Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini memberikan beberapa contoh arsitektur kelangsungan bisnis yang mungkin Anda pertimbangkan untuk Azure HDInsight. Toleransi untuk mengurangi fungsionalitas selama bencana adalah keputusan bisnis yang bervariasi dari satu aplikasi ke aplikasi berikutnya. Hal ini mungkin dapat diterima agar beberapa aplikasi tidak tersedia atau tersedia sebagian dengan fungsionalitas yang berkurang atau penundaan pemrosesan selama satu periode. Untuk aplikasi lain, fungsionalitas apa pun yang dikurangi tidak dapat diterima.
Catatan
Arsitektur yang disajikan dalam artikel ini sama sekali tidak lengkap. Anda harus merancang arsitektur unik Anda sendiri setelah Anda membuat penentuan objektif seputar kelangsungan bisnis yang diharapkan, kompleksitas operasional, dan biaya kepemilikan.
Apache Hive dan Interactive Query
Hive Replication V2 direkomendasikan untuk kelangsungan bisnis di kluster kueri HDInsight Hive dan kueri interaktif. Bagian persisten dari kluster Hive mandiri yang perlu direplikasi adalah Lapisan Penyimpanan dan metastore Hive. Kluster Hive dalam skenario multi-pengguna dengan Paket Keamanan Perusahaan memerlukan Microsoft Entra Domain Services dan Ranger Metastore.
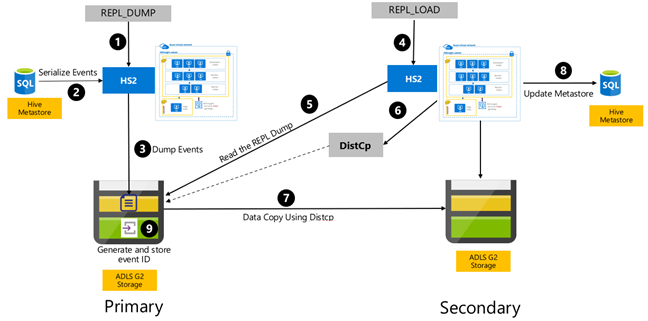
Replikasi berbasis peristiwa Apache Hive dikonfigurasi antara kluster primer dan sekunder. Hal ini terdiri dari dua fase yang berbeda, proses bootstrap dan eksekusi inkremental:
Bootstrapping mereplikasi seluruh gudang Hive, termasuk informasi metastore Hive dari sistem utama ke sistem sekunder.
Eksekusi inkremental diotomatisasi pada kluster primer dan kejadian yang dihasilkan selama eksekusi inkremental diputar kembali pada klaster sekunder. Kluster sekunder mengejar kejadian yang dihasilkan dari kluster primer, memastikan bahwa kluster sekunder sejalan dengan peristiwa kluster primer setelah eksekusi replikasi.
Kluster sekunder hanya diperlukan pada saat replikasi untuk menjalankan salinan terdistribusi, DistCp, tetapi penyimpanan dan metastores harus persisten. Anda dapat memilih untuk membangun kluster sekunder ber-skrip secara on-demand sebelum replikasi, menjalankan skrip replikasi pada kluster tersebut, dan kemudian membongkarnya setelah replikasi berhasil.
Kluster sekunder biasanya bersifat hanya-baca. Anda dapat membuat kluster sekunder baca-tulis, tetapi hal ini memberikan kompleksitas tambahan yang melibatkan replikasi perubahan dari kluster sekunder ke kluster primer.
RPO & RTO replikasi Apache Hive berdasarkan peristiwa
RPO: Kehilangan data terbatas pada peristiwa replikasi inkremental terakhir yang berhasil dari primer ke sekunder.
RTO: Waktu antara kegagalan dan dimulainya kembali transaksi hulu dan hilir dengan sekunder.
Arsitektur Apache Hive dan Interactive Query
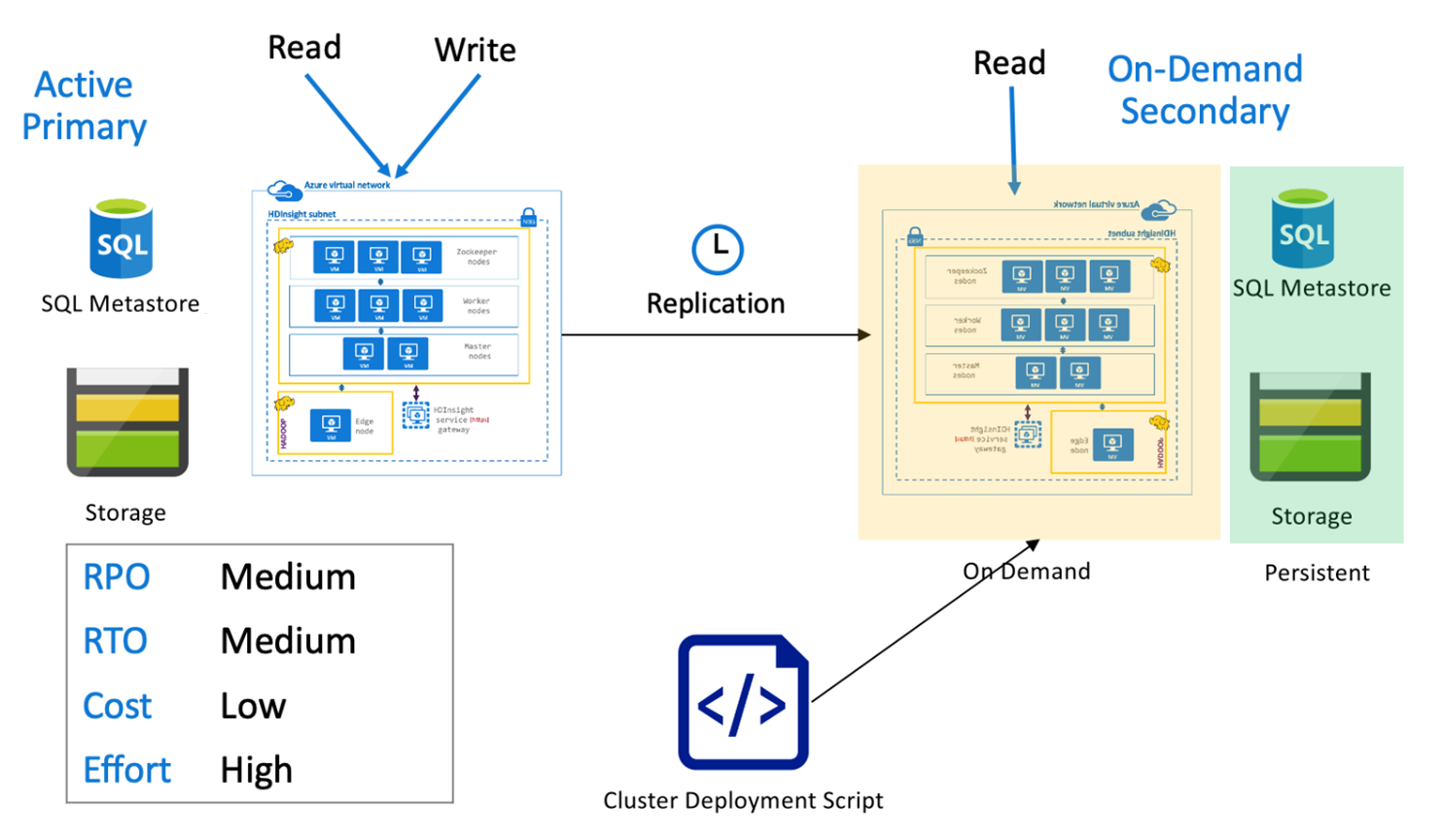
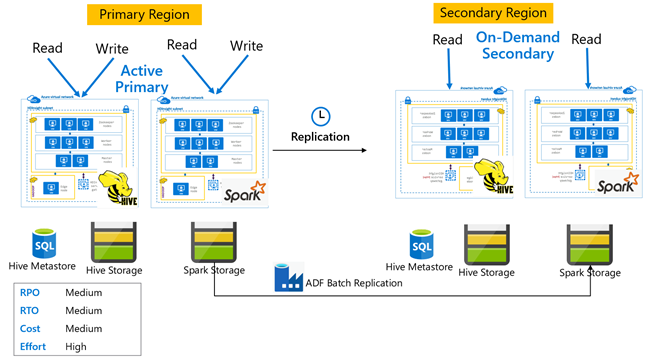
Hive primer aktif dengan sekunder sesuai permintaan
Di arsitektur primer aktif dengan arsitektur sekunder sesuai permintaan, aplikasi menulis ke wilayah primer aktif sementara tidak ada kluster yang disediakan di wilayah sekunder selama operasi normal. SQL Metastore dan penyimpanan di wilayah sekunder bersifat persisten, sementara kluster HDInsight diatur dan disebarkan sesuai permintaan hanya sebelum replikasi Hive yang dijadwalkan dijalankan.
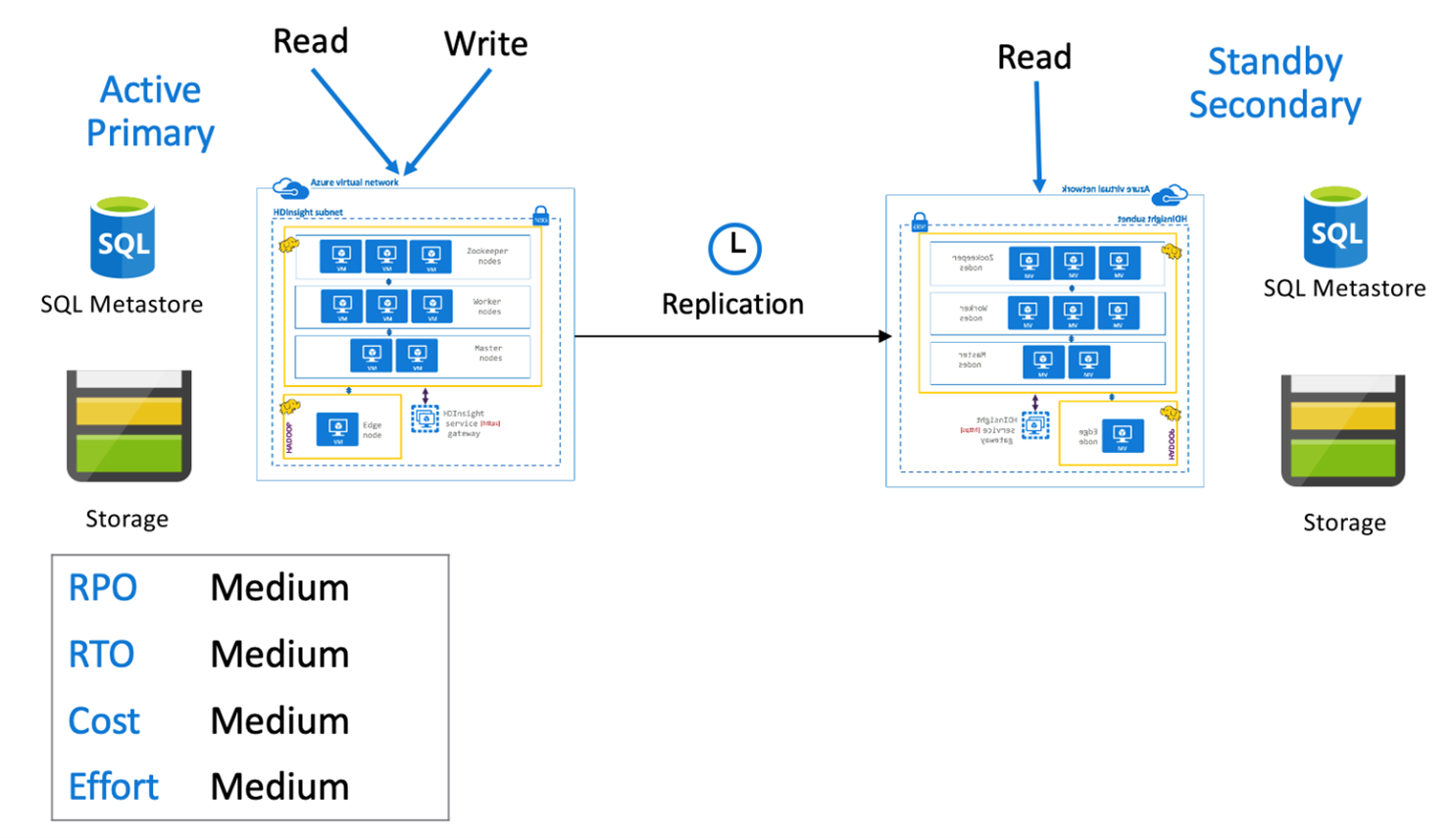
Primer dalam kondisi aktif dengan sekunder cadangan
Dalam primer aktif dengan sekunder siaga, aplikasi menulis ke wilayah primer aktif sementara kluster sekunder siaga yang diturunkan skalanya dalam mode baca-saja berjalan selama operasi normal. Selama operasi normal, Anda dapat memilih untuk mengalihkan operasi baca yang spesifik terhadap wilayah ke basis data sekunder.
Untuk informasi lebih lanjut tentang replikasi Hive dan sampel kode, lihat Replikasi Apache Hive di kluster Azure HDInsight
Apache Spark
Beban kerja Spark mungkin atau mungkin tidak melibatkan komponen Hive. Untuk memungkinkan beban kerja Spark SQL membaca dan menulis data dari Apache Hive, kluster HDInsight Spark berbagi metastore kustom Hive dari kluster kueri Hive/Interactive di wilayah yang sama. Dalam skenario seperti itu, replikasi lintas wilayah tugas-tugas Spark juga harus disertai dengan replikasi Apache Hive metastore dan penyimpanan. Skenario kegagalan di bagian ini berlaku untuk keduanya:
- Spark SQL pada tabel ACID menggunakan Pengaturan Hive Warehouse Connector (HWC) dalam klaster Kueri Interaktif HDInsight.
- Beban kerja Spark SQL pada tabel non-ACID menggunakan kluster HDInsight Hadoop.
Untuk skenario di mana Spark bekerja dalam mode mandiri, data yang dikurasi dan Spark Jars yang disimpan (untuk job Livy) perlu direplikasi dari wilayah primer ke wilayah sekunder secara teratur menggunakan Azure Data Factory's DistCP.
Kami menyarankan agar Anda menggunakan sistem kontrol versi untuk menyimpan notebook dan pustaka Spark di mana mereka dapat dengan mudah dideploy pada kluster primer atau sekunder. Pastikan bahwa solusi berbasis notebook dan non-notebook disiapkan untuk memuat susunan data yang benar di ruang kerja primer atau sekunder.
Jika terdapat perpustakaan khusus pelanggan yang berada di luar apa yang disediakan HDInsight secara asli, mereka harus dilacak dan secara berkala dimuat ke dalam kluster sekunder siaga.
RPO & RTO untuk replikasi Apache Spark
RPO: Kehilangan data terbatas pada replikasi inkremental terakhir yang berhasil (Spark dan Apache Hive) dari primer ke sekunder.
RTO: Waktu antara kegagalan dan pemulihan transaksi hulu dan hilir dengan sistem sekunder.
Arsitektur Apache Spark
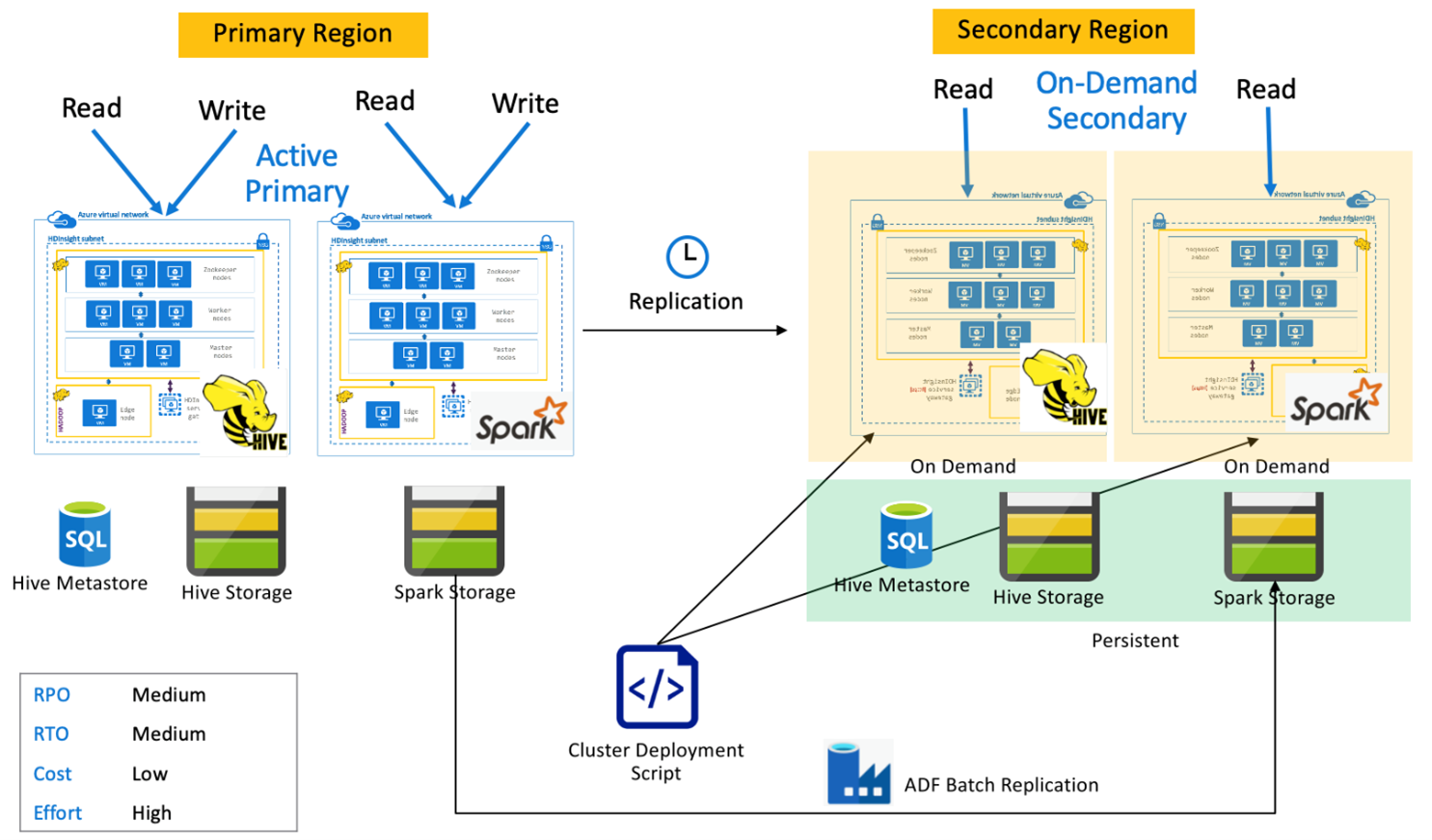
Spark utama aktif dengan sekunder sesuai permintaan
Aplikasi membaca dan menulis ke kluster Spark dan Apache Hive di wilayah primer sementara tidak ada kluster yang disediakan di wilayah sekunder selama operasi normal. SQL Metastore, Apache Hive Storage, dan Spark Storage tetap berada di wilayah sekunder. Kluster Spark dan Apache Hive ditulis dan disebarkan sesuai permintaan. Replikasi Apache Hive digunakan untuk mereplikasi Hive Storage dan Hive Metastores sementara Azure Data Factory's DistCP dapat digunakan untuk menyalin penyimpanan Spark mandiri. Kluster Apache Hive perlu diterapkan sebelum setiap pelaksanaan replikasi Apache Hive mengingat ketergantungan DistCp komputasi.
Aktifkan primer utama dengan sekunder cadangan
Aplikasi membaca dan menulis ke kluster Spark dan Apache Hive di wilayah primer, sementara kluster Apache Hive dan Spark berkapasitas lebih kecil dalam keadaan siaga pada mode hanya-baca berjalan di wilayah sekunder selama operasi normal. Selama operasi normal, Anda dapat memilih untuk memindahkan operasi baca Hive dan Spark yang spesifik untuk wilayah ke sekunder.
Apache HBase
Ekspor HBase dan Replikasi HBase adalah cara umum untuk memungkinkan kelangsungan bisnis antara kluster HDInsight HBase.
Ekspor HBase adalah proses replikasi batch yang menggunakan Utilitas Ekspor HBase untuk mengekspor tabel dari kluster HBase primer ke Azure Data Lake Storage Gen 2 yang mendasarinya. Data yang diekspor kemudian dapat diakses dari kluster HBase sekunder dan diimpor ke dalam tabel yang harus sudah ada sebelumnya di kluster sekunder. Sementara HBase Export menawarkan granularitas tingkat tabel, dalam situasi pembaruan inkremental, mesin otomatisasi ekspor mengontrol rentang baris inkremental untuk disertakan dalam setiap proses. Untuk informasi selengkapnya, lihat Backup dan Replikasi HDInsight HBase.
Replikasi HBase menggunakan replikasi hampir real-time antara kluster HBase dengan cara yang sepenuhnya otomatis. Replikasi dilakukan pada tingkat tabel. Semua tabel atau tabel tertentu dapat ditargetkan untuk replikasi. Replikasi HBase pada akhirnya konsisten, yang berarti bahwa pengeditan terbaru ke tabel di wilayah primer mungkin tidak segera tersedia untuk semua wilayah sekunder. Para sekunder dijamin akhirnya akan menjadi konsisten dengan primer. Replikasi HBase dapat diatur antara dua atau lebih kluster HDInsight HBase jika:
- Primer dan sekunder berada dalam jaringan virtual yang sama.
- Primer dan sekunder berada di peer VNets yang berbeda di wilayah yang sama.
- Primer dan sekunder berada di peer VNets yang berbeda di berbagai wilayah.
Untuk informasi selengkapnya, lihat Menyiapkan replikasi kluster Apache HBase di jaringan virtual Azure.
Ada beberapa cara lain untuk melakukan pencadangan kluster HBase seperti menyalin folder hbase, menyalin tabel dan Merekam Jepret (Snapshot).
RPO & RTO HBase
Ekspor HBase
- RPO: Kehilangan Data terbatas pada impor batch inkremental terakhir yang berhasil dari primer ke sekunder.
- RTO: Waktu antara kegagalan sistem primer dan dimulainya kembali operasi I/O pada sistem sekunder.
Replikasi HBase
- RPO: Kehilangan Data terbatas pada Pengiriman WalEdit terakhir yang diterima di server sekunder.
- RTO: Waktu antara kegagalan primer dan dimulainya kembali operasi I/O pada sekunder.
Arsitektur HBase
Replikasi HBase dapat diatur dalam tiga mode: Pemimpin-Pengikut, Pemimpin-Pemimpin, dan Siklik.
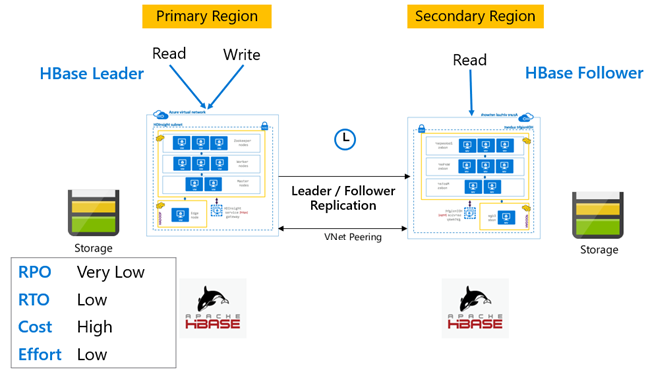
Replikasi HBase: Model Pemimpin – Pengikut
Dalam pengaturan lintas wilayah ini, replikasi satu arah dari wilayah primer ke wilayah sekunder. Baik semua tabel atau tabel tertentu di primer dapat diidentifikasi untuk replikasi searah. Selama operasi normal, kluster sekunder dapat digunakan untuk melayani permintaan baca di wilayahnya sendiri.
Kluster sekunder beroperasi sebagai kluster HBase normal yang dapat menjadi host untuk tabelnya sendiri dan dapat melayani bacaan dan tulis dari aplikasi regional. Namun, penulisan pada tabel yang telah direplikasi atau tabel milik sistem sekunder tidak direplikasikan kembali ke sistem primer.
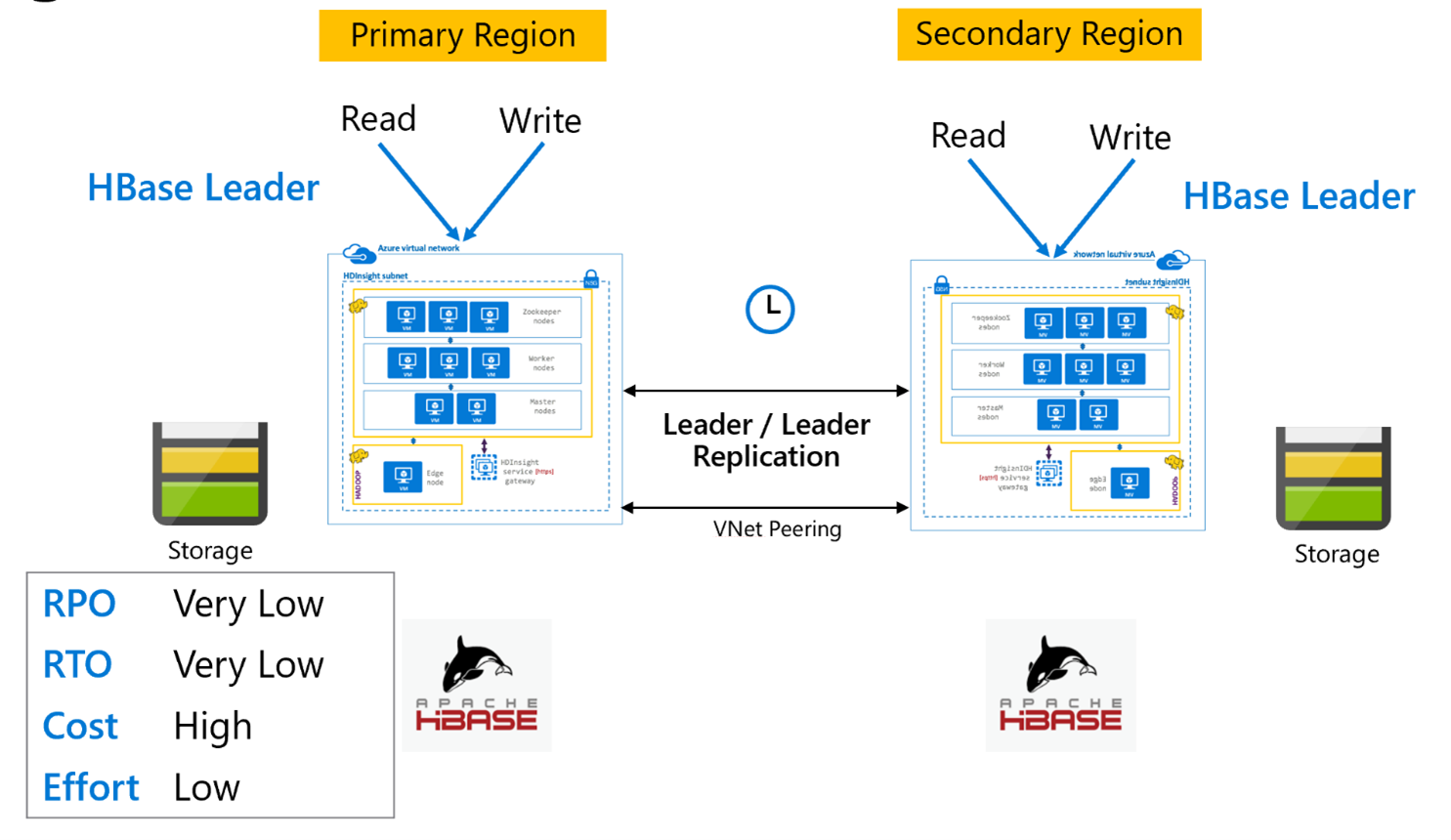
Replikasi HBase: Model pemimpin
Pengaturan lintas wilayah ini sangat mirip dengan pengaturan unidirectional kecuali bahwa replikasi terjadi dua arah antara wilayah utama dan wilayah sekunder. Aplikasi dapat menggunakan kedua kluster dalam mode baca-tulis dan pembaruan adalah pertukaran secara asinkron di antara mereka.
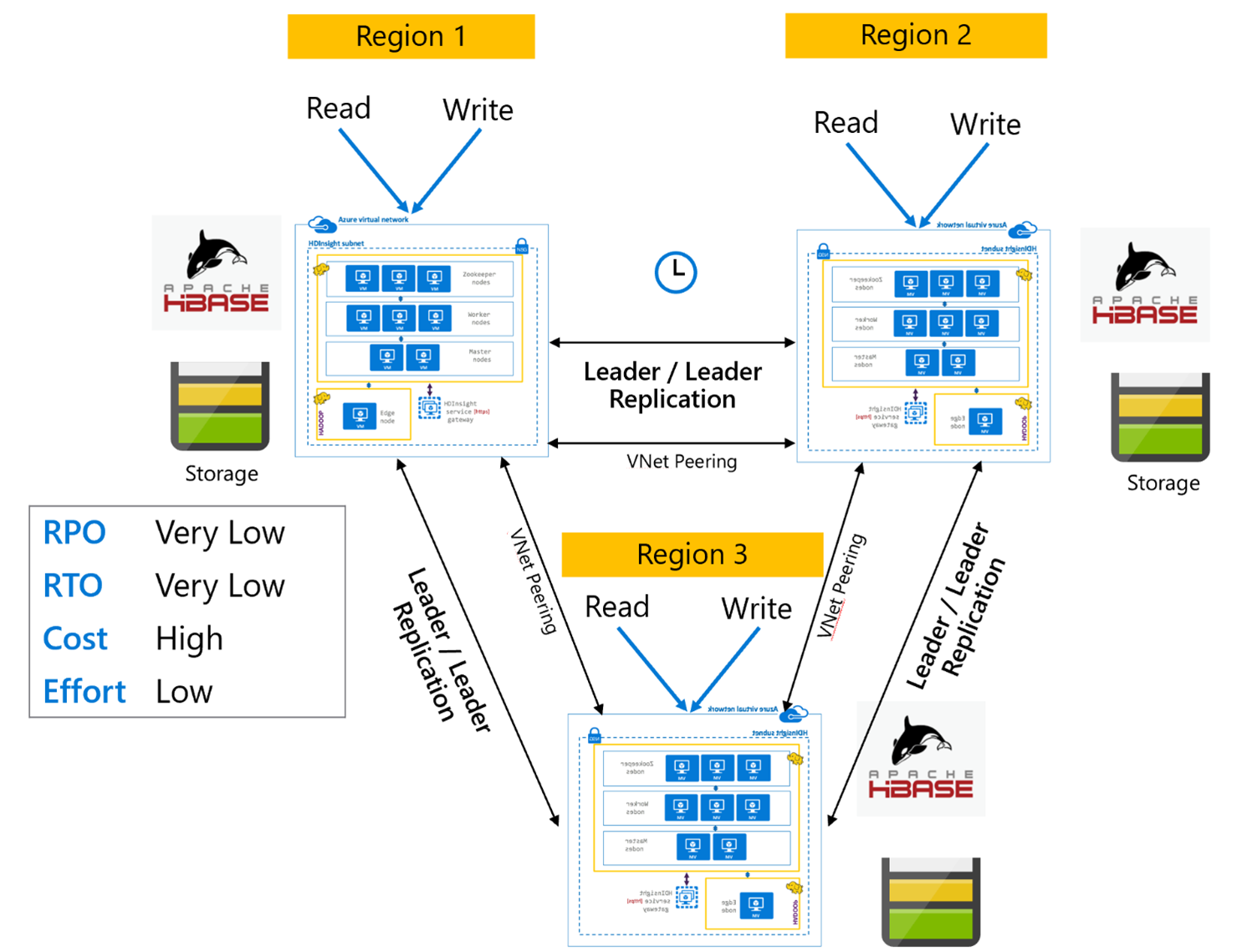
Replikasi HBase: Banyak Wilayah atau Siklus
Model replikasi Multi-Wilayah/Siklik adalah ekstensi Replikasi HBase dan dapat digunakan untuk membuat arsitektur HBase yang redundan secara global dengan beberapa aplikasi yang membaca dari dan menulis ke kluster HBase khusus wilayah. Kluster dapat diatur dalam berbagai kombinasi Pemimpin/Pemimpin atau Pemimpin/Pengikut tergantung pada persyaratan bisnis.
Apache Kafka
Untuk memungkinkan ketersediaan lintas wilayah HDInsight 4.0 mendukung Kafka MirrorMaker yang dapat digunakan untuk mempertahankan replika sekunder kluster Kafka primer di wilayah yang berbeda. MirrorMaker bertindak sebagai konsumen dan produsen tingkat tinggi, mengonsumsi dari topik tertentu di kluster utama dan menyalurkan ke sebuah topik dengan nama yang sama di kluster kedua. Replikasi lintas kluster untuk pemulihan bencana dengan tingkat ketersediaan tinggi menggunakan MirrorMaker hadir dengan asumsi bahwa Produsen dan Konsumen perlu beralih ke kluster replika. Untuk informasi selengkapnya, lihat Menggunakan MirrorMaker untuk mereplikasi topik Apache Kafka dengan Kafka di HDInsight
Tergantung pada masa pakai topik ketika replikasi dimulai, replikasi topik MirrorMaker dapat menyebabkan offset yang berbeda antara topik sumber dan replika. Kluster HDInsight Kafka juga mendukung replikasi partisi topik yang merupakan fitur ketersediaan tinggi di tingkat kluster individu.
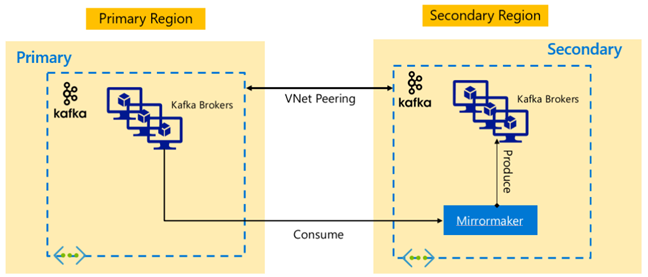
Arsitektur Apache Kafka
Replikasi Kafka: Aktif – Pasif
Pengaturan Aktif-Pasif ini memungkinkan pencerminan searah asinkron dari Aktif ke Pasif. Produsen dan Konsumen perlu menyadari keberadaan kluster Aktif dan Pasif serta harus siap untuk beralih ke kluster Pasif jika kluster Aktif mengalami kegagalan. Di bawah ini adalah beberapa keuntungan dan kerugian pengaturan Aktif-Pasif.
Keuntungan:
- Latensi jaringan antara kluster tidak memengaruhi kinerja kluster Aktif.
- Kesederhanaan replikasi searah.
Kekurangan:
- Kluster Pasif mungkin tetap kurang dimanfaatkan.
- Kompleksitas desain dalam menggabungkan kesadaran kegagalan pada produsen aplikasi dan konsumen.
- Kemungkinan kehilangan data selama kegagalan kluster Aktif.
- Konsistensi akhirnya antara topik antara kluster Aktif dan Pasif.
- Kegagalan balik ke Primer dapat menyebabkan ketidakkonsistenan pesan dalam topik.
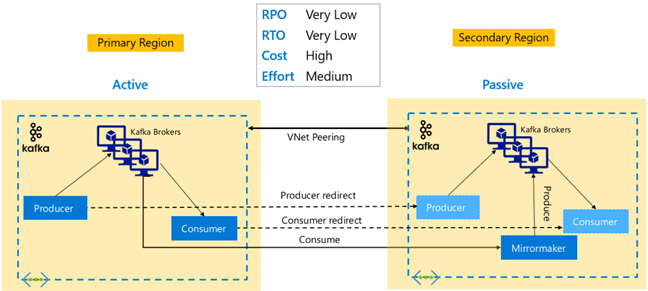
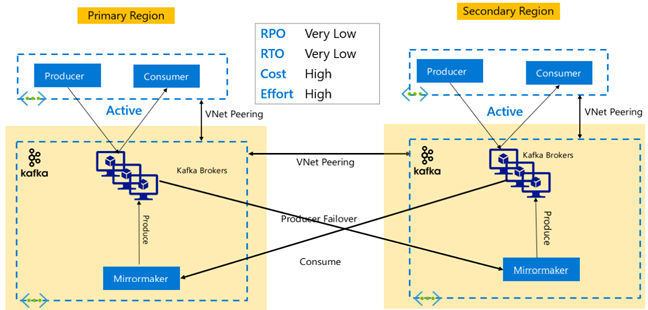
Replikasi Kafka: Aktif – Aktif
Pengaturan Active-Active melibatkan dua kluster HDInsight Kafka yang dipisahkan secara regional, terhubung melalui VNet peered, dengan replikasi asinkron dua arah menggunakan MirrorMaker. Dalam desain ini, pesan yang dikonsumsi oleh konsumen di primer juga tersedia untuk konsumen di sekunder dan sebaliknya. Beberapa keuntungan dan kerugian dari pengaturan Aktif-Aktif diuraikan di bawah ini.
Keuntungan:
- Karena kondisi failover dan failback yang diduplikasi, keduanya lebih mudah dilaksanakan.
Kekurangan:
- Pengaturan, manajemen, dan pemantauan lebih kompleks daripada Aktif-Pasif.
- Masalah replikasi melingkar perlu ditangani.
- Replikasi dua arah menyebabkan biaya keluar data regional yang lebih tinggi.
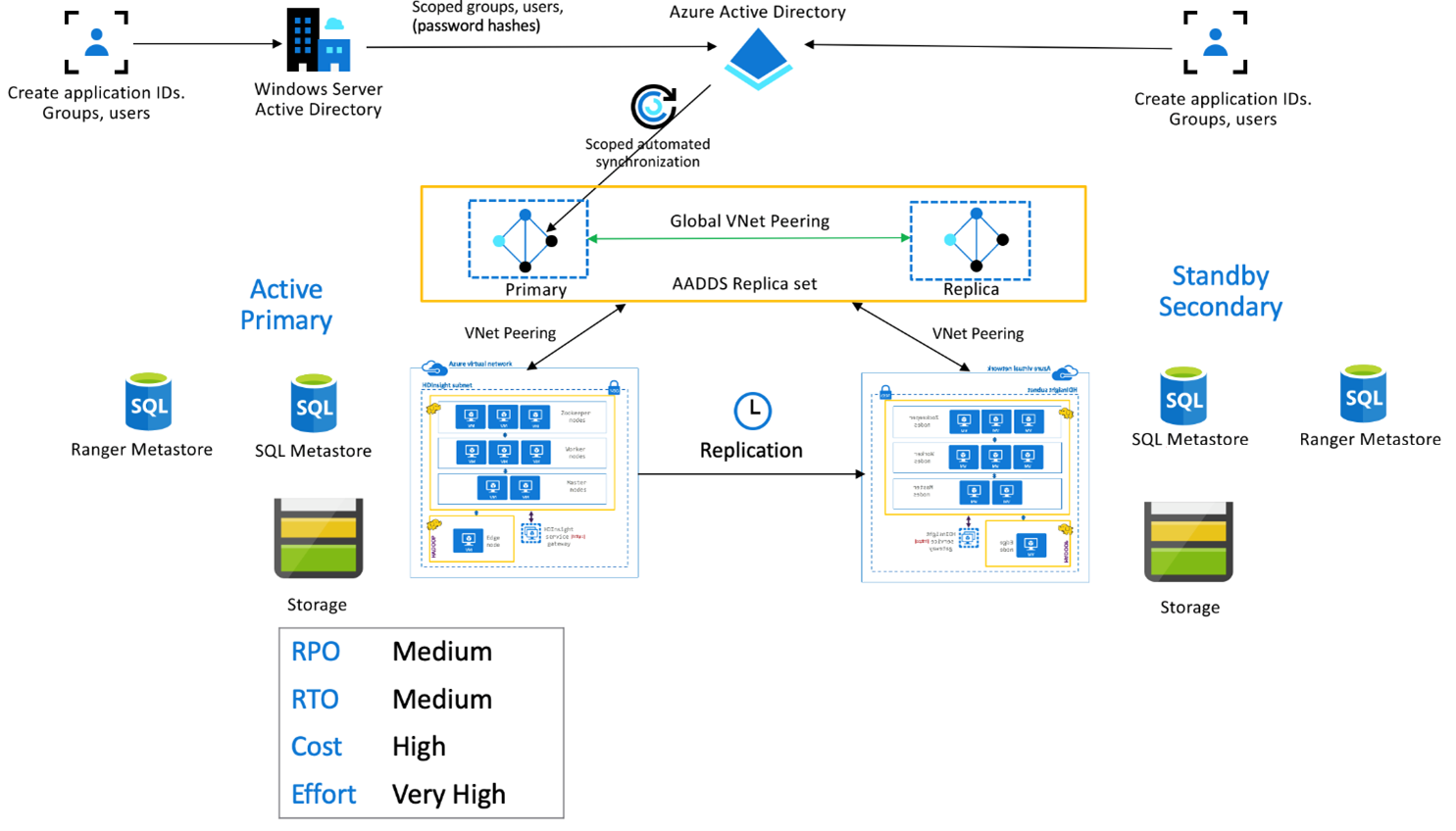
Paket Keamanan Perusahaan HDInsight
Penyiapan ini digunakan untuk mengaktifkan fungsionalitas multi-pengguna dalam sistem primer dan sekunder, serta set replika Microsoft Entra Domain Services untuk memastikan bahwa pengguna dapat mengautentikasi pada kedua kluster. Selama operasi normal, kebijakan Ranger perlu disiapkan di sistem sekunder untuk memastikan bahwa pengguna dibatasi untuk operasi Membaca. Arsitektur di bawah ini menjelaskan tampilan penyiapan Apache Hive Active Primary – Standby Secondary dengan dukungan ESP.
Replikasi Ranger Metastore:
Ranger Metastore digunakan untuk terus menyimpan dan melayani kebijakan Ranger untuk mengontrol otorisasi data. Kami menyarankan agar Anda mempertahankan kebijakan Ranger independen di primer dan sekunder dan mempertahankan sekunder sebagai replika baca.
Jika persyaratannya adalah menjaga kebijakan Ranger tetap sinkron antara primer dan sekunder, gunakan Ranger Import/Export untuk mencadangkan dan mengimpor kebijakan Ranger secara berkala dari primer ke sekunder.
Mereplikasi kebijakan Ranger antara primer dan sekunder dapat menyebabkan sekunder menjadi dapat ditulis, yang dapat menyebabkan penulisan tidak disengaja pada sekunder, yang berujung pada ketidakkonsistenan data.
Langkah berikutnya
Untuk mempelajari selengkapnya tentang item yang dibahas di artikel ini, lihat: