Menyiapkan kluster di HDInsight dengan Apache Hadoop, Apache Spark, Apache Kafka, dan banyak lagi
Pelajari cara menyiapkan dan melakukan konfigurasi Apache Hadoop, Apache Spark, Apache Kafka, Interactive Query, Apache HBase, atau di HDInsight. Selain itu, pelajari cara kustomisasi klaster dan menambahkan keamanan dengan bergabung ke domain.
Klaster Hadoop terdiri dari beberapa komputer virtual (node) yang digunakan untuk pemrosesan tugas terdistribusi. Azure HDInsight menangani rincian penerapan penginstalan dan konfigurasi node individu, sehingga Anda hanya perlu memberikan informasi konfigurasi umum.
Penting
Tagihan klaster HDInsight mulai dihitung setelah klaster dibuat dan akan berhenti saat klaster dihapus. Penagihan dihitung pro-rata per menit, sehingga Anda harus selalu menghapus kluster jika tidak digunakan lagi. Pelajari cara menghapus klaster.
Jika menggunakan beberapa klaster bersama-sama, Anda dapat membuat jaringan virtual, dan jika Anda menggunakan klaster Spark, Anda juga dapat menggunakan Hive Warehouse Connector. Untuk informasi selengkapnya, lihat Merencanakan jaringan virtual untuk Azure HDInsight dan Mengintegrasikan Apache Spark dan Apache Hive dengan Hive Warehouse Connector.
Metode penyiapan klaster
Tabel berikut ini menampilkan berbagai metode yang dapat Anda gunakan untuk menyiapkan klaster HDInsight.
| Klaster dibuat dengan | Browser web | Baris perintah | REST API | SDK |
|---|---|---|---|---|
| Portal Azure | ✅ | |||
| Azure Data Factory | ✅ | ✅ | ✅ | ✅ |
| Azure CLI | ✅ | |||
| Azure PowerShell | ✅ | |||
| cURL | ✅ | ✅ | ||
| Templat Azure Resource Manager | ✅ |
Artikel ini memandu Anda melakukan penyiapan di portal Azure, tempat Anda dapat membuat klaster HDInsight.
Dasar
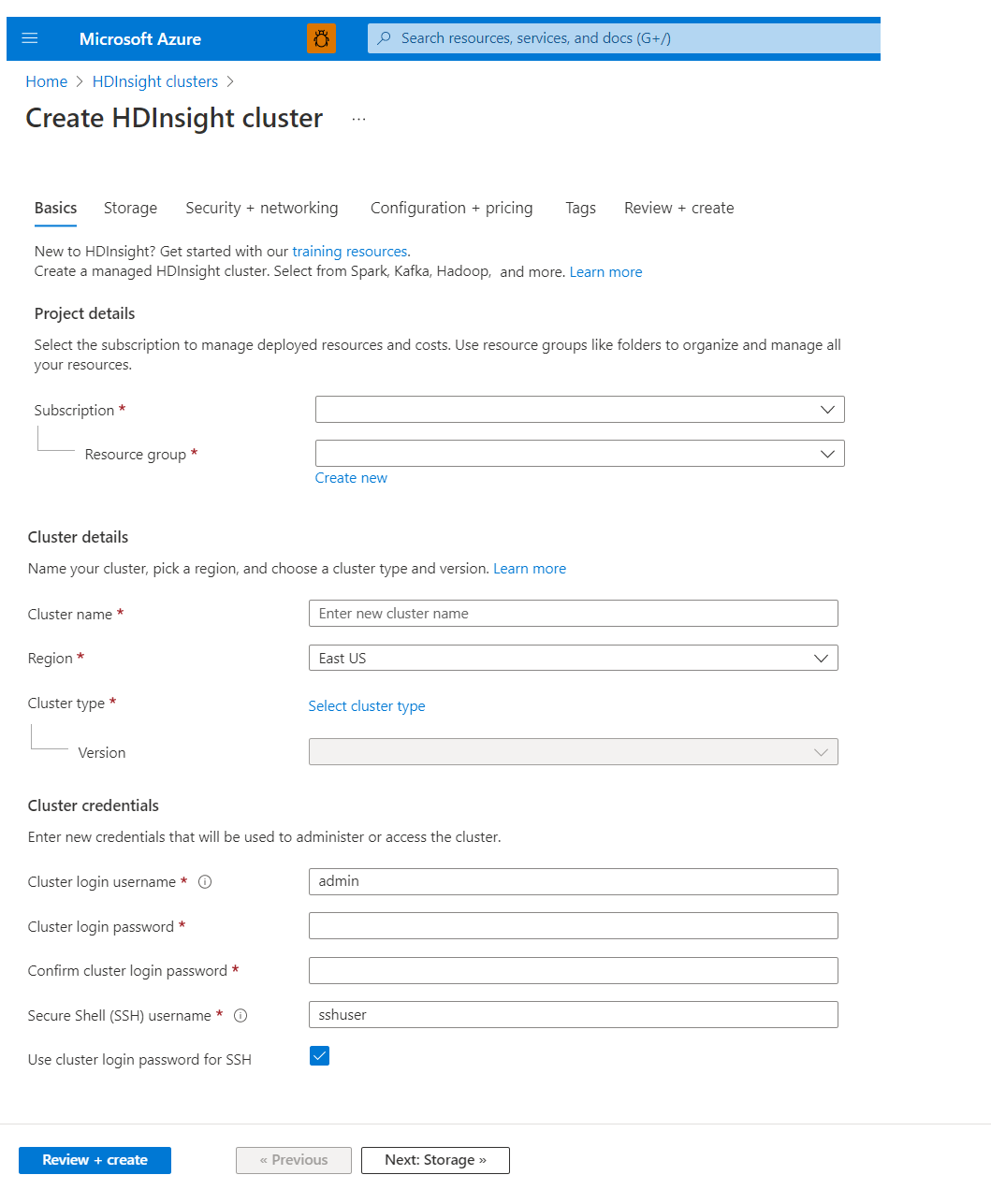
Detail proyek
Azure Resource Manager membantu Anda menggunakan sumber daya dalam aplikasi Anda sebagai grup, yang disebut sebagai grup sumber daya Azure. Anda dapat menyebarkan, memperbarui, memantau, atau menghapus semua sumber daya untuk aplikasi Anda dalam satu operasi terkoordinasi.
Detail kluster
Nama kluster
Nama klaster HDInsight memiliki batasan berikut:
- Karakter yang diperbolehkan: a-z, 0-9, A-Z
- Panjang maksimum: 59
- Nama yang dipesan: apps
- Cakupan penamaan klaster adalah untuk semua Azure, di semua langganan. Jadi nama klaster harus unik untuk seluruh dunia.
- Enam karakter pertama harus unik dalam jaringan virtual
Wilayah
Anda tidak perlu menentukan lokasi klaster secara eksplisit: klaster berada di lokasi yang sama dengan penyimpanan default. Untuk daftar region yang didukung, pilih daftar tarik turun Region pada harga HDInsight.
Jenis kluster
Azure HDInsight saat ini menyediakan jenis klaster berikut, masing-masing dengan set komponen untuk menyediakan fungsi tertentu.
Penting
Klaster HDInsight tersedia dalam berbagai jenis, masing-masing untuk satu beban kerja atau teknologi. Tidak ada metode yang didukung untuk membuat kluster yang menggabungkan beberapa jenis, seperti HBase pada satu kluster. Jika solusi Anda memerlukan teknologi yang tersebar melintasi beberapa jenis klaster HDInsight, jaringan virtual Azure dapat menghubungkan jenis klaster yang diperlukan.
| Jenis kluster | Fungsi |
|---|---|
| Hadoop | Kueri dan analisis batch dari data yang disimpan |
| HBase | Pemrosesan untuk sejumlah besar data NoSQL tanpa skema |
| Kueri Interaktif | Penembolokan dalam memori untuk kueri Hive yang interaktif dan lebih cepat |
| Kafka | Platform streaming terdistribusi yang dapat digunakan untuk membangun alur dan aplikasi data streaming waktu nyata |
| Spark | Pemrosesan dalam memori, kueri interaktif, pemrosesan stream batch mikro |
Versi
Pilih versi HDInsight untuk klaster ini. Untuk informasi selengkapnya, lihat Versi HDInsight yang didukung.
Kredensial klaster
Dengan klaster HDInsight, Anda dapat mengonfigurasi dua akun pengguna selama pembuatan klaster :
- Nama pengguna login klaster: Nama pengguna default adalah admin. Ia menggunakan konfigurasi dasar pada portal Azure. Kadang-kadang disebut "Pengguna klaster," atau "Pengguna HTTP."
- Nama pengguna Secure Shell (SSH) : Digunakan untuk terhubung ke klaster melalui SSH. Untuk informasi selengkapnya, lihat Menggunakan SSH dengan HDInsight.
Nama pengguna HTTP memiliki batasan berikut:
- Karakter khusus yang diperbolehkan:
_dan@ - Karakter tidak diperbolehkan:
#;."',/:!*?$(){}[]<>|&--=+%~^space' - Panjang maksimum: 20
Nama pengguna SSH memiliki batasan berikut:
- Karakter khusus yang diperbolehkan:
_dan@ - Karakter tidak diperbolehkan:
#;."',/:!*?$(){}[]<>|&--=+%~^space' - Panjang maksimum: 64
- Nama yang dipesan: hadoop, pengguna, oozie, sarang, dipetakan, ambari-qa, zookeeper, tez, hdfs, sqoop, yarn, hcat, ams, hbase, administrator, admin, pengguna, pengguna1, menguji, user2, test1, user3, admin1, 1, 123, a, ,
actuseradm, admin2, aspnet, cadangan, konsol, David, tamu, John, pemilik, root, server, sql, mendukung, support_388945a0, sys, test2, test3, user4, user5, spark
Penyimpanan
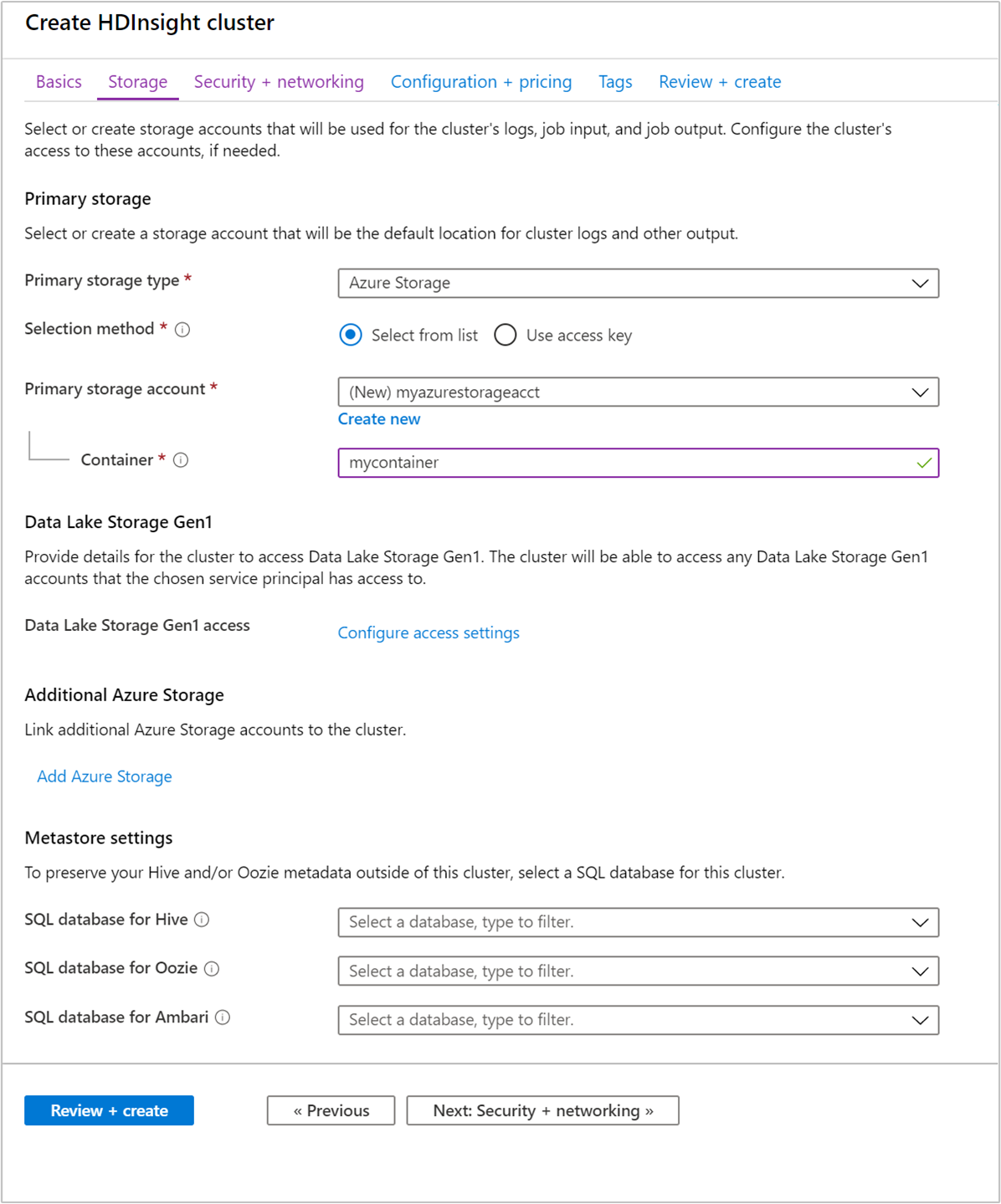
Meskipun penginstalan Hadoop lokal menggunakan Sistem File Terdistribusi Hadoop (HDFS) untuk penyimpanan pada klaster, di cloud Anda menggunakan titik akhir penyimpanan yang terhubung ke klaster. Penggunaan penyimpanan cloud berarti Anda dapat menghapus klaster HDInsight yang digunakan dengan aman untuk komputasi selagi tetap menyimpan data Anda.
Klaster HDInsight dapat menggunakan opsi penyimpanan berikut:
- Azure Data Lake Storage Gen2
- Tujuan Umum Azure Storage v2
-
- Blob Azure Storage Block (hanya didukung sebagai penyimpanan sekunder)
Untuk informasi selengkapnya tentang opsi penyimpanan dengan HDInsight, lihat Membandingkan opsi penyimpanan untuk digunakan dengan klaster Azure HDInsight.
Peringatan
Penggunaan akun penyimpanan tambahan di lokasi yang berbeda dari klaster HDInsight tidak didukung.
