Menggunakan MirrorMaker untuk mereplikasi topik Apache Kafka dengan Kafka pada Microsoft Azure HDInsight
Pelajari cara menggunakan fitur pencerminan Apache Kafka untuk mereplikasi topik ke kluster sekunder. Anda dapat menjalankan pencerminan sebagai proses berkelanjutan, atau terputus-putus, untuk memigrasikan data dari satu kluster ke kluster lainnya.
Dalam artikel ini, Anda akan menggunakan pencerminan untuk mereplikasi topik antara dua kluster HDInsight. Kluster ini berada di jaringan virtual yang berbeda di pusat data yang berbeda.
Peringatan
Jangan gunakan pencerminan sebagai sarana untuk mencapai toleransi kesalahan. Offset ke item dalam topik berbeda antara kluster primer dan sekunder, sehingga klien tidak dapat menggunakan keduanya secara bergantian. Jika khawatir dengan toleransi kesalahan, Anda harus mengatur replikasi untuk topik dalam kluster Anda. Untuk informasi selengkapnya, lihat Memulai dengan Apache Kafka pada Microsoft Azure HDInsight.
Cara kerja pencerminan Apache Kafka
Pencerminan bekerja dengan menggunakan alat MirrorMaker, yang merupakan bagian dari Apache Kafka. MirrorMaker menggunakan catatan dari topik di kluster primer, lalu membuat salinan lokal di kluster sekunder. MirrorMaker menggunakan satu (atau lebih) konsumen yang membaca dari kluster primer, dan produsen yang menulis ke kluster lokal (sekunder).
Penyiapan pencerminan yang paling berguna untuk pemulihan bencana menggunakan kluster Kafka di berbagai wilayah Azure. Untuk mencapai hal ini, jaringan virtual tempat kluster berada dibuat serekan secara bersamaan.
Diagram berikut menggambarkan proses pencerminan dan cara komunikasi mengalir antar kluster:

Kluster primer dan sekunder dapat berlainan dalam jumlah simpul dan partisi, dan offset dalam topik juga berbeda. Pencerminan mempertahankan nilai kunci yang digunakan untuk pemartisian, sehingga urutan rekaman dipertahankan berdasarkan per kunci.
Pencerminan lintas perbatasan jaringan
Jika Anda harus mencerminkan antar kluster Kafka di jaringan yang berbeda, ada pertimbangan tambahan berikut:
Gateway: Jaringan harus dapat berkomunikasi pada tingkat TCP/IP.
Pengalamatan server: Anda dapat memilih untuk menangani node kluster dengan menggunakan alamat IP node kluster atau nama domain yang sepenuhnya memenuhi syarat.
Alamat IP: Jika Anda mengonfigurasi kluster Kafka untuk menggunakan iklan alamat IP, Anda dapat melanjutkan dengan penyiapan pencerminan dengan menggunakan alamat IP dari node broker dan node ZooKeeper.
Nama domain: Jika Anda tidak mengonfigurasi kluster Kafka untuk iklan alamat IP, kluster harus dapat terhubung satu sama lain dengan menggunakan nama domain yang sepenuhnya memenuhi syarat (FQDN). Hal ini memerlukan server sistem nama domain (DNS) di setiap jaringan yang dikonfigurasi untuk meneruskan permintaan ke jaringan lain. Saat Anda membuat jaringan virtual Azure, daripada menggunakan DNS otomatis yang disediakan dengan jaringan, Anda harus menentukan server DNS kustom dan alamat IP untuk server tersebut. Setelah membuat jaringan virtual, Anda harus membuat mesin virtual Azure yang menggunakan alamat IP tersebut. Kemudian Anda menginstal dan mengonfigurasi perangkat lunak DNS di atasnya.
Penting
Buat dan konfigurasikan server DNS kustom sebelum menginstal HDInsight ke dalam jaringan virtual. Tidak ada konfigurasi tambahan yang diperlukan untuk HDInsight untuk menggunakan server DNS yang dikonfigurasi untuk jaringan virtual.
Untuk informasi selengkapnya tentang menghubungkan dua jaringan virtual Azure, lihat Mengonfigurasi koneksi.
Arsitektur pencerminan
Arsitektur ini menampilkan dua kluster dalam grup sumber daya dan jaringan virtual yang berbeda: primer dan sekunder.
Langkah-langkah pembuatan
Buat dua grup sumber daya baru:
Grup sumber daya Lokasi kafka-primary-rg US Tengah kafka-secondary-rg US Tengah Utara Buat jaringan virtual baru kafka-primer-vnet di kafka-primer-rg. Biarkan pengaturan default.
Buat jaringan virtual baru kafka-sekunder-vnet di kafka-sekunder-rg, juga dengan pengaturan default.
Membuat dua kluster Kafka baru:
Nama kluster Grup sumber daya Jaringan virtual Akun penyimpanan kafka-primary-cluster kafka-primary-rg kafka-primary-vnet kafkaprimarystorage kafka-secondary-cluster kafka-secondary-rg kafka-secondary-vnet kafkasecondarystorage Buat serekan jaringan virtual. Langkah ini akan membuat dua peering: satu dari kafka-primary-vnet ke kafka-secondary-vnet, dan satu kembali dari kafka-secondary-vnet ke kafka-primer-vnet.
Pilih jaringan virtual kafka-primary-vnet.
Pada Pengaturan, pilih Perekanan.
Pilih Tambahkan.
Pada layar Tambahkan peering, masukkan detail seperti yang ditunjukkan pada cuplikan layar berikut.

Mengonfigurasikan iklan IP
Konfigurasikan iklan IP untuk memungkinkan klien terhubung dengan menggunakan alamat IP broker, bukan nama domain.
Buka dasbor Ambari untuk kluster primer:
https://PRIMARYCLUSTERNAME.azurehdinsight.net.Pilih Layanan>Kafka. Pilih tab Konfigurasi.
Tambahkan baris konfigurasi berikut ke bagian templat kafka-env bawah. Pilih Simpan.
# Configure Kafka to advertise IP addresses instead of FQDN IP_ADDRESS=$(hostname -i) echo advertised.listeners=$IP_ADDRESS sed -i.bak -e '/advertised/{/advertised@/!d;}' /usr/hdp/current/kafka-broker/conf/server.properties echo "advertised.listeners=PLAINTEXT://$IP_ADDRESS:9092" >> /usr/hdp/current/kafka-broker/conf/server.propertiesMasukkan catatan pada layar Simpan Konfigurasi, dan pilih Simpan.
Jika Anda mendapatkan peringatan konfigurasi, pilih Tetap Lanjutkan.
Pada Simpan Perubahan Konfigurasi, pilih Ok.
Dalam pemberitahuan Menghidupkan Ulang Diperlukan, pilih Hidupkan Ulang>Hidupkan Ulang Semua yang Terpengaruh. Kemudian pilih Konfirmasi Hidupkan ulang Semua.

Mengonfigurasi Kafka untuk mendengarkan di semua antarmuka jaringan
- Tetaplah berada pada tab Konfigurasi di bawah Layanan>Kafka. Di bagian Kafka Broker, atur properti listener ke
PLAINTEXT://0.0.0.0:9092. - Pilih Simpan.
- Pilih Hidupkan Ulang>Konfirmasi Hidupkan Ulang Semua.
Mencatat alamat IP broker dan alamat ZooKeeper untuk kluster primer
Pilih Hos pada dasbor Ambari.
Catat alamat IP untuk broker dan ZooKeeper. Node broker memiliki wn sebagai dua huruf pertama dari nama host, dan node ZooKeeper memiliki zk sebagai dua huruf pertama dari nama host.
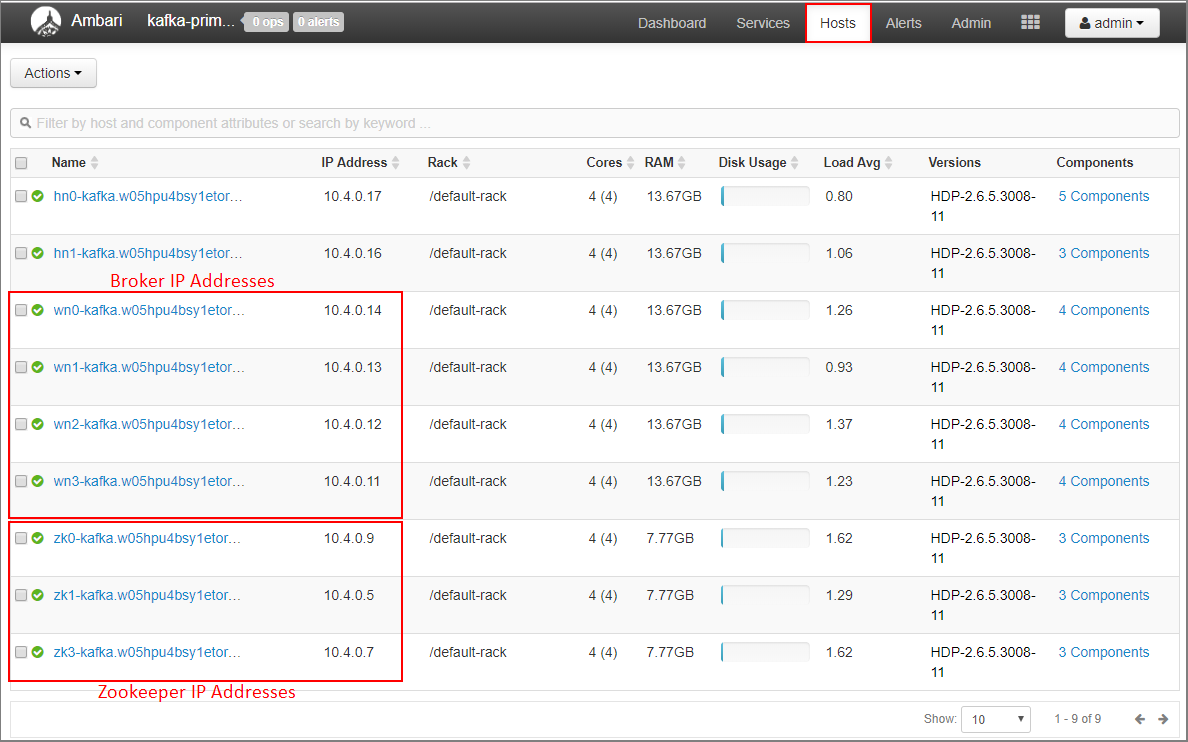
Ulangi tiga langkah sebelumnya untuk kluster kedua, kafka-secondary-cluster: konfigurasikan iklan IP, atur listener, dan catat alamat IP broker dan ZooKeeper.
Membuat topik
Hubungkan ke kluster primer dengan menggunakan SSH:
ssh sshuser@PRIMARYCLUSTER-ssh.azurehdinsight.netGanti
sshuserdengan nama pengguna SSH yang Anda gunakan saat membuat kluster. GantiPRIMARYCLUSTERdengan nama dasar yang Anda gunakan saat membuat kluster.Untuk informasi selengkapnya, lihat Menggunakan SSH dengan HDInsight.
Gunakan perintah berikut untuk membuat dua variabel lingkungan dengan host Apache ZooKeeper dan host broker untuk kluster primer. Ganti string seperti
ZOOKEEPER_IP_ADDRESS1dengan alamat IP sebenarnya yang dicatat sebelumnya, seperti10.23.0.11dan10.23.0.7. Tindakan yang sama juga berlaku untukBROKER_IP_ADDRESS1. Jika Anda menggunakan resolusi FQDN dengan server DNS kustom, ikuti langkah-langkah berikut untuk mendapatkan nama broker dan ZooKeeper.# get the ZooKeeper hosts for the primary cluster export PRIMARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181, ZOOKEEPER_IP_ADDRESS2:2181, ZOOKEEPER_IP_ADDRESS3:2181' # get the broker hosts for the primary cluster export PRIMARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Untuk membuat topik bernama
testtopic, gunakan perintah berikut:/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $PRIMARY_ZKHOSTSJalankan perintah berikut untuk memverifikasi bahwa topik berhasil dibuat:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $PRIMARY_ZKHOSTSTanggapannya berisi
testtopic.Gunakan yang berikut ini untuk melihat informasi host broker untuk kluster (primer) ini:
echo $PRIMARY_BROKERHOSTSPerintah ini menampilkan informasi yang mirip dengan teks berikut:
10.23.0.11:9092,10.23.0.7:9092,10.23.0.9:9092Simpan informasi ini. Informasi ini digunakan di bagian berikutnya.
Mengonfigurasikan pencerminan
Hubungkan ke kluster sekunder dengan menggunakan sesi SSH yang berbeda:
ssh sshuser@SECONDARYCLUSTER-ssh.azurehdinsight.netGanti
sshuserdengan nama pengguna SSH yang Anda gunakan saat membuat kluster. GantiSECONDARYCLUSTERdengan nama yang Anda gunakan saat membuat kluster.Untuk informasi selengkapnya, lihat Menggunakan SSH dengan HDInsight.
Gunakan file
consumer.propertiesuntuk mengonfigurasi komunikasi dengan kluster primer. Untuk membuat file, gunakan perintah berikut:nano consumer.propertiesMenggunakan teks berikut sebagai konten file
consumer.properties:bootstrap.servers=PRIMARY_BROKERHOSTS group.id=mirrorgroupGanti
PRIMARY_BROKERHOSTSdengan alamat IP host broker dari kluster primer.File ini menjelaskan informasi konsumen untuk digunakan saat membaca dari kluster Kafka primer. Untuk informasi selengkapnya, lihat Konfigurasi Pelanggan di
kafka.apache.org.Untuk menyimpan file, tekan Ctrl+X, tekan Y, lalu tekan Enter.
Sebelum mengonfigurasikan produsen yang berkomunikasi dengan kluster sekunder, siapkan variabel untuk alamat IP perantara dari kluster sekunder. Menggunakan perintah berikut untuk membuat variabel ini:
export SECONDARY_BROKERHOSTS='BROKER_IP_ADDRESS1:9092,BROKER_IP_ADDRESS2:9092,BROKER_IP_ADDRESS2:9092'Perintah
echo $SECONDARY_BROKERHOSTSakan menampilkan informasi yang mirip dengan teks berikut:10.23.0.14:9092,10.23.0.4:9092,10.23.0.12:9092Gunakan file
producer.propertiesuntuk mengomunikasikan kluster sekunder. Untuk membuat file, gunakan perintah berikut:nano producer.propertiesMenggunakan teks berikut sebagai konten file
producer.properties:bootstrap.servers=SECONDARY_BROKERHOSTS compression.type=noneGanti
SECONDARY_BROKERHOSTSdengan alamat IP broker yang digunakan pada langkah sebelumnya.Untuk informasi selengkapnya, lihat Konfigurasi Produsen di
kafka.apache.org.Gunakan perintah berikut untuk membuat variabel lingkungan dengan alamat IP host ZooKeeper untuk kluster sekunder:
# get the ZooKeeper hosts for the secondary cluster export SECONDARY_ZKHOSTS='ZOOKEEPER_IP_ADDRESS1:2181,ZOOKEEPER_IP_ADDRESS2:2181,ZOOKEEPER_IP_ADDRESS3:2181'Konfigurasi default untuk Kafka pada Microsoft Azure HDInsight tidak memungkinkan pembuatan topik secara otomatis. Anda harus menggunakan salah satu opsi berikut sebelum memulai proses pencerminan:
Membuat topik pada kluster sekunder: Opsi ini juga memungkinkan Anda untuk mengatur jumlah partisi dan faktor replikasi.
Anda bisa membuat topik lebih awal dengan menggunakan perintah berikut:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 2 --partitions 8 --topic testtopic --zookeeper $SECONDARY_ZKHOSTSGanti
testtopicdengan nama topik yang dibuat.Konfigurasikan kluster untuk pembuatan topik otomatis: Opsi ini memungkinkan MirrorMaker membuat topik secara otomatis. Perhatikan bahwa hal ini mungkin membuat MirrorMaker dengan jumlah partisi yang berbeda atau faktor replikasi yang berbeda dari topik utama.
Untuk mengonfigurasikan kluster sekunder untuk membuat topik secara otomatis, lakukan langkah-langkah berikut:
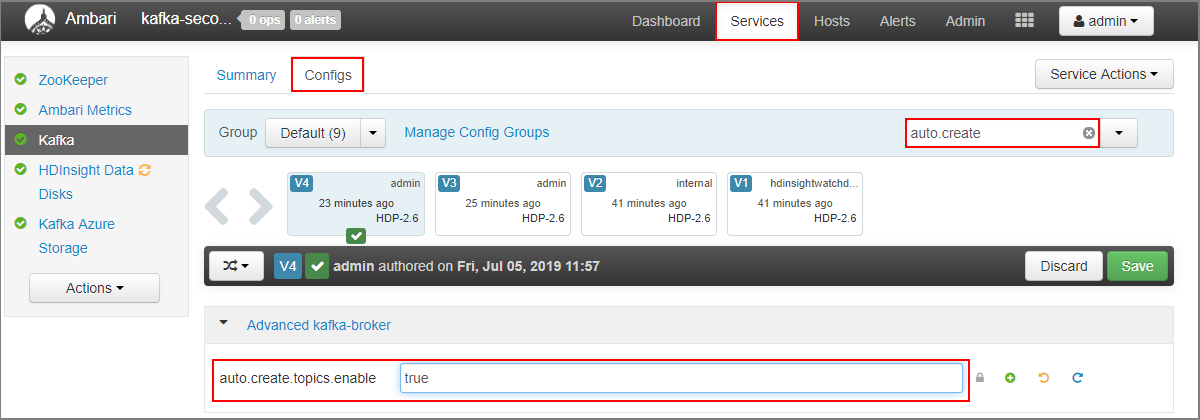
- Buka dasbor Ambari untuk kluster sekunder:
https://SECONDARYCLUSTERNAME.azurehdinsight.net. - Pilih Layanan>Kafka. Kemudian pilih tab Konfigurasi.
- Di bidang Filter, masukkan nilai
auto.create. Hal ini memfilter daftar properti dan menampilkan pengaturanauto.create.topics.enable. - Ubah nilai
auto.create.topics.enablemenjaditrue, lalu pilih Simpan. Tambahkan catatan, lalu pilih Simpan lagi. - Pilih layanan Kafka, pilih Mulai ulang, lalu pilih Mulai ulang semua yang terdampak. Saat diminta, pilih Konfirmasi mulai ulang semua.
- Buka dasbor Ambari untuk kluster sekunder:
Memulai MirrorMaker
Catatan
Artikel ini berisi referensi ke istilah yang tidak lagi digunakan Microsoft. Ketika istilah dihapus dari perangkat lunak, kami akan menghapusnya dari artikel ini.
Dari koneksi SSH ke kluster sekunder, gunakan perintah berikut untuk memulai proses MirrorMaker:
/usr/hdp/current/kafka-broker/bin/kafka-run-class.sh kafka.tools.MirrorMaker --consumer.config consumer.properties --producer.config producer.properties --whitelist testtopic --num.streams 4Parameter yang digunakan dalam contoh ini adalah:
Parameter Deskripsi --consumer.configMenentukan file yang berisi properti konsumen. Anda menggunakan properti ini untuk membuat konsumen yang membaca dari kluster Kafka utama. --producer.configMenentukan file yang berisi properti produsen. Anda menggunakan properti ini untuk membuat produsen yang menulis ke kluster Kafka sekunder. --whitelistDaftar topik yang direplikasi MirrorMaker dari kluster primer ke sekunder. --num.streamsJumlah rangkaian konsumen yang dibuat. Konsumen pada simpul sekunder saat ini menunggu untuk menerima pesan.
Dari koneksi SSH ke kluster primer, gunakan perintah berikut untuk memulai produsen dan mengirim pesan ke topik:
/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $PRIMARY_BROKERHOSTS --topic testtopicSaat Anda sampai di baris kosong dengan kursor, ketikkan beberapa pesan teks. Pesan dikirim ke topik pada kluster primer. Setelah selesai, tekan Ctrl+C untuk mengakhiri proses produsen.
Dari koneksi SSH ke kluster sekunder, tekan Ctrl+C untuk mengakhiri proses MirrorMaker. Mungkin perlu beberapa detik untuk mengakhiri proses. Untuk memverifikasi bahwa pesan direplikasi ke sekunder, gunakan perintah berikut:
/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $SECONDARY_BROKERHOSTS --topic testtopic --from-beginningDaftar topik saat ini menyertakan
testtopic, yang dibuat ketika MirrorMaster mencerminkan topik dari kluster primer ke sekunder. Pesan yang diambil dari topik ini sama dengan pesan yang Anda masukkan pada kluster primer.
Menghapus kluster
Peringatan
Tagihan untuk kluster HDInsight dirata-rata per menit, baik Anda menggunakannya maupun tidak. Pastikan untuk menghapus kluster Anda setelah selesai menggunakannya. Lihat cara menghapus kluster HDInsight.
Langkah-langkah dalam artikel ini membuat kluster di grup sumber daya Azure yang berbeda. Untuk menghapus semua sumber daya yang dibuat, Anda dapat menghapus dua grup sumber daya yang dibuat: kafka-primary-rg dan kafka-secondary-rg. Menghapus grup sumber daya akan menghapus semua sumber daya yang dibuat dengan mengikuti artikel ini, termasuk kluster, jaringan virtual, dan akun penyimpanan.
Langkah berikutnya
Dalam artikel ini, Anda mempelajari cara menggunakan MirrorMaker untuk membuat replika kluster Apache Kafka. Menggunakan tautan berikut untuk menemukan cara lain untuk menggunakan Kafka: