Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Tutorial ini menunjukkan cara membuat kluster Apache HBase di Microsoft Azure HDInsight, membuat tabel HBase, dan mengkueri tabel dengan menggunakan Apache Hive. Untuk informasi umum tentang HBase, lihat Ikhtisar HDInsight HBase.
Dalam tutorial ini, Anda akan mempelajari cara:
- Membuat kluster HBase Apache
- Membuat tabel HBase dan menyisipkan data
- Menggunakan Apache Hive untuk melakukan query Apache HBase
- Menggunakan API HBase REST menggunakan Curl
- Periksa status kluster
Prasyarat
Klien SSH. Untuk informasi selengkapnya, lihat Menyambungkan ke HDInsight (Apache Hadoop) menggunakan SSH.
Bash. Contoh dalam artikel ini menggunakan shell Bash pada Windows 10 untuk perintah curl. Lihat Panduan Penginstalan Subsistem Windows untuk Linux untuk Windows 10 sebagai langkah-langkah penginstalan. Shell Unix lainnya juga berfungsi. Contoh curl, dengan sedikit modifikasi, dapat dijalankan pada Command Prompt Windows. Atau Anda dapat menggunakan cmdlet Windows PowerShell Invoke-RestMethod.
Membuat kluster HBase Apache
Prosedur berikut menggunakan templat Azure Resource Manager untuk membuat kluster HBase. Templat ini juga membuat akun Microsoft Azure Storage default dependen. Untuk memahami parameter yang digunakan dalam prosedur dan metode pembuatan kluster lainnya, lihat Membuat kluster Hadoop berbasis Linux di Microsoft Azure HDInsight.
Pilih gambar berikut untuk membuka templat di portal Microsoft Azure. Templat terletak di Azure Quickstart Templates.

Dari dialog Penyebaran kustom, masukkan nilai berikut ini:
Properti Deskripsi Langganan Pilih langganan Azure Anda yang digunakan untuk membuat kluster. Grup sumber daya Buat grup manajemen Sumber Daya Azure atau gunakan grup yang sudah ada. Lokasi Tentukan lokasi grup sumber daya. ClusterName Masukkan nama untuk kluster HBase. Nama untuk masuk dan kata sandi kluster Nama login default adalah admin.nama pengguna dan kata sandi SSH Nama pengguna default adalah sshuser.Parameter lainnya bersifat opsional.
Setiap kluster memiliki dependensi akun Microsoft Azure Storage. Setelah Anda menghapus kluster, data tetap berada di akun penyimpanan. Nama akun penyimpanan default kluster adalah nama kluster dengan "penyimpanan" ditambahkan. Nilai ini telah tertanam secara permanen di bagian variabel template.
Lalu, pilih Saya menyetujui syarat dan ketentuan yang dinyatakan di atas, lalu pilih Pembelian. Dibutuhkan sekitar 20 menit untuk membuat kluster.
Setelah kluster HBase dihapus, Anda dapat membuat kluster HBase lain dengan menggunakan kontainer blob default yang sama. Kluster baru mengambil tabel HBase yang Anda buat di kluster asli. Untuk menghindari inkonsistensi, kami sarankan Anda menonaktifkan tabel HBase sebelum Anda menghapus kluster.
Membuat tabel dan menyisipkan data
Anda dapat menggunakan SSH untuk menyambungkan ke kluster HBase lalu menggunakan Apache HBase Shell untuk membuat tabel HBase, menyisipkan data, dan mengkueri data.
Untuk kebanyakan orang, data muncul dalam format tabular:

Di HBase (implementasi Cloud BigTable), data yang sama terlihat seperti:

Untuk menggunakan shell HBase
Gunakan perintah
sshuntuk menyambungkan ke kluster HBase Anda. Edit perintah berikut dengan menggantiCLUSTERNAMEdengan nama kluster Anda, lalu masukkan perintah:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netGunakan
hbase shellperintah untuk memulai shell interaktif HBase. Masukkan perintah berikut di koneksi SSH Anda:hbase shellGunakan
createperintah untuk membuat tabel HBase dengan keluarga dua kolom. Nama tabel dan kolom sensitif terhadap huruf besar/kecil. Masukkan perintah berikut:create 'Contacts', 'Personal', 'Office'Gunakan
listperintah untuk mencantumkan semua tabel di HBase. Masukkan perintah berikut:listGunakan
putperintah untuk menyisipkan nilai pada kolom tertentu dalam baris tertentu dalam tabel tertentu. Masukkan perintah berikut:put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'Gunakan
scanperintah untuk memindai dan mengembalikanContactsdata tabel. Masukkan perintah berikut:scan 'Contacts'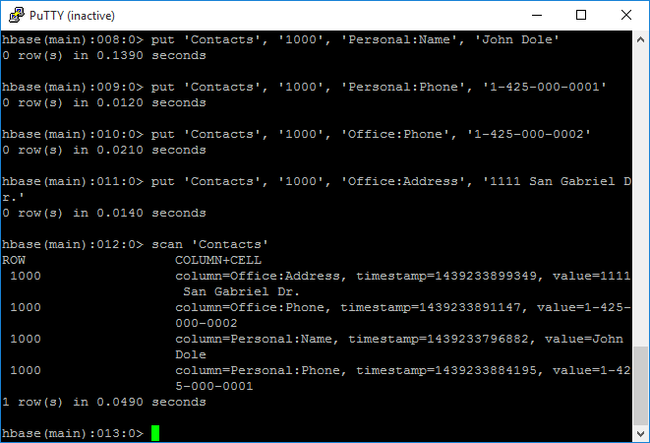
Gunakan
getperintah untuk mengambil konten baris. Masukkan perintah berikut:get 'Contacts', '1000'Anda melihat hasil yang sama seperti menggunakan
scanperintah karena hanya ada satu baris.Untuk informasi selengkapnya tentang skema tabel HBase, lihat Pengantar Desain Skema Apache HBase. Untuk perintah HBase lainnya, lihat panduan referensi Apache HBase.
Gunakan
exitperintah untuk menghentikan shell interaktif HBase. Masukkan perintah berikut:exit
Untuk memuat data dalam jumlah besar ke dalam tabel HBase kontak
HBase menyertakan beberapa metode memuat data ke dalam tabel. Untuk informasi selengkapnya, lihat Memuat secara massal.
Contoh file data dapat ditemukan dalam kontainer blob publik, wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt. Konten file data adalah:
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
Anda dapat secara opsional membuat file teks dan mengunggah file ke akun penyimpanan Anda sendiri. Untuk mengetahui petunjuknya, lihat Mengunggah data untuk pekerjaan Apache Hadoop di Microsoft Azure HDInsight.
Prosedur ini menggunakan Contactstabel HBase yang Anda buat dalam prosedur terakhir.
Dari koneksi ssh terbuka Anda, jalankan perintah berikut untuk mengubah file data ke StoreFiles dan simpan di jalur relatif yang ditentukan oleh
Dimporttsv.bulk.output.hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txtJalankan perintah berikut untuk mengunggah data dari
/example/data/storeDataFileOutputke tabel HBase:hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput ContactsAnda dapat membuka shell HBase, dan menggunakan
scanperintah untuk mencantumkan konten tabel.
Menggunakan Apache Hive untuk melakukan kueri Apache HBase
Anda dapat mengkueri data dalam tabel HBase dengan menggunakan Apache Hive. Di bagian ini, Anda membuat tabel Hive yang memetakan dengan tabel HBase dan menggunakannya untuk melakukan query pada data dalam tabel HBase Anda.
Dari koneksi ssh terbuka Anda, gunakan perintah berikut untuk memulai Beeline:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n adminUntuk informasi lebih lanjut tentang Beeline, lihat Gunakan Hive dengan Hadoop di HDInsight dengan Beeline.
Jalankan skrip HiveQL berikut untuk membuat tabel Hive yang memetakan ke tabel HBase. Pastikan Anda telah membuat tabel sampel yang direferensikan sebelumnya di artikel ini dengan menggunakan shell HBase sebelum Anda menjalankan pernyataan ini.
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');Jalankan skrip HiveQL berikut ini untuk mengkueri data dalam tabel HBase:
SELECT count(rowkey) AS rk_count FROM hbasecontacts;Untuk keluar dari Beeline, gunakan
!exit.Untuk keluar dari koneksi ssh Anda, gunakan
exit.
Pisahkan Kluster Hive dan HBase
Kueri Apache Hive untuk mengakses data HBase tidak perlu dijalankan dari kluster HBase. Kluster apa pun yang dilengkapi dengan Apache Hive (termasuk Spark, Hadoop, HBase, atau Interactive Query) dapat digunakan untuk mengkueri data HBase, asalkan langkah-langkah berikut selesai:
- Kedua kluster harus dilampirkan ke Microsoft Azure Virtual Network dan Subnet yang sama
- Salin
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xmldari headnode kluster HBase ke headnode kluster Hive dan node pekerja.
Kluster yang Aman
Data HBase juga dapat dikueri dari Hive menggunakan HBase dengan fitur ESP:
- Saat mengikuti pola multi-kluster, kedua kluster harus mendukung ESP.
- Untuk mengizinkan Apache Hive mengkueri data HBase, pastikan bahwa
hivepengguna diberikan izin untuk mengakses data HBase melalui plugin HBase Apache Ranger - Ketika Anda menggunakan kluster terpisah yang diaktifkan oleh ESP, konten
/etc/hostsdari kluster headnode HBase harus ditambahkan ke/etc/hostsdari kluster headnode dan node pekerja Apache Hive.
Catatan
Setelah Anda menskalakan salah satu kluster, /etc/hosts harus ditambahkan lagi
Menggunakan REST API HBase melalui Curl
REST API HBase diamankan melalui autentikasi dasar. Anda harus selalu membuat permintaan dengan menggunakan HTTP Aman (HTTPS) untuk membantu memastikan bahwa informasi masuk Anda dikirim dengan aman ke server.
Untuk mengaktifkan REST API HBase di kluster HDInsight, tambahkan skrip mulai khusus berikut ke bagian Tindakan Skrip. Anda dapat menambahkan skrip startup saat membuat kluster atau setelah kluster dibuat. Untuk Jenis Node, pilih Server Wilayah untuk memastikan bahwa skrip hanya dijalankan di Server Wilayah HBase. Skrip ini memulai proksi HBase REST pada port 8090 di server region.
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fiAtur variabel lingkungan untuk kemudahan penggunaan. Edit perintah berikut dengan mengganti
MYPASSWORDdengan kata sandi masuk kluster. GantiMYCLUSTERNAMEdengan nama kluster HBase Anda. Kemudian masukkan perintah.export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAMEGunakan perintah berikut ini untuk mencantumkan tabel HBase yang sudah ada:
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Gunakan perintah berikut ini untuk membuat tabel HBase baru dengan keluarga dua kolom:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -vSkema disediakan dalam format JSON.
Gunakan perintah berikut untuk menyisipkan beberapa data:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -vBase64 mengodekan nilai yang ditentukan dalam sakelar
-d. Dalam contoh:MTAwMA==: 1000
UGVyc29uYWw6TmFtZQ==: Pribadi: Nama
Sm9obiBEb2xl: John Dole
false-row-key memungkinkan Anda menyisipkan beberapa nilai yang banyak (dikelompokkan).
Gunakan perintah berikut untuk mendapatkan baris:
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
Catatan
Pemindaian melalui titik akhir kluster belum didukung.
Untuk informasi selengkapnya tentang HBase Rest, lihat Panduan Referensi Apache HBase.
Catatan
Thrift tidak didukung oleh HBase di HDInsight.
Saat Anda menggunakan Curl atau komunikasi REST lainnya dengan WebHCat, Anda harus mengautentikasi permintaan dengan memberikan nama pengguna dan kata sandi untuk administrator kluster HDInsight. Anda juga harus menggunakan nama kluster sebagai bagian dari Uniform Resource Identifier (URI) yang digunakan untuk mengirim permintaan ke server:
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
Anda harus menerima respons yang mirip dengan respons berikut:
{"status":"ok","version":"v1"}
Periksa status kluster
HBase dalam Microsoft Azure HDInsight dilengkapi dengan UI Web untuk memantau kluster. Menggunakan UI Web, Anda dapat meminta statistik atau informasi tentang wilayah.
Untuk mengakses HBase Master UI
Masuk ke Ambari Web UI di
https://CLUSTERNAME.azurehdinsight.nettempatCLUSTERNAMEnama klaster HBase Anda.Pilih HBase dari menu kiri.
Pilih Tautan cepat di bagian atas halaman, arahkan ke link node Zookeeper aktif, lalu pilih HBase Master UI. UI dibuka di tab browser lain:
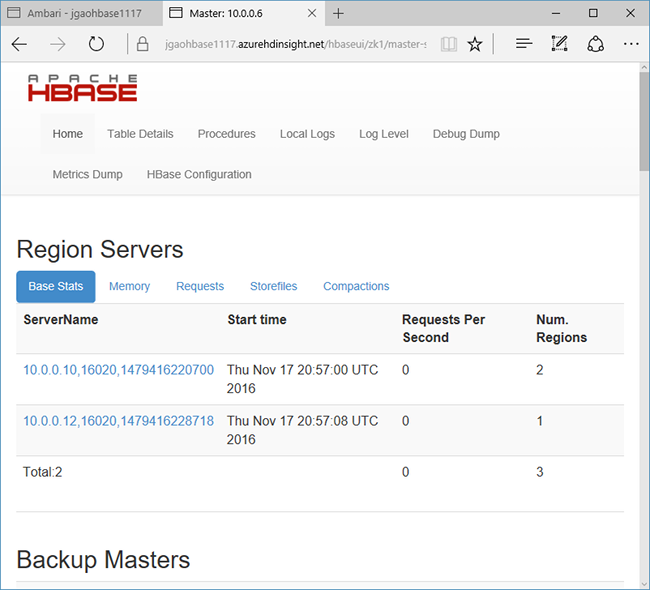
HBase Master UI berisi bagian-bagian berikut:
- server wilayah
- master cadangan
- tabel
- tugas
- atribut perangkat lunak
Fasilitas rekreasi klaster
Setelah kluster HBase dihapus, Anda dapat membuat kluster HBase lain dengan menggunakan kontainer blob default yang sama. Kluster baru mengambil tabel HBase yang Anda buat di kluster asli. Untuk menghindari inkonsistensi, kami sarankan Anda menonaktifkan tabel HBase sebelum Anda menghapus kluster.
Anda dapat menggunakan perintah HBasedisable 'Contacts'.
Membersihkan sumber daya
Jika Anda tidak akan terus menggunakan aplikasi ini, hapus kluster yang Anda buat dengan langkah-langkah berikut:
- Masuk ke portal Azure.
- Dalam kotak Pencarian di bagian atas, ketik Microsoft Azure HDInsight.
- Pilih kluster Microsoft Azure HDInsight di Layanan.
- Dalam daftar kluster Microsoft Azure HDInsight yang muncul, klik ... di samping kluster yang Anda buat untuk tutorial ini.
- Klik Hapus. Klik Ya.
Langkah berikutnya
Dalam tutorial ini, Anda belajar cara membuat kluster Apache HBase. Dan cara membuat tabel dan menampilkan data dalam tabel tersebut dari shell HBase. Anda juga mempelajari cara menggunakan kueri Apache Hive pada data dalam tabel HBase. Dan cara menggunakan HBase C# REST API untuk membuat tabel HBase dan mengambil data dari tabel. Untuk mempelajari selengkapnya, lihat: