Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menunjukkan cara mengembangkan aplikasi Apache Spark di Azure HDInsight menggunakan plug-in Azure Toolkit untuk IntelliJ IDE. Azure HDInsight adalah layanan analitik sumber terbuka terkelola di cloud. Layanan ini memungkinkan Anda menggunakan kerangka kerja sumber terbuka seperti Hadoop, Apache Spark, Apache Hive, dan Apache Kafka.
Anda dapat menggunakan plug-in Azure Toolkit dengan beberapa cara:
- Mengembangkan dan mengirimkan aplikasi Scala Spark ke kluster HDInsight Spark.
- Akses sumber daya kluster Azure HDInsight Spark Anda.
- Mengembangkan dan menjalankan aplikasi Scala Spark secara lokal.
Dalam artikel ini, Anda akan mempelajari cara:
- Penggunaan Toolkit Azure untuk plugin IntelliJ
- Kembangkan aplikasi Apache Spark
- Mengirimkan aplikasi ke kluster Azure HDInsight
Prasyarat
Klaster Apache Spark pada HDInsight. Untuk petunjuk selengkapnya, lihat Membuat kluster Apache Spark di Microsoft Azure HDInsight. Hanya kluster HDInsight di cloud publik yang didukung sementara jenis cloud aman lainnya (misalnya cloud pemerintah) tidak.
Kit Pengembangan Oracle Java. Artikel ini menggunakan Java versi 8.0.202.
IntelliJ IDEA. Artikel ini menggunakan IntelliJ IDEA Community 2018.3.4.
Azure Toolkit untuk IntelliJ. Lihat Menginstal Azure Toolkit untuk IntelliJ.
Menginstal plugin Scala untuk IntelliJ IDEA
Langkah-langkah untuk menginstal plugin Scala:
Buka IntelliJ IDEA.
Pada layar selamat datang, navigasikan ke Konfigurasi>Plugin untuk membuka jendela Plugin .
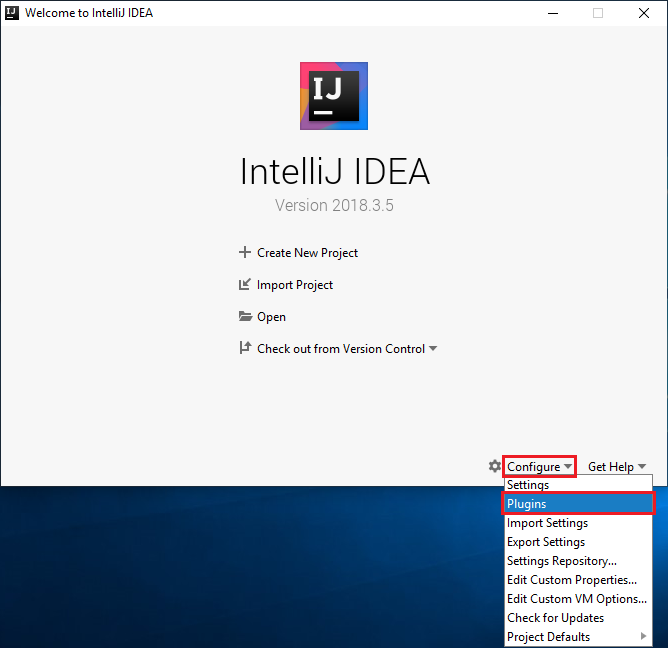
Pilih Instal untuk plugin Scala yang ditampilkan di jendela baru.
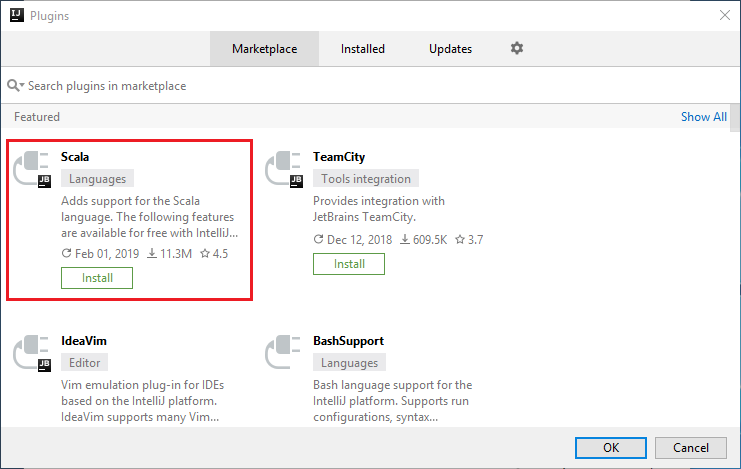
Setelah plugin berhasil diinstal, Anda harus menghidupkan ulang IDE.
Membuat aplikasi Spark Scala untuk kluster HDInsight Spark
Buka IntelliJ IDEA, dan pilih Buat Proyek Baru untuk membuka jendela Proyek Baru.
Pilih Apache Spark/Microsoft Azure HDInsight dari panel sisi kiri.
Pilih Proyek Spark (Scala) dari jendela utama.
Dari menu tarik-turun Alat build, pilih salah satu opsi berikut:
Maven untuk dukungan wizard pembuatan proyek Scala.
SBT untuk mengelola dependensi dan pembangunan proyek Scala.
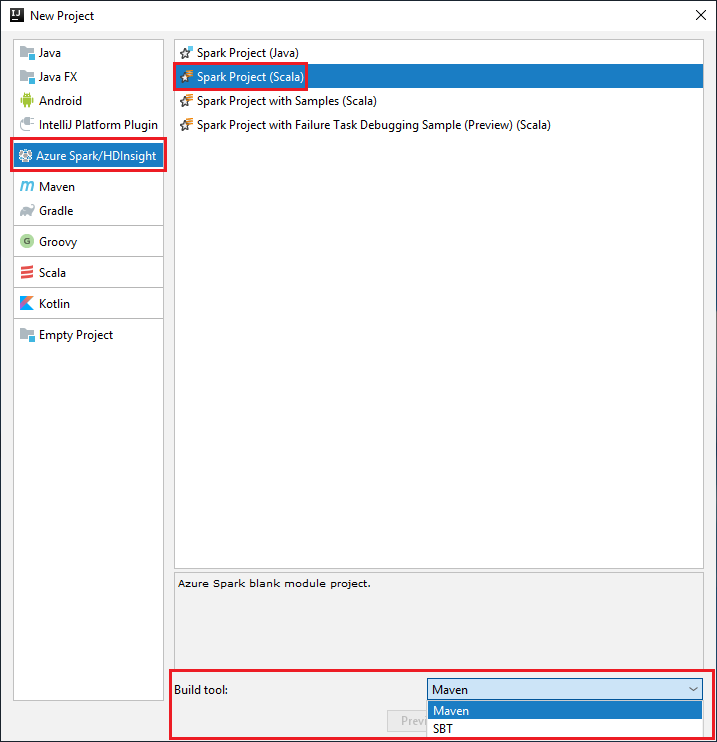
Pilih Selanjutnya.
Di jendela Proyek Baru, berikan informasi berikut ini:
Harta benda Deskripsi Nama proyek Masukkan nama. Artikel ini menggunakan myApp.Lokasi proyek Masukkan lokasi untuk menyimpan proyek Anda. SDK Proyek Bidang ini mungkin kosong pada penggunaan IDEA pertama Anda. Pilih Baru... dan navigasi ke JDK Anda. Versi Spark Wizard pembuatan mengintegrasikan versi yang tepat untuk SDK Spark dan SDK Scala. Jika versi kluster Spark lebih lama dari 2.0, pilih Spark 1.x. Jika tidak, pilih Spark2.x. Contoh ini menggunakan Spark 2.3.0 (Scala 2.11.8). 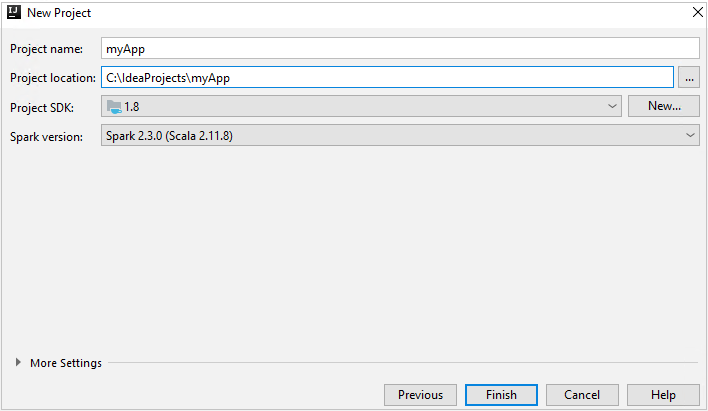
Pilih Selesai. Mungkin perlu waktu beberapa menit sebelum proyek tersedia.
Proyek Spark secara otomatis membuat artefak untuk Anda. Untuk melihat artefak, lakukan langkah-langkah berikut:
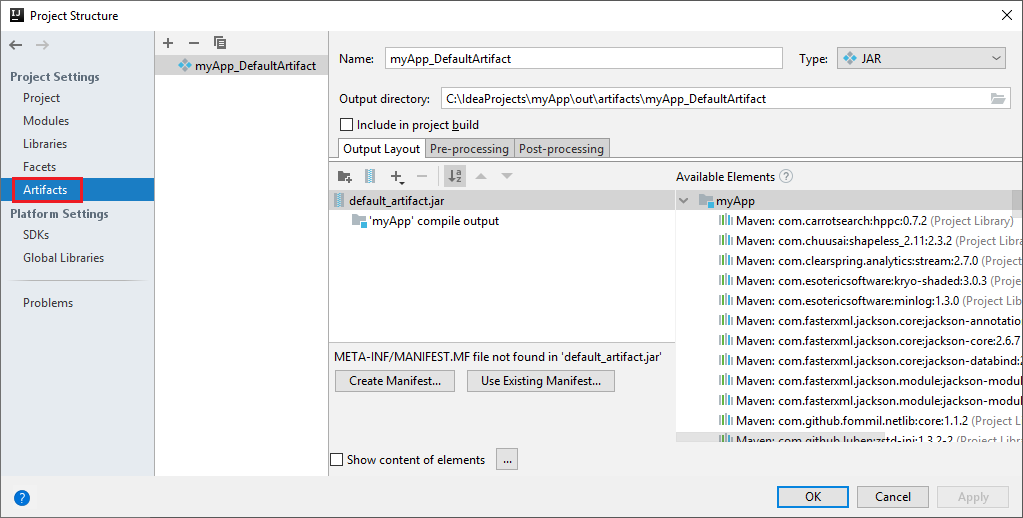
a. Dari bilah menu, navigasikan ke File>Struktur Proyek....
b. Dari jendela Struktur Proyek, pilih Artefak.
c. Pilih Batal setelah melihat artefak.
Tambahkan kode sumber aplikasi Anda dengan melakukan langkah-langkah berikut:
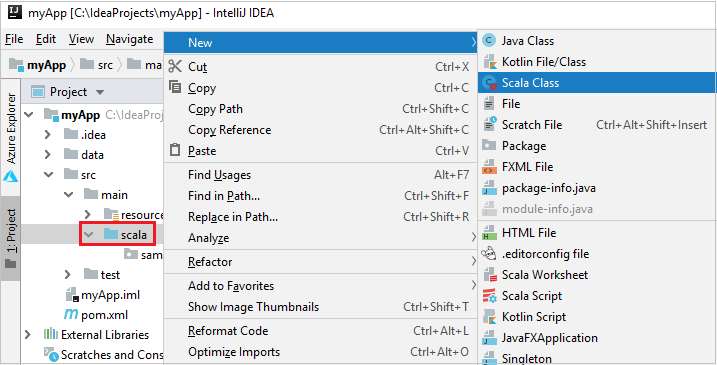
a. Dari Project, navigasikan ke myApp>src>main>scala.
b. Klik kanan scala, lalu navigasikan ke Baru>Kelas Scala.
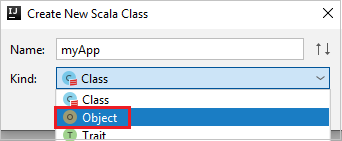
c. Dalam kotak dialog Buat Kelas Scala Baru , berikan nama, pilih Objek di daftar drop-down Jenis , lalu pilih OK.
d. File myApp.scala kemudian terbuka di tampilan utama. Ganti kode default dengan kode yang ditemukan di bawah ini:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }Kode membaca data dari HVAC.csv (tersedia di semua kluster HDInsight Spark), mengambil baris yang hanya memiliki satu digit di kolom ketujuh dalam file CSV, dan menulis output ke
/HVACOutdi bawah kontainer penyimpanan default untuk kluster.
Menyambungkan ke kluster HDInsight Anda
Pengguna dapat masuk ke langganan Azure Anda, atau menautkan kluster HDInsight. Gunakan nama pengguna/kata sandi Ambari atau kredensial yang terhubung dengan domain untuk menyambungkan ke kluster HDInsight Anda.
Masuk ke langganan Azure Anda
Dari bilah menu, navigasi ke Tampilkan>Alat WindowsAzure >Explorer.
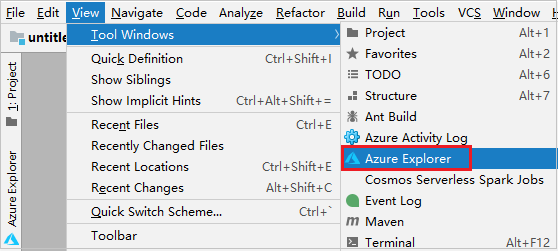
Dari Explorer Azure, klik kanan simpul Azure, lalu pilih Masuk.
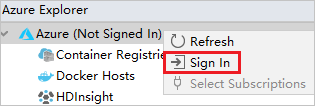
Dalam kotak dialog Masuk Azure, pilih Masuk Perangkat, lalu pilih Masuk.
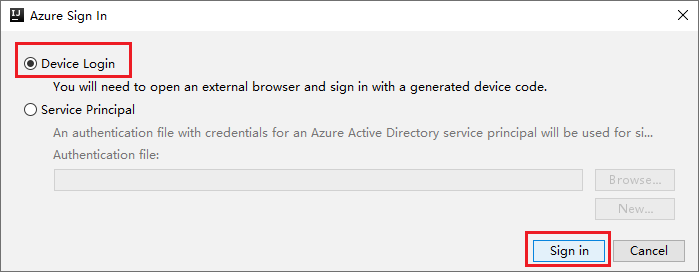
Dalam kotak dialog Masuk Perangkat Azure , klik Salin&Buka.
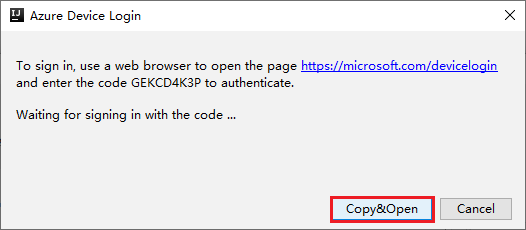
Di antarmuka browser, tempelkan kode, lalu klik Berikutnya.
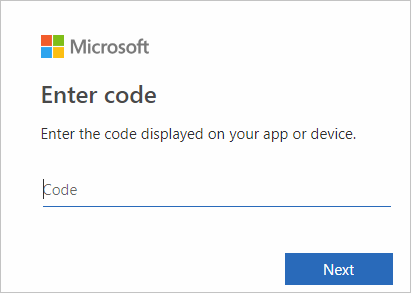
Masukkan kredensial Azure Anda, lalu tutup browser.
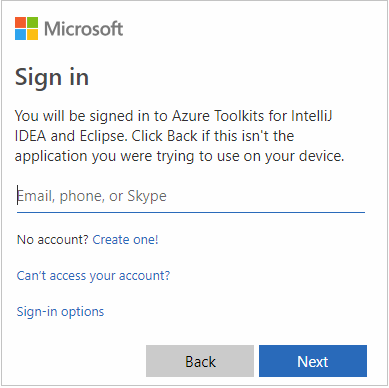
Setelah Anda masuk, kotak dialog Pilih Langganan mencantumkan semua langganan Azure yang terkait dengan kredensial. Pilih langganan Anda lalu pilih tombol Pilih .
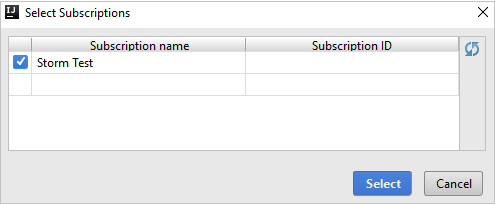
Dari Azure Explorer, perluas HDInsight untuk melihat kluster HDInsight Spark yang ada di langganan Anda.
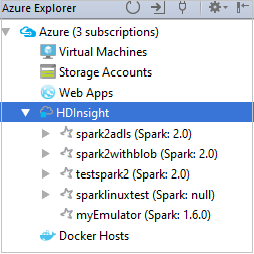
Untuk melihat sumber daya (misalnya, akun penyimpanan) yang terkait dengan kluster, Anda dapat memperluas node nama kluster lebih lanjut.
Tautkan kluster
Anda dapat menautkan kluster HDInsight dengan menggunakan nama pengguna terkelola Apache Ambari. Demikian pula, untuk kluster HDInsight yang bergabung dengan domain, Anda dapat menautkan dengan menggunakan domain dan nama pengguna, seperti user1@contoso.com. Anda juga dapat menautkan kluster Livy Service.
Dari bilah menu, navigasi ke Tampilkan>Alat WindowsAzure >Explorer.
Dari Azure Explorer, klik kanan simpul HDInsight , lalu pilih Tautkan Kluster A.
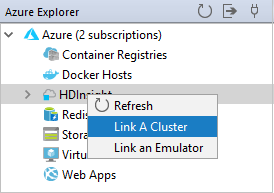
Opsi yang tersedia di jendela Tautkan Kluster dapat bervariasi tergantung pada nilai yang Anda pilih dari daftar drop-down Jenis Sumber Daya Tautan. Masukkan nilai Anda lalu pilih OK.
Kluster HDInsight
Harta benda Nilai Jenis Sumber Daya Tautan Pilih Kluster HDInsight dari daftar drop-down. Kluster Nama/URL Masukkan nama kluster. Jenis Autentikasi Biarkan sebagai Autentikasi Dasar Nama Pengguna Masukkan nama pengguna kluster, defaultnya adalah admin. Kata sandi Masukkan kata sandi untuk nama pengguna. 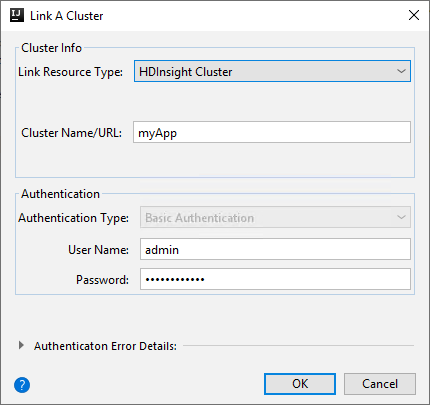
Layanan Livy
Harta benda Nilai Jenis Sumber Daya Tautan Pilih Livy Service dari daftar drop-down. Titik Akhir Livy Masukkan Titik Akhir Livy Nama Kluster Masukkan nama kluster. Titik Akhir Yarn Fakultatif. Jenis Autentikasi Biarkan sebagai Autentikasi Dasar Nama Pengguna Masukkan nama pengguna kluster, defaultnya adalah admin. Kata sandi Masukkan kata sandi untuk nama pengguna. 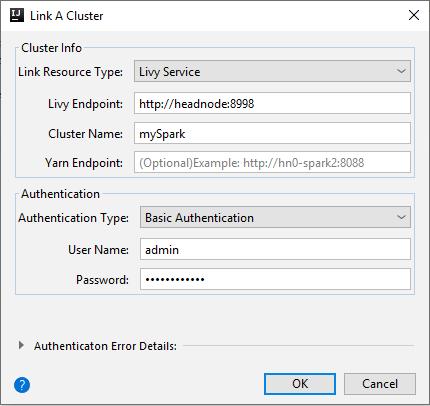
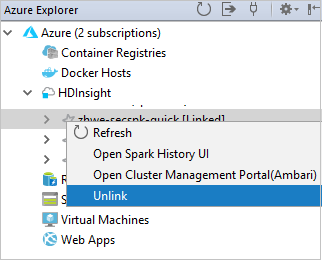
Anda dapat melihat kluster yang ditautkan dari simpul HDInsight .
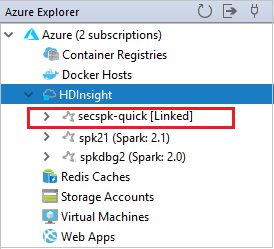
Anda juga dapat membatalkan kaitan kluster dari Azure Explorer.
Menjalankan aplikasi Spark Scala pada kluster HDInsight Spark
Setelah membuat aplikasi Scala, Anda dapat mengirimkannya ke kluster.
Dari Proyek, navigasikan ke myApp>src>main>scala>myApp. Klik kanan myApp, dan pilih Kirim Aplikasi Spark (Kemungkinan akan terletak di bagian bawah daftar).
Di jendela dialog Kirim Aplikasi Spark , pilih 1. Spark di HDInsight.
Di jendela Edit konfigurasi , berikan nilai berikut lalu pilih OK:
Harta benda Nilai Kluster Spark (khusus Linux) Pilih kluster HDInsight Spark tempat Anda ingin menjalankan aplikasi Anda. Pilih Artefak untuk dikirim Biarkan pengaturan bawaan. Nama kelas utama Nilai default adalah kelas utama dari file yang dipilih. Anda dapat mengubah kelas dengan memilih elipsis(...) dan memilih kelas lain. Konfigurasi pekerjaan Anda dapat mengubah kunci default dan, atau nilai. Untuk mengetahui informasi selengkapnya, lihat REST API Apache Livy. Argumen baris perintah Anda dapat memasukkan argumen yang dipisahkan oleh spasi untuk kelas utama jika diperlukan. Jars yang Direferensikan dan File yang Direferensikan Anda dapat memasukkan jalur-jalur untuk Jar dan file yang direferensikan jika ada. Anda juga dapat menelusuri file di sistem file virtual Azure, yang saat ini hanya mendukung kluster ADLS Gen 2. Untuk informasi selengkapnya: Konfigurasi Apache Spark. Lihat juga, Cara mengunggah sumber daya ke kluster. Penyimpanan Pengunggahan Pekerjaan Luaskan untuk menampilkan opsi tambahan. Jenis Penyimpanan Pilih Gunakan Azure Blob untuk mengunggah dari daftar drop-down. Akun Penyimpanan Masukkan akun penyimpanan Anda. Kunci Penyimpanan Masukkan kunci penyimpanan Anda. Wadah Penyimpanan Pilih kontainer penyimpanan Anda dari daftar menurun setelah Akun Penyimpanan dan Kunci Penyimpanan dimasukkan. 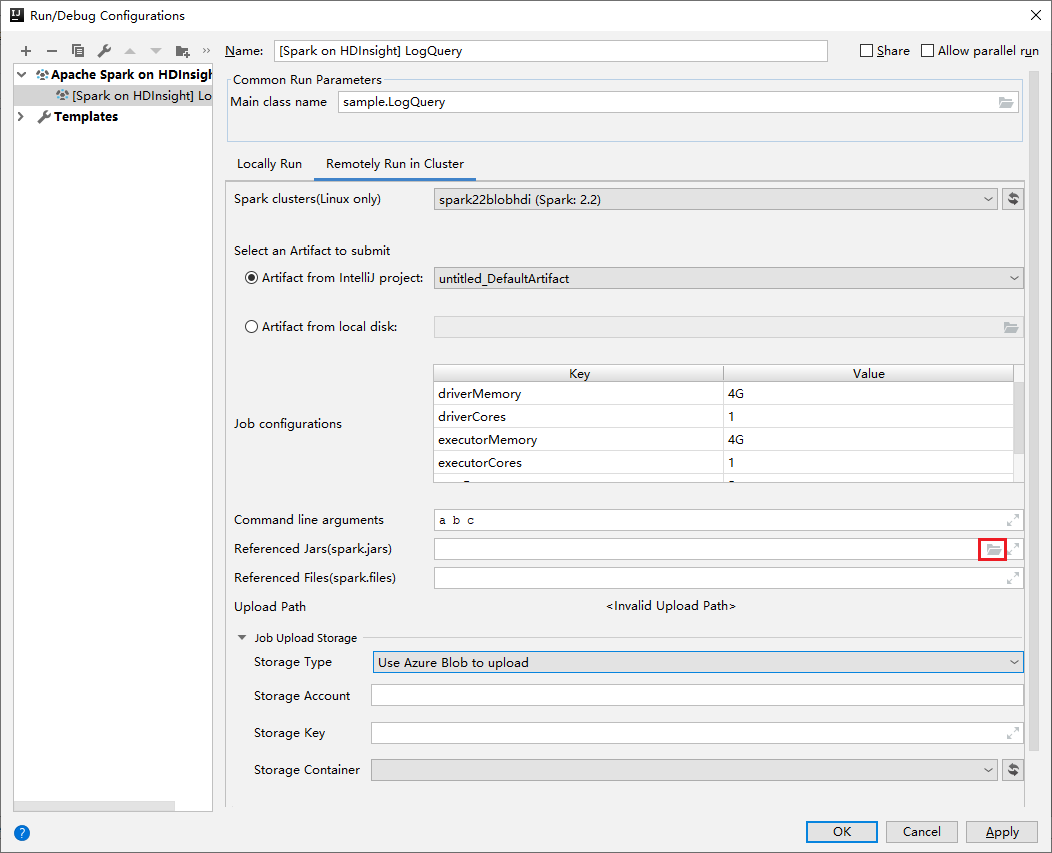
