Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Alur data mendasari berbagai solusi analitik data. Seperti namanya, alur data mengambil data mentah, membersihkan, dan membentuknya kembali sesuai kebutuhan, dan kemudian biasanya melakukan perhitungan atau agregasi sebelum menyimpan data yang diproses. Data yang diproses digunakan untuk klien, laporan, atau API. Alur data harus memberikan hasil yang dapat diulang, baik pada jadwal atau saat dipicu oleh data baru.
Artikel ini menjelaskan cara mengoperasionalkan alur data Anda untuk pengulangan, dengan menggunakan Oozie yang berjalan pada kluster HDInsight Hadoop. Contoh skenario ini memandu Anda melintasi alur data yang menyiapkan dan memproses data rangkaian waktu penerbangan maskapai.
Dalam skenario berikut, data inputnya adalah file datar yang berisi kumpulan data penerbangan selama satu bulan. Data penerbangan ini mencakup informasi seperti bandara asal dan tujuan, mil yang diterbangkan, waktu keberangkatan dan kedatangan, dan sebagainya. Tujuan dari alur ini adalah untuk meringkas kinerja maskapai harian, di mana setiap maskapai memiliki satu baris untuk setiap hari dengan rata-rata keterlambatan keberangkatan dan kedatangan dalam hitungan menit, dan total mil yang diterbangkan hari itu.
| YEAR | MONTH | HARI_DALAM_SEBULAN | OPERATOR | RATA-RATA_PENUNDAAN_KEBERANGKATAN | RATA-RATA_PENUNDAAN_KEDATANGAN | TOTAL_JARAK |
|---|---|---|---|---|---|---|
| 2017 | 1 | 3 | AA | 10.142229 | 7.862926 | 2644539 |
| 2017 | 1 | 3 | AS | 9.435449 | 5.482143 | 572289 |
| 2017 | 1 | 3 | DL | 6.935409 | -2.1893024 | 1909696 |
Contoh alur ini menunggu sampai data penerbangan periode waktu baru tiba, kemudian menyimpan informasi penerbangan terperinci ke gudang data Apache Hive Anda untuk analisis jangka panjang. Alur ini juga membuat kumpulan data yang jauh lebih kecil yang hanya meringkas data penerbangan harian. Data ringkasan penerbangan harian ini dikirim ke SQL Database untuk menyediakan laporan, seperti untuk situs web.
Diagram berikut menggambarkan contoh alur.
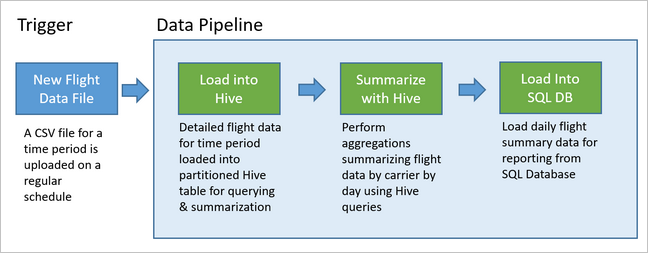
Ikhtisar solusi Apache Oozie
Alur ini menggunakan Apache Oozie yang berjalan pada kluster HDInsight Hadoop.
Oozie menjelaskan alurnya dengan tindakan, alur kerja, dan koordinator. Tindakan menentukan pekerjaan sebenarnya yang dilakukan, seperti menjalankan kueri Apache Hive. Alur kerja menentukan urutan tindakan. Koordinator menentukan jadwal kapan alur kerja dijalankan. Koordinator juga dapat menunggu ketersediaan data baru sebelum meluncurkan instans alur kerja.
Diagram berikut menunjukkan rancangan tingkat tinggi dari contoh alur Oozie ini.
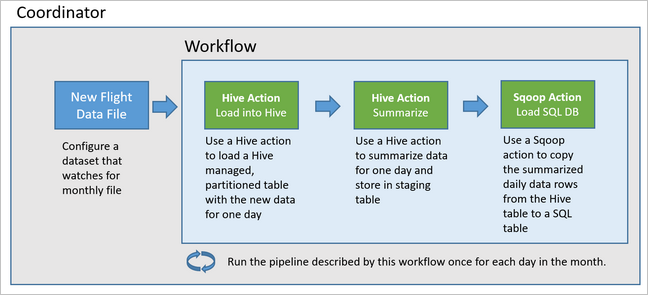
Penyediaan sumber daya Azure
Alur ini membutuhkan Azure SQL Database dan kluster HDInsight Hadoop berada di lokasi yang sama. Azure SQL Database menyimpan data ringkasan yang dihasilkan oleh alur dan Oozie Metadata Store.
Penyediaan Azure SQL Database
Buat Azure SQL Database. Lihat Membuat Azure SQL Database di portal Microsoft Azure.
Untuk memastikan kluster HDInsight Anda dapat mengakses Azure SQL Database yang terhubung, konfigurasikan aturan firewall Azure SQL Database untuk memungkinkan layanan dan sumber daya Azure mengakses server. Anda dapat mengaktifkan opsi ini di portal Microsoft Azure dengan memilih Mengatur firewall server, dan memilih NYALA di bawah Memungkinkan layanan dan sumber daya Azure untuk mengakses server ini untuk Azure SQL Database. Untuk informasi selengkapnya, lihat Membuat dan mengelola aturan firewall IP.
Gunakan Editor kueri untuk menjalankan pernyataan SQL berikut untuk membuat tabel
dailyflightsyang akan menyimpan data ringkas dari setiap perjalanan alur.CREATE TABLE dailyflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER CHAR(2), AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) GO CREATE CLUSTERED INDEX dailyflights_clustered_index on dailyflights(YEAR,MONTH,DAY_OF_MONTH,CARRIER) GO
Azure SQL Database Anda sudah siap sekarang.
Penyediaan Apache Hadoop Cluster
Buat kluster Apache Hadoop dengan metastore kustom. Selama pembuatan kluster dari portal, dari tab Penyimpanan, pastikan Anda memilih SQL Database Anda di bawah Pengaturan Metastore. Untuk informasi selengkapnya tentang pemilihan metastore, lihat Memilih metastore kustom selama pembuatan kluster. Untuk informasi selengkapnya tentang pembuatan kluster, lihat Mulai menggunakan HDInsight pada Linux.
Memverifikasi penyiapan terowongan SSH
Untuk menggunakan Oozie Web Console untuk melihat status koordinator dan instans alur kerja Anda, siapkan terowongan SSH ke kluster HDInsight Anda. Untuk informasi selengkapnya, lihat Terowongan SSH.
Catatan
Anda juga dapat menggunakan Chrome dengan ekstensi Foxy Proxy untuk menelusuri sumber daya web kluster Anda melintasi terowongan SSH. Konfigurasikan untuk mewakili semua permintaan melalui hos localhost pada port terowongan 9876. Pendekatan ini kompatibel dengan Subsistem Windows untuk Linux, juga dikenal sebagai Bash pada Windows 10.
Jalankan perintah berikut untuk membuka terowongan SSH ke kluster Anda, di mana
CLUSTERNAMEadalah nama kluster Anda:ssh -C2qTnNf -D 9876 sshuser@CLUSTERNAME-ssh.azurehdinsight.netPastikan terowongan beroperasi dengan mengarahkan ke Ambari di headnode Anda dengan menelusuri ke:
http://headnodehost:8080Untuk mengakses Oozie Web Console dari dalam Ambari, navigasikan ke Oozie>Tautan Cepat> [Server aktif] >Oozie Antarmuka Web.
Mengonfigurasi Apache Hive
Menggunggah data
Unduh contoh file CSV yang berisi data penerbangan selama satu bulan. Unduh file ZIP
2017-01-FlightData.zipdari repositori HDInsight GitHub dan buka kompresannya ke file CSV2017-01-FlightData.csv.Salin file CSV ini ke akun Azure Storage yang terpasang ke kluster HDInsight Anda dan letakkan di folder
/example/data/flights.Gunakan SCP untuk menyalin file dari mesin lokal Anda ke penyimpanan lokal headnode kluster HDInsight Anda.
scp ./2017-01-FlightData.csv sshuser@CLUSTERNAME-ssh.azurehdinsight.net:2017-01-FlightData.csvGunakan perintah ssh untuk menyambungkan ke kluster Anda. Edit perintah di bawah ini dengan mengganti
CLUSTERNAMEdengan nama kluster Anda, lalu masukkan perintah:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netDari sesi ssh Anda, gunakan perintah HDFS untuk menyalin file dari penyimpanan lokal head node Anda ke Azure Storage.
hadoop fs -mkdir /example/data/flights hdfs dfs -put ./2017-01-FlightData.csv /example/data/flights/2017-01-FlightData.csv
Membuat tabel
Data sampel sekarang tersedia. Akan tetapi, alur membutuhkan dua tabel Apache Hive untuk pemrosesan, satu untuk data masuk (rawFlights) dan satu untuk data ringkas (flights). Buat tabel ini di Ambari seperti berikut ini.
Masuklah ke Ambari dengan mengarahkan ke
http://headnodehost:8080.Dari daftar layanan, pilih Apache Hive.
Pilih Buka Tampilan di samping label Apache Hive View 2.0.
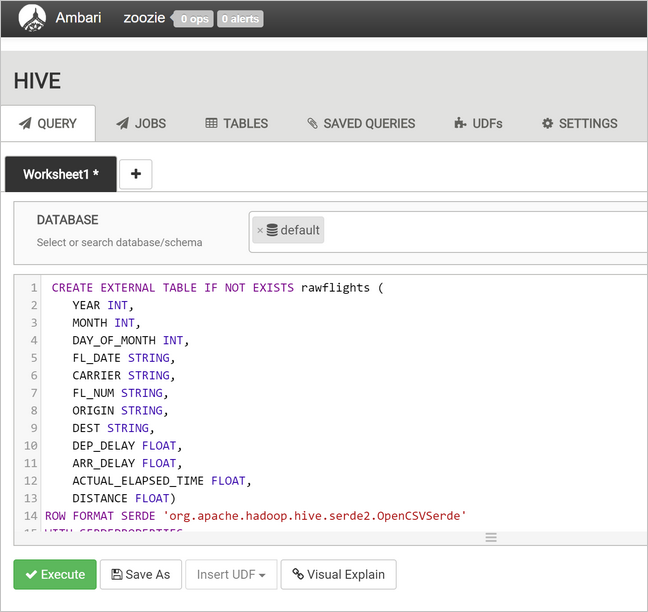
Di area teks kueri, tempelkan pernyataan berikut ini untuk membuat tabel
rawFlights. TabelrawFlightsini menyediakan skema-untuk-baca untuk file CSV dalam folder/example/data/flightsdi Azure Storage.CREATE EXTERNAL TABLE IF NOT EXISTS rawflights ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" ) LOCATION '/example/data/flights'Pilih Jalankan untuk membuat tabel.
Untuk membuat tabel
flights, ganti teks di area teks kueri dengan pernyataan berikut. Tabelflightsadalah tabel yang dikelola Apache Hive yang mempartisi data yang dimuat ke dalamnya berdasarkan tahun, bulan, dan hari dalam sebulan. Tabel ini akan mengandung semua riwayat data penerbangan, dengan granularitas terendah berada dalam satu baris data sumber per penerbangan.SET hive.exec.dynamic.partition.mode=nonstrict; CREATE TABLE flights ( FL_DATE STRING, CARRIER STRING, FL_NUM STRING, ORIGIN STRING, DEST STRING, DEP_DELAY FLOAT, ARR_DELAY FLOAT, ACTUAL_ELAPSED_TIME FLOAT, DISTANCE FLOAT ) PARTITIONED BY (YEAR INT, MONTH INT, DAY_OF_MONTH INT) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde' WITH SERDEPROPERTIES ( "separatorChar" = ",", "quoteChar" = "\"" );Pilih Jalankan untuk membuat tabel.
Membuat alur kerja Oozie
Alur biasanya memproses data dalam batch dengan interval waktu tertentu. Dalam hal ini, alur memproses data penerbangan secara harian. Pendekatan ini memungkinkan file CSV input tiba secara harian, mingguan, bulanan, atau tahunan.
Alur kerja sampel memproses data penerbangan dari hari ke hari, dalam tiga langkah utama:
- Menjalankan kueri Apache Hive untuk mengekstrak data untuk rentang tanggal hari itu dari file CSV sumber yang diwakili oleh tabel
rawFlightsdan menyisipkan data ke dalam tabelflights. - Menjalankan kueri Apache Hive untuk membuat tabel berjenjang secara dinamis di Apache Hive untuk hari itu, yang berisi salinan data penerbangan yang dirangkum berdasarkan hari dan operator.
- Menggunakan Apache Sqoop untuk menyalin semua data dari tabel berjenjang harian di Hive ke tabel tujuan
dailyflightsdi Azure SQL Database. Sqoop membaca baris sumber dari data di balik tabel Apache Hive yang berada di Azure Storage dan memuatnya ke dalam SQL Database menggunakan koneksi JDBC.
Ketiga langkah ini dikoordinasikan oleh alur kerja Oozie.
Dari stasiun kerja lokal Anda, buat file bernama
job.properties. Gunakan teks di bawah ini sebagai konten awal untuk file. Kemudian perbarui nilai untuk lingkungan spesifik Anda. Tabel di bawah teks meringkas setiap properti dan menunjukkan di mana Anda dapat menemukan nilai untuk lingkungan Anda sendiri.nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net jobTracker=[ACTIVERESOURCEMANAGER]:8050 queueName=default oozie.use.system.libpath=true appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie oozie.wf.application.path=${appBase}/load_flights_by_day hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql hiveDailyTableName=dailyflights${year}${month}${day} hiveDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/${year}/${month}/${day} sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]" sqlDatabaseTableName=dailyflights year=2017 month=01 day=03Properti Sumber nilai nameNode Jalur lengkap ke Azure Storage Container terpasang pada kluster HDInsight Anda. jobTracker Nama hos internal ke headnode YARN kluster aktif Anda. Pada halaman beranda Ambari, pilih YARN dari daftar layanan, lalu pilih Active Resource Manager. URI nama host ditampilkan di bagian atas halaman. Tambahkan port 8050. queueName Nama antrean YARN digunakan saat menjadwalkan tindakan Apache Hive. Biarkan sebagai default. oozie.use.system.libpath Biarkan tetap true. appBase Jalur ke subfolder di Azure Storage tempat Anda menggunakan alur kerja Oozie dan file pendukung. oozie.wf.application.path Lokasi alur kerja Oozie workflow.xmldijalankan.hiveScriptLoadPartition Jalur di Azure Storage ke file kueri Apache Hive hive-load-flights-partition.hql.hiveScriptMembuatDailyTable Jalur di Azure Storage ke file kueri Apache Hive hive-create-daily-summary-table.hql.hiveDailyTableName Nama yang dihasilkan secara dinamis yang digunakan untuk tabel berjenjang. hiveDataFolder Jalur di Azure Storage ke data yang dikandung oleh tabel berjenjang. sqlDatabaseConnectionString String koneksi sintaks JDBC ke Azure SQL Database Anda. sqlDatabaseTableName Nama tabel di Azure SQL Database tempat baris ringkasan disisipkan. Biarkan tetap dailyflights.tahun Komponen tahun dari hari di mana ringkasan penerbangan dihitung. Biarkan apa adanya. month Komponen bulan dari hari di mana ringkasan penerbangan dihitung. Biarkan apa adanya. hari Komponen hari dalam sebulan dari hari di mana ringkasan penerbangan dihitung. Biarkan apa adanya. Dari stasiun kerja lokal Anda, buat file bernama
hive-load-flights-partition.hql. Gunakan kode di bawah ini sebagai konten untuk file.SET hive.exec.dynamic.partition.mode=nonstrict; INSERT OVERWRITE TABLE flights PARTITION (YEAR, MONTH, DAY_OF_MONTH) SELECT FL_DATE, CARRIER, FL_NUM, ORIGIN, DEST, DEP_DELAY, ARR_DELAY, ACTUAL_ELAPSED_TIME, DISTANCE, YEAR, MONTH, DAY_OF_MONTH FROM rawflights WHERE year = ${year} AND month = ${month} AND day_of_month = ${day};Variabel Oozie menggunakan sintaks
${variableName}. Variabel ini diatur dalam filejob.properties. Oozie menggantikan nilai sebenarnya saat runtime.Dari stasiun kerja lokal Anda, buat file bernama
hive-create-daily-summary-table.hql. Gunakan kode di bawah ini sebagai konten untuk file.DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName} ( YEAR INT, MONTH INT, DAY_OF_MONTH INT, CARRIER STRING, AVG_DEP_DELAY FLOAT, AVG_ARR_DELAY FLOAT, TOTAL_DISTANCE FLOAT ) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT year, month, day_of_month, carrier, avg(dep_delay) avg_dep_delay, avg(arr_delay) avg_arr_delay, sum(distance) total_distance FROM flights GROUP BY year, month, day_of_month, carrier HAVING year = ${year} AND month = ${month} AND day_of_month = ${day};Kueri ini membuat tabel berjenjang yang hanya akan menyimpan data ringkasan selama satu hari, perhatikan pernyataan SELECT yang menghitung penundaan rata-rata dan total jarak yang diterbangkan oleh operator berdasarkan hari. Data yang dimasukkan ke dalam tabel ini disimpan di lokasi yang diketahui (jalur yang ditunjukkan oleh variabel hiveDataFolder) sehingga dapat digunakan sebagai sumber oleh Sqoop di langkah berikutnya.
Dari stasiun kerja lokal Anda, buat file bernama
workflow.xml. Gunakan kode di bawah ini sebagai konten untuk file. Langkah-langkah di atas ini dinyatakan sebagai tindakan terpisah dalam file alur kerja Oozie.<workflow-app name="loadflightstable" xmlns="uri:oozie:workflow:0.5"> <start to = "RunHiveLoadFlightsScript"/> <action name="RunHiveLoadFlightsScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptLoadPartition}</script> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> </hive> <ok to="RunHiveCreateDailyFlightTableScript"/> <error to="fail"/> </action> <action name="RunHiveCreateDailyFlightTableScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScriptCreateDailyTable}</script> <param>hiveTableName=${hiveDailyTableName}</param> <param>year=${year}</param> <param>month=${month}</param> <param>day=${day}</param> <param>hiveDataFolder=${hiveDataFolder}/${year}/${month}/${day}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}/${year}/${month}/${day}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>
Dua kueri Apache Hive diakses berdasarkan jalurnya di Azure Storage, dan nilai variabel yang tersisa disediakan oleh file job.properties. File ini mengonfigurasi alur kerja untuk dijalankan untuk tanggal 3 Januari 2017.
Menerapkan dan menjalankan alur kerja Oozie
Gunakan SCP dari sesi bash Anda untuk menyebarkan alur kerja Oozie Anda (workflow.xml), kueri Apache Hive (hive-load-flights-partition.hql dan hive-create-daily-summary-table.hql), dan konfigurasi pekerjaan (job.properties). Di Oozie, hanya file job.properties yang dapat berada di penyimpanan lokal headnode. Semua file lain harus disimpan dalam HDFS, dalam hal ini Azure Storage. Tindakan Sqoop yang digunakan oleh alur kerja mengandalkan driver JDBC untuk berkomunikasi dengan SQL Database Anda, yang harus disalin dari headnode ke HDFS.
Buat subfolder
load_flights_by_daydi bawah jalur pengguna di penyimpanan lokal headnode. Dari sesi ssh terbuka Anda, jalankan perintah di bawah ini:mkdir load_flights_by_daySalin semua file di direktori saat ini (file
workflow.xmldanjob.properties) ke subfolderload_flights_by_day. Dari stasiun kerja lokal Anda, jalankan perintah berikut:scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:load_flights_by_daySalin file alur kerja ke HDFS. Dari sesi ssh terbuka Anda, jalankan perintah di bawah ini:
cd load_flights_by_day hadoop fs -mkdir -p /oozie/load_flights_by_day hdfs dfs -put ./* /oozie/load_flights_by_daySalin
mssql-jdbc-7.0.0.jre8.jardari headnode lokal ke folder alur kerja di HDFS. Revisi perintah sesuai kebutuhan jika kluster Anda berisi file jar yang berbeda. Revisiworkflow.xmlsesuai kebutuhan untuk mencerminkan file jar yang berbeda. Dari sesi ssh terbuka Anda, jalankan perintah di bawah ini:hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /oozie/load_flights_by_dayJalankan alur kerja. Dari sesi ssh terbuka Anda, jalankan perintah di bawah ini:
oozie job -config job.properties -runAmati status menggunakan Oozie Web Console. Dari dalam Ambari, pilih Oozie, Tautan Cepat, lalu Oozie Web Console. Di bawah tab Pekerjaan Alur Kerja, pilih Semua Pekerjaan.
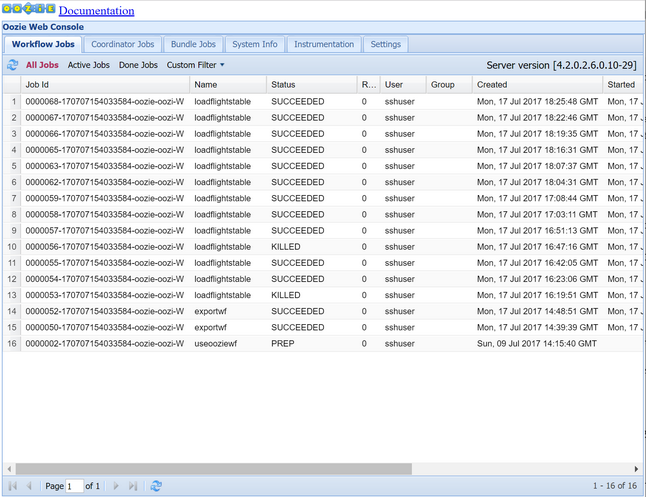
Ketika status BERHASIL, kuerikan tabel SQL Database untuk menampilkan baris yang disisipkan. Dengan menggunakan portal Microsoft Azure, arahkan ke panel untuk SQL Database Anda, pilih Alat, dan buka Editor Kueri.
SELECT * FROM dailyflights
Sekarang setelah alur kerja berjalan untuk satu hari pengujian, Anda dapat menutup alur kerja ini dengan koordinator yang menjadwalkan alur kerja agar berjalan setiap hari.
Menjalankan alur kerja dengan koordinator
Untuk menjadwalkan alur kerja ini agar berjalan setiap hari (atau semua hari dalam rentang tanggal), Anda bisa menggunakan koordinator. Koordinator didefinisikan oleh file XML, contohnya coordinator.xml:
<coordinator-app name="daily_export" start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" timezone="UTC" xmlns="uri:oozie:coordinator:0.4">
<datasets>
<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC">
<uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template>
<done-flag></done-flag>
</dataset>
</datasets>
<input-events>
<data-in name="event_input1" dataset="ds_input1">
<instance>${coord:current(0)}</instance>
</data-in>
</input-events>
<action>
<workflow>
<app-path>${appBase}/load_flights_by_day</app-path>
<configuration>
<property>
<name>year</name>
<value>${coord:formatTime(coord:nominalTime(), 'yyyy')}</value>
</property>
<property>
<name>month</name>
<value>${coord:formatTime(coord:nominalTime(), 'MM')}</value>
</property>
<property>
<name>day</name>
<value>${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveScriptLoadPartition</name>
<value>${hiveScriptLoadPartition}</value>
</property>
<property>
<name>hiveScriptCreateDailyTable</name>
<value>${hiveScriptCreateDailyTable}</value>
</property>
<property>
<name>hiveDailyTableNamePrefix</name>
<value>${hiveDailyTableNamePrefix}</value>
</property>
<property>
<name>hiveDailyTableName</name>
<value>${hiveDailyTableNamePrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}${coord:formatTime(coord:nominalTime(), 'MM')}${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>hiveDataFolderPrefix</name>
<value>${hiveDataFolderPrefix}</value>
</property>
<property>
<name>hiveDataFolder</name>
<value>${hiveDataFolderPrefix}${coord:formatTime(coord:nominalTime(), 'yyyy')}/${coord:formatTime(coord:nominalTime(), 'MM')}/${coord:formatTime(coord:nominalTime(), 'dd')}</value>
</property>
<property>
<name>sqlDatabaseConnectionString</name>
<value>${sqlDatabaseConnectionString}</value>
</property>
<property>
<name>sqlDatabaseTableName</name>
<value>${sqlDatabaseTableName}</value>
</property>
</configuration>
</workflow>
</action>
</coordinator-app>
Seperti yang Anda lihat, sebagian besar koordinator hanya meneruskan informasi konfigurasi ke instans alur kerja. Akan tetapi, ada beberapa item penting yang harus diperintah.
Poin 1: Atribut
startdanendpada elemencoordinator-appsendiri mengontrol interval waktu di tempat koordinator berjalan.<coordinator-app ... start="2017-01-01T00:00Z" end="2017-01-05T00:00Z" frequency="${coord:days(1)}" ...>Koordinator bertanggung jawab untuk menjadwalkan tindakan dalam rentang tanggal
startdanend, sesuai dengan interval yang ditentukan oleh atributfrequency. Setiap tindakan terjadwal pada gilirannya menjalankan alur kerja sebagaimana dikonfigurasi. Dalam definisi koordinator di atas, koordinator dikonfigurasi untuk menjalankan tindakan dari 1 Januari 2017 hingga 5 Januari 2017. Frekuensi diatur ke satu hari oleh ekspresi frekuensi Oozie Expression Language${coord:days(1)}. Tindakan ini menyebabkan koordinator menjadwalkan tindakan (dan karenanya alur kerja) sekali per hari. Untuk rentang tanggal yang ada di masa lalu, seperti dalam contoh ini, tindakan akan dijadwalkan untuk berjalan tanpa penundaan. Awal tanggal tindakan dijadwalkan untuk berjalan disebut waktu nominal. Contohnya, untuk memproses data untuk 1 Januari 2017 koordinator akan menjadwalkan aksi dengan nominal waktu 2017-01-01T00:00:00 GMT.Poin 2: Dalam rentang tanggal alur kerja, elemen
datasetmenentukan tempat mencari HDFS untuk data pada rentang tanggal tertentu, dan mengonfigurasi cara Oozie menentukan apakah data sudah tersedia untuk diproses.<dataset name="ds_input1" frequency="${coord:days(1)}" initial-instance="2016-12-31T00:00Z" timezone="UTC"> <uri-template>${sourceDataFolder}${YEAR}-${MONTH}-FlightData.csv</uri-template> <done-flag></done-flag> </dataset>Jalur ke data dalam HDFS dibangun secara dinamis sesuai dengan ekspresi yang disediakan dalam elemen
uri-template. Dalam koordinator ini, frekuensi satu hari juga digunakan dengan set data. Meski tanggal mulai dan berakhir pada kontrol elemen koordinator saat tindakan dijadwalkan (dan menentukan waktu nominalnya),initial-instancedanfrequencypada set data mengontrol perhitungan tanggal yang digunakan dalam membangunuri-template. Dalam hal ini, atur instans awal ke satu hari sebelum dimulainya koordinator untuk memastikan bahwa instans mengambil data senilai hari pertama (1 Januari 2017). Perhitungan tanggal set data bergulir dari nilaiinitial-instance(31/12/2016) berlanjut dengan pertambahan frekuensi set data (satu hari) hingga menemukan tanggal terbaru yang tidak melewati waktu nominal yang ditetapkan oleh koordinator (2017-01-01T00:00:00 GMT untuk tindakan pertama).Elemen
done-flagkosong menunjukkan bahwa ketika Oozie memeriksa keberadaan data input pada waktu yang ditentukan, Oozie menentukan data apakah tersedia dengan kehadiran direktori atau file. Dalam hal ini, data tersedia dengan kehadiran file csv. Jika file csv ada, Oozie menganggap data sudah siap dan meluncurkan contoh alur kerja untuk memproses file. Jika tidak ada file csv yang tersedia, Oozie menganggap data belum siap dan jalannya alur kerja masuk ke status tunggu.Poin 3: Elemen
data-inmenentukan tanda waktu tertentu untuk digunakan sebagai waktu nominal saat mengganti nilai diuri-templateuntuk set data terkait.<data-in name="event_input1" dataset="ds_input1"> <instance>${coord:current(0)}</instance> </data-in>Jika demikian, atur instans ke ekspresi
${coord:current(0)}, yang menerjemahkan penggunaan waktu nominal tindakan seperti yang dijadwalkan sesungguhnya oleh koordinator. Dengan kata lain, ketika koordinator menjadwalkan aksi untuk berjalan dengan waktu nominal 01/01/2017, maka 01/01/2017 inilah yang digunakan untuk mengganti variabel TAHUN (2017) dan BULAN (01) dalam template URI. Setelah template URI dihitung untuk instans ini, Oozie memeriksa apakah direktori atau file yang diharapkan menjadi tersedia dan menjadwalkan jalannya alur kerja berikutnya karenanya.
Tiga poin sebelumnya digabungkan untuk menghasilkan situasi di mana koordinator menjadwalkan pemrosesan data sumber dalam hari-per-hari.
Poin 1: Koordinator dimulai dengan tanggal nominal 2017-01-01.
Poin 2: Oozie mencari data yang tersedia di
sourceDataFolder/2017-01-FlightData.csv.Poin 3: Ketika Oozie menemukan file tersebut, Oozie menjadwalkan instans alur kerja yang akan memproses data untuk 1 Januari 2017. Oozie kemudian melanjutkan proses untuk 2017-01-02. Evaluasi ini berulang hingga tetapi tidak termasuk 2017-01-05.
Seperti halnya alur kerja, konfigurasi koordinator ditentukan dalam file job.properties, yang memiliki superset pengaturan yang digunakan oleh alur kerja.
nameNode=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net
jobTracker=[ACTIVERESOURCEMANAGER]:8050
queueName=default
oozie.use.system.libpath=true
appBase=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie
oozie.coord.application.path=${appBase}
sourceDataFolder=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/
hiveScriptLoadPartition=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-load-flights-partition.hql
hiveScriptCreateDailyTable=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/oozie/load_flights_by_day/hive-create-daily-summary-table.hql
hiveDailyTableNamePrefix=dailyflights
hiveDataFolderPrefix=wasbs://[CONTAINERNAME]@[ACCOUNTNAME].blob.core.windows.net/example/data/flights/day/
sqlDatabaseConnectionString="jdbc:sqlserver://[SERVERNAME].database.windows.net;user=[USERNAME];password=[PASSWORD];database=[DATABASENAME]"
sqlDatabaseTableName=dailyflights
Satu-satunya properti baru yang diperkenalkan dalam file job.properties ini adalah:
| Properti | Sumber nilai |
|---|---|
| oozie.coord.application.path | Menunjukkan lokasi file coordinator.xml yang berisi koordinator Oozie yang dijalankan. |
| hiveDailyTableNamePrefix | Prefiks yang digunakan saat secara dinamis membuat nama tabel dari tabel berjenjang. |
| hiveDataFolderPrefix | Prefiks jalur di mana semua tabel berjenjang akan disimpan. |
Menyebarkan dan menjalankan Oozie Coordinator
Untuk menjalankan alur dengan koordinator, proses dengan cara yang sama seperti untuk alur kerja, kecuali Anda bekerja dari folder yang berada satu tingkat di atas folder yang berisi alur kerja Anda. Konvensi folder ini memisahkan koordinator dari alur kerja di disk, sehingga Anda dapat mengaitkan satu koordinator dengan alur kerja anak yang berbeda.
Gunakan SCP dari komputer lokal Anda untuk menyalin file koordinator ke penyimpanan lokal headnode kluster Anda.
scp ./* sshuser@CLUSTERNAME-ssh.azurehdinsight.net:~SSH ke dalam headnode Anda.
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netSalin file koordinator ke HDFS.
hdfs dfs -put ./* /oozie/Jalankan koordinator.
oozie job -config job.properties -runPastikan status menggunakan Oozie Web Console, kali ini dengan memilih tab Pekerjaan Koordinator, lalu Semua pekerjaan.
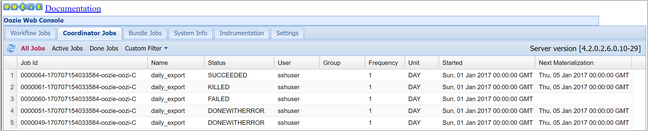
Pilih instans koordinator untuk menampilkan daftar tindakan terjadwal. Dalam hal ini, Anda akan melihat empat tindakan dengan waktu nominal dalam rentang 1 Januari 2017 hingga 4 Januari 2017.
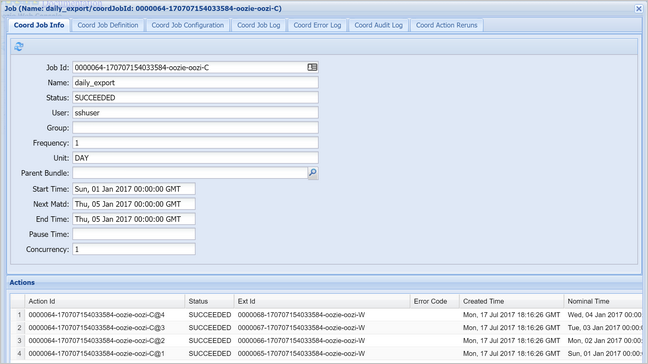
Setiap tindakan dalam daftar ini sesuai dengan instans alur kerja yang memproses data senilai satu hari, di mana awal hari itu ditunjukkan oleh waktu nominal.