Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pelajari cara mengakses catatan untuk aplikasi Apache Hadoop YARN (Pengatur Sumber Daya Lain) pada kluster Apache Hadoop di Azure HDInsight.
Apa itu Apache YARN?
YARN mendukung beberapa model pemrograman (Apache Hadoop MapReduce menjadi salah satunya) dengan memisahkan manajemen sumber daya dari penjadwalan/pemantauan aplikasi. YARN menggunakan ResourceManager global (RM), per node pekerja NodeManagers (NMs), dan per aplikasi ApplicationMasters (AMs). AM per aplikasi menegosiasikan sumber daya (CPU, memori, disk, jaringan) untuk menjalankan aplikasi Anda dengan RM. RM bekerja dengan NM untuk memberikan sumber daya ini, yang diberikan sebagai kontainer . AM bertanggung jawab untuk melacak kemajuan kontainer yang ditugaskan kepadanya oleh RM. Aplikasi mungkin memerlukan banyak kontainer tergantung pada sifat aplikasi.
Setiap aplikasi dapat terdiri dari beberapa percobaan aplikasi . Jika aplikasi gagal, aplikasi mungkin dicoba kembali sebagai upaya baru. Setiap upaya berjalan dalam kontainer. Dalam arti tertentu, kontainer menyediakan konteks untuk unit dasar pekerjaan yang dilakukan oleh aplikasi YARN. Semua pekerjaan yang dilakukan dalam konteks kontainer dilakukan pada node pekerja tunggal di mana kontainer ditempatkan. Lihat Hadoop: Menulis Aplikasi YARN, atau apache Hadoop YARN untuk referensi lebih lanjut.
Untuk menskalakan kluster Anda untuk mendukung throughput pemrosesan yang lebih besar, Anda dapat menggunakan Autoscale atau Menskalakan kluster Anda secara manual menggunakan beberapa bahasa yang berbeda.
Server Garis Waktu YARN
Server Timeline Apache Hadoop YARN menyediakan informasi umum tentang aplikasi yang telah selesai
Server Garis Waktu YARN menyertakan jenis data berikut:
- ID aplikasi, pengidentifikasi unik aplikasi
- Pengguna yang memulai aplikasi
- Informasi tentang upaya yang dilakukan untuk menyelesaikan aplikasi
- Kontainer-kontainer yang digunakan oleh suatu aplikasi tertentu
Aplikasi dan log YARN
Log aplikasi (dan log kontainer terkait) sangat penting dalam men-debug aplikasi Hadoop yang bermasalah. YARN menyediakan kerangka kerja yang bagus untuk mengumpulkan, menggabungkan, dan menyimpan log aplikasi dengan Agregasi Log.
Fitur Agregasi Log membuat mengakses log aplikasi lebih deterministik. Ini menggabungkan log di semua kontainer pada simpul pekerja dan menyimpannya sebagai satu file log agregat per simpul pekerja. Log disimpan pada sistem file default setelah aplikasi selesai. Aplikasi Anda dapat menggunakan ratusan atau ribuan kontainer, tetapi log untuk semua kontainer yang dijalankan pada satu simpul pekerja selalu dikumpulkan ke satu file. Jadi hanya ada satu log untuk setiap simpul pekerja yang digunakan oleh aplikasi Anda. Agregasi Log diaktifkan secara default pada kluster HDInsight versi 3.0 ke atas. Log agregat terletak di penyimpanan default untuk kluster. Jalur berikut adalah jalur HDFS ke log:
/app-logs/<user>/logs/<applicationId>
Dalam jalur, user adalah nama pengguna yang memulai aplikasi.
applicationId adalah pengidentifikasi unik yang ditetapkan ke aplikasi oleh YARN RM.
Log agregat tidak dapat dibaca secara langsung, karena ditulis dalam TFile, format biner yang diindeks oleh kontainer. Gunakan log YARN ResourceManager atau alat CLI untuk melihat log ini sebagai teks biasa untuk kepentingan aplikasi atau kontainer.
Log yarn dalam kluster ESP
Dua konfigurasi harus ditambahkan ke mapred-site kustom di Ambari.
Dari browser web, arahkan ke
https://CLUSTERNAME.azurehdinsight.net, di manaCLUSTERNAMEmerupakan nama kluster Anda.Dari UI Ambari, navigasikan ke MapReduce2>Konfigurasi>Advanced>Custom mapred-site.
Tambahkan satu dari kumpulan properti berikut:
Set 1
mapred.acls.enabled=true mapreduce.job.acl-view-job=*Set 2
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>Simpan perubahan dan mulai ulang semua layanan yang terpengaruh.
Perangkat YARN CLI
Gunakan perintah ssh untuk menyambungkan ke kluster Anda. Edit perintah berikut dengan mengganti CLUSTERNAME dengan nama kluster Anda, lalu masukkan perintah:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netCantumkan semua ID aplikasi aplikasi Yarn yang sedang berjalan dengan perintah berikut:
yarn topPerhatikan ID aplikasi dari kolom
APPLICATIONIDyang lognya akan diunduh.YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerAnda dapat melihat log ini sebagai teks biasa dengan menjalankan salah satu perintah berikut:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>Tentukan <applicationId>, pengguna-yang-memulai-aplikasi <>, containerId <>, dan informasi alamat simpul pekerja <> saat menjalankan perintah ini.
Contoh perintah lainnya
Unduh log kontainer Yarn untuk semua master aplikasi dengan perintah berikut. Langkah ini membuat file log bernama
amlogs.txtdalam format teks.yarn logs -applicationId <application_id> -am ALL > amlogs.txtUnduh log kontainer Yarn khusus untuk master aplikasi terbaru dengan perintah berikut:
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txtUnduh log kontainer YARN untuk dua master aplikasi pertama dengan perintah berikut:
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtUnduh semua log kontainer Yarn dengan perintah berikut:
yarn logs -applicationId <application_id> > logs.txtUnduh log kontainer yarn untuk kontainer tertentu dengan perintah berikut:
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
YARN ResourceManager UI
UI YARN ResourceManager beroperasi pada node utama kluster. Ini diakses melalui UI web Ambari. Gunakan langkah-langkah berikut untuk melihat log YARN:
Di browser web Anda, navigasikan ke
https://CLUSTERNAME.azurehdinsight.net. Ganti CLUSTERNAME dengan nama kluster HDInsight Anda.Dari daftar layanan di sebelah kiri, pilih YARN.
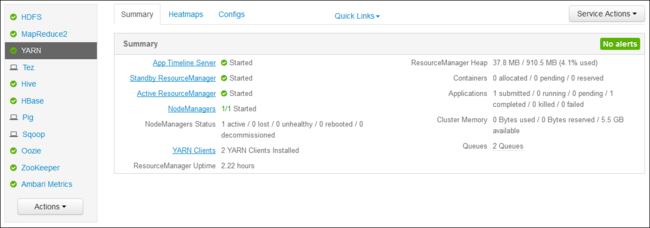
Dari menu dropdown Tautan Cepat, pilih salah satu simpul kepala kluster lalu pilih
ResourceManager Log.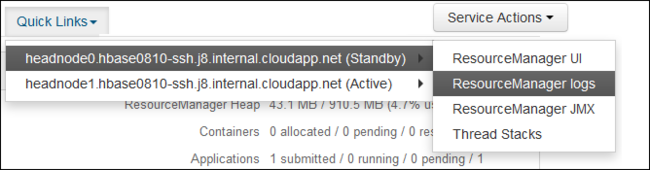
Anda disajikan dengan daftar tautan ke log YARN.