Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Azure DocumentDB menggunakan disk Premium SSD v2 untuk memberikan kinerja yang jauh lebih tinggi untuk beban kerja intensif I/O dengan memisahkan kapasitas penyimpanan dari IOPS dan pengaturan bandwidth.
Dengan penyimpanan Premium SSD v2 pada Azure DocumentDB, pengaturan IOPS dan bandwidth maksimum yang dapat dikonfigurasi tersedia secara default terlepas dari kapasitas penyimpanan yang dikonfigurasi untuk kluster. Kapasitas IOPS dan bandwidth tingkat Komputasi menentukan IOPS dan bandwidth yang dapat dicapai di lapisan penyimpanan tanpa perlu meningkatkan kapasitas penyimpanan.
Hanya kapasitas penyimpanan yang diperlukan yang perlu dipilih, sementara IOPS dan bandwidth tertinggi yang dapat dicapai dikonfigurasi secara otomatis oleh Azure DocumentDB tanpa biaya tambahan. Tidak diperlukan intervensi pengguna tambahan untuk memastikan kluster disiapkan untuk performa optimal. Hasilnya adalah peningkatan performa 12x tanpa biaya tambahan.
Sebelumnya, lompatan dari 5.000 IOPS menjadi 20.000 IOPS diperlukan untuk meningkatkan ukuran disk dari 1TB menjadi 20TB, bahkan tanpa adanya kebutuhan penyimpanan yang lebih tinggi. Dengan Premium SSD v2, 20.000 IOPS dapat dicapai pada disk 1TB yang sama selama tingkat komputasi kluster memiliki kapasitas untuk mendorong dan mempertahankan 20.000 IOPS. Selain itu, disk Premium SSD v2 dapat mendukung hingga 80.000 IOPS - peningkatan 4x daripada SSD Premium.
Guidance
Performa maximum untuk kluster DocumentDB Azure Anda sekarang hanya bergantung pada tingkat komute dan bukan ukuran penyimpanan. Mulailah dengan memilih hanya ukuran penyimpanan yang diinginkan yang diperlukan untuk kluster, lalu pilih tingkat komputasi yang menyediakan yang diperlukan (IOPS) dan throughput (MBps) untuk beban kerja Anda. Ditabulasikan di bawah ini adalah batas IOPS dan bandwidth tertinggi yang dapat dicapai dan berkelanjutan per tingkat komputasi.
Batasan IOPS dan throughput
Dengan disk Premium SSD v2, kluster akan dikonfigurasi secara otomatis dengan nilai terikat atas yang ditaulatasi di bawah ini, tanpa biaya tambahan.
| Tingkat Komputasi | Maks IOPS | Lebar pita maksimum (MBps) |
|---|---|---|
| M30 (2 inti) | 3,750 | 85 |
| M40 (4 inti) | 6.400 | 145 |
| M50 (8 inti) | 12.800 | 290 |
| M60 (16 core) | 25.600 | 600 |
| M80 (32 core) | 51.200 | 865 |
| M200 (64 core) | 80.000 | 1,200 |
Prerequisites
Langganan Azure
- Jika Anda tidak memiliki langganan Azure, buat akun gratis
Kluster Azure DocumentDB yang sudah ada
- Jika Anda tidak memiliki kluster, buat kluster baru
Gunakan lingkungan Bash di Azure Cloud Shell. Untuk informasi selengkapnya, lihat Mulai menggunakan Azure Cloud Shell.

Jika Anda lebih suka menjalankan perintah referensi CLI secara lokal, instal Azure CLI. Jika Anda menjalankan Windows atau macOS, pertimbangkan untuk menjalankan Azure CLI dalam kontainer Docker. Untuk informasi lebih lanjut, lihat Cara menjalankan Azure CLI di kontainer Docker.
Jika Anda menggunakan instalasi lokal, masuk ke Azure CLI dengan menggunakan perintah az login. Untuk menyelesaikan proses autentikasi, ikuti langkah-langkah yang ditampilkan di terminal Anda. Untuk opsi masuk lainnya, lihat Mengautentikasi ke Azure menggunakan Azure CLI.
Saat diminta, instal ekstensi Azure CLI saat pertama kali digunakan. Untuk informasi selengkapnya tentang ekstensi, lihat Menggunakan dan mengelola ekstensi dengan Azure CLI.
Jalankan az version untuk menemukan versi dan pustaka dependen yang terinstal. Untuk meng-upgrade ke versi terbaru, jalankan az upgrade.
- Terraform 1.2.0 atau yang lebih baru.
Membuat kluster dengan penyimpanan berkinerja tinggi
Konfigurasikan kluster menggunakan penyimpanan Premium SSD v2 (performa tinggi) sebagai bagian dari langkah pembuatan kluster.
Masuk ke portal Microsoft Azure (https://portal.azure.com).
Pada menu portal Microsoft Azure atau halaman Beranda, pilih Buat sumber daya.
Pada halaman Baru, cari dan pilih Azure DocumentDB.
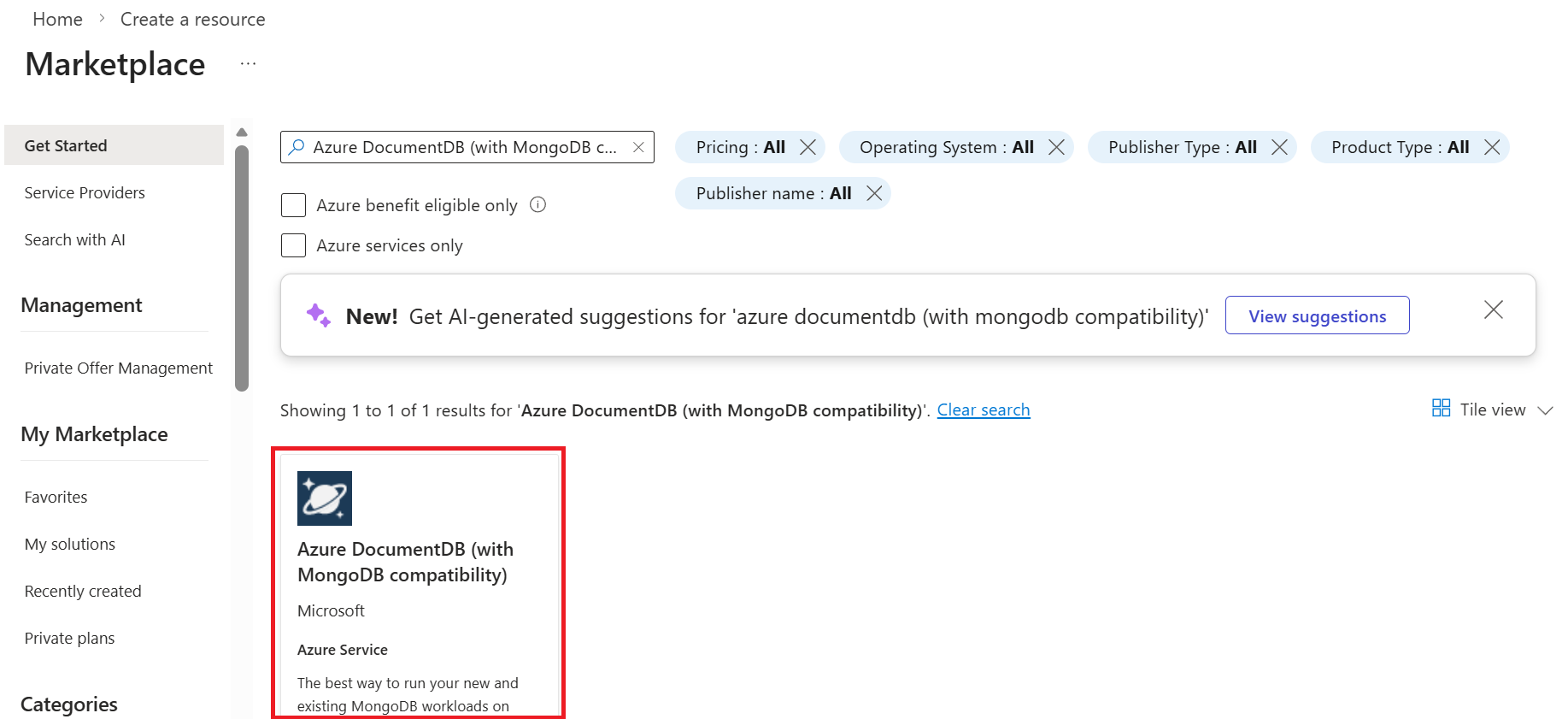
Pada halaman Buat kluster Azure DocumentDB dan di dalam bagian Dasar , pilih opsi Konfigurasi di dalam bagian Tingkat kluster .
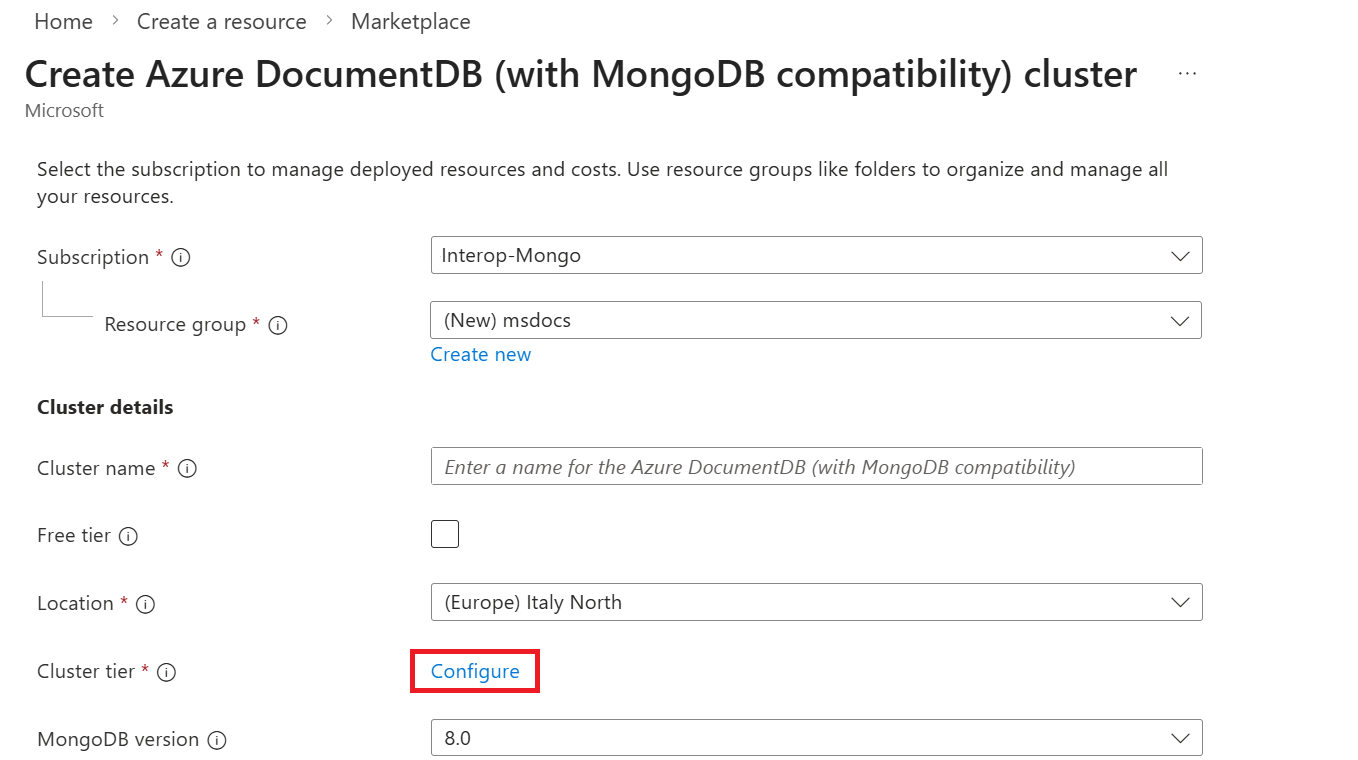
Pada halaman Konfigurasi , pilih tingkat kluster dan ukuran penyimpanan sesuai kebutuhan. Pilih jenis penyimpanan sebagai Premium SSD v2 untuk mengaktifkan penyimpanan berkinerja tinggi, lalu pilih Simpan untuk menerapkan perubahan.
Isi detail yang tersisa lalu pilih Tinjau + buat.
Tinjau pengaturan yang Anda berikan, kemudian pilih Buat. Perlu waktu beberapa menit untuk membuat kluster tersebut. Tunggu penyebaran sumber daya selesai.
Terakhir, pilih Buka sumber daya untuk menavigasi ke kluster Azure DocumentDB di portal.
Buka terminal baru.
Masuk ke Azure CLI.
Buat file Bicep baru untuk menentukan definisi peran Anda. Beri nama file main.bicep.
Tambahkan templat ini ke konten file. Gantikan
<cluster-name>,<location>,<username>, dan<password>dengan nilai yang sesuai.resource cluster 'Microsoft.DocumentDB/mongoClusters@2025-09-01' = { name: '<cluster-name>' location: '<location>' properties: { administrator: { userName: '<username>' password: '<password>' } serverVersion: '8.0' storage: { sizeGb: 32 type: 'PremiumSSDv2' } compute: { tier: 'M30' } sharding: { shardCount: 1 } highAvailability: { targetMode: 'Disabled' } } }Sebarkan templat Bicep menggunakan
az deployment group create. Tentukan nama templat Bicep dan ganti tempat penampung<resource-group>dengan nama grup sumber daya Azure yang dituju.az deployment group create \ --resource-group "<resource-group>" \ --template-file main.bicepTunggu hingga penerapan selesai. Tinjau output dari penyebaran.
Buka terminal baru.
Masuk ke Azure CLI.
Periksa langganan Azure Anda yang ditargetkan.
az account showTentukan kluster Anda dalam file Terraform baru. Beri nama file kluster.
tf.Tambahkan konfigurasi sumber daya ini ke konten file. Ganti placeholder
<cluster-name>,<resource-group>, dan<location>dengan nilai yang sesuai.variable "admin_username" { type = string description = "Administrator username for the cluster." sensitive = true } variable "admin_password" { type = string description = "Administrator password for the cluster." sensitive = true } terraform { required_providers { azurerm = { source = "hashicorp/azurerm" version = "~> 4.0" } } } provider "azurerm" { features {} } data "azurerm_resource_group" "existing" { name = "<resource-group>" } resource "azurerm_mongo_cluster" "cluster" { name = "<cluster-name>" resource_group_name = data.azurerm_resource_group.existing.name location = "<location>" administrator_username = var.admin_username administrator_password = var.admin_password shard_count = "1" compute_tier = "M30" high_availability_mode = "Disabled" storage_size_in_gb = "32" storage_type = "PremiumSSDv2" version = "8.0" }Tip
Untuk informasi selengkapnya tentang opsi menggunakan
azurerm_mongo_clustersumber daya, lihatazurermdokumentasi penyedia di Terraform Registry.Inisialisasi penerapan Terraform.
terraform init --upgradeBuat rencana eksekusi dan simpan ke file bernama cluster.tfplan. Berikan nilai saat diminta untuk
admin_usernamevariabel danadmin_password.ARM_SUBSCRIPTION_ID=$(az account show --query id --output tsv) terraform plan --out "cluster.tfplan"Nota
Perintah ini mengatur
ARM_SUBSCRIPTION_IDvariabel lingkungan untuk sementara. Pengaturan ini diperlukan untuk penyediaazurermyang dimulai dengan versi 4.0. Untuk informasi selengkapnya, lihat ID langganan diazurerm.Terapkan rencana eksekusi untuk menyebarkan kluster ke Azure.
ARM_SUBSCRIPTION_ID=$(az account show --query id --output tsv) terraform apply "cluster.tfplan"Tunggu hingga penerapan selesai. Tinjau output dari penyebaran.
Buka terminal baru.
Masuk ke Azure CLI.
Buat file JSON baru bernama cluster.json.
Tambahkan dokumen ini ke isi file. Ganti placeholder
<location>,<username>, dan<password>dengan nilai yang sesuai.{ "location": "<location>", "properties": { "administrator": { "userName": "<username>", "password": "<password>" }, "serverVersion": "8.0", "storage": { "sizeGb": 32, "type": "PremiumSSDv2" }, "compute": { "tier": "M30" }, "sharding": { "shardCount": 1 }, "highAvailability": { "targetMode": "Disabled" } } }az restGunakan perintah Azure CLI untuk membuat kluster baru dengan konfigurasi yang ditentukan dalam file JSON. Tentukan nama file JSON sebagaibodydari permintaan dan ganti placeholder berikut:Description <subscription-id>Identifikasi unik langganan Azure target Anda <resource-group>Nama grup sumber daya Azure target Anda <cluster-name>Nama unik kluster Azure DocumentDB baru Anda az rest \ --method "GET" \ --url "https://management.azure.com/subscriptions/<subscription-id>/resourceGroups/<resource-group>/providers/Microsoft.DocumentDB/mongoClusters/<cluster-name>/users?api-version=2025-09-01" \ --body @cluster.jsonTip
Gunakan
az account showuntuk mendapatkan pengidentifikasi unik langganan Azure target Anda.Tunggu hingga penerapan selesai. Tinjau output dari penyebaran.
Batasan penyimpanan performa tinggi saat ini (penyimpanan Premium SSD v2)
Kunci yang dikelola pengguna (CMK) tidak didukung oleh penyimpanan Premium SSD v2.
Pengaturan kapasitas penyimpanan pada disk Premium SSD v2 dapat disesuaikan hingga empat kali dalam periode 24 jam. Untuk kluster yang baru dibuat, maksimal tiga penyesuaian kapasitas penyimpanan dapat dilakukan selama 24 jam pertama.
Replikasi dari SSD Premium ke Premium SSD v2 hanya didukung untuk skenario migrasi. Replikasi yang sedang berlangsung tidak didukung karena SSD Premium tidak dapat mencocokkan performa SSD Premium v2 dan dapat mengakibatkan latensi yang lebih tinggi.
Migrasi online dari SSD Premium ke Premium SSD v2 saat ini tidak didukung. Untuk meningkatkan dari Premium SSD ke Premium SSD V2, Anda dapat melakukan pemulihan point-in-time ke server baru menggunakan Premium SSD v2. Atau, Anda dapat membuat replika baca dari server SSD Premium ke server Premium SSD v2 dan mempromosikannya setelah replikasi selesai.
Jika Anda melakukan operasi apa pun yang memerlukan hidrasi disk, kesalahan berikut mungkin terjadi. Kesalahan ini terjadi karena disk Premium SSD v2 tidak mendukung operasi apa pun saat disk masih menghidrasi.
- Pesan kesalahan: Tidak dapat menyelesaikan operasi karena disk masih dihidrasi. Coba lagi setelah beberapa saat.
- Operasi yang dapat memicu perilaku ini meliputi:
- Memungkinkan ketersediaan tinggi (HA), melakukan penskalaan komputasi, dan penskalaan penyimpanan secara cepat dan berturut-turut.
- Ini juga termasuk failover yang dipicu layanan untuk menjamin ketersediaan tinggi.
- Menggunakan PITR (point-in-time-restore) untuk membuat kluster baru dan segera mengaktifkan Ketersediaan Tinggi saat disk masih dihidrasi.
- Sebagai praktik terbaik, saat menggunakan disk Premium SSD v2, bagi operasi ini secara berkala atau selesaikan secara berurutan, memastikan pengisian data pada disk selesai di antara setiap tindakan.