Mengelola log untuk kluster HDInsight
Kluster HDInsight menghasilkan berbagai file log. Misalnya, Apache Hadoop dan layanan terkait, seperti Apache Spark, menghasilkan log eksekusi pekerjaan yang terperinci. Manajemen file log adalah bagian dari mempertahankan kluster HDInsight yang sehat. Ada juga persyaratan peraturan untuk pengarsipan log. Karena jumlah dan ukuran file log, pengoptimalan penyimpanan log dan pengarsipan membantu manajemen biaya layanan.
Mengelola log kluster HDInsight termasuk menyimpan informasi tentang semua aspek lingkungan kluster. Informasi ini mencakup semua log Layanan Azure terkait, konfigurasi kluster, informasi eksekusi pekerjaan, kondisi kesalahan apa pun, dan data lainnya sesuai kebutuhan.
Langkah-langkah umum dalam manajemen log HDInsight adalah:
- Langkah 1: Menentukan kebijakan retensi log
- Langkah 2: Mengelola log konfigurasi versi layanan kluster
- Langkah 3: Mengelola file log eksekusi pekerjaan kluster
- Langkah 4: Memperkirakan ukuran dan biaya penyimpanan volume log
- Langkah 5: Menentukan kebijakan dan proses arsip log
Langkah 1: Menentukan kebijakan retensi log
Langkah pertama dalam membuat strategi manajemen log kluster HDInsight adalah mengumpulkan informasi tentang skenario bisnis dan persyaratan penyimpanan riwayat eksekusi pekerjaan.
Detail kluster
Detail kluster berikut ini berguna dalam membantu mengumpulkan informasi dalam strategi manajemen log Anda. Kumpulkan informasi ini dari semua kluster HDInsight yang telah Anda buat di akun Azure tertentu.
- Nama kluster
- Wilayah kluster dan zona ketersediaan Azure
- Kondisi kluster, termasuk rincian perubahan status terakhir
- Ketik dan jumlah instans HDInsight yang ditentukan untuk simpul master, inti, dan tugas
Anda bisa mendapatkan sebagian besar informasi tingkat teratas ini menggunakan portal Microsoft Azure. Atau, Anda dapat menggunakan Azure CLI untuk mendapatkan informasi tentang kluster HDInsight Anda:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
Anda juga bisa menggunakan PowerShell untuk menampilkan informasi ini. Untuk informasi selengkapnya, lihat Apache Kelola kluster Hadoop di HDInsight dengan menggunakan Azure PowerShell.
Pahami beban kerja yang berjalan pada kluster Anda
Penting untuk memahami jenis beban kerja yang berjalan pada kluster HDInsight Anda untuk merancang strategi pengelogan yang sesuai untuk setiap jenis.
- Apakah beban kerja bersifat eksperimental (seperti pengembangan atau pengujian) atau kualitas produksi?
- Seberapa sering beban kerja berkualitas produksi biasanya berjalan?
- Apakah salah satu beban kerja sumber daya intensif dan/atau berjalan lama?
- Apakah salah satu beban kerja menggunakan set layanan Hadoop yang kompleks yang menghasilkan beberapa jenis log diproduksi?
- Apakah salah satu beban kerja memiliki persyaratan silsilah data eksekusi peraturan yang dikaitkan?
Contoh pola dan praktik retensi log
Mempertimbangkan untuk mempertahankan pelacakan silsilah data dengan menambahkan pengidentifikasi ke setiap entri log, atau melalui teknik lain. Hal ini memungkinkan Anda untuk melacak kembali sumber asli data dan operasi, dan mengikuti data melalui setiap tahap guna memahami konsistensi dan validitasnya.
Mempertimbangkan bagaimana Anda dapat mengumpulkan log dari kluster, atau dari lebih dari satu kluster, dan menyusunnya untuk tujuan seperti audit, pemantauan, perencanaan, dan peringatan. Anda dapat menggunakan solusi kustom untuk mengakses dan mengunduh file log secara teratur, dan menggabungkan dan menganalisisnya untuk menyediakan tampilan dasbor. Anda juga dapat menambahkan kemampuan lain untuk memperingatkan deteksi keamanan atau kegagalan. Anda dapat membangun utilitas ini menggunakan PowerShell, HDInsight SDKs, atau kode yang mengakses model penyebaran klasik Azure.
Mempertimbangkan apakah solusi atau layanan pemantauan akan menjadi manfaat yang berguna. Pusat Sistem Microsoft menyediakan paket manajemen HDInsight. Anda juga dapat menggunakan alat pihak ketiga seperti Apache Chukwa dan Ganglia untuk mengumpulkan dan memusatkan log. Banyak perusahaan menawarkan layanan untuk memantau solusi big data berbasis Hadoop, misalnya:
Centerity, Compuware APM, Sematext SPM, dan Zettaset Orchestrator.
Langkah 2: Kelola versi layanan kluster dan tampilkan log
Kluster HDInsight yang khas menggunakan beberapa layanan dan paket perangkat lunak sumber terbuka (seperti Apache HBase, Apache Spark, dan sebagainya). Untuk beberapa beban kerja, seperti bioinformatik, Anda mungkin diharuskan mempertahankan riwayat log konfigurasi layanan selain log eksekusi pekerjaan.
Menampilkan pengaturan konfigurasi kluster dengan UI Ambari
Apache Ambari menyederhanakan manajemen dan pemantauan kluster HDInsight dengan menyediakan UI web dan REST API yang mudah digunakan. Ambari termasuk dalam kluster Microsoft Azure HDInsight berbasis Linux. Pilih panel Dasbor Kluster di halaman HDInsight portal Microsoft Azure untuk membuka halaman tautan Dasbor Kluster. Selanjutnya, pilih panel dasbor kluster HDInsight untuk membuka UI Ambari. Anda akan dimintai info masuk login kluster Anda.
Untuk membuka daftar tampilan layanan, pilih panel Tampilan Ambari di halaman portal Microsoft Azure untuk HDInsight. Daftar ini bervariasi, bergantung pada pustaka mana yang telah Anda pasang. Misalnya, Anda mungkin melihat Yarn Queue Manager, Apache Hive View, dan Tez View. Pilih tautan layanan apa pun untuk melihat informasi konfigurasi dan layanan. Halaman Tumpukan dan Versi Ambari UI menyediakan informasi tentang konfigurasi layanan kluster dan riwayat versi layanan. Untuk mengarahkan ke bagian ini dari UI Ambari, pilih menu Admin lalu Tumpukan dan Versi. Pilih tab Versi untuk melihat informasi versi layanan.
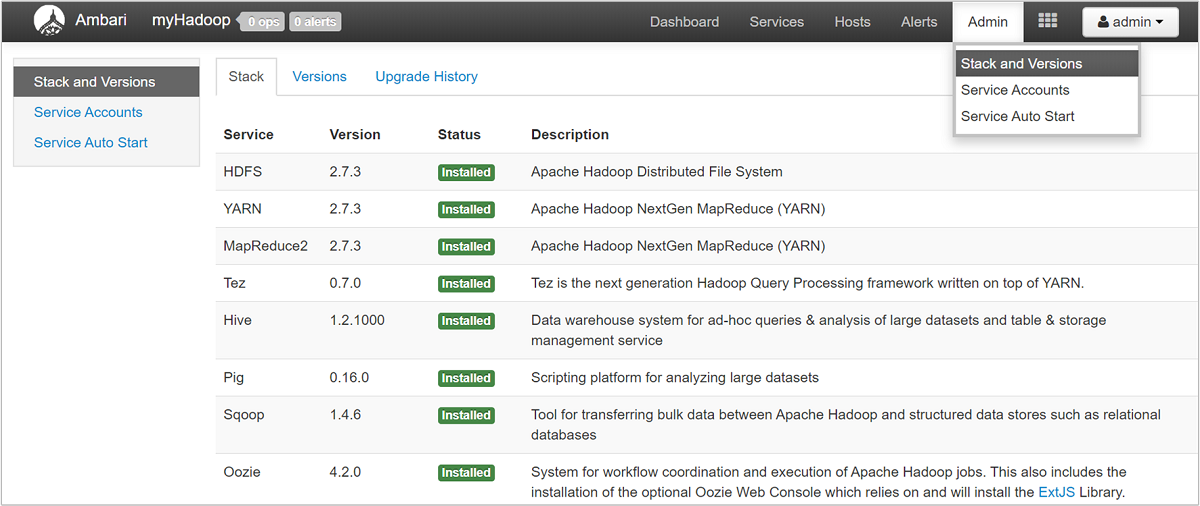
Penggunaan Ambari UI, Anda dapat mengunduh konfigurasi untuk setiap (atau semua) layanan yang berjalan pada host (atau simpul) tertentu di kluster. Pilih menu Host, lalu tautan untuk host yang diminati. Pada halaman host tersebut, pilih tombol Tindakan Host lalu Unduh Konfigurasi Klien.
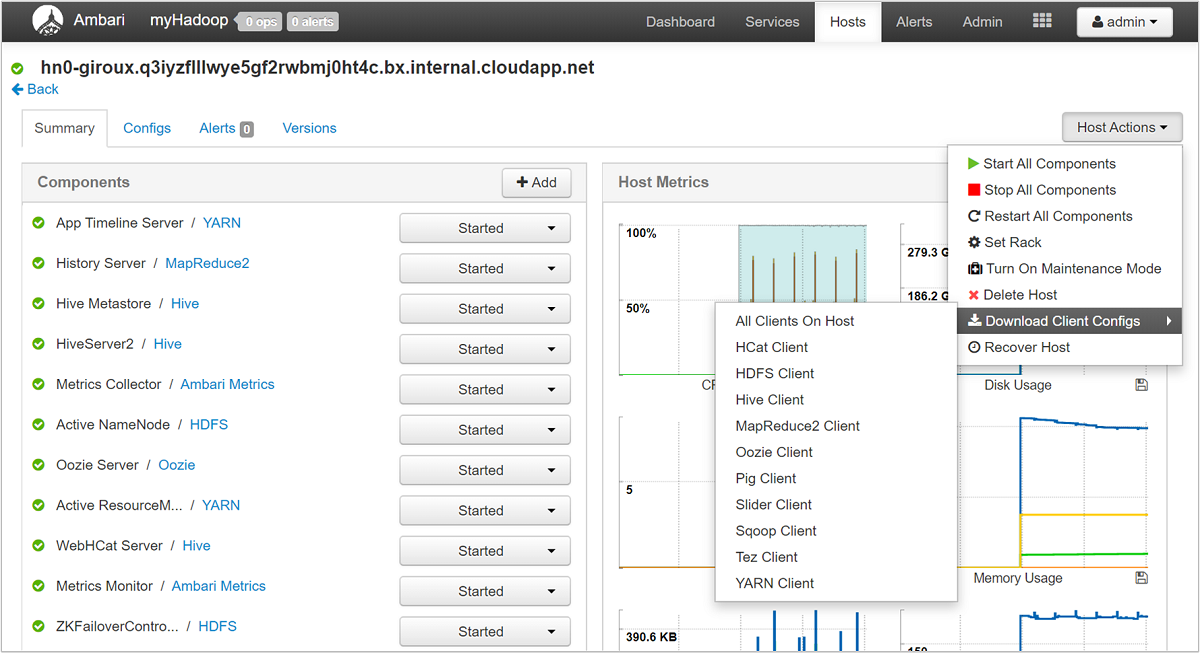
Tampilkan log tindakan skrip
Tindakan skrip HDInsight jalankan skrip pada kluster, baik secara manual atau ketika ditentukan. Misalnya, tindakan skrip dapat digunakan untuk menginstal perangkat lunak lain pada kluster atau untuk mengubah pengaturan konfigurasi dari nilai default. Log tindakan skrip dapat memberikan wawasan tentang kesalahan yang terjadi selama pengaturan kluster, dan juga perubahan pengaturan konfigurasi yang dapat memengaruhi kinerja dan ketersediaan kluster. Untuk melihat status tindakan skrip, pilih tombol ops di UI Ambari Anda, atau akses log status di akun penyimpanan default. Log penyimpanan tersedia di /STORAGE_ACCOUNT_NAME/DEFAULT_CONTAINER_NAME/custom-scriptaction-logs/CLUSTER_NAME/DATE.
Menampilkan log status peringatan Ambari
Apache Ambari menulis perubahan status peringatan ke ambari-alerts.log. Jalur lengkapnya adalah /var/log/ambari-server/ambari-alerts.log. Untuk mengaktifkan penelusuran kesalahan untuk log, ubah properti di /etc/ambari-server/conf/log4j.properties.Ubah lalu entri di bawah # Log alert state changes dari:
log4j.logger.alerts=INFO,alerts
to
log4j.logger.alerts=DEBUG,alerts
Langkah 3: Mengelola file log eksekusi pekerjaan kluster
Langkah selanjutnya adalah mengulas file log eksekusi pekerjaan untuk berbagai layanan. Layanan dapat mencakup Apache HBase, Apache Spark, dan banyak lainnya. Kluster Hadoop menghasilkan sejumlah besar log verbose, jadi menentukan log mana yang berguna (dan mana yang tidak) dapat memakan waktu. Pemahaman sistem pengelogan penting untuk manajemen file log yang ditargetkan. Gambar berikut adalah contoh file log.
Akses file log Hadoop
HDInsight menyimpan file lognya baik dalam sistem file kluster maupun di Azure Storage. Anda dapat memeriksa file log di kluster dengan membuka koneksi SSH ke kluster dan menelusuri sistem file, atau dengan menggunakan portal Status YARN Hadoop di server simpul kepala jarak jauh. Anda dapat memeriksa file log di Azure Storage menggunakan salah satu alat yang dapat mengakses dan mengunduh data dari Azure Storage. Contohnya adalah AzCopy, CloudXplorer, dan Visual Studio Server Explorer. Anda juga bisa menggunakan PowerShell dan pustaka Azure Storage Client, atau Azure .NET SDKs, untuk mengakses data di penyimpanan blob Azure.
Hadoop menjalankan pekerjaan sebagai upaya tugas pada berbagai simpul dalam kluster. HDInsight dapat memulai upaya tugas spekulatif, mengakhiri upaya tugas lain yang tidak selesai terlebih dahulu. Ini menghasilkan aktivitas signifikan yang dicatat ke file log pengontrol, stderr, dan syslog on-the-fly. Selain itu, beberapa upaya tugas berjalan secara bersamaan, tetapi file log hanya dapat menampilkan hasil secara linear.
Log HDInsight ditulis ke penyimpanan Azure Blob
Kluster HDInsight dikonfigurasi untuk menulis log tugas ke akun penyimpanan Azure Blob untuk pekerjaan apa pun yang dikirimkan menggunakan cmdlet Azure PowerShell atau API pengiriman pekerjaan .NET. Jika Anda mengirimkan pekerjaan melalui SSH ke kluster, maka informasi pencatatan eksekusi disimpan di Tabel Azure seperti yang dibahas di bagian sebelumnya.
Selain file log inti yang dihasilkan oleh HDInsight, layanan yang dipasang seperti YARN juga menghasilkan file log eksekusi pekerjaan. Jumlah dan jenis file log tergantung pada layanan yang dipasang. Layanan umum adalah Apache HBase, Apache Spark, dan sebagainya. Menyelidiki file eksekusi log pekerjaan untuk setiap layanan untuk memahami keseluruhan file pencatatan yang tersedia di kluster Anda. Setiap layanan memiliki metode pengelogan dan lokasi uniknya sendiri untuk menyimpan file log. Sebagai contoh, detail untuk mengakses file log layanan yang paling umum (dari YARN) dibahas di bagian berikut.
Log HDInsight yang dihasilkan oleh YARN
YARN menggabungkan log di semua kontainer pada simpul pekerja dan menyimpan log tersebut sebagai satu file log agregat per simpul pekerja. Log disimpan pada sistem file default setelah aplikasi selesai. Aplikasi Anda dapat menggunakan ratusan atau ribuan kontainer, tetapi log untuk semua kontainer yang dijalankan pada satu simpul pekerja selalu dikumpulkan ke satu file. Jadi hanya ada 1 log per simpul pekerja yang digunakan oleh aplikasi Anda. Agregasi log diaktifkan secara default pada kluster HDInsight versi 3.0 ke atas. Log agregat terletak di penyimpanan default untuk kluster.
/app-logs/<user>/logs/<applicationId>
Log agregat tidak dapat dibaca secara langsung, karena ditulis dalam format biner yang TFile diindeks oleh kontainer. Gunakan log YARN ResourceManager atau alat CLI untuk melihat log ini sebagai teks biasa untuk kepentingan aplikasi atau kontainer.
Alat CLI YARN
Untuk menggunakan alat YARN CLI, Anda harus terlebih dahulu terhubung ke kluster HDInsight menggunakan SSH. Tentukan <applicationId>, <user-who-started-the-application>, <containerId>, dan <worker-node-address> informasi saat menjalankan perintah ini. Anda bisa menampilkan log ini sebagai teks biasa dengan menjalankan salah satu perintah berikut:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application>
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>
YARN Resource Manager UI
UI YARN Resource Manager berjalan pada simpul kepala kluster, dan diakses melalui antarmuka pengguna web Ambari. Gunakan langkah-langkah berikut untuk melihat log YARN:
- Di browser web, arahkan ke
https://CLUSTERNAME.azurehdinsight.net. Ganti CLUSTERNAME dengan nama kluster HDInsight Anda. - Dari daftar layanan di sebelah kiri, pilih YARN.
- Dari menu dropdown Tautan Cepat, pilih salah satu simpul kepala kluster lalu pilih log Resource Manager. Anda disajikan dengan daftar tautan ke log YARN.
Langkah 4: Memperkirakan ukuran dan biaya penyimpanan volume log
Setelah menyelesaikan langkah-langkah sebelumnya, Anda memiliki pemahaman tentang jenis dan volume file log yang diproduksi oleh kluster HDInsight Anda.
Selanjutnya, Menganalisa volume data log di lokasi penyimpanan log kunci selama periode waktu tertentu. Misalnya, Anda dapat menganalisa volume dan pertumbuhan selama periode 30-60-90 hari. Rekam informasi ini di spreadsheet atau gunakan alat lain seperti Visual Studio, Azure Storage Explorer, atau Power Query untuk Excel. ```
Anda sekarang memiliki cukup informasi untuk membuat strategi manajemen log untuk log kunci. Gunakan spreadsheet Anda (atau alat pilihan) untuk memperkirakan pertumbuhan ukuran log dan biaya layanan Azure penyimpanan log ke depannya. Mempertimbangkan juga setiap persyaratan retensi.log untuk set log yang sedang Anda periksa. Sekarang Anda dapat memperkirakan ulang biaya penyimpanan log di masa mendatang, setelah menentukan file log mana yang dapat dihapus (jika ada) dan log mana yang harus dipertahankan dan diarsipkan ke Azure Storage yang lebih murah.
Langkah 5: Menentukan kebijakan dan proses arsip log
Setelah menentukan file log mana yang dapat dihapus, Anda dapat menyesuaikan parameter pengelogan pada banyak layanan Hadoop untuk menghapus file log secara otomatis setelah periode waktu yang ditentukan.
Untuk file log tertentu, Anda dapat menggunakan pendekatan pengarsipan file log dengan harga lebih rendah. Untuk log aktivitas Azure Resource Manager, Anda dapat menjelajahi pendekatan ini menggunakan portal Microsoft Azure. Menyiapkan pengarsipan log Resource Manager dengan memilih tautan Log Aktivitas di portal Microsoft Azure untuk instans HDInsight Anda. Di bagian atas halaman pencarian Log Aktivitas, pilih item menu Ekspor untuk membuka panel Ekspor log aktivitas. Isi langganan, wilayah, apakah akan mengekspor ke akun penyimpanan, dan berapa hari untuk menyimpan log. Pada panel yang sama ini, Anda juga dapat mengindikasikan apakah akan mengekspor ke hub peristiwa.
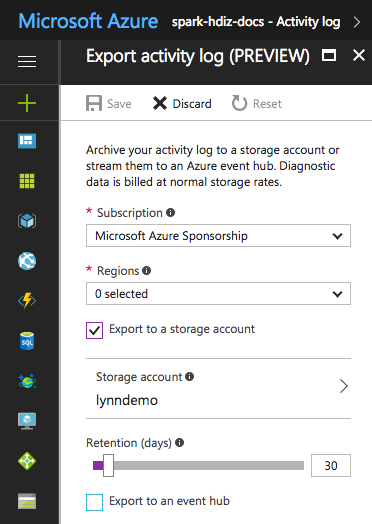
Atau, Anda dapat membuat pengarsipan log skrip dengan PowerShell.
Mengakses metrik Azure Storage
Azure Storage dapat dikonfigurasi untuk mencatat operasi dan akses penyimpanan. Anda dapat menggunakan log terperinci ini untuk pemantauan dan perencanaan kapasitas, dan untuk mengaudit permintaan ke penyimpanan. Informasi yang dicatat mencakup detail latensi, memungkinkan Anda untuk memantau dan menyempurnakan performa solusi Anda. Anda dapat menggunakan .NET SDK untuk Hadoop untuk memeriksa file log yang dihasilkan untuk Azure Storage yang menyimpan data untuk kluster HDInsight.
Kontrol ukuran dan jumlah indeks cadangan untuk file log lama
Untuk mengontrol ukuran dan jumlah file log yang dipertahankan, set properti berikut dari RollingFileAppender:
maxFileSizeadalah ukuran penting file, yang filenya digulung. Nilai defaultnya adalah 10 MB.maxBackupIndexMenspesifikasikan jumlah file cadangan yang akan dibuat, default 1.
Teknik manajemen log lainnya
Untuk menghindari kehabisan ruang disk, Anda dapat menggunakan beberapa alat OS seperti logrotate untuk mengelola penanganan file log. Anda dapat mengonfigurasi logrotate untuk berjalan setiap hari, mengompresi file log dan menghapus file lama. Pendekatan Anda bergantung pada kebutuhan Anda, seperti berapa lama file log disimpan di node lokal.
Anda juga dapat memeriksa apakah pengelogan DEBUG diaktifkan untuk satu atau beberapa layanan, yang sangat meningkatkan ukuran log output.
Untuk mengumpulkan log dari semua simpul ke satu lokasi pusat, Anda dapat membuat aliran data, seperti menelan semua entri log ke Solr.