Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam serangkaian artikel, kami membahas mekanisme pengambilan pengetahuan yang digunakan model bahasa besar (LLM) untuk menghasilkan respons. Secara default, LLM hanya memiliki akses ke data pelatihannya. Tetapi Anda dapat menambah model untuk menyertakan data real-time atau data privat.
Mekanisme pertama adalah retrieval-augmented generation (RAG). RAG adalah bentuk pra-pemrosesan yang menggabungkan pencarian semantik dengan priming kontekstual. Priming konteks dibahas secara rinci dalam Konsep dan Pertimbangan Utama untuk membangun solusi AI generatif.
Mekanisme kedua adalah penyempurnaan. Selama proses penyempurnaan, LLM dilatih lebih lanjut menggunakan himpunan data tertentu setelah pelatihan luas awalnya. Tujuannya adalah untuk menyesuaikan LLM untuk berkinerja lebih baik pada tugas atau untuk memahami konsep yang terkait dengan himpunan data. Proses ini membantu model mengkhususkan atau meningkatkan akurasi dan efisiensinya dalam menangani jenis input atau domain tertentu.
Bagian berikut menjelaskan kedua mekanisme ini secara lebih rinci.
Memahami RAG
RAG sering digunakan untuk mengaktifkan skenario "obrolan melalui data saya". Dalam skenario ini, organisasi memiliki korpus konten tekstual yang berpotensi besar, seperti dokumen, dokumentasi, dan data kepemilikan lainnya. Ini menggunakan corpus ini sebagai dasar untuk jawaban atas permintaan pengguna.
Pada tingkat tinggi, Anda membuat entri database untuk setiap dokumen atau untuk sebagian dokumen yang disebut potongan . Potongan diindeks berdasarkan penyematan , yaitu vektor (array) angka yang menggambarkan berbagai aspek dari dokumen. Saat pengguna mengirimkan kueri, Anda mencari database untuk dokumen serupa, lalu mengirimkan kueri dan dokumen ke LLM untuk menyusun jawaban.
Catatan
Kami menggunakan istilah retrieval-augmented generation (RAG) dengan cara yang fleksibel. Proses penerapan sistem obrolan berbasis RAG seperti yang diuraikan dalam artikel ini dapat diterapkan apakah Anda ingin menggunakan data eksternal dalam kapasitas pendukung (RAG) atau sebagai pusat respons (RCG). Perbedaan yang bernuansa tidak dibahas dalam sebagian besar bahan bacaan yang terkait dengan RAG.
Membuat indeks dokumen yang di-vektorisasi
Langkah pertama untuk membuat sistem obrolan berbasis RAG adalah membuat penyimpanan data vektor yang berisi penyematan vektor dokumen atau gugus. Pertimbangkan diagram berikut, yang menguraikan langkah-langkah dasar untuk membuat indeks dokumen yang di-vektorisasi.

Diagram mewakili alur data . Alur bertanggung jawab atas penyerapan, pemrosesan, dan manajemen data yang digunakan sistem. Alur mencakup data pra-pemrosesan yang akan disimpan dalam database vektor dan memastikan bahwa data yang diumpankan ke LLM dalam format yang benar.
Seluruh proses didorong oleh gagasan penyematan, yang merupakan representasi numerik data (biasanya kata, frasa, kalimat, atau bahkan seluruh dokumen) yang menangkap properti semantik input dengan cara yang dapat diproses oleh model pembelajaran mesin.
Untuk membuat penyematan, Anda mengirim potongan konten (kalimat, paragraf, atau seluruh dokumen) ke Azure OpenAI Embeddings API. API mengembalikan vektor. Setiap nilai dalam vektor mewakili karakteristik (dimensi) konten. Dimensi mungkin mencakup materi topik, makna semantik, sintaksis dan tata bahasa, penggunaan kata dan frasa, hubungan kontekstual, gaya, atau nada. Bersama-sama, semua nilai vektor mewakili ruang dimensi konten. Jika Anda memikirkan representasi 3D dari vektor yang memiliki tiga nilai, vektor tertentu berada di area tertentu dari bidang XYZ. Bagaimana jika Anda memiliki 1.000 nilai, atau bahkan lebih? Meskipun tidak mungkin bagi manusia untuk menggambar grafik 1.000 dimensi pada selembar kertas untuk membuatnya lebih dimengerti, komputer tidak memiliki masalah memahami tingkat ruang dimensi tersebut.
Langkah berikutnya dari diagram menggambarkan penyimpanan vektor dan konten (atau penunjuk ke lokasi konten) dan metadata lainnya dalam database vektor. Database vektor seperti jenis database apa pun, tetapi dengan dua perbedaan:
- Database vektor menggunakan vektor sebagai indeks untuk mencari data.
- Database vektor menerapkan algoritma yang disebut pencarian kesamaan kosinus , juga disebut tetangga terdekat . Algoritma menggunakan vektor yang paling cocok dengan kriteria pencarian.
Dengan korpus dokumen yang disimpan dalam database vektor, pengembang dapat membangun komponen retriever untuk mengambil dokumen yang cocok dengan kueri pengguna. Data digunakan untuk memberikan LLM informasi yang dibutuhkan untuk menjawab kueri pengguna.
Menjawab pertanyaan dengan menggunakan dokumen Anda
Sistem RAG pertama kali menggunakan pencarian semantik untuk menemukan artikel yang mungkin berguna bagi LLM ketika menyusun jawaban. Langkah selanjutnya adalah mengirim artikel yang cocok dengan perintah asli pengguna ke LLM untuk menyusun jawaban.
Pertimbangkan diagram berikut sebagai implementasi RAG sederhana (kadang-kadang disebut RAG naif):
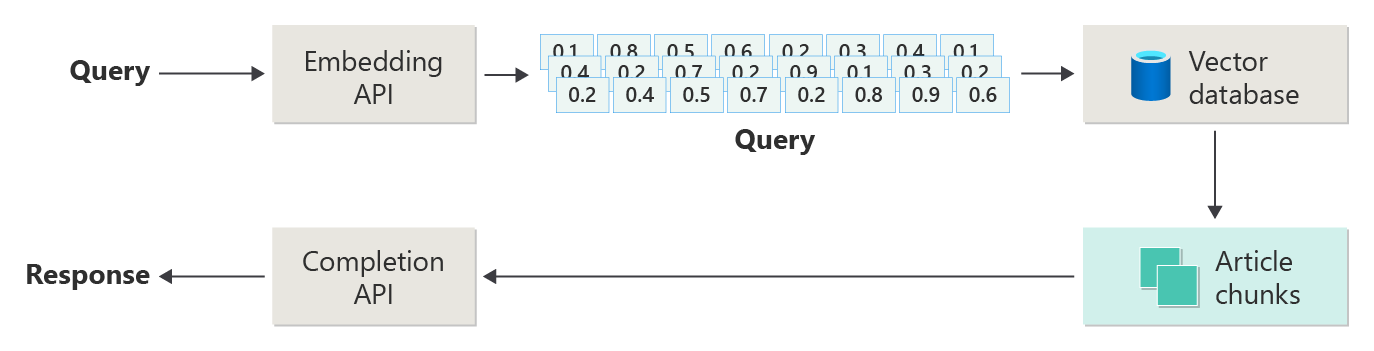
Dalam diagram, pengguna mengirimkan kueri. Langkah pertama adalah membuat penyematan untuk permintaan pengguna untuk mengembalikan vektor. Langkah selanjutnya adalah mencari dokumen-dokumen atau bagian dokumen dalam database vektor yang merupakan kecocokan tetangga terdekat.
kesamaan Kosinus adalah ukuran yang membantu menentukan seberapa mirip dua vektor. Pada dasarnya metrik menilai kosinus sudut di antara mereka. Kesamaan kosinus yang mendekati 1 menunjukkan tingkat kesamaan yang tinggi (sudut kecil). Kesamaan dekat -1 menunjukkan perbedaan (sudut hampir 180 derajat). Metrik ini sangat penting untuk tugas seperti kesamaan dokumen, di mana tujuannya adalah untuk menemukan dokumen yang memiliki konten atau makna yang sama.
Algoritma tetangga terdekat bekerja dengan menemukan vektor terdekat (tetangga) untuk titik di ruang vektor. Dalam algoritma k-nearest neighbors (KNN), k mengacu pada jumlah tetangga terdekat yang perlu dipertimbangkan. Pendekatan ini banyak digunakan dalam klasifikasi dan regresi, di mana algoritma memprediksi label titik data baru berdasarkan label mayoritas k tetangga terdekat dalam set pelatihan. Kesamaan KNN dan kosinus sering digunakan bersama dalam sistem seperti mesin rekomendasi, di mana tujuannya adalah untuk menemukan item yang paling mirip dengan preferensi pengguna, yang diwakili sebagai vektor di ruang penyematan.
Anda mengambil hasil terbaik dari pencarian tersebut dan mengirimkan konten yang sesuai dengan permintaan pengguna untuk menghasilkan respons yang diharapkan terinformasi oleh konten yang cocok.
Tantangan dan pertimbangan
Sistem RAG memiliki serangkaian tantangan implementasinya. Privasi data sangat penting. Sistem harus menangani data pengguna secara bertanggung jawab, terutama ketika mengambil dan memproses informasi dari sumber eksternal. Persyaratan komputasi juga bisa signifikan. Baik proses pengambilan maupun proses generatif bersifat intensif sumber daya. Memastikan akurasi dan relevansi respons saat mengelola bias dalam data atau model adalah pertimbangan penting lainnya. Pengembang harus menavigasi tantangan ini dengan hati-hati untuk menciptakan sistem RAG yang efisien, etis, dan berharga.
Membangun sistem pembuatan berbasis retrieval-augmented yang canggih memberi Anda informasi lebih lanjut tentang menyiapkan data dan jalur inferensi untuk mendukung sistem RAG yang siap untuk produksi.
Jika Anda ingin mulai bereksperimen dengan segera membangun solusi AI generatif, sebaiknya lihat Memulai obrolan menggunakan sampel data Anda sendiri untuk Python. Tutorial ini juga tersedia untuk .NET, Java, dan JavaScript.
Menyempurnakan model
Dalam konteks LLM, penyempurnaan adalah proses penyesuaian parameter model dengan melatihnya pada himpunan data khusus domain setelah LLM awalnya dilatih pada himpunan data yang besar dan beragam.
LLM dilatih (telah dilatih sebelumnya) pada himpunan data yang luas, struktur bahasa yang menggenggam, konteks, dan berbagai pengetahuan. Tahap ini melibatkan pembelajaran pola bahasa umum. Penyempurnaan menambahkan lebih banyak pelatihan ke model yang telah dilatih sebelumnya berdasarkan himpunan data tertentu yang lebih kecil. Fase pelatihan sekunder ini bertujuan untuk menyesuaikan model untuk berkinerja lebih baik pada tugas tertentu atau memahami domain tertentu, meningkatkan akurasi dan relevansinya untuk aplikasi khusus tersebut. Selama penyempurnaan, bobot model disesuaikan untuk lebih memprediksi atau memahami nuansa himpunan data yang lebih kecil ini.
Beberapa pertimbangan:
- Spesialisasi: Menyempurnakan menyesuaikan model dengan tugas tertentu, seperti analisis dokumen hukum, interpretasi teks medis, atau interaksi layanan pelanggan. Spesialisasi ini membuat model lebih efektif di area tersebut.
- Efisiensi: Lebih efisien untuk menyempurnakan model yang telah dilatih sebelumnya untuk tugas tertentu daripada melatih model dari awal. Penyempurnaan membutuhkan lebih sedikit data dan lebih sedikit sumber daya komputasi.
- Adaptabilitas: Penyempurnaan memungkinkan adaptasi ke tugas atau domain baru yang bukan bagian dari data pelatihan asli. Kemampuan beradaptasi LLM menjadikannya alat serbaguna untuk berbagai aplikasi.
- Peningkatan performa: Untuk tugas yang berbeda dari data yang dilatih model secara awal, penyesuaian dapat mengarah pada performa yang lebih baik. Penyempurnaan menyesuaikan model untuk memahami bahasa, gaya, atau terminologi tertentu yang digunakan di domain baru.
- Personalisasi: Dalam beberapa aplikasi, penyempurnaan dapat membantu mempersonalisasi respons atau prediksi model agar sesuai dengan kebutuhan atau preferensi spesifik pengguna atau organisasi. Namun, penyempurnaan memiliki kelemahan dan batasan tertentu. Memahami faktor-faktor ini dapat membantu Anda memutuskan kapan harus memilih penyempurnaan versus alternatif seperti RAG.
- Persyaratan data: Penyempurnaan memerlukan himpunan data yang cukup besar dan berkualitas tinggi yang khusus untuk tugas atau domain target. Mengumpulkan dan mengumpulkan himpunan data ini bisa menjadi tantangan dan intensif sumber daya.
- Risiko penyesuaian berlebihan: Penyesuaian berlebihan adalah risiko, terutama dengan kumpulan data yang kecil. Overfitting membuat model berkinerja optimal pada data pelatihan tetapi berkinerja buruk pada data baru yang belum pernah diujikan. Generalisasi menurun ketika overfitting terjadi.
- Biaya dan sumber daya: Meskipun lebih sedikit sumber daya intensif daripada pelatihan dari awal, penyempurnaan masih memerlukan sumber daya komputasi, terutama untuk model besar dan himpunan data. Biaya mungkin tidak terjangkau untuk beberapa pengguna atau proyek.
- Pemeliharaan dan pembaruan: Model yang disempurnakan mungkin memerlukan pembaruan rutin agar tetap efektif seiring perubahan informasi khusus domain dari waktu ke waktu. Pemeliharaan yang sedang berlangsung ini membutuhkan sumber daya dan data tambahan.
- pergeseran model: Karena model disempurnakan untuk tugas tertentu, model tersebut mungkin kehilangan sebagian pemahaman bahasa umum dan fleksibilitasnya. Fenomena ini disebut penyimpangan model .
Menyesuaikan model melalui penyempurnaan menjelaskan cara menyempurnakan model. Pada tingkat tinggi, Anda memberikan himpunan data JSON tentang pertanyaan potensial dan jawaban yang disukai. Dokumentasi menunjukkan bahwa ada peningkatan yang nyata dengan menyediakan 50 hingga 100 pasangan tanya jawab, tetapi angka yang tepat sangat bervariasi pada kasus penggunaan.
Penyesuaian vs. RAG
Di permukaan, mungkin tampak seperti ada sedikit tumpang tindih antara penyempurnaan dan RAG. Memilih antara penyempurnaan dan pembuatan tambahan pengambilan tergantung pada persyaratan khusus tugas Anda, termasuk harapan performa, ketersediaan sumber daya, dan kebutuhan akan kekhususan domain versus generalisasi.
Kapan menggunakan penyetelan alih-alih RAG:
- Performa khusus Tugas: Penyempurnaan lebih disukai ketika performa tinggi pada tugas tertentu sangat penting, dan ada data khusus domain yang memadai untuk melatih model secara efektif tanpa risiko overfitting yang signifikan.
- Kontrol atas data: Jika Anda memiliki data eksklusif atau sangat khusus yang secara signifikan berbeda dari data yang dilatih model dasar, penyempurnaan memungkinkan Anda memasukkan pengetahuan unik ini ke dalam model.
- Kebutuhan terbatas untuk pembaruan real time: Jika tugas tidak mengharuskan model untuk terus diperbarui dengan informasi terbaru, penyempurnaan dapat lebih efisien karena model RAG biasanya memerlukan akses ke database eksternal up-to-date atau internet untuk menarik data terbaru.
Kapan memilih RAG daripada fine-tuning:
- Konten dinamis atau konten yang berkembang: RAG lebih cocok untuk tugas di mana memiliki informasi terbaru sangat penting. Karena model RAG dapat menarik data dari sumber eksternal secara real-time, model tersebut lebih cocok untuk aplikasi seperti pembuatan berita atau menjawab pertanyaan tentang peristiwa terbaru.
- Generalisasi atas spesialisasi: Jika tujuannya adalah untuk mempertahankan performa yang kuat di berbagai topik daripada unggul di domain sempit, RAG mungkin lebih disukai. Ini menggunakan basis pengetahuan eksternal, memungkinkannya untuk menghasilkan respons di berbagai domain tanpa risiko overfitting ke himpunan data tertentu.
- Batasan sumber daya: Untuk organisasi dengan sumber daya terbatas untuk pengumpulan data dan pelatihan model, menggunakan pendekatan RAG mungkin menawarkan alternatif hemat biaya untuk penyempurnaan, terutama jika model dasar sudah berkinerja cukup baik pada tugas yang diinginkan.
Pertimbangan akhir untuk desain aplikasi
Berikut adalah daftar singkat hal-hal yang perlu dipertimbangkan dan kesimpulan lainnya dari artikel ini yang mungkin memengaruhi keputusan desain aplikasi Anda.
- Tentukan antara penyempurnaan dan RAG berdasarkan kebutuhan spesifik aplikasi Anda. Penyempurnaan mungkin menawarkan performa yang lebih baik untuk tugas khusus, sementara RAG mungkin memberikan fleksibilitas dan konten up-to-tanggal untuk aplikasi dinamis.