Contoh streaming Apache Spark (DStream) dengan Apache Kafka di Azure HDInsight
Pelajari cara menggunakan Apache Spark untuk melakukan streaming data ke atau keluar dari Apache Kafka di Azure HDInsight menggunakan DStreams. Contoh ini menggunakan Jupyter Notebook yang berjalan pada kluster Spark.
Catatan
Langkah-langkah dalam dokumen ini membuat grup sumber daya Azure yang memuat Spark di Azure HDInsight dan Kafka di kluster Azure HDInsight. Kedua kluster ini terletak di dalam Azure Virtual Network, yang memungkinkan kluster Spark untuk langsung berkomunikasi dengan kluster Kafka.
Bila Anda sudah menyelesaikan langkah-langkah dalam dokumen ini, jangan lupa hapus kluster untuk menghindari biaya berlebih.
Penting
Contoh ini menggunakan DStreams, yang merupakan teknologi streaming Spark yang lebih lama. Misalnya yang menggunakan fitur streaming Spark yang lebih baru, lihat Streaming Spark Structured dengan dokumen Apache Kafka.
Membuat kluster
Apache Kafka di HDInsight tidak menyediakan akses ke broker Kafka melalui internet publik. Apa pun yang berkaitan dengan Kafka harus berada di jaringan virtual Azure yang sama dengan simpul di kluster Kafka. Dalam contoh ini, kluster Kafka dan Spark terletak di jaringan virtual Azure. Diagram berikut menunjukkan bagaimana komunikasi mengalir antara kluster-kluster:
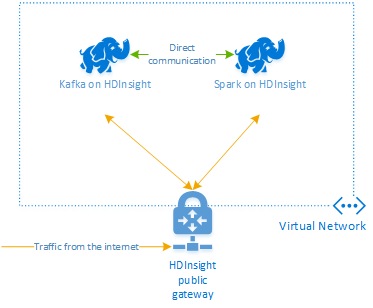
Catatan
Meskipun Kafka sendiri terbatas pada komunikasi dalam jaringan virtual, layanan lain di kluster seperti SSH dan Ambari dapat diakses melalui internet. Untuk informasi selengkapnya tentang port publik yang tersedia lewat HDInsight, lihat Port dan URI yang digunakan oleh HDInsight.
Meskipun Anda dapat membuat kluster jaringan virtual Azure, Kafka, dan Spark secara manual, hal ini lebih mudah menggunakan templat Azure Resource Manager. Gunakan langkah-langkah berikut untuk menggunakan kluster jaringan virtual Azure, Kafka, dan Spark ke langganan Azure Anda.
Gunakan tombol berikut untuk masuk ke Azure dan buka templat di portal Microsoft Azure.

Peringatan
Untuk menjamin ketersediaan Kafka pada HDInsight, kluster Anda harus berisi setidaknya empat simpul pekerja. Templat ini membuat kluster Kafka yang berisi empat simpul pekerja.
Templat ini membuat kluster HDInsight 4.0 untuk Kafka dan Spark.
Gunakan informasi berikut untuk mengisi entri di bagian Penyebaran kustom:
Properti Nilai Grup sumber daya Buat Grup atau pilih yang sudah ada. Lokasi Pilih lokasi yang secara geografis dekat dengan Anda. Nama kluster Dasar Nilai ini digunakan sebagai nama dasar untuk kluster Spark dan Kafka. Misalnya, memasukkan hdistreaming membuat kluster Spark bernama spark-hdistreaming dan kluster Kafka bernama kafka-hdistreaming. Nama Pengguna Masuk Kluster Nama pengguna admin untuk kluster Spark dan Kafka. Kata Sandi Masuk Kluster Kata sandi pengguna admin untuk kluster Spark dan Kafka. Nama Pengguna SSH Pengguna SSH membuat untuk kluster Spark dan Kafka. Kata Sandi SSH Kata sandi untuk pengguna SSH untuk kluster Spark dan Kafka. 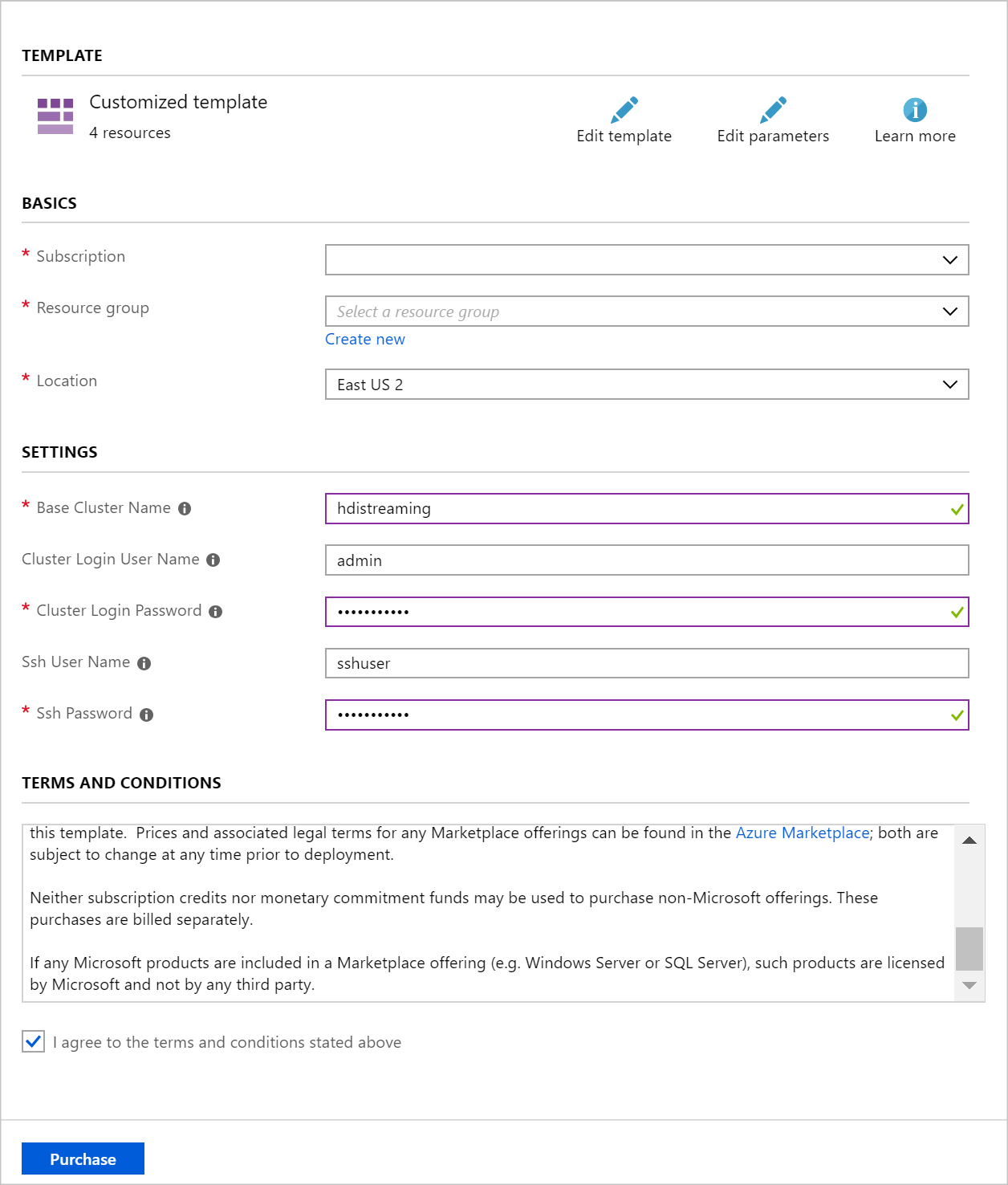
Baca Syarat dan Ketentuan, lalu pilih Saya menyetujui syarat dan ketentuan yang tercantum di atas.
Terakhir, pilih Beli. Dibutuhkan sekitar 20 menit untuk membuat kluster.
Setelah sumber daya dibuat, halaman ringkasan akan muncul.
Penting
Perhatikan bahwa nama-nama kluster Azure HDInsight adalah spark-BASENAME dan kafka-BASENAME, di mana BASENAME adalah nama yang Anda berikan ke template. Anda menggunakan nama-nama ini di langkah-langkah selanjutnya ketika menyambungkan ke kluster.
Menggunakan buku catatan
Kode untuk contoh yang dijelaskan dalam dokumen ini tersedia di https://github.com/Azure-Samples/hdinsight-spark-scala-kafka.
Menghapus kluster
Peringatan
Tagihan untuk kluster HDInsight dirata-rata per menit, baik Anda menggunakannya maupun tidak. Pastikan untuk menghapus kluster Anda setelah selesai menggunakannya. Lihat cara menghapus kluster HDInsight.
Karena langkah-langkah dalam dokumen ini membuat kedua kluster di grup sumber daya Azure yang sama, Anda bisa menghapus grup sumber daya di portal Microsoft Azure. Penghapusan grup menghapus semua sumber daya yang dibuat dengan mengikuti dokumen ini, Azure Virtual Network, dan akun penyimpanan yang digunakan oleh kluster.
Langkah berikutnya
Dalam contoh ini, Anda belajar cara menggunakan Spark untuk membaca dan menulis ke Kafka. Gunakan tautan berikut untuk menemukan cara lain untuk menggunakan Kafka: