Membangun sistem Retrieval-Augmented Generation tingkat lanjut
Artikel sebelumnya membahas dua opsi untuk membangun aplikasi "obrolan atas data Anda", salah satu kasus penggunaan premier untuk AI generatif dalam bisnis:
- Pengambilan augmented generation (RAG) yang melengkapi pelatihan Model Bahasa Besar (LLM) dengan database artikel yang dapat dicari yang dapat diambil berdasarkan kesamaan dengan kueri pengguna dan diteruskan ke LLM untuk penyelesaian.
- Penyempurnaan, yang memperluas pelatihan LLM untuk memahami lebih lanjut tentang domain masalah.
Artikel sebelumnya juga membahas kapan harus menggunakan setiap pendekatan, pro dan con dari setiap pendekatan dan beberapa pertimbangan lainnya.
Artikel ini mengeksplorasi RAG secara lebih mendalam, khususnya, semua pekerjaan yang diperlukan untuk membuat solusi siap produksi.
Artikel sebelumnya menggambarkan langkah-langkah atau fase RAG menggunakan diagram berikut.
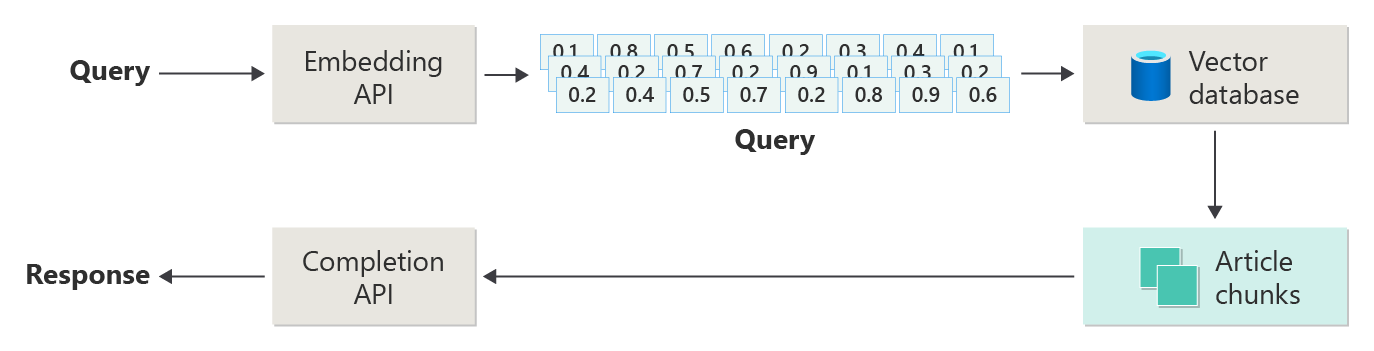
Penggambutan ini disebut sebagai "RAG naif" dan merupakan cara yang berguna untuk terlebih dahulu memahami mekanisme, peran, dan tanggung jawab yang diperlukan untuk menerapkan sistem obrolan berbasis RAG.
Namun, implementasi dunia yang lebih nyata memiliki lebih banyak langkah pra-dan pasca-pemrosesan untuk menyiapkan artikel, kueri, dan respons untuk digunakan. Diagram berikut adalah penggambaran RAG yang lebih realistis, kadang-kadang disebut sebagai "RAG tingkat lanjut."

Artikel ini menyediakan kerangka kerja konseptual untuk memahami jenis masalah pra-dan pasca-pemrosesan dalam sistem obrolan berbasis RAG dunia nyata, yang diatur sebagai berikut:
- Fase penyerapan
- Fase Alur Inferensi
- Fase evaluasi
Sebagai gambaran umum konseptual, kata kunci dan ide disediakan sebagai konteks dan titik awal untuk eksplorasi dan penelitian lebih lanjut.
Konsumsi
Penyerapan terutama berkaitan dengan penyimpanan dokumen organisasi Anda sedih sehingga mereka dapat dengan mudah diambil untuk menjawab pertanyaan pengguna. Tantangannya adalah memastikan bahwa bagian dokumen yang paling cocok dengan kueri pengguna berada dan digunakan selama inferensi. Pencocokan dilakukan terutama melalui penyematan vektorisasi dan pencarian kesamaan kosinus. Namun, ini difasilitasi dengan memahami sifat konten (pola, formulir, dll.) dan strategi organisasi data (struktur data saat disimpan dalam database vektor).
Untuk itu, pengembang perlu mempertimbangkan hal-hal berikut:
- Pra-pemrosesan dan ekstraksi konten
- Strategi pemotongan
- Organisasi pemotongan
- Perbarui strategi
Pra-pemrosesan dan ekstraksi konten
Konten yang bersih dan akurat adalah salah satu cara terbaik untuk meningkatkan kualitas keseluruhan sistem obrolan berbasis RAG. Untuk mencapai hal ini, pengembang perlu memulai dengan menganalisis bentuk dan bentuk dokumen yang akan diindeks. Apakah dokumen sesuai dengan pola konten tertentu seperti dokumentasi? Jika tidak, jenis pertanyaan apa yang mungkin dijawab oleh dokumen?
Minimal, pengembang harus membuat langkah-langkah dalam alur penyerapan untuk:
- Menstandarkan format teks
- Menangani karakter khusus
- Menghapus konten yang tidak terkait dan kedaluarsa
- Akun untuk konten versi
- Akun untuk pengalaman konten (tab, gambar, tabel)
- Ekstrak metadata
Beberapa informasi ini (seperti metadata misalnya) mungkin berguna untuk disimpan dengan dokumen dalam database vektor untuk digunakan selama proses pengambilan dan evaluasi dalam alur inferensi, atau dikombinasikan dengan potongan teks untuk membujuk penyematan vektor gugus.
Strategi pemotongan
Pengembang harus memutuskan cara memecah dokumen yang lebih panjang menjadi potongan yang lebih kecil. Ini dapat meningkatkan relevansi konten tambahan yang dikirim ke LLM untuk menjawab kueri pengguna secara akurat. Selain itu, pengembang perlu mempertimbangkan cara menggunakan gugus setelah pengambilan. Ini adalah area di mana perancang sistem harus melakukan beberapa penelitian tentang teknik yang digunakan dalam industri, dan melakukan beberapa eksperimen, bahkan mengujinya dalam kapasitas terbatas di organisasi mereka.
Pengembang harus mempertimbangkan:
- Pengoptimalan ukuran gugus - Tentukan berapa ukuran ideal gugus, dan cara menunjuk gugus. Menurut bagian? Berdasarkan paragraf? Dengan kalimat?
- Potongan jendela tumpang tindih dan geser - Tentukan cara membagi konten menjadi potongan diskrit. Atau akan gugus tumpang tindih? Atau keduanya (jendela geser)?
- Small2Big - Saat memotong pada tingkat terperinci seperti satu kalimat, apakah konten akan diatur sededimikian rupan sehingga mudah untuk menemukan kalimat tetangga atau berisi paragraf? (Lihat "Organisasi penggugusan.") Mengambil informasi tambahan ini dan menyediakannya ke LLM dapat memberikan lebih banyak konteks saat menjawab kueri pengguna.
Organisasi pemotongan
Dalam sistem RAG, organisasi data dalam database vektor sangat penting untuk pengambilan informasi yang relevan yang efisien untuk menambah proses pembuatan. Berikut adalah jenis strategi pengindeksan dan pengambilan yang mungkin dipertimbangkan pengembang:
- Indeks Hierarkis - Pendekatan ini melibatkan pembuatan beberapa lapisan indeks, di mana indeks tingkat atas (indeks ringkasan) dengan cepat mempersempit ruang pencarian ke subset gugus yang berpotensi relevan, dan indeks tingkat kedua (indeks gugus) menyediakan penunjuk yang lebih terperinci ke data aktual. Metode ini dapat secara signifikan mempercepat proses pengambilan karena mengurangi jumlah entri untuk dipindai dalam indeks terperinci dengan memfilter melalui indeks ringkasan terlebih dahulu.
- Indeks Khusus - Indeks khusus seperti database berbasis grafik atau relasional dapat digunakan tergantung pada sifat data dan hubungan antara gugus. Contohnya:
- Indeks berbasis grafik berguna ketika gugus memiliki informasi atau hubungan yang saling terhubung yang dapat meningkatkan pengambilan, seperti jaringan kutipan atau grafik pengetahuan.
- Database relasional dapat efektif jika gugus disusun dalam format tabular di mana kueri SQL dapat digunakan untuk memfilter dan mengambil data berdasarkan atribut atau hubungan tertentu.
- Indeks Hibrid - Pendekatan hibrid menggabungkan beberapa strategi pengindeksan untuk memanfaatkan kekuatan masing-masing. Misalnya, pengembang mungkin menggunakan indeks hierarkis untuk pemfilteran awal dan indeks berbasis grafik untuk menjelajahi hubungan antara gugus secara dinamis selama pengambilan.
Pengoptimalan perataan
Untuk meningkatkan relevansi dan akurasi potongan yang diambil, dapat bermanfaat untuk menyelaraskannya lebih dekat dengan jenis pertanyaan atau kueri yang dimaksudkan untuk dijawab. Salah satu strategi untuk mencapai hal ini adalah menghasilkan dan memasukkan pertanyaan hipotetis untuk setiap gugus yang mewakili pertanyaan apa yang paling cocok untuk dijawab. Ini membantu dalam beberapa cara:
- Pencocokan yang Ditingkatkan: Selama pengambilan, sistem dapat membandingkan kueri masuk dengan pertanyaan hipotetis ini untuk menemukan kecocokan terbaik, meningkatkan relevansi gugus yang diambil.
- Data Pelatihan untuk Model Pembelajaran Mesin: Pasangan pertanyaan dan gugus ini dapat berfungsi sebagai data pelatihan untuk meningkatkan model pembelajaran mesin yang mendasar sistem RAG, membantunya mempelajari jenis pertanyaan mana yang paling baik dijawab oleh gugus mana.
- Penanganan Kueri Langsung: Jika kueri pengguna nyata sangat cocok dengan pertanyaan hipotetis, sistem dapat dengan cepat mengambil dan menggunakan potongan yang sesuai, mempercepat waktu respons.
Setiap pertanyaan hipotetis setiap gugus bertindak sebagai semacam "label" yang memandu algoritma pengambilan, membuatnya lebih fokus dan sadar secara kontekstual. Ini berguna dalam skenario di mana gugus mencakup berbagai topik atau jenis informasi.
Perbarui strategi
Jika organisasi Anda perlu mengindeks dokumen yang sering diperbarui, penting untuk mempertahankan korpus yang diperbarui untuk memastikan komponen retriever (logika dalam sistem yang bertanggung jawab untuk melakukan kueri terhadap database vektor dan mengembalikan hasilnya) dapat mengakses informasi terbaru. Berikut adalah beberapa strategi untuk memperbarui database vektor dalam sistem tersebut:
- Pembaruan inkremental:
- Interval reguler: Menjadwalkan pembaruan secara berkala (misalnya, harian, mingguan) tergantung pada frekuensi perubahan dokumen. Metode ini memastikan bahwa database disegarkan secara berkala.
- Pembaruan berbasis pemicu: Menerapkan sistem tempat pembaruan memicu pengindeksan ulang. Misalnya, setiap modifikasi atau penambahan dokumen dapat secara otomatis memulai pengindeksan ulang bagian yang terpengaruh.
- Pembaruan parsial:
- Pengindeksan ulang selektif: Alih-alih mengindeks ulang seluruh database, secara selektif hanya memperbarui bagian-bagian korpus yang telah berubah. Ini bisa lebih efisien daripada pengindeksan ulang penuh, terutama untuk himpunan data besar.
- Pengodean Delta: Hanya simpan perbedaan antara dokumen yang ada dan versi yang diperbarui. Pendekatan ini mengurangi beban pemrosesan data dengan menghindari kebutuhan untuk memproses data yang tidak berubah.
- Penerapan versi:
- Rekam jepret: Pertahankan versi korpus dokumen pada titik waktu yang berbeda. Ini memungkinkan sistem untuk kembali atau merujuk ke versi sebelumnya jika perlu dan menyediakan mekanisme pencadangan.
- Kontrol versi dokumen: Gunakan sistem kontrol versi untuk melacak perubahan dalam dokumen secara sistematis. Ini membantu dalam mempertahankan riwayat perubahan dan dapat menyederhanakan proses pembaruan.
- Pembaruan real time:
- Pemrosesan aliran: Memanfaatkan teknologi pemrosesan aliran untuk memperbarui database vektor secara real time saat perubahan dilakukan pada dokumen. Ini bisa sangat penting untuk aplikasi di mana ketepatan waktu informasi sangat penting.
- Kueri langsung: Alih-alih hanya mengandalkan vektor yang telah diindeks sebelumnya, terapkan mekanisme untuk mengkueri data langsung untuk respons terbaru, mungkin menggabungkan ini dengan hasil yang di-cache untuk efisiensi.
- Teknik pengoptimalan:
- Pemrosesan batch: Mengakumulasi perubahan dan memprosesnya dalam batch untuk mengoptimalkan penggunaan sumber daya dan mengurangi overhead yang disebabkan oleh pembaruan yang sering.
- Pendekatan hibrid: Gabungkan berbagai strategi, seperti menggunakan pembaruan bertahap untuk perubahan kecil dan pengindeksan ulang penuh untuk pembaruan besar atau perubahan struktural dalam korpus dokumen.
Memilih strategi pembaruan atau kombinasi strategi yang tepat tergantung pada persyaratan tertentu seperti ukuran korpus dokumen, frekuensi pembaruan, kebutuhan akan data real-time, dan ketersediaan sumber daya. Setiap pendekatan memiliki trade-off dalam hal kompleksitas, biaya, dan latensi pembaruan, jadi penting untuk mengevaluasi faktor-faktor ini berdasarkan kebutuhan spesifik aplikasi.
Alur inferensi
Sekarang setelah artikel telah dipotong, di-vektorisasi, dan disimpan dalam database vektor, fokus berubah menjadi tantangan dalam penyelesaian.
- Apakah kueri pengguna ditulis singgah cara untuk mendapatkan hasil dari sistem yang dicari pengguna?
- Apakah kueri pengguna melanggar salah satu kebijakan kami?
- Bagaimana cara menulis ulang kueri pengguna untuk meningkatkan peluangnya dalam menemukan kecocokan terdekat dalam database vektor?
- Bagaimana kita mengevaluasi hasil kueri untuk memastikan bahwa potongan artikel selaras dengan kueri?
- Bagaimana cara mengevaluasi dan memodifikasi hasil kueri sebelum meneruskannya ke LLM untuk memastikan bahwa detail yang paling relevan disertakan dalam penyelesaian LLM?
- Bagaimana cara mengevaluasi respons LLM untuk memastikan bahwa penyelesaian LLM menjawab kueri asli pengguna?
- Bagaimana cara memastikan respons LLM mematuhi kebijakan kami?
Seperti yang Anda lihat, ada banyak tugas yang harus diperhitungkan pengembang, sebagian besar dalam bentuk:
- Input pra-pemrosesan untuk mengoptimalkan kemungkinan mendapatkan hasil yang diinginkan
- Output pasca-pemrosesan untuk memastikan hasil yang diinginkan
Perlu diingat bahwa seluruh alur inferensi berjalan secara real time. Meskipun tidak ada cara yang tepat untuk merancang logika yang melakukan langkah-langkah pra-dan pasca-pemrosesan, kemungkinan itu adalah kombinasi dari logika pemrograman dan panggilan tambahan ke LLM. Salah satu pertimbangan terpenting adalah trade-off antara membangun alur yang paling akurat dan patuh dan biaya dan latensi yang diperlukan untuk melahirkannya.
Mari kita lihat setiap tahap untuk mengidentifikasi strategi tertentu.
Langkah-langkah pra-pemrosesan kueri
Pra-pemrosesan kueri terjadi segera setelah pengguna Anda mengirimkan kueri mereka, seperti yang digambarkan dalam diagram ini:

Tujuan dari langkah-langkah ini adalah untuk memastikan pengguna mengajukan pertanyaan dalam cakupan sistem kami (dan tidak mencoba "jailbreak" sistem untuk membuatnya melakukan sesuatu yang tidak diinginkan) dan menyiapkan kueri pengguna untuk meningkatkan kemungkinan bahwa itu akan menemukan potongan artikel terbaik yang mungkin menggunakan kesamaan kosinus / pencarian "tetangga terdekat".
Pemeriksaan kebijakan - Langkah ini dapat melibatkan logika yang mengidentifikasi, menghapus, menandai, atau menolak konten tertentu. Beberapa contoh mungkin termasuk menghapus informasi yang dapat diidentifikasi secara pribadi, menghapus eksplisit, dan mengidentifikasi upaya "jailbreak". Jailbreaking mengacu pada metode yang mungkin digunakan pengguna untuk menghindari atau memanipulasi panduan keamanan, etika, atau operasional bawaan model.
Penulisan ulang kueri - Ini bisa menjadi apa pun mulai dari memperluas akronim dan menghapus slang untuk membuat frasa ulang pertanyaan untuk menanyakannya secara lebih abstrak untuk mengekstrak konsep dan prinsip tingkat tinggi ("permintaan langkah kembali").
Variasi tentang permintaan langkah mundur adalah penyematan dokumen hipotetis (HyDE) yang menggunakan LLM untuk menjawab pertanyaan pengguna, membuat penyematan untuk respons tersebut (penyematan dokumen hipotetis), dan menggunakan penyematan tersebut untuk melakukan pencarian terhadap database vektor.
Subkueri
Langkah pemrosesan ini menyangkut kueri asli. Jika kueri asli panjang dan kompleks, akan berguna untuk memecahnya secara terprogram menjadi beberapa kueri yang lebih kecil, lalu menggabungkan semua respons.
Misalnya, pertimbangkan pertanyaan yang terkait dengan penemuan ilmiah, terutama di bidang fisika. Kueri pengguna mungkin: "Siapa yang membuat kontribusi yang lebih signifikan untuk fisika modern, Albert Einstein atau Niels Bohr?"
Kueri ini bisa kompleks untuk ditangani secara langsung karena "kontribusi signifikan" dapat berkonyektif dan multifaktor. Memecahnya menjadi subkueri dapat membuatnya lebih mudah dikelola:
- Subkueri 1: "Apa kontribusi utama Albert Einstein terhadap fisika modern?"
- Subkueri 2: "Apa kontribusi utama Niels Bohr terhadap fisika modern?"
Hasil subkueri ini akan merinci teori dan penemuan utama oleh setiap fisikawan. Contohnya:
- Untuk Einstein, kontribusi mungkin mencakup teori relativitas, efek fotoelektrik, dan E=mc^2.
- Untuk Bohr, kontribusi mungkin termasuk model atom hidrogennya, karyanya pada mekanika kuantum, dan prinsip pelengkapnya.
Setelah kontribusi ini diuraikan, mereka dapat dinilai untuk menentukan:
- Subkueri 3: "Bagaimana teori Einstein berdampak pada perkembangan fisika modern?"
- Subkueri 4: "Bagaimana teori Bohr berdampak pada perkembangan fisika modern?"
Subkueri ini akan mengeksplorasi pengaruh pekerjaan setiap ilmuwan di lapangan, seperti bagaimana teori Einstein menyebabkan kemajuan dalam teori kosmologi dan kuantum, dan bagaimana pekerjaan Bohr berkontribusi pada pemahaman tentang struktur atom dan mekanika kuantum.
Menggabungkan hasil subkueri ini dapat membantu model bahasa membentuk respons yang lebih komprehensif mengenai siapa yang memberikan kontribusi yang lebih signifikan terhadap fisika modern, berdasarkan tingkat dan dampak kemajuan teoritis mereka. Metode ini menyederhanakan kueri kompleks asli dengan menangani komponen yang lebih spesifik dan dapat dijawab dan kemudian mensintesis temuan tersebut ke dalam jawaban yang koheren.
Router kueri
Ada kemungkinan bahwa organisasi Anda memutuskan untuk membagi korpus kontennya menjadi beberapa penyimpanan vektor atau seluruh sistem pengambilan. Dalam hal ini, pengembang dapat menggunakan router kueri, yang merupakan mekanisme yang secara cerdas menentukan indeks atau mesin pengambilan mana yang akan digunakan berdasarkan kueri yang disediakan. Fungsi utama router kueri adalah mengoptimalkan pengambilan informasi dengan memilih database atau indeks yang paling tepat yang dapat memberikan jawaban terbaik untuk kueri tertentu.
Router kueri biasanya berfungsi pada titik setelah kueri diformulasikan oleh pengguna tetapi sebelum dikirim ke sistem pengambilan apa pun. Berikut adalah alur kerja yang disederhanakan:
- Analisis Kueri: LLM atau komponen lain menganalisis kueri masuk untuk memahami konten, konteks, dan jenis informasi yang mungkin diperlukan.
- Pemilihan Indeks: Berdasarkan analisis, router kueri memilih satu atau beberapa dari beberapa indeks yang berpotensi tersedia. Setiap indeks mungkin dioptimalkan untuk berbagai jenis data atau kueri—misalnya, beberapa mungkin lebih cocok untuk kueri faktual, sementara yang lain mungkin unggul dalam memberikan pendapat atau konten subjektif.
- Pengiriman Kueri: Kueri kemudian dikirim ke indeks yang dipilih.
- Agregasi Hasil: Respons dari indeks yang dipilih diambil dan mungkin dikumpulkan atau diproses lebih lanjut untuk membentuk jawaban yang komprehensif.
- Pembuatan Jawaban: Langkah terakhir melibatkan pembuatan respons yang koheren berdasarkan informasi yang diambil, mungkin mengintegrasikan atau mensintesis konten dari berbagai sumber.
Organisasi Anda mungkin menggunakan beberapa mesin pengambilan atau indeks untuk kasus penggunaan berikut:
- Spesialisasi Jenis Data: Beberapa indeks mungkin mengkhususkan diri dalam artikel berita, yang lain dalam makalah akademik, namun yang lain dalam konten web umum atau database tertentu seperti untuk informasi medis atau hukum.
- Pengoptimalan Jenis Kueri: Indeks tertentu mungkin dioptimalkan untuk pencarian faktual cepat (misalnya, tanggal, peristiwa), sementara yang lain mungkin lebih baik untuk tugas penalaran kompleks atau kueri yang membutuhkan pengetahuan domain yang mendalam.
- Perbedaan Algoritma: Algoritma pengambilan yang berbeda dapat digunakan di mesin yang berbeda, seperti pencarian kesamaan berbasis vektor, pencarian berbasis kata kunci tradisional, atau model pemahaman semantik yang lebih canggih.
Bayangkan sistem berbasis RAG yang digunakan dalam konteks saran medis. Sistem memiliki akses ke beberapa indeks:
- Indeks makalah penelitian medis yang dioptimalkan untuk penjelasan terperinci dan teknis.
- Indeks studi kasus klinis yang memberikan contoh gejala dan perawatan dunia nyata.
- Indeks informasi kesehatan umum untuk kueri dasar dan informasi kesehatan publik.
Jika pengguna mengajukan pertanyaan teknis tentang efek biokimia obat baru, router kueri mungkin memprioritaskan indeks makalah penelitian medis karena fokus kedalaman dan teknisnya. Untuk pertanyaan tentang gejala umum penyakit umum, namun, indeks kesehatan umum mungkin dipilih untuk kontennya yang luas dan mudah dimengerti.
Langkah-langkah pemrosesan pasca-pengambilan
Pemrosesan pasca-pengambilan terjadi setelah komponen retriever mengambil potongan konten yang relevan dari database vektor seperti yang digambarkan dalam diagram:

Dengan potongan konten kandidat yang diambil, langkah selanjutnya adalah memvalidasi bahwa potongan artikel akan berguna saat menambah prompt LLM dan kemudian mulai menyiapkan prompt untuk disajikan ke LLM.
Pengembang harus mempertimbangkan beberapa aspek permintaan. Perintah yang menyertakan terlalu banyak informasi suplemen dan beberapa (mungkin informasi yang paling penting) dapat diabaikan. Demikian pula, perintah yang menyertakan informasi yang tidak relevan dapat berdampak pada jawaban.
Pertimbangan lain adalah jarum dalam masalah tumpukan jerami, istilah yang mengacu pada kekhasan yang diketahui dari beberapa LLM di mana konten di awal dan akhir prompt memiliki bobot yang lebih besar ke LLM daripada konten di tengah.
Terakhir, panjang jendela konteks maksimum LLM dan jumlah token yang diperlukan untuk menyelesaikan perintah yang luar biasa panjang (terutama saat berhadapan dengan kueri dalam skala besar) harus dipertimbangkan.
Untuk menangani masalah ini, alur pemrosesan pasca-pengambilan mungkin menyertakan langkah-langkah berikut:
- Hasil pemfilteran - Dalam langkah ini, pengembang memastikan bahwa potongan artikel yang dikembalikan oleh database vektor relevan dengan kueri. Jika tidak, hasilnya diabaikan saat menyusun permintaan untuk LLM.
- Peringkat ulang - Peringkatkan potongan artikel yang diambil dari penyimpanan vektor untuk memastikan detail yang relevan berada di dekat tepi (awal dan akhir) perintah.
- Kompresi perintah - Menggunakan model kecil dan murah yang dirancang untuk menggabungkan dan meringkas beberapa potongan artikel menjadi satu perintah terkompresi sebelum mengirimkannya ke LLM.
Langkah-langkah pemrosesan pasca-penyelesaian
Pemrosesan pasca-penyelesaian terjadi setelah kueri pengguna dan semua gugus konten telah dikirim ke LLM, seperti yang digambarkan dalam diagram berikut:

Setelah perintah selesai oleh LLM, saatnya untuk memvalidasi penyelesaian untuk memastikan bahwa jawabannya akurat. Alur pemrosesan pasca-penyelesaian mungkin mencakup langkah-langkah berikut:
- Cek fakta - Ini bisa mengambil banyak formulir, tetapi niatnya adalah untuk mengidentifikasi klaim tertentu yang dibuat dalam artikel yang disajikan sebagai fakta dan kemudian untuk memeriksa fakta-fakta tersebut untuk akurasi. Jika langkah pemeriksaan fakta gagal, mungkin tepat untuk mengkueri ulang LLM dengan harapan jawaban yang lebih baik atau mengembalikan pesan kesalahan kepada pengguna.
- Pemeriksaan kebijakan - Ini adalah baris pertahanan terakhir untuk memastikan bahwa jawaban tidak berisi konten berbahaya, baik kepada pengguna atau organisasi.
Evaluasi
Mengevaluasi hasil sistem non-deterministik tidak sesederhana, misalnya, pengujian unit atau integrasi yang akrab bagi sebagian besar pengembang. Ada beberapa faktor yang perlu dipertimbangkan:
- Apakah pengguna puas dengan hasil yang mereka dapatkan?
- Apakah pengguna mendapatkan respons yang akurat terhadap pertanyaan mereka?
- Bagaimana cara mengambil umpan balik pengguna? Apakah kami memiliki kebijakan yang membatasi data apa yang dapat kami kumpulkan tentang data pengguna?
- Untuk diagnosis tentang respons yang tidak memuaskan, apakah kita memiliki visibilitas ke semua pekerjaan yang menjawab pertanyaan? Apakah kita menyimpan log dari setiap tahap dalam alur inferensi input dan output sehingga kita dapat melakukan analisis akar penyebab?
- Bagaimana kita dapat membuat perubahan pada sistem tanpa regresi atau degradasi hasil?
Menangkap dan bertindak berdasarkan umpan balik dari pengguna
Seperti disebutkan sebelumnya, pengembang mungkin perlu bekerja dengan tim privasi organisasi mereka untuk merancang mekanisme pengambilan umpan balik dan telemetri, pengelogan, dll. untuk mengaktifkan forensik dan analisis akar penyebab pada sesi kueri tertentu.
Langkah selanjutnya adalah mengembangkan alur penilaian. Kebutuhan akan alur penilaian muncul dari kompleksitas dan sifat intensif waktu menganalisis umpan balik verbatim dan akar penyebab respons yang disediakan oleh sistem AI. Analisis ini sangat penting karena melibatkan penyelidikan setiap respons untuk memahami bagaimana kueri AI menghasilkan hasil, memeriksa kesesuaian potongan konten yang digunakan dari dokumentasi, dan strategi yang digunakan dalam membagi dokumen ini.
Selain itu, ini melibatkan mempertimbangkan langkah-langkah pra-atau pasca-pemrosesan tambahan yang dapat meningkatkan hasilnya. Pemeriksaan terperinci ini sering mengungkap kesenjangan konten, terutama ketika tidak ada dokumentasi yang cocok sebagai respons terhadap kueri pengguna.
Oleh karena itu, membangun alur penilaian menjadi penting untuk mengelola skala tugas-tugas ini secara efektif. Alur yang efisien akan menggunakan alat kustom untuk mengevaluasi metrik yang mempertanyakan kualitas jawaban yang disediakan oleh AI. Sistem ini akan menyederhanakan proses penentuan mengapa jawaban tertentu diberikan pada pertanyaan pengguna, dokumen mana yang digunakan untuk menghasilkan jawaban tersebut, dan efektivitas alur inferensi yang memproses kueri.
Himpunan data emas
Salah satu strategi untuk mengevaluasi hasil sistem non-deterministik seperti sistem obrolan RAG adalah dengan menerapkan "himpunan data emas". Himpunan data emas adalah serangkaian pertanyaan yang dikumpulkan dengan jawaban, metadata yang disetujui (seperti topik dan jenis pertanyaan), referensi ke dokumen sumber yang dapat berfungsi sebagai kebenaran dasar untuk jawaban, dan bahkan variasi (frasa yang berbeda untuk menangkap keragaman bagaimana pengguna mungkin mengajukan pertanyaan yang sama).
"Himpunan data emas" mewakili "skenario kasus terbaik" dan memungkinkan pengembang mengevaluasi sistem untuk melihat seberapa baik performanya, dan melakukan pengujian regresi saat menerapkan fitur atau pembaruan baru.
Menilai bahaya
Pemodelan bahaya adalah metodologi yang bertujuan untuk memperkirakan potensi bahaya, menemukan kekurangan dalam produk yang mungkin menimbulkan risiko bagi individu, dan mengembangkan strategi proaktif untuk mengurangi risiko tersebut.
Untuk alat yang dirancang untuk menilai dampak teknologi, terutama sistem AI, akan menampilkan beberapa komponen utama berdasarkan prinsip pemodelan bahaya seperti yang diuraikan dalam sumber daya yang disediakan.
Fitur utama alat evaluasi bahaya mungkin mencakup:
Identifikasi Pemangku Kepentingan: Alat ini akan membantu pengguna mengidentifikasi dan mengategorikan berbagai pemangku kepentingan yang terkena dampak teknologi, termasuk pengguna langsung, pihak yang terkena dampak tidak langsung, dan entitas lain seperti generasi mendatang atau faktor non-manusia seperti masalah lingkungan (.
Kategori dan Deskripsi Bahaya: Ini akan mencakup daftar komprehensif potensi bahaya, seperti kehilangan privasi, tekanan emosional, atau eksploitasi ekonomi. Alat ini dapat memandu pengguna melalui berbagai skenario yang menggambarkan bagaimana teknologi dapat menyebabkan bahaya ini, membantu mengevaluasi konsekuensi yang dimaksudkan dan tidak diinginkan.
Penilaian Tingkat Keparahan dan Probabilitas: Alat ini akan memungkinkan pengguna untuk menilai tingkat keparahan dan probabilitas setiap bahaya yang diidentifikasi, memungkinkan mereka untuk memprioritaskan masalah mana yang harus ditangani terlebih dahulu. Ini mungkin termasuk penilaian kualitatif dan dapat didukung oleh data jika tersedia.
Strategi Mitigasi: Setelah mengidentifikasi dan mengevaluasi bahaya, alat ini akan menyarankan potensi strategi mitigasi. Ini dapat mencakup perubahan pada desain sistem, lebih banyak perlindungan, atau solusi teknologi alternatif yang meminimalkan risiko yang diidentifikasi.
Mekanisme Umpan Balik: Alat ini harus menggabungkan mekanisme untuk mengumpulkan umpan balik dari pemangku kepentingan, memastikan bahwa proses evaluasi bahaya bersifat dinamis dan responsif terhadap informasi dan perspektif baru.
Dokumentasi dan Pelaporan: Untuk membantu transparansi dan akuntabilitas, alat ini akan memfasilitasi pembuatan laporan terperinci yang mendokumentasikan proses penilaian bahaya, temuan, dan tindakan yang diambil untuk mengurangi potensi risiko.
Fitur-fitur ini tidak hanya akan membantu mengidentifikasi dan mengurangi risiko, tetapi juga membantu dalam merancang sistem AI yang lebih etis dan bertanggung jawab dengan mempertimbangkan spektrum dampak yang luas dari awal.
Untuk informasi selengkapnya, lihat:
Menguji dan memverifikasi perlindungan
Artikel ini menguraikan beberapa proses yang bertujuan untuk mengurangi kemungkinan bahwa sistem obrolan berbasis RAG dapat dieksploitasi atau disusupi. Red-teaming memainkan peran penting dalam memastikan mitigasi efektif. Red-teaming melibatkan simulasi tindakan adversary yang ditujukan untuk aplikasi untuk mengungkap potensi kelemahan atau kerentanan. Pendekatan ini sangat penting dalam mengatasi risiko jailbreaking yang signifikan.
Untuk menguji dan memverifikasi perlindungan sistem obrolan berbasis RAG secara efektif, pengembang perlu menilai sistem ini dengan ketat di bawah berbagai skenario di mana pedoman ini dapat diuji. Ini tidak hanya memastikan ketahanan tetapi juga membantu menyempurnakan respons sistem untuk mematuhi standar etika dan prosedur operasional yang ditentukan.
Pertimbangan akhir yang mungkin memengaruhi keputusan desain aplikasi Anda
Berikut adalah daftar singkat hal-hal yang perlu dipertimbangkan dan pengamanan lainnya dari artikel ini yang memengaruhi keputusan desain aplikasi Anda:
- Mengakui sifat AI generatif yang tidak deterministik dalam desain Anda, merencanakan variabilitas dalam output dan menyiapkan mekanisme untuk memastikan konsistensi dan relevansi dalam respons.
- Menilai manfaat permintaan pengguna praproses terhadap potensi peningkatan latensi dan biaya. Menyederhanakan atau memodifikasi perintah sebelum pengiriman dapat meningkatkan kualitas respons tetapi dapat menambahkan kompleksitas dan waktu ke siklus respons.
- Selidiki strategi untuk paralelisasi permintaan LLM untuk meningkatkan performa. Pendekatan ini dapat mengurangi latensi tetapi memerlukan manajemen yang cermat untuk menghindari peningkatan kompleksitas dan implikasi biaya potensial.
Jika Anda ingin mulai bereksperimen dengan segera membangun solusi AI generatif, sebaiknya lihat Memulai obrolan menggunakan sampel data Anda sendiri untuk Python. Ada versi tutorial yang juga tersedia di .NET, Java, dan JavaScript.