tersedia di Lakeflow Spark Declarative Pipelines dan Databricks SQL. |
Lewati komit perubahan upstream dengan skipChangeCommits
Atur skipChangeCommits untuk mengabaikan transaksi yang menghapus atau memodifikasi catatan yang ada, dan hanya untuk memproses penambahan. Ini berguna ketika perubahan pada data yang ada tidak perlu disebarluaskan melalui aliran, atau ketika Anda lebih suka logika terpisah untuk menangani perubahan tersebut. Anda dapat mengaktifkan dan menonaktifkan skipChangeCommits jika Anda perlu mengabaikan perubahan satu kali untuk sementara waktu.
Databricks merekomendasikan penggunaan skipChangeCommits untuk sebagian besar beban kerja yang tidak menggunakan umpan data perubahan.
Python
(spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
)
Scala
spark.readStream
.option("skipChangeCommits", "true")
.table("source_table")
Important
Jika skema untuk tabel Delta berubah setelah pembacaan streaming dimulai terhadap tabel, kueri gagal. Untuk sebagian besar perubahan skema, Anda dapat memulai ulang stream untuk mengatasi ketidakcocokan skema dan melanjutkan pemrosesan.
Di Databricks Runtime 12.2 LTS dan di bawahnya, Anda tidak dapat melakukan streaming dari tabel Delta dengan pemetaan kolom diaktifkan yang telah mengalami evolusi skema non-aditif seperti mengganti nama atau menghilangkan kolom. Untuk detailnya, lihat Pemetaan kolom dan streaming.
Note
Di Databricks Runtime 12.2 LTS ke atas, skipChangeCommits menggantikan ignoreChanges. Di Databricks Runtime 11.3 LTS dan yang lebih rendah, ignoreChanges adalah satu-satunya opsi yang didukung. Lihat Opsi warisan: ignoreChanges untuk detailnya.
Opsi warisan: ignoreDeletes
ignoreDeletes adalah opsi warisan yang hanya menangani transaksi yang menghapus data pada batas partisi (yaitu, penurunan partisi penuh). Jika Anda perlu menangani penghapusan, pembaruan, atau modifikasi non-partisi lainnya, gunakan skipChangeCommits saja.
Python
(spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
)
Scala
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Opsi warisan: ignoreChanges
ignoreChanges tersedia di Databricks Runtime 11.3 LTS dan yang lebih rendah. Dalam Databricks Runtime 12.2 LTS ke atas, digantikan oleh skipChangeCommits.
Dengan ignoreChanges diaktifkan, file data yang ditulis ulang dalam tabel sumber dipancarkan kembali setelah operasi modifikasi data seperti UPDATE, , MERGE INTODELETE (dalam partisi), atau OVERWRITE. Baris yang tidak berubah sering dikeluarkan bersama dengan baris baru, jadi konsumen hilir harus dapat menangani duplikat. Penghapusan tidak diteruskan ke bagian berikutnya.
ignoreChanges lebih diutamakan daripada ignoreDeletes.
Sebaliknya, skipChangeCommits mengabaikan operasi pengubahan file sepenuhnya. Menulis ulang file data dalam tabel sumber karena operasi modifikasi data seperti UPDATE, , MERGE INTODELETE, dan OVERWRITE diabaikan sepenuhnya. Untuk mencerminkan perubahan dalam tabel sumber aliran, Anda harus menerapkan logika terpisah untuk menyebarluaskan perubahan ini.
Databricks merekomendasikan penggunaan skipChangeCommits untuk semua beban kerja baru. Untuk memigrasikan beban kerja dari ignoreChanges ke skipChangeCommits, refaktor logika streaming Anda.
Penyegaran penuh tabel downstream
Jika perubahan upstream jarang terjadi dan data cukup kecil untuk diolah ulang, Anda dapat menghapus titik pemeriksaan streaming dan tabel output, lalu memulai ulang aliran dari awal. Hal ini menyebabkan aliran memproses ulang semua data dari tabel sumber. Ketahuilah bahwa pendekatan ini juga memerlukan pemrosesan ulang semua tabel hilir yang bergantung pada output aliran ini.
Pendekatan ini paling cocok untuk himpunan data atau beban kerja yang lebih kecil di mana perubahan hulu jarang dan biaya refresh penuh dapat diterima.
Gunakan umpan data perubahan
Untuk beban kerja yang memproses semua jenis perubahan (sisipan, pembaruan, dan penghapusan), gunakan umpan data perubahan Delta Lake. Umpan data perubahan mencatat perubahan tingkat baris ke tabel Delta, memungkinkan Anda mengalirkan perubahan tersebut dan menulis logika untuk menangani setiap jenis perubahan dalam tabel hilir. Ini adalah pendekatan yang paling kuat karena kode Anda secara eksplisit menangani setiap jenis peristiwa perubahan. Lihat Gunakan umpan data perubahan Delta Lake pada Azure Databricks.
Jika Anda menggunakan Alur Deklaratif Lakeflow Spark, lihat API CDC OTOMATIS: Menyederhanakan perubahan pengambilan data dengan alur.
Important
Di Databricks Runtime 12.2 LTS dan di bawahnya, Anda tidak dapat melakukan streaming dari umpan data perubahan untuk tabel Delta dengan pemetaan kolom diaktifkan yang telah mengalami evolusi skema non-aditif, seperti mengganti nama atau menghilangkan kolom. Lihat Pemetaan kolom dan streaming.
Menggunakan tampilan materialisasi
Tampilan materialisasi secara otomatis menangani perubahan upstream dengan menghitung ulang hasil saat data sumber berubah. Jika Anda tidak memerlukan latensi serendah mungkin dan ingin menghindari pengelolaan kompleksitas streaming, tampilan materialisasi dapat menyederhanakan arsitektur Anda. Tampilan materialisasi tersedia di Alur Deklaratif Lakeflow Spark dan di Databricks SQL. Lihat Tampilan termaterialisasi.
Example
Misalnya, Anda memiliki user_events tabel dengan kolom date, user_email, dan action yang dipartisi oleh date. Anda perlu menghapus data dari tabel user_events karena alasan GDPR setelah melakukan streaming keluar dari tabel tersebut.
skipChangeCommits memungkinkan Anda menghapus data dalam beberapa partisi (dalam contoh ini, pemfilteran pada user_email). Gunakan sintaks berikut:
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
Jika Anda memperbarui user_email dengan pernyataan UPDATE, file yang berisi user_email yang dimaksud akan ditulis ulang. Gunakan skipChangeCommits untuk mengabaikan file data yang diubah.
Databricks merekomendasikan penggunaan skipChangeCommits alih-alih ignoreDeletes kecuali Anda yakin bahwa penghapusan selalu merupakan penurunan partisi penuh.
Gunakan foreachBatch untuk penulisan tabel idempogen
Note
Databricks merekomendasikan untuk mengonfigurasi penulisan streaming terpisah untuk setiap sink yang ingin Anda perbarui alih-alih menggunakan foreachBatch. Menulis ke beberapa sink dalam foreachBatch mengurangi paralelisasi dan meningkatkan latensi keseluruhan karena menulis ke beberapa tabel diserialisasikan dalam foreachBatch.
Tabel Delta mendukung opsi DataFrameWriter berikut untuk membuat penulisan ke beberapa tabel dalam foreachBatch menjadi idempoten:
-
txnAppId: String unik yang dapat Anda teruskan pada setiap penulisan DataFrame. Misalnya, Anda dapat menggunakan ID StreamingQuery sebagaitxnAppId.txnAppIddapat berupa string unik yang dihasilkan pengguna dan tidak harus terkait dengan ID aliran. -
txnVersion: Angka yang meningkat secara monoton yang berfungsi sebagai versi transaksi.
Delta Lake menggunakan txnAppId dan txnVersion untuk mengidentifikasi dan mengabaikan penulisan duplikat. Misalnya, setelah kegagalan mengganggu penulisan batch, Anda dapat menjalankan kembali batch dengan menggunakan txnAppId dan txnVersion yang sama untuk dengan benar mengidentifikasi dan mengabaikan duplikat. Lihat Gunakan foreachBatch untuk menulis ke sink data sembarang.
Warning
Jika Anda menghapus titik pemeriksaan streaming dan memulai ulang kueri dengan titik pemeriksaan baru, Anda harus menyediakan yang berbeda txnAppId. Titik pemeriksaan baru dimulai dengan ID batch .0 Delta Lake menggunakan ID batch dan txnAppId sebagai kunci unik, dan mengabaikan batch yang nilainya sudah pernah terlihat.
Contoh kode berikut menunjukkan pola ini:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
Upsert dari kueri streaming dengan menggunakan foreachBatch
Anda dapat menggunakan merge dan foreachBatch untuk menulis upsert kompleks dari kueri streaming ke dalam tabel Delta. Lihat Gunakan foreachBatch untuk menulis ke sink data sembarang.
Pendekatan ini memiliki banyak aplikasi:
- Meningkatkan performa tulis dengan
updatemode output, sedangkancompletemode output memerlukan penulisan ulang seluruh tabel hasil untuk setiap mikrobatch. - Terus menerapkan aliran perubahan ke tabel Delta dengan menggunakan kueri penggabungan untuk menulis perubahan data di
foreachBatch. Lihat Data yang Berubah Perlahan (SCD) dan Pengambilan Data Berubah (CDC) dengan Delta Lake. - Menangani deduplikasi selama pemrosesan aliran. Anda bisa menggunakan kueri penggabungan khusus sisipan untuk
foreachBatchterus menulis data ke tabel Delta dengan deduplikasi otomatis. Lihat Deduplikasi data saat menulis ke dalam tabel Delta.
Note
Verifikasi bahwa pernyataan Anda
mergedi dalamforeachBatchbersifat idempoten. Jika tidak, menghidupkan ulang kueri streaming dapat menerapkan operasi pada batch data yang sama beberapa kali. Lihat GunakanforeachBatchuntuk penulisan tabel idempoten.Ketika
mergedigunakan dalamforeachBatch, metrik laju data input mungkin mengembalikan kelipatan laju aktual yang dihasilkan data di sumbernya.mergemembaca data input berulang kali, yang menyebabkan perkalian pada metrik. Untuk mencegah perkalian metrik, cache DataFrame batch sebelummergedan kemudian hapus cache setelahmerge.Laju data input tersedia melalui
StreamingQueryProgressdan dalam grafik laju streaming notebook. Lihat Monitoring Kueri Streaming Terstruktur pada Azure Databricks.
Misalnya, Anda dapat menggunakan MERGE pernyataan SQL dalam foreachBatch:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Anda juga dapat menggunakan API Delta Lake untuk upsert streaming:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Mengatur versi tabel awal untuk memproses perubahan
Secara default, aliran dimulai dengan versi tabel Delta terbaru yang tersedia. Ini termasuk rekam jepret lengkap tabel pada saat itu dan semua perubahan di masa mendatang. Databricks merekomendasikan agar Anda menggunakan versi tabel awal default untuk sebagian besar beban kerja.
Secara opsional, Anda dapat menggunakan opsi berikut untuk menentukan titik awal sumber streaming Delta Lake tanpa memproses seluruh tabel.
startingVersion: Versi tabel Delta untuk mulai membaca. Semua perubahan tabel yang dilakukan pada atau setelah versi yang ditentukan dibaca oleh aliran. Jika versi yang ditentukan tidak tersedia, aliran gagal dimulai.Untuk menemukan versi commit yang tersedia, jalankan
DESCRIBE HISTORYdan periksaversion. Untuk mengembalikan hanya perubahan terbaru, tentukanlatest. Untuk informasi tentang versi tabel Delta, lihat Bekerja dengan riwayat tabel.startingTimestamp: Penanda waktu untuk mulai membaca dari. Semua perubahan tabel yang dilakukan pada atau setelah tanda waktu yang ditentukan akan dibaca oleh stream. Jika tanda waktu yang disediakan mendahului semua komit tabel, pembacaan streaming dimulai dengan tanda waktu paling awal yang tersedia. Atur salah satu:- String stempel waktu. Contohnya,
"2019-01-01T00:00:00.000Z". - String tanggal. Contohnya,
"2019-01-01".
- String stempel waktu. Contohnya,
Anda tidak dapat mengatur keduanya startingVersion dan startingTimestamp pada saat yang sama. Pengaturan ini hanya berlaku untuk kueri streaming baru. Jika kueri streaming telah dimulai dan kemajuan telah direkam di titik pemeriksaan, pengaturan ini diabaikan.
Important
Meskipun Anda dapat memulai sumber streaming dari versi atau tanda waktu tertentu, skema sumber streaming selalu merupakan skema terbaru dari tabel Delta. Anda harus memastikan tidak ada perubahan skema yang tidak kompatibel ke tabel Delta setelah versi atau tanda waktu yang ditentukan. Jika tidak, sumber streaming mungkin mengembalikan hasil yang salah saat membaca data dengan skema yang salah.
Example
Misalnya, Anda memiliki tabel user_events. Jika Anda ingin membaca perubahan sejak versi 5, gunakan:
spark.readStream
.option("startingVersion", "5")
.table("user_events")
Jika Anda ingin membaca perubahan sejak versi 2018-10-18, gunakan:
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Memproses rekam jepret awal tanpa menghilangkan data
Fitur ini tersedia di Databricks Runtime 11.3 LTS ke atas.
Dalam kueri streaming stateful dengan watermark yang ditentukan, memproses file berdasarkan waktu modifikasi dapat mengakibatkan catatan diproses dalam urutan yang salah. Ini dapat menyebabkan penanda air salah menandai rekaman sebagai peristiwa terlambat dan menghapusnya. Ini hanya dapat terjadi ketika rekam jepret Delta awal diproses dalam urutan default.
Untuk aliran dengan tabel sumber Delta, kueri terlebih dahulu memproses semua data yang ada dalam tabel dan membuat versi yang disebut rekam jepret awal. Secara default, file data tabel Delta diproses berdasarkan file mana yang terakhir diubah. Namun, waktu modifikasi terakhir tidak selalu mewakili urutan waktu peristiwa rekaman.
Untuk menghindari penurunan data selama pemrosesan rekam jepret awal, aktifkan withEventTimeOrder opsi .
withEventTimeOrder membagi rentang waktu peristiwa data snapshot awal menjadi segmen waktu. Setiap mikro-batch memproses bucket dengan memfilter data dalam rentang waktu tertentu. Opsi maxFilesPerTrigger dan maxBytesPerTrigger masih berlaku untuk mengontrol ukuran mikro-batch, tetapi hanya secara perkiraan karena sifat pendekatan pemrosesannya.
Diagram berikut menunjukkan proses ini:
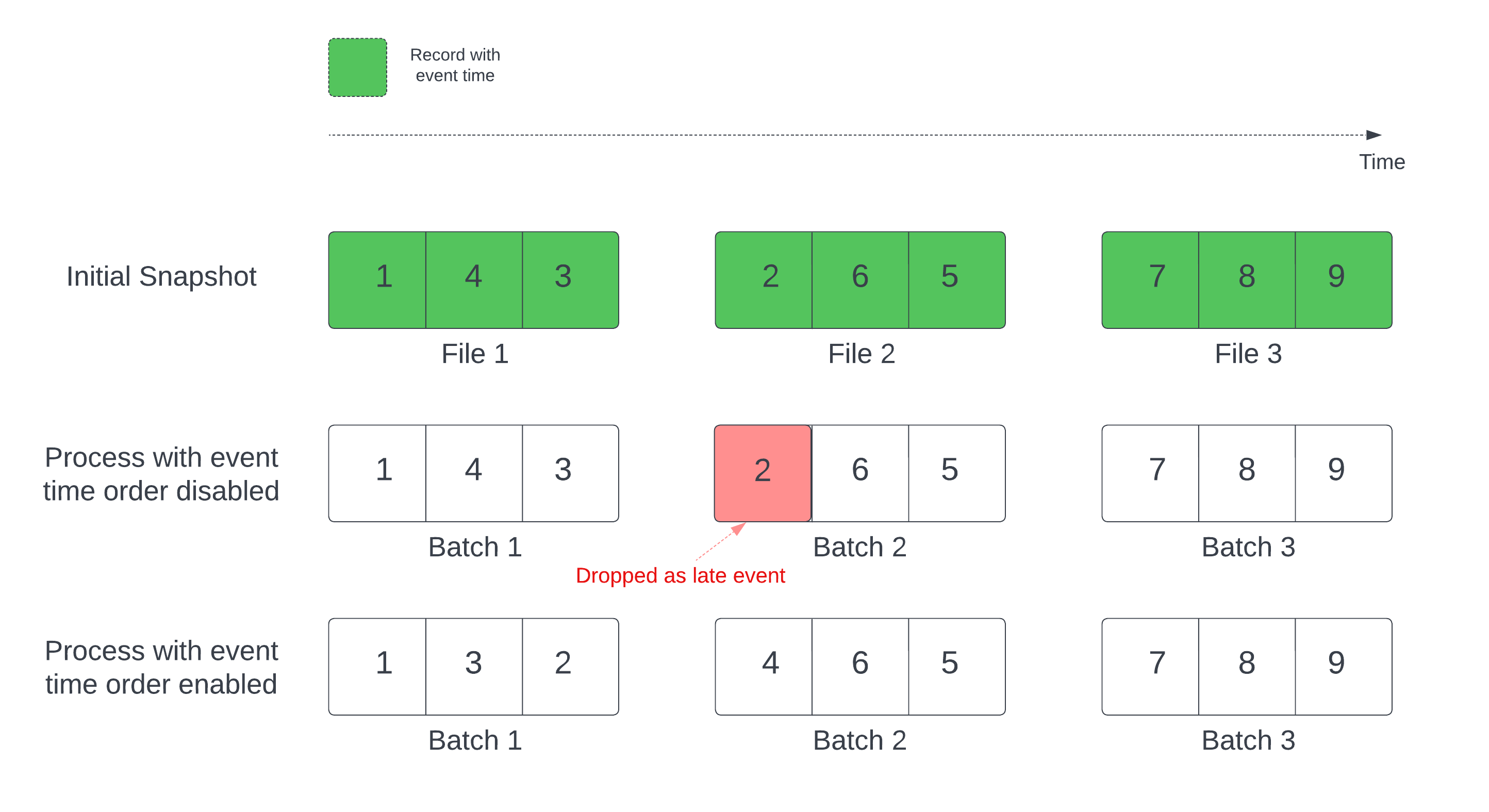
Keterbatasan
- Anda tidak dapat mengubah
withEventTimeOrderjika kueri aliran telah dimulai dan rekam jepret awal sedang diproses secara aktif. Untuk memulai ulang denganwithEventTimeOrderyang telah diubah, Anda harus menghapus titik pemeriksaan. - Jika
withEventTimeOrderdiaktifkan, Anda tidak dapat menurunkan tingkat aliran ke versi Databricks Runtime yang tidak mendukung fitur ini hingga pemrosesan rekam jepret awal selesai. Untuk menurunkan tingkat, tunggu hingga rekam jepret awal selesai, atau hapus titik pemeriksaan dan mulai ulang kueri. - Fitur ini tidak didukung dalam skenario berikut:
- Kolom waktu peristiwa adalah kolom yang dihasilkan dan ada transformasi non-proyeksi antara sumber Delta dan marka air.
- Ada marka air yang memiliki lebih dari satu sumber Delta dalam kueri aliran.
Kinerja
Jika withEventTimeOrder diaktifkan, performa pemrosesan rekam jepret awal mungkin lebih lambat. Setiap mikro-batch memindai rekam jepret awal untuk memfilter data dalam rentang waktu peristiwa yang sesuai. Untuk meningkatkan performa pemfilteran:
- Gunakan kolom sumber Delta sebagai waktu kejadian agar penghindaran data dapat diterapkan. Lihat Data Skipping.
- Partisi tabel berdasarkan kolom waktu peristiwa.
Gunakan antarmuka pengguna Spark untuk melihat berapa banyak file Delta yang dipindai untuk mikro-batch tertentu.
Example
Misalkan Anda memiliki tabel user_events dengan kolom event_time. Kueri streaming Anda adalah kueri agregasi. Jika Anda ingin memastikan tidak ada penurunan data selama pemrosesan snapshot awal, Anda dapat menggunakan:
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
Anda dapat mengatur withEventTimeOrder dengan konfigurasi Spark pada kluster untuk menerapkannya ke semua kueri streaming: spark.databricks.delta.withEventTimeOrder.enabled true.
Batasi laju input untuk meningkatkan performa pemrosesan
Secara default, Streaming Terstruktur memproses file sebanyak mungkin di setiap mikro-batch. Untuk membatasi jumlah data yang diproses per batch dan mengelola penggunaan memori, stabilkan latensi, atau kurangi biaya penyimpanan cloud, gunakan opsi berikut:
-
maxFilesPerTrigger: Jumlah file baru yang akan dipertimbangkan dalam setiap mikro-batch. Defaultnya adalah 1000. -
maxBytesPerTrigger: Jumlah data yang diproses di setiap mikro-batch. Opsi ini menetapkan "soft max", yang berarti batch memproses sekitar jumlah data ini dan mungkin memproses lebih dari batas tersebut agar kueri streaming dapat bergerak maju dalam situasi ketika unit input terkecil lebih besar dari batas ini. Ini tidak diatur secara default.
Jika Anda menggunakan maxBytesPerTrigger dan maxFilesPerTrigger, mikro-batch memproses data hingga salah satu dari batas maxFilesPerTrigger atau maxBytesPerTrigger tercapai.
Note
Secara default, jika logRetentionDuration membersihkan transaksi dalam tabel sumber dan kueri streaming mencoba memproses versi tersebut, kueri gagal mencegah kehilangan data. Anda dapat mengatur opsi failOnDataLoss ke false untuk mengabaikan data yang hilang dan melanjutkan pemrosesan. Lihat Mengonfigurasi retensi data untuk kueri perjalanan lintas waktu.
Mengontrol biaya penyimpanan cloud
Kueri streaming memiliki beberapa mode pemicu yang tersedia yang memungkinkan Anda menyeimbangkan biaya dan latensi, termasuk processingTime, , availableNowdan realTime. Lihat Mengontrol biaya penyimpanan cloud.