Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menjelaskan cara membuat titik akhir pencarian vektor dan indeks menggunakan Mosaic AI Vector Search.
Anda dapat membuat dan mengelola komponen pencarian vektor, seperti titik akhir pencarian vektor dan indeks pencarian vektor, menggunakan UI, Python SDK, atau REST API.
Misalnya buku catatan yang mengilustrasikan cara membuat dan mengkueri titik akhir pencarian vektor, lihat Contoh buku catatan pencarian vektor. Untuk informasi referensi, lihat referensi SDK Python.
Persyaratan
- Ruang kerja yang menggunakan Katalog Unity.
- Komputasi tanpa server diaktifkan. Untuk petunjuknya, lihat Menyambungkan ke komputasi tanpa server.
- Untuk titik akhir standar, tabel sumber harus mengaktifkan Ubah Umpan Data. Lihat Gunakan umpan data perubahan Delta Lake pada Azure Databricks.
- Untuk membuat indeks pencarian vektor, Anda harus memiliki hak istimewa CREATE TABLE pada skema katalog tempat indeks akan dibuat.
- Untuk melakukan query pada indeks yang dimiliki oleh pengguna lain, Anda harus memiliki hak istimewa tambahan. Lihat Cara mengkueri indeks pencarian vektor.
Izin untuk membuat dan mengelola titik akhir pencarian vektor dikonfigurasi menggunakan daftar kontrol akses. Lihat Daftar Kontrol Akses titik akhir pencarian vektor.
Installation
Untuk menggunakan SDK pencarian vektor, Anda harus menginstalnya di notebook Anda. Gunakan kode berikut untuk menginstal paket.
%pip install databricks-vectorsearch
dbutils.library.restartPython()
Kemudian gunakan perintah berikut untuk mengimpor VectorSearchClient:
from databricks.vector_search.client import VectorSearchClient
Untuk informasi tentang autentikasi, lihat Perlindungan dan autentikasi data.
Buat titik akhir pencarian vektor
Anda dapat membuat titik akhir pencarian vektor menggunakan UI Databricks, Python SDK, atau API.
Buatlah endpoint pencarian vektor menggunakan UI
Ikuti langkah-langkah berikut untuk membuat endpoint pencarian vektor menggunakan UI.
Di bilah sisi kiri, klik Compute.
Klik tab Pencarian Vektor dan klik Buat titik akhir.

Formulir buat titik akhir terbuka. Masukkan nama untuk titik akhir ini.
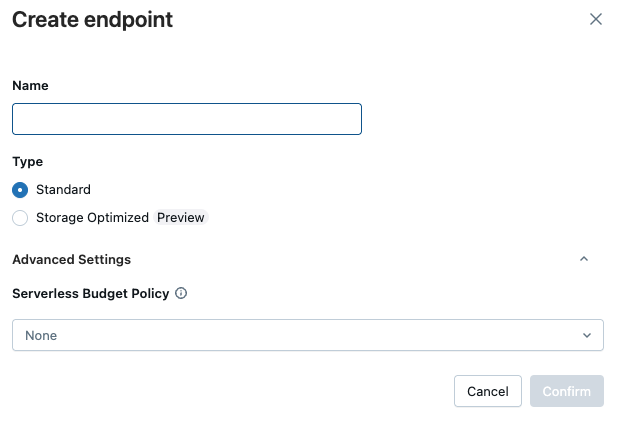
Di bidang Jenis , pilih Standar atau Penyimpanan Dioptimalkan. Lihat Opsi titik akhir.
(Opsional) Di bawah Pengaturan tingkat lanjut, pilih kebijakan anggaran. Lihat Kebijakan anggaran pencarian vektor.
Klik tombol Konfirmasi.
Membuat titik akhir pencarian vektor menggunakan SDK Python
Contoh berikut menggunakan fungsi SDK create_endpoint() untuk membuat endpoint pencarian vektor.
# The following line automatically generates a PAT Token for authentication
client = VectorSearchClient()
# The following line uses the service principal token for authentication
# client = VectorSearchClient(service_principal_client_id=<CLIENT_ID>,service_principal_client_secret=<CLIENT_SECRET>)
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD" # or "STORAGE_OPTIMIZED"
)
Buat endpoint pencarian vektor menggunakan REST API
Lihat dokumentasi referensi REST API: POST /api/2.0/vector-search/endpoints.
Buat endpoint dengan target QPS minimum untuk beban kerja dengan throughput tinggi
Penting
Fitur ini ada di Beta. Admin ruang kerja dapat mengontrol akses ke fitur ini dari halaman Pratinjau . Lihat Kelola pratinjau Azure Databricks.
Untuk beban kerja dengan throughput tinggi, Anda dapat membuat endpoint dengan target QPS minimum. Fitur ini hanya tersedia untuk titik akhir standar.
Untuk menetapkan target QPS minimum, gunakan min_qps parameter . Lihat Menskalakan throughput titik akhir dengan QPS (Beta) tinggi.
Penting
Menetapkan min_qps provisi kapasitas tambahan, yang meningkatkan biaya titik akhir. Anda dikenakan biaya untuk kapasitas tambahan ini terlepas dari lalu lintas kueri aktual. Untuk berhenti dikenakan biaya ini, mengatur ulang titik akhir menggunakan min_qps=-1. Pensakalan throughput dilakukan sebisa mungkin dan tidak dijamin selama Beta.
client.create_endpoint(
name="vector_search_endpoint_name",
endpoint_type="STANDARD",
min_qps=500, # Beta: minimum QPS target for high-throughput workloads
)
Untuk mengubah QPS minimum pada titik akhir yang ada, gunakan update_endpoint().
from databricks.vector_search.client import VectorSearchClient, MIN_QPS_RESET_TO_DEFAULT
client = VectorSearchClient()
# Set or update minimum QPS
response = client.update_endpoint(name="vector_search_endpoint_name", min_qps=500)
# Check scaling status
scaling_info = response.get("endpoint", {}).get("scaling_info", {})
print(f"State: {scaling_info.get('state')}") # SCALING_CHANGE_IN_PROGRESS or SCALING_CHANGE_APPLIED
# Remove high QPS configuration and return to default
client.update_endpoint(name="vector_search_endpoint_name", min_qps=MIN_QPS_RESET_TO_DEFAULT)
Setelah memperbarui QPS minimum, sinkronkan indeks Anda untuk menerapkan konfigurasi baru.
(Opsional) Buat dan konfigurasikan titik akhir untuk menyajikan model embedding.
Jika Anda memilih untuk membiarkan Databricks menghitung embedding, Anda bisa menggunakan endpoint API Model Dasar yang telah dikonfigurasikan sebelumnya atau membuat endpoint penyajian model untuk menyajikan model embedding pilihan Anda. Lihat API Model Dasar Bayar per Token atau Membuat titik akhir penyajian model dasar untuk panduan. Misalnya buku catatan, lihat Contoh buku catatan pencarian vektor.
Saat Anda mengonfigurasi endpoint embedding, Databricks menyarankan agar Anda menghapus pilihan default dari Skala ke nol. Endpoint yang melayani dapat memerlukan beberapa menit untuk pemanasan, dan kueri awal pada indeks dengan endpoint yang dikurangi skalanya mungkin mengalami waktu habis.
Nota
Inisialisasi indeks pencarian vektor mungkin kehabisan waktu jika titik akhir penyematan tidak dikonfigurasi dengan tepat untuk himpunan data. Anda hanya boleh menggunakan titik akhir CPU untuk himpunan data dan pengujian kecil. Untuk dataset yang lebih besar, gunakan endpoint GPU untuk kinerja yang optimal.
Buat indeks pencarian vektor
Anda dapat membuat indeks pencarian vektor menggunakan UI, Python SDK, atau REST API. Antarmuka Pengguna adalah pendekatan yang paling sederhana.
Ada dua jenis indeks:
- Indeks Sinkronisasi Delta secara otomatis disinkronkan dengan Tabel Delta sumber, secara otomatis dan bertahap memperbarui indeks saat data yang mendasar dalam Tabel Delta berubah.
- Indeks Akses Vektor Langsung mendukung pembacaan dan penulisan langsung vektor dan metadata. Pengguna bertanggung jawab untuk memperbarui tabel ini menggunakan REST API atau SDK Python. Tipe indeks ini tidak dapat dibuat menggunakan UI. Anda harus menggunakan REST API atau SDK.
Indeks Sinkronisasi Delta mendukung mode pencarian berikut:
-
Pencarian vektor (ANN atau hibrid): Memerlukan kolom penyematan. Mendukung titik akhir standar dan titik akhir yang dioptimalkan untuk penyimpanan. Anda juga dapat menggunakan
query_type="FULL_TEXT"untuk pencarian kata kunci pada indeks ini. - Indeks pencarian teks lengkap khusus (Beta): Indeks Sinkronisasi Delta dibuat tanpa kolom penyematan apa pun, untuk pencarian khusus kata kunci. Hanya tersedia di titik akhir yang dioptimalkan untuk penyimpanan menggunakan mode sinkronisasi tertunda. Lihat Membuat indeks pencarian teks lengkap.
Nota
Nama kolom _id sudah dipesan. Jika tabel sumber Anda memiliki kolom bernama _id, ubahlah namanya sebelum membuat indeks pencarian vektor.
Buat indeks menggunakan UI
Di bilah sisi kiri, klik Katalog
untuk membuka UI Penjelajah Katalog. Arahkan ke tabel Delta yang ingin Anda gunakan.
Klik tombol Create di kanan atas, dan pilih Indeks pencarian vektor dari menu tarik-turun.
Gunakan pemilih dalam dialog untuk mengkonfigurasi indeks.
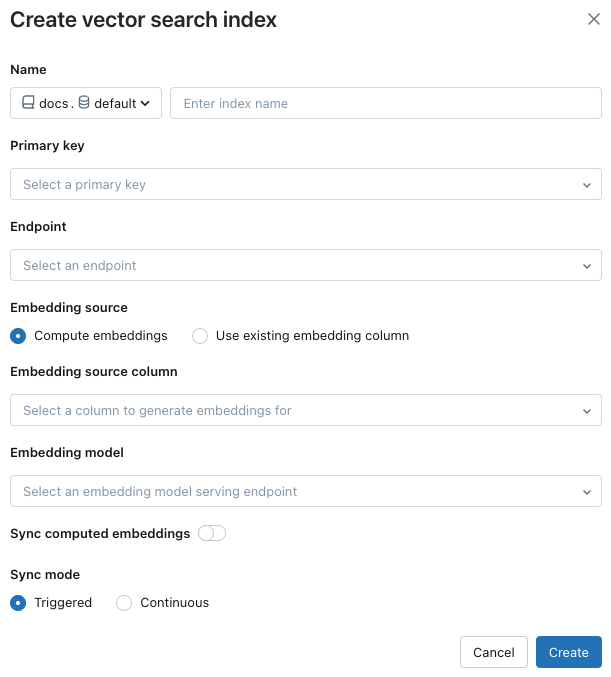
Nama: Nama yang akan digunakan untuk tabel online di Katalog Unity. Nama memerlukan namespace tiga tingkat,
<catalog>.<schema>.<name>. Hanya karakter alfanumerik dan garis bawah yang diizinkan.Primary key: Kolom yang digunakan sebagai kunci utama.
Kolom yang akan disinkronkan: Pilih kolom yang akan disinkronkan dengan indeks vektor. Jika Anda membiarkan kolom ini kosong, semua kolom dari tabel sumber akan disinkronkan dengan indeks. Kolom kunci utama dan kolom sumber embedding atau kolom vektor embedding selalu disinkronisasi.
Sumber Penyematan: Indikasikan jika Anda ingin Databricks melakukan penghitungan embeddings untuk kolom teks dalam tabel Delta (Hitung embeddings), atau jika tabel Delta Anda sudah berisi embeddings yang sudah dihitung sebelumnya (Gunakan kolom penyematan yang ada).
Jika Anda memilih Hitung penyematan, pilih kolom yang Anda inginkan dihitung penyematannya dan model penyematan yang ingin Anda gunakan untuk perhitungan tersebut. Hanya kolom teks yang didukung.
Untuk aplikasi produksi yang menggunakan titik akhir standar, Databricks merekomendasikan penggunaan model
databricks-gte-large-endasar dengan throughput yang telah disediakan untuk titik akhir.Untuk aplikasi produksi yang menggunakan titik akhir yang dioptimalkan untuk penyimpanan dengan model yang dihosting di Databricks, gunakan nama model secara langsung (misalnya,
databricks-gte-large-en) sebagai titik akhir model penyematan. Titik akhir yang dioptimalkan untuk penyimpanan menggunakanai_querydengan inferensi batch pada waktu pengambilan, memberikan throughput tinggi untuk pekerjaan pemrosesan embedding. Jika Anda lebih suka menggunakan titik akhir throughput yang telah disediakan untuk melakukan kueri, tentukan di bidangmodel_endpoint_name_for_querysaat Anda membuat indeks.
Jika Anda memilih Gunakan kolom embedding yang ada, pilih kolom yang berisi embedding yang sudah dihitung sebelumnya dan dimensi embeddingnya. Format kolom embedding yang telah dihitung sebelumnya harus
array[float]. Untuk titik akhir yang dioptimalkan penyimpanan, dimensi penyematan harus dapat dibagi secara merata dengan 16.
Sinkronisasi embeddings yang dihitung: Alihkan pengaturan ini untuk menyimpan embeddings yang dihasilkan ke tabel Katalog Unity. Untuk informasi lebih lanjut, lihat Simpan tabel penyematan yang dihasilkan.
Titik akhir pencarian vektor: Pilih titik akhir pencarian vektor untuk menyimpan indeks.
Mode Sinkronisasi: Kontinu menjaga indeks tetap sinkron dengan latensi dalam hitungan detik. Namun, biayanya lebih tinggi karena kluster komputasi disediakan untuk menjalankan pipeline streaming sinkronisasi berkelanjutan.
- Untuk titik akhir standar, Berkelanjutan dan Dipicu melakukan pembaruan bertahap, sehingga hanya data yang berubah sejak sinkronisasi terakhir yang diproses.
- Untuk endpoint yang teroptimasi penyimpanan, setiap sinkronisasi sebagian memperbarui indeks. Untuk indeks terkelola pada sinkronisasi berikutnya, setiap penyematan yang dihasilkan di mana baris sumber belum berubah digunakan kembali dan tidak perlu dikomputasi ulang. Lihat Batasan pada titik akhir yang dioptimalkan untuk penyimpanan.
Dengan mode sinkronisasi Triggered, Anda menggunakan SDK Python atau REST API untuk memulai sinkronisasi. Lihat Memperbarui Indeks Sinkronisasi Delta.
Untuk titik akhir yang dioptimalkan untuk penyimpanan, hanya mode sinkronisasi yang dipicu yang didukung.
Pengaturan Tingkat Lanjut: (Opsional)
Anda dapat menerapkan kebijakan anggaran ke indeks. Lihat Kebijakan anggaran pencarian vektor.
Jika Anda memilih Penyematan komputasi, Anda bisa menentukan model penyematan terpisah untuk mengkueri indeks pencarian vektor Anda. Ini dapat berguna jika Anda memerlukan titik akhir throughput tinggi untuk penyerapan tetapi titik akhir latensi yang lebih rendah untuk mengkueri indeks. Model yang ditentukan dalam bidang Model penyematan selalu digunakan untuk pengambilan dan juga digunakan untuk pengkuerian, kecuali Anda menentukan model yang berbeda di sini. Untuk menentukan model lain, klik Pilih model penyematan terpisah untuk mengkueri indeks dan memilih model dari menu drop-down.
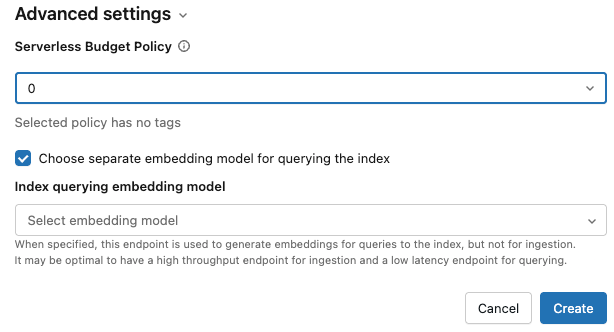
Setelah Anda selesai mengkonfigurasi indeks, klik Buat.
Membuat indeks menggunakan SDK Python
Contoh berikut menciptakan Indeks Delta Sync dengan embeddings yang dihitung oleh Databricks. Untuk detailnya, lihat referensi SDK Python.
Contoh ini juga menunjukkan parameter opsional model_endpoint_name_for_query, yang menentukan model penyematan terpisah yang mengelola titik akhir yang akan digunakan untuk melakukan kueri indeks.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_source_column="text",
embedding_model_endpoint_name="e5-small-v2", # This model is used for ingestion, and is also used for querying unless model_endpoint_name_for_query is specified.
model_endpoint_name_for_query="e5-mini-v2" # Optional. If specified, used only for querying the index.
)
Contoh berikut membuat Indeks Sinkronisasi Delta dengan embeddings yang dikelola sendiri.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="vector_search_demo_endpoint",
source_table_name="vector_search_demo.vector_search.en_wiki",
index_name="vector_search_demo.vector_search.en_wiki_index",
pipeline_type="TRIGGERED",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector"
)
Secara default, semua kolom dari tabel sumber disinkronkan dengan indeks. Untuk memilih subset kolom yang akan disinkronkan, gunakan columns_to_sync. Kunci utama dan kolom penyematan selalu disertakan dalam indeks.
Untuk menyinkronkan hanya kunci utama dan kolom penyematan, Anda harus menentukan mereka dalam columns_to_sync seperti yang diperlihatkan:
index = client.create_delta_sync_index(
...
columns_to_sync=["id", "text_vector"] # to sync only the primary key and the embedding column
)
Untuk menyinkronkan kolom tambahan, tentukan seperti yang ditunjukkan. Anda tidak perlu menyertakan kunci utama dan kolom embedding, karena mereka selalu disinkronkan.
index = client.create_delta_sync_index(
...
columns_to_sync=["revisionId", "text"] # to sync the `revisionId` and `text` columns in addition to the primary key and embedding column.
)
Membuat indeks pencarian teks lengkap (Beta)
Penting
Pembuatan indeks pencarian teks lengkap hanya tersedia sebagai fitur beta pada titik akhir yang dioptimalkan penyimpanan. Untuk menggunakannya, vs_full_text pratinjau ruang kerja harus diaktifkan. Hubungi tim akun Anda atau lihat Kelola pratinjau Azure Databricks untuk mengaktifkan pratinjau.
Indeks pencarian teks lengkap memungkinkan pencarian berbasis kata kunci pada kolom teks tanpa memerlukan penyematan vektor. Ini berguna ketika Anda ingin mencari istilah, pengidentifikasi, atau kata kunci yang tepat daripada kesamaan semantik.
Indeks pencarian teks lengkap memiliki persyaratan berikut:
- Harus menggunakan titik akhir yang dioptimalkan penyimpanan . Titik akhir standar tidak didukung.
- Harus menggunakan mode sinkronisasi yang dipicu . Sinkronisasi berkelanjutan tidak didukung.
- Parameter
embedding_source_column,embedding_vector_column, danembedding_dimensiontidak didukung.
Contoh berikut membuat indeks pencarian teks lengkap menggunakan SDK Python.
client = VectorSearchClient()
index = client.create_delta_sync_index(
endpoint_name="storage_optimized_endpoint",
source_table_name="catalog.schema.source_table",
index_name="catalog.schema.full_text_index",
pipeline_type="TRIGGERED",
primary_key="id",
columns_to_sync=["id", "text", "metadata_column"],
index_subtype="FULL_TEXT"
)
Setelah membuat indeks, picu sinkronisasi untuk mengisinya:
index.sync()
Untuk mengkueri indeks teks lengkap, gunakan query_type="FULL_TEXT". Lihat Mengkueri indeks pencarian vektor untuk detailnya.
results = index.similarity_search(
query_text="search terms",
columns=["id", "text"],
num_results=10,
query_type="FULL_TEXT"
)
Contoh berikut membuat Indeks Akses Vektor Langsung.
client = VectorSearchClient()
index = client.create_direct_access_index(
endpoint_name="storage_endpoint",
index_name=f"{catalog_name}.{schema_name}.{index_name}",
primary_key="id",
embedding_dimension=1024,
embedding_vector_column="text_vector",
schema={
"id": "int",
"field2": "string",
"field3": "float",
"text_vector": "array<float>"}
)
Buat indeks menggunakan REST API
Lihat dokumentasi referensi REST API: POST /api/2.0/vector-search/indexes.
Simpan tabel pencocokan yang dihasilkan
Jika Databricks menghasilkan embeddings, Anda dapat menyimpan embeddings yang dihasilkan ke tabel di Unity Catalog. Tabel ini dibuat dalam skema yang sama dengan indeks vektor dan ditautkan dari halaman indeks vektor.
Nama tabel adalah nama indeks pencarian vektor, ditambahkan oleh _writeback_table. Nama tidak bisa diedit.
Anda dapat mengakses dan menanyakan tabel seperti tabel lainnya dalam Unity Catalog. Namun, Anda sebaiknya tidak menghapus atau mengubah tabel, karena tabel tersebut tidak dimaksudkan untuk diperbarui secara manual. Tabel dihapus secara otomatis jika indeks dihapus.
Perbarui indeks pencarian vektor
Memperbarui Indeks Sinkronisasi Delta
Indeks yang dibuat dengan mode sinkronisasi Continuous akan diperbarui secara otomatis ketika tabel Delta sumber berubah. Jika Anda menggunakan mode sinkronisasi Triggered, Anda dapat memulai sinkronisasi menggunakan UI, Python SDK, atau REST API.
Databricks Antarmuka Pengguna
Di Catalog Explorer, navigasikan ke indeks pencarian vektor.
Pada tab Gambaran Umum , di bagian Penyerapan Data , klik Sinkronkan sekarang.
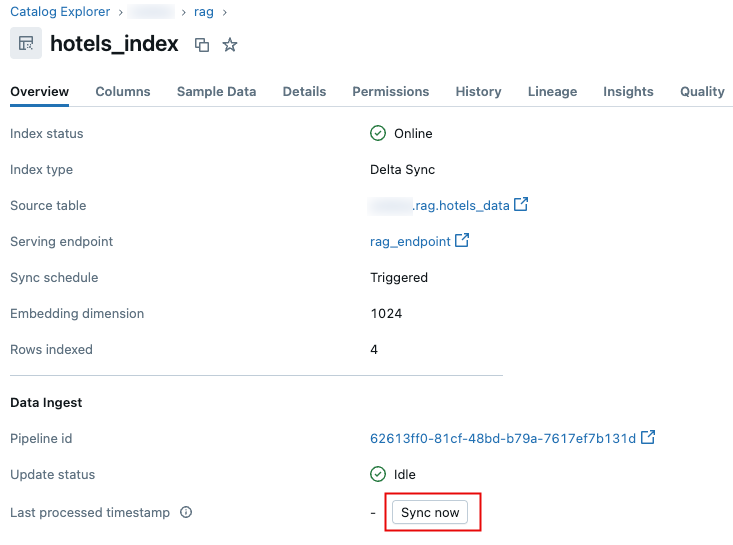 .
.
Python SDK
Untuk detailnya, lihat referensi SDK Python.
client = VectorSearchClient()
index = client.get_index(index_name="vector_search_demo.vector_search.en_wiki_index")
index.sync()
REST API
Lihat dokumentasi referensi REST API: POST /api/2.0/vector-search/indexes/{index_name}/sync.
Perbarui Indeks Akses Vektor Langsung
Anda dapat menggunakan SDK Python atau REST API untuk menyisipkan, memperbarui, atau menghapus data dari Indeks Akses Vektor Langsung.
Python SDK
Untuk detailnya, lihat referensi SDK Python.
index.upsert([
{
"id": 1,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.0] * 1024
},
{
"id": 2,
"field2": "value2",
"field3": 3.0,
"text_vector": [1.1] * 1024
}
])
REST API
Lihat dokumentasi referensi REST API: POST /api/2.0/vector-search/indexes.
Untuk aplikasi produksi, Databricks merekomendasikan penggunaan perwakilan layanan alih-alih token akses pribadi. Kinerja dapat ditingkatkan hingga 100 milidetik per kueri.
Contoh kode berikut menunjukkan cara memperbarui indeks menggunakan service principal.
export SP_CLIENT_ID=...
export SP_CLIENT_SECRET=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
export WORKSPACE_ID=...
# Set authorization details to generate OAuth token
export AUTHORIZATION_DETAILS='{"type":"unity_catalog_permission","securable_type":"table","securable_object_name":"'"$INDEX_NAME"'","operation": "WriteVectorIndex"}'
# Generate OAuth token
export TOKEN=$(curl -X POST --url $WORKSPACE_URL/oidc/v1/token -u "$SP_CLIENT_ID:$SP_CLIENT_SECRET" --data 'grant_type=client_credentials' --data 'scope=all-apis' --data-urlencode 'authorization_details=['"$AUTHORIZATION_DETAILS"']' | jq .access_token | tr -d '"')
# Get index URL
export INDEX_URL=$(curl -X GET -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME | jq -r '.status.index_url' | tr -d '"')
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/upsert-data --data '{"inputs_json": "[...]"}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url https://$INDEX_URL/delete-data --data '{"primary_keys": [...]}'
Contoh kode berikut menggambarkan cara memperbarui indeks menggunakan token akses pribadi (PAT).
export TOKEN=...
export INDEX_NAME=...
export WORKSPACE_URL=https://...
# Upsert data into vector search index.
curl -X POST -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/upsert-data --data '{"inputs_json": "..."}'
# Delete data from vector search index
curl -X DELETE -H 'Content-Type: application/json' -H "Authorization: Bearer $TOKEN" --url $WORKSPACE_URL/api/2.0/vector-search/indexes/$INDEX_NAME/delete-data --data '{"primary_keys": [...]}'
Cara membuat perubahan skema tanpa waktu henti
Perubahan skema pada tabel sumber tidak didukung kecuali Anda membangun ulang indeks. Ini termasuk memodifikasi kolom yang sudah ada dan menambahkan kolom baru. Skema indeks ditetapkan pada saat pembuatan, sehingga setiap perubahan skema memerlukan pembuatan indeks baru agar dapat diterapkan.
Ikuti langkah-langkah ini untuk membangun kembali dan menyebarkan indeks tanpa waktu henti:
- Lakukan perubahan skema pada tabel sumber Anda.
- Buat indeks baru menggunakan skema yang diperbarui.
- Setelah indeks baru siap, alihkan lalu lintas ke indeks baru.
- Hapus indeks asli.