Selama konfigurasi, untuk titik akhir penyimpanan default, Anda menentukan kontainer blob dari akun Azure Storage atau Data Lake Storage. Penyimpanan default berisi aplikasi dan log sistem. Secara opsional, Anda dapat menentukan akun Microsoft Azure Storage tertaut tambahan dan akun Data Lake Storage yang dapat diakses klaster. Klaster HDInsight dan akun penyimpanan dependen harus berada di lokasi Azure yang sama.
Catatan
Fitur yang memerlukan transfer aman memberlakukan semua permintaan ke akun Anda melalui koneksi yang aman. Hanya kluster HDInsight versi 3.6 atau yang lebih baru yang mendukung fitur ini. Untuk mengetahui informasi selengkapnya, lihat Membuat kluster Apache Hadoop dengan akun penyimpanan transfer aman di Azure HDInsight.
Penting
Pengaktifan transfer penyimpanan yang aman setelah pembuatan klaster dapat mengakibatkan eror penggunaan akun penyimpanan Anda dan tidak disarankan. Lebih baik membuat klaster baru menggunakan akun penyimpanan dengan transfer aman sudah diaktifkan.
Catatan
Azure HDInsight tidak secara otomatis mentransfer, memindahkan, atau menyalin data Anda yang disimpan di Azure Storage dari satu region ke region lainnya.
Pengaturan metastore
Anda dapat membuat metastore Hive atau Apache Oozie opsional. Akan tetapi, tidak semua jenis klaster mendukung metastore, dan Azure Synapse Analytics tidak kompatibel dengan metastore.
Untuk mengetahui informasi selengkapnya, lihat Menggunakan penyimpanan metadata eksternal di Azure HDInsight.
Penting
Saat Anda membuat metastore kustom, jangan gunakan tanda hubung pendek, tanda hubung panjang, atau spasi dalam nama database. Hal ini dapat menyebabkan proses pembuatan klaster gagal.
Database SQL untuk Hive
Jika Anda ingin mempertahankan tabel Hive setelah Anda menghapus klaster HDInsight, gunakan metastore kustom. Anda kemudian dapat melampirkan metastore ke klaster HDInsight lain.
Metastore HDInsight yang dibuat untuk satu versi klaster HDInsight tidak dapat dibagikan di berbagai versi klaster HDInsight. Untuk daftar versi HDInsight, lihat Versi HDInsight yang didukung.
Penting
Metastore default menyediakan Microsoft Azure SQL Database dengan batas DTU tingkat dasar 5 (tidak dapat diiperbarui)! Cocok untuk tujuan pengujian dasar. Untuk beban kerja besar atau produksi, sebaiknya migrasi ke metastore eksternal.
Database SQL untuk Oozie
Untuk meningkatkan kinerja saat menggunakan Oozie, gunakan metastore kustom. Metastore juga dapat menyediakan akses ke data pekerjaan Oozie setelah Anda menghapus klaster Anda.
Database SQL untuk Ambari
Ambari digunakan untuk memantau klaster HDInsight, melakukan perubahan konfigurasi, dan menyimpan informasi manajemen klaster serta riwayat pekerjaan. Fitur Ambari DB kustom memungkinkan Anda untuk menyebarkan klaster baru dan mengatur Ambari dalam database eksternal yang Anda kelola. Untuk informasi selengkapnya, lihat Ambari DB Kustom.
Penting
Anda tidak dapat menggunakan kembali metastore Oozie kustom. Untuk menggunakan metastore Oozie kustom, Anda harus menyediakan Azure SQL Database kosong saat membuat klaster HDInsight.
Keamanan + jaringan
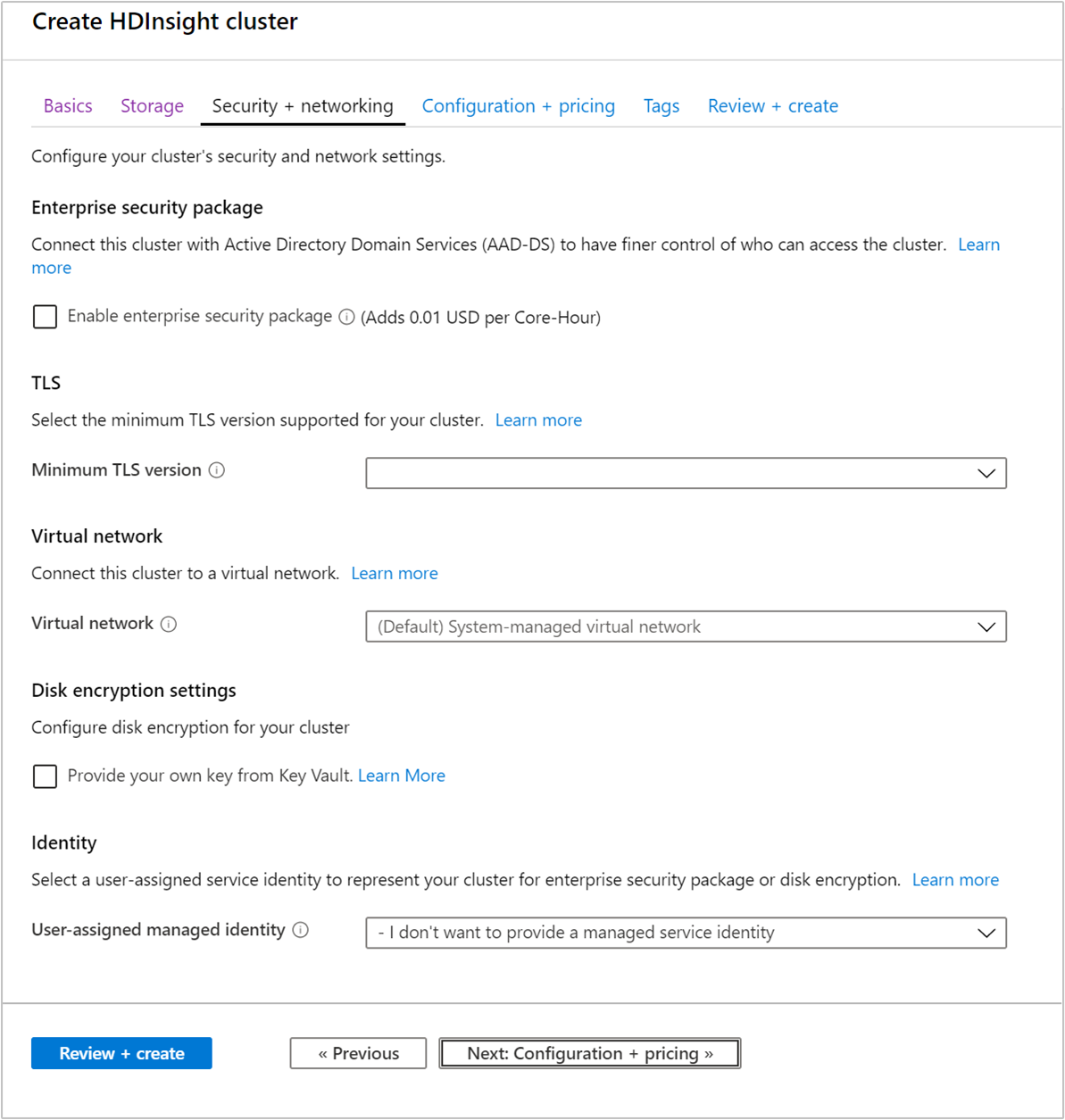
Paket Keamanan Enterprise
Untuk tipe klaster Hadoop, Spark, HBase, Kafka, dan Interactive Query, Anda dapat memilih untuk mengaktifkan Paket Keamanan Perusahaan. Paket ini menyediakan opsi untuk memiliki penyiapan kluster yang lebih aman dengan menggunakan Apache Ranger dan mengintegrasikan dengan MICROSOFT Entra ID. Untuk informasi selengkapnya, lihat Ikhtisar keamanan perusahaan di Azure HDInsight.
Paket keamanan Perusahaan memungkinkan Anda untuk mengintegrasikan HDInsight dengan Active Directory dan Apache Ranger. Beberapa pengguna dapat dibuat menggunakan paket keamanan Perusahaan.
Untuk informasi selengkapnya tentang pembuatan klaster HDInsight yang tergabung ke domain, lihat Membuat lingkungan sandbox HDInsight yang tergabung ke domain.
TLS
Untuk informasi selengkapnya, lihat Transport Layer Security
Jaringan virtual
Jika solusi Anda memerlukan teknologi yang tersebar melintasi beberapa jenis klaster HDInsight, jaringan virtual Azure dapat menghubungkan jenis klaster yang diperlukan. Konfigurasi ini memungkinkan klaster, dan kode apa pun yang Anda sebarkan ke mereka, untuk langsung berkomunikasi satu sama lain.
Untuk informasi selengkapnya tentang penggunaan jaringan virtual Azure dengan HDInsight, lihat Merencanakan jaringan virtual untuk HDInsight.
Untuk contoh penggunaan dua jenis klaster dalam jaringan virtual Azure, lihat Menggunakan Apache Spark Structured Streaming dengan Apache Kafka. Untuk informasi selengkapnya tentang penggunaan HDInsight dengan jaringan virtual, termasuk persyaratan konfigurasi khusus untuk jaringan virtual, lihat Merencanakan jaringan virtual untuk HDInsight.
Pengaturan enkripsi disk
Untuk informasi selengkapnya, lihat Enkripsi disk kunci yang dikelola konsumen.
Proksi Kafka REST
Pengaturan ini hanya tersedia untuk jenis klaster Kafka. Untuk informasi selengkapnya, lihat Penggunaan proksi REST.
Identitas
Untuk informasi selengkapnya, lihat Mengelola identitas di Azure HDInsight.
Konfigurasi + harga
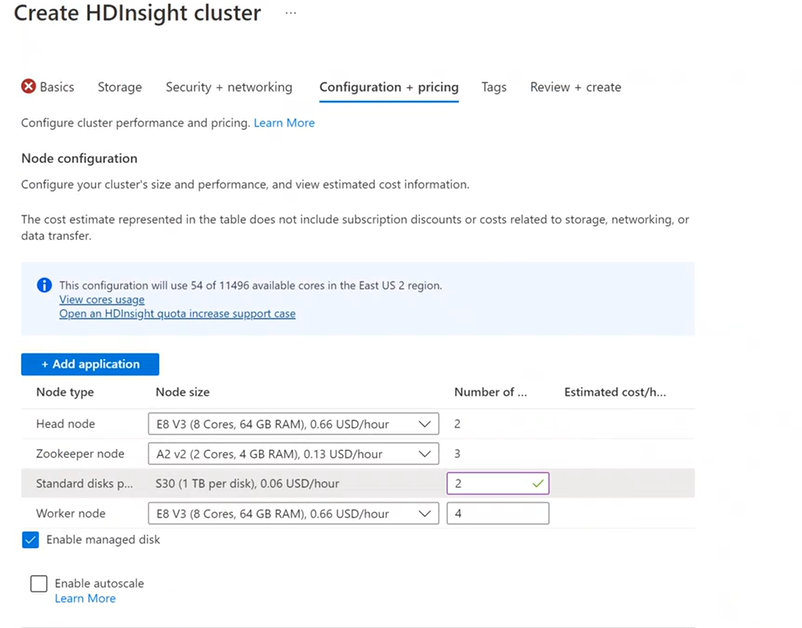
Anda ditagih untuk penggunaan node selama klaster masih ada. Penagihan dimulai saat klaster dibuat dan berhenti saat klaster dihapus. Klaster tidak dapat di-de-alokasikan atau ditangguhkan.
Konfigurasi node
Setiap jenis klaster memiliki jumlah node, terminologi untuk node, dan ukuran VM default. Dalam tabel berikut, jumlah node untuk setiap jenis node ada dalam tanda kurung.
| Jenis | Simpul | Diagram |
|---|---|---|
| Hadoop | Head node (2), Node pekerja (1+) | 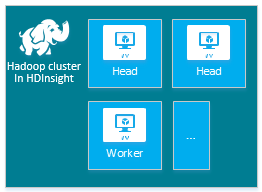
|
| HBase | Head server (2), server region (1+), node master/ZooKeeper (3) | 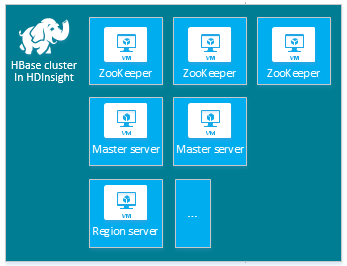
|
| Spark | Head node (2), node Pekerja (1+), node ZooKeeper (3) (gratis untuk ukuran A1 ZooKeeper VM) | 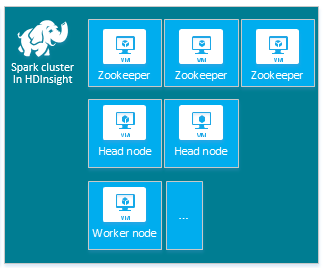
|
Untuk informasi selengkapnya, lihat Konfigurasi node default dan ukuran komputer virtual untuk klaster di "Apa saja komponen dan versi Hadoop di HDInsight?"
Biaya klaster HDInsight ditentukan oleh jumlah node dan ukuran komputer virtual untuk node.
Jenis klaster yang berbeda memiliki jenis node, jumlah node, dan ukuran node yang berbeda:
- Default jenis kluster Hadoop:
Dua head node
Empat node Pekerja
Jika Anda hanya mencoba HDInsight, kami menyarankan Anda menggunakan satu node Pekerja. Untuk informasi selengkapnya tentang harga HDInsight, lihat Harga HDInsight.
Catatan
Batas ukuran klaster bervariasi di antara langganan Azure. Hubungi Dukungan penagihan Azure untuk menambah batas.
Saat Anda menggunakan portal Azure untuk mengonfigurasi klaster, ukuran node tersedia melalui tab Konfigurasi + harga. Di portal, Anda juga dapat melihat biaya yang terkait dengan ukuran node yang berbeda.
Ukuran Mesin Virtual
Saat Anda menyebarkan klaster, pilih sumber daya komputasi berdasarkan solusi yang Anda rencanakan untuk disebarkan. VM berikut digunakan untuk klaster HDInsight:
- VM seri A dan D1-4: Ukuran VM Linux tujuan umum
- VM seri D11-14: Ukuran VM Linux yang dioptimalkan memori
Untuk mengetahui nilai apa yang harus Anda gunakan untuk menentukan ukuran VM saat membuat klaster menggunakan SDK yang berbeda atau saat menggunakan Azure PowerShell, lihat Ukuran VM yang akan digunakan untuk klaster HDInsight. Dari artikel tertaut, gunakan nilai di kolom Ukuran dari tabel.
Penting
Jika Anda membutuhkan lebih dari 32 simpul Pekerja di klaster, Anda harus memilih ukuran head node dengan setidaknya 8 inti dan RAM 14 GB.
Untuk info selengkapnya, lihat Ukuran untuk komputer virtual. Untuk informasi tentang harga berbagai ukuran, lihat Harga HDInsight.
Lampiran disk
Catatan
Disk yang ditambahkan hanya dikonfigurasi untuk direktori lokal manajer simpul dan bukan untuk direktori datanode
Kluster HDInsight dilengkapi dengan ruang disk yang telah ditentukan sebelumnya berdasarkan SKU. Jika Anda menjalankan beberapa aplikasi besar, dapat menyebabkan ruang disk yang tidak memadai, dengan kesalahan penuh disk - LinkId=221672#ERROR_NOT_ENOUGH_DISK_SPACE dan kegagalan pekerjaan.
Lebih banyak disk dapat ditambahkan ke kluster menggunakan fitur baru direktori lokal NodeManager. Pada saat pembuatan kluster Apache Hive dan Spark, jumlah disk dapat dipilih dan ditambahkan ke node pekerja. Disk yang dipilih, yang masing-masing berukuran 1 TB, akan menjadi bagian dari direktori lokal NodeManager.
- Dari tab Konfigurasi + harga
- Pilih opsi Aktifkan disk terkelola
- Dari disk Standar, Masukkan Jumlah disk
- Pilih Simpul pekerja Anda
Anda dapat memverifikasi jumlah disk dari tab Tinjau + buat, di bagianKonfigurasi kluster
Menambah aplikasi
Aplikasi HDInsight adalah aplikasi yang dapat diinstal pengguna pada kluster HDInsight berbasis Linux. Anda dapat menggunakan aplikasi yang disediakan oleh Microsoft, pihak ketiga, atau yang Anda kembangkan sendiri. Untuk informasi selengkapnya, lihat Menginstal aplikasi Apache Hadoop pihak ketiga pada Azure HDInsight.
Sebagian besar aplikasi HDInsight diinstal pada node tepi kosong. Node tepi kosong adalah komputer virtual Linux dengan alat klien yang sama diinstal dan dikonfigurasi seperti di head node. Anda dapat menggunakan simpul tepi untuk mengakses kluster, menguji aplikasi klien Anda, dan menghosting aplikasi klien Anda. Untuk informasi selengkapnya, lihat Menggunakan node tepi kosong di HDInsight.
Tindakan skrip
Anda dapat menginstal komponen tambahan atau melakukan kustomisasi konfigurasi klaster dengan menggunakan skrip selama pembuatan. Skrip semacam itu diminta melalui Tindakan Skrip, yang merupakan opsi konfigurasi yang dapat digunakan dari portal Azure, cmdlet HDInsight Windows PowerShell, atau HDInsight .NET SDK. Untuk informasi selengkapnya, lihat Kustomisasi klaster HDInsight menggunakan Tindakan Skrip.
Beberapa komponen asli Java, seperti Apache Mahout dan Cascading, dapat dijalankan pada klaster sebagai file Java Archive (JAR). File JAR ini dapat didistribusikan ke Azure Storage dan dikirimkan ke klaster HDInsight dengan mekanisme pengiriman pekerjaan Hadoop. Untuk informasi selengkapnya, lihat Mengirimkan pekerjaan Apache Hadoop secara terprogram.
Catatan
Jika Anda mengalami masalah saat menyebarkan file JAR ke klaster HDInsight, atau memerintahkan file JAR di klaster HDInsight, hubungi Dukungan Microsoft.
Cascading tidak didukung oleh HDInsight dan tidak memenuhi syarat untuk Dukungan Microsoft. Untuk daftar komponen yang didukung, lihat Apa yang baru dalam versi klaster yang disediakan oleh HDInsight.
Terkadang, Anda ingin mengonfigurasikan file konfigurasi berikut selama proses pembuatan:
- clusterIdentity.xml
- core-site.xml
- gateway.xml
- hbase-env.xml
- hbase-site.xml
- hdfs-site.xml
- hive-env.xml
- hive-site.xml
- mapred-site
- oozie-site.xml
- oozie-env.xml
- tez-site.xml
- webhcat-site.xml
- yarn-site.xml
Untuk informasi selengkapnya, lihat Kustomisasi klaster HDInsight menggunakan Bootstrap.
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk