Memantau performa klaster di Azure HDInsight
Pemantauan kesehatan dan kinerja klaster HDInsight sangat penting untuk menjaga kinerja dan pemanfaatan sumber daya yang optimal. Pemantauan juga dapat membantu Anda mendeteksi dan mengatasi eror konfigurasi klaster dan masalah kode pengguna.
Bagian berikut menjelaskan cara memantau dan mengoptimalkan beban pada klaster Anda, antrean Apache Hadoop YARN serta pendeteksian masalah pembatasan penyimpanan.
Memantau beban klaster
Klaster Hadoop dapat memberikan kinerja yang paling optimal ketika beban pada klaster didistribusikan secara merata pada semua node. Hal ini memungkinkan tugas pemrosesan berjalan tanpa dibatasi oleh RAM, CPU, atau sumber daya disk pada node individual.
Untuk mendapatkan tampilan tingkat tinggi pada node klaster Anda dan pemuatannya, masuklah ke Ambari Web UI, lalu pilih tab Hos. Hos Anda dicantumkan berdasarkan nama domain mereka yang sepenuhnya memenuhi syarat. Status operasi setiap hos ditampilkan dengan indikator kesehatan berwarna:
| Warna | Deskripsi |
|---|---|
| Merah | Setidaknya satu komponen master pada hos tidak berfungsi. Goyangkan tetikus untuk melihat tipsalat yang mencantumkan komponen yang terdampak. |
| Orange | Setidaknya satu komponen sekunder pada hos tidak berfungsi. Goyangkan tetikus untuk melihat tipsalat yang mencantumkan komponen yang terdampak. |
| Kuning | Ambari Server belum menerima detak jantung dari hos selama lebih dari 3 menit. |
| Hijau | Keadaan berjalan normal. |
Anda juga akan melihat kolom yang menampilkan jumlah inti dan jumlah RAM untuk setiap hos, serta penggunaan disk dan rata-rata beban.
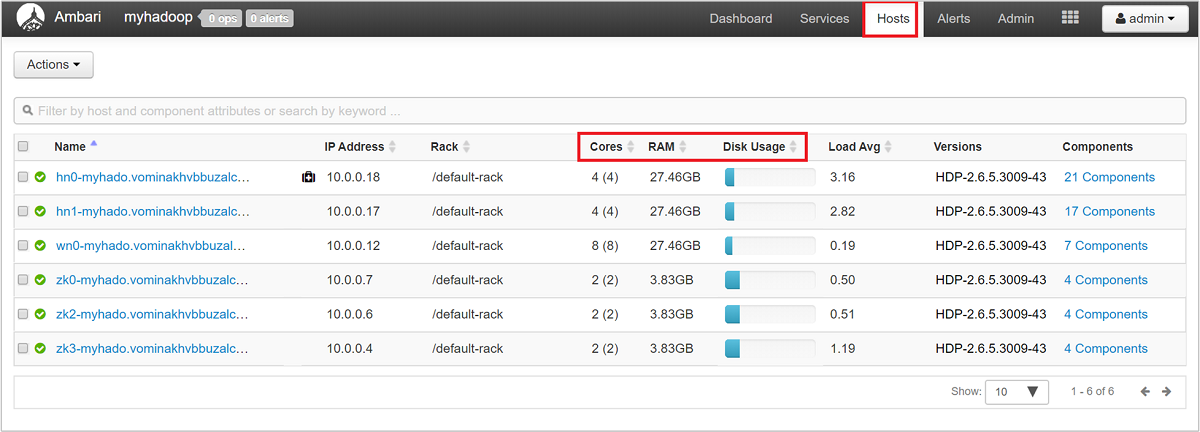
Pilih salah satu nama host untuk tampilan terperinci komponen yang berjalan pada hos tersebut dan metriknya. Metrik ditampilkan sebagai garis waktu penggunaan CPU, beban, penggunaan disk, penggunaan memori, penggunaan jaringan, dan jumlah proses yang dapat dipilih.
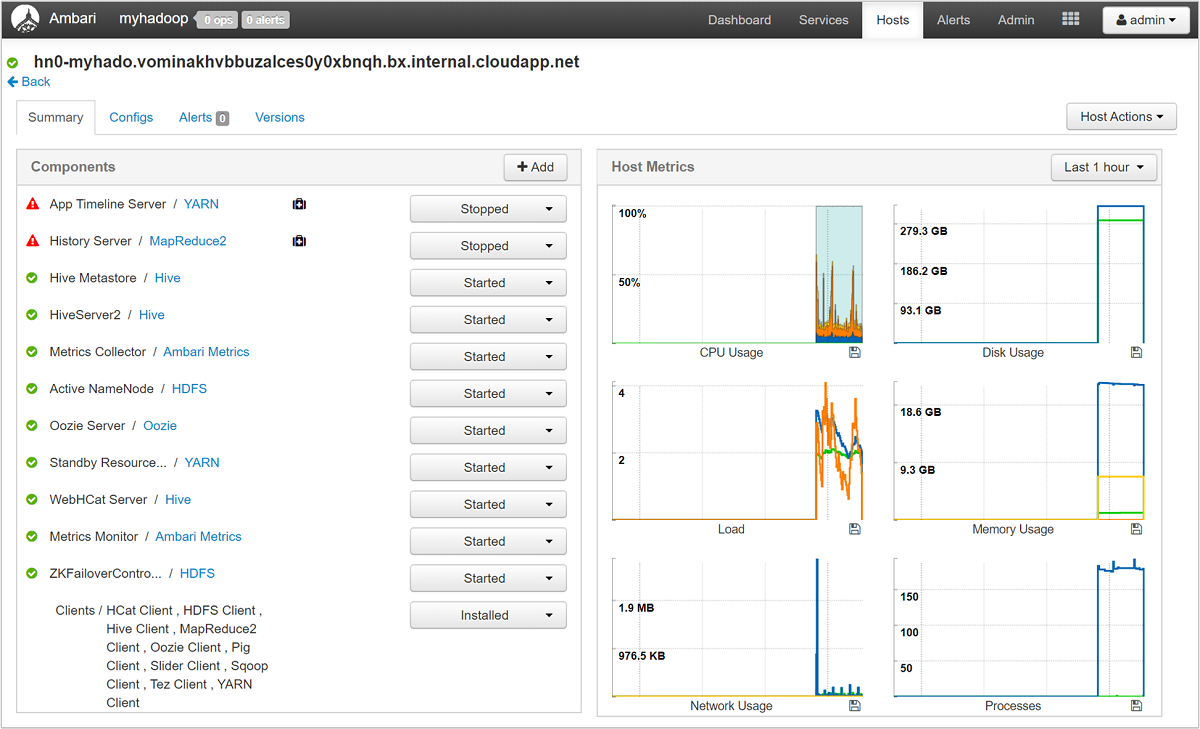
Lihat Mengelola klaster HDInsight dengan menggunakan Apache Ambari Web UI untuk perincian tentang pengaturan peringatan dan melihat metrik.
Konfigurasi antrean YARN
Hadoop memiliki berbagai layanan yang berjalan pada semua platform terdistribusinya. YARN (Masih Negosiator Sumber Daya Lain) mengoordinasikan layanan ini dan mengalokasikan sumber daya klaster untuk memastikan semua beban didistribusikan secara merata pada semua klaster.
YARN membagi dua tanggung jawab JobTracker, manajemen sumber daya dan penjadwalan/pemantauan pekerjaan, ke dalam dua daemon: Resource Manager global, dan ApplicationMaster (AM) per aplikasi.
Resource Manager adalah penjadwal murni, dan satu-satunya arbitrase sumber daya yang tersedia di antara semua aplikasi yang bersaing. Resource Manager memastikan bahwa semua sumber daya selalu digunakan, mengoptimalkan berbagai konstanta seperti SLA, jaminan kapasitas, dan sebagainya. ApplicationMaster menegosiasikan sumber daya dari Resource Manager, dan bekerja sama dengan NodeManager untuk mengeksekusi dan memantau kontainer dan konsumsi sumber dayanya.
Ketika beberapa penyewa berbagi klaster besar, ada persaingan pada sumber daya klaster. CapacityScheduler adalah penjadwal yang dapat dicolokkan yang membantu berbagi sumber daya dengan mengantre permintaan. CapacityScheduler juga mendukung antrean hierarkis untuk memastikan bahwa sumber daya dibagi antar sub-antrean organisasi, sebelum antrean aplikasi lain diperbolehkan untuk menggunakan sumber daya gratis.
YARN memungkinkan kita mengalokasikan sumber daya untuk antrean ini, dan menunjukkan kepada Anda apakah semua sumber daya yang tersedia telah ditetapkan. Untuk melihat informasi tentang antrean Anda, masuklah ke Ambari Web UI, lalu pilih Manajer Antrean Yarn dari menu di bagian atas.
Halaman Manajer Antrean YARN memperlihatkan daftar antrean Anda di sebelah kiri, bersama dengan persentase kapasitas yang ditetapkan untuk masing-masing antrean.
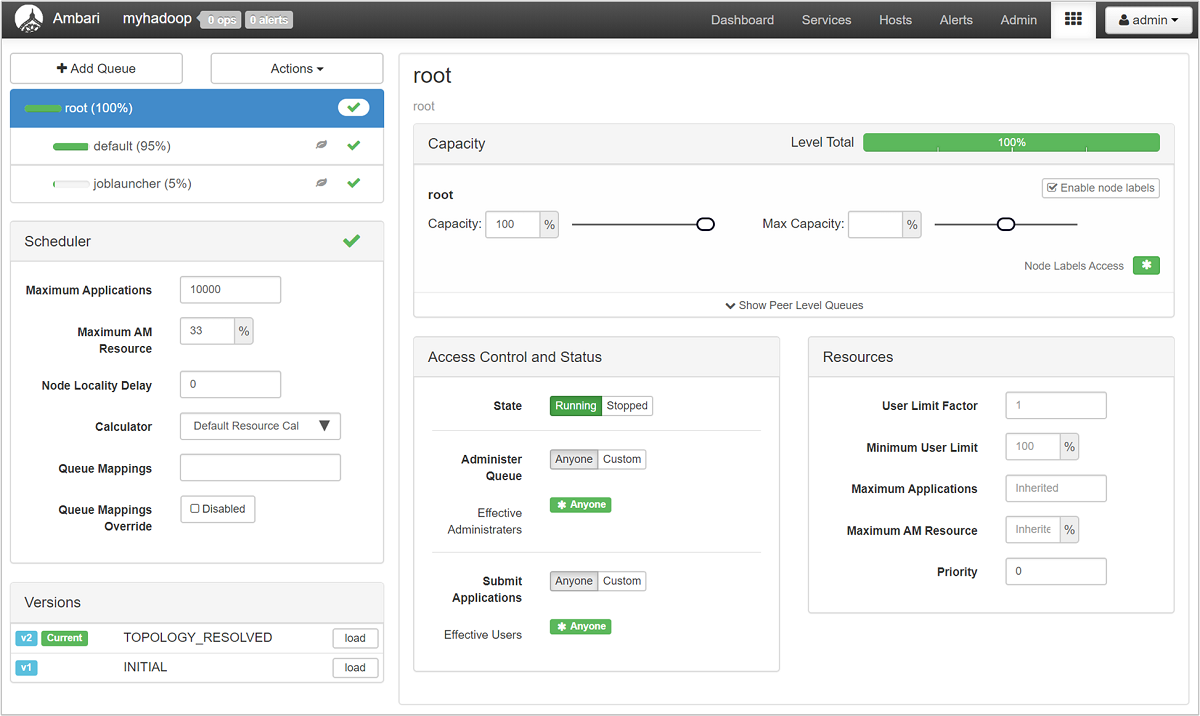
Untuk tampilan antrean Anda yang lebih terperinci, dari dasbor Ambari, pilih layanan YARN dari daftar di sebelah kiri. Lalu di bawah menu tarik-turun Tautan Cepat, pilih UI Resource Manager di bawah node aktif Anda.
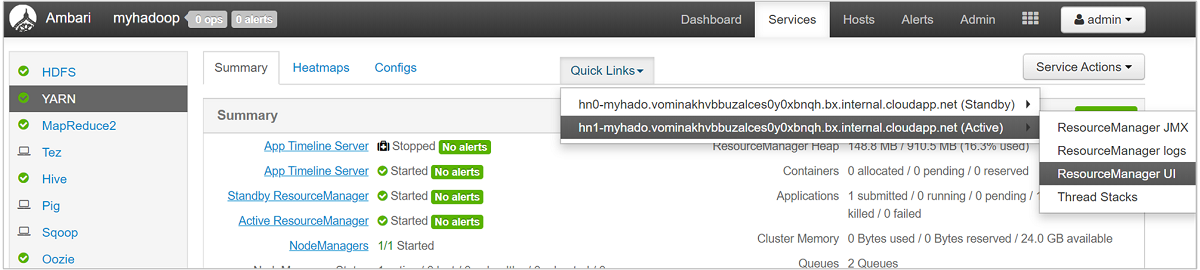
Di UI Resource Manager, pilih Penjadwal dari menu sebelah kiri. Anda melihat daftar antrean Anda di bawah Antrean Aplikasi. Di sini Anda dapat melihat kapasitas yang digunakan untuk setiap antrean Anda, seberapa baik pekerjaan didistribusikan di antara mereka, dan apakah ada pekerjaan yang dibatasi sumber daya.
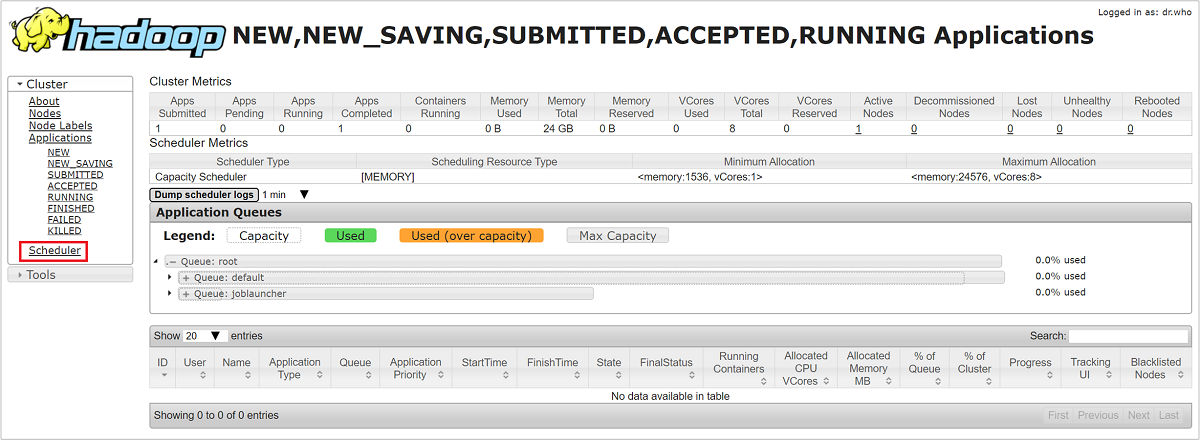
Pembatasan penyimpanan
Kemacetan kinerja klaster dapat terjadi di tingkat penyimpanan. Jenis kemacetan ini paling sering terjadi karena pemblokiran operasi input/output (IO), yang terjadi saat tugas yang Anda jalankan mengirim lebih banyak IO daripada yang dapat ditangani oleh layanan penyimpanan. Pemblokiran ini menghasilkan antrean permintaan IO yang menunggu untuk diproses hingga IO saat ini selesai diproses. Blok ini terjadi karena pembatasan penyimpanan, yang bukan merupakan batas fisik, melainkan batas yang diberlakukan oleh layanan penyimpanan oleh perjanjian tingkat layanan (SLA). Batas ini memastikan bahwa tidak ada satu klien atau penyewa yang dapat memonopoli layanan. SLA membatasi jumlah IO per detik (IOPS) untuk Azure Storage - untuk rinciannya, lihat Skalabilitas dan target kinerja untuk akun penyimpanan standar.
Jika Anda menggunakan Azure Storage, untuk informasi tentang pemantauan masalah terkait penyimpanan, termasuk pembatasan, lihat Memantau, mendiagnosis, dan memecahkan masalah Microsoft Azure Storage.
Jika toko pendukung klaster Anda adalah Azure Data Lake Storage (ADLS), pembatasan kemungkinan besar terjadi karena batas bandwidth. Pembatasan dalam hal ini dapat diidentifikasi dengan mengamati eror pembatasan dalam log tugas. Untuk ADLS, lihat bagian pembatasan untuk layanan yang sesuai dalam artikel berikut:
- Panduan penyetelan kinerja untuk Apache Hive pada HDInsight dan Azure Data Lake Storage
- Panduan penyetelan kinerja untuk MapReduce pada HDInsight dan Azure Data Lake Storage
Memecahkan masalah kinerja node yang lamban
Dalam beberapa kasus, kelambatan dapat terjadi karena ruang disk yang rendah pada klaster. Selidiki dengan langkah-langkah berikut:
Gunakan perintah ssh untuk terhubung ke dalam masing-masing node.
Periksa penggunaan diska dengan menjalankan salah satu perintah berikut ini:
df -h du -h --max-depth=1 / | sort -hTinjau output, dan periksa keberadaan file besar di folder
mntatau folder lain. Biasanya, folderusercache, danappcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) berisi file besar.Jika ada file besar, bisa saja pekerjaan saat ini menyebabkan pertumbuhan file atau pekerjaan sebelumnya yang gagal mungkin telah berkontribusi pada masalah ini. Untuk memeriksa apakah perilaku ini disebabkan oleh pekerjaan saat ini, jalankan perintah berikut:
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/Jika perintah ini menunjukkan pekerjaan tertentu, Anda dapat memilih untuk mengakhiri pekerjaan dengan menggunakan perintah yang menyerupai berikut ini:
yarn application -kill -applicationId <application_id>Ganti
application_iddengan ID aplikasi. Jika tidak ada pekerjaan spesifik yang ditunjukkan, lanjutkan ke langkah berikutnya.Setelah perintah di atas selesai, atau jika tidak ada pekerjaan tertentu yang ditunjukkan, hapus file besar yang Anda identifikasi dengan menjalankan perintah yang menyerupai berikut ini:
rm -rf filecache usercache
Untuk informasi selengkapnya mengenai masalah ruang disk, lihat Di luar ruang disk.
Catatan
CATATAN: Jika Anda memiliki file besar yang ingin Anda simpan tetapi berkontribusi pada masalah ketersediaan ruang disk yang rendah, Anda harus meningkatkan skala klaster HDInsight Anda dan memulai ulang layanan Anda. Setelah Anda menyelesaikan prosedur ini dan menunggu beberapa menit, Anda akan melihat bahwa ketersediaan penyimpanan telah bertambah dan kinerja normal node telah dipulihkan.
Langkah berikutnya
Kunjungi tautan berikut untuk informasi selengkapnya tentang pemecahan masalah dan pemantauan klaster Anda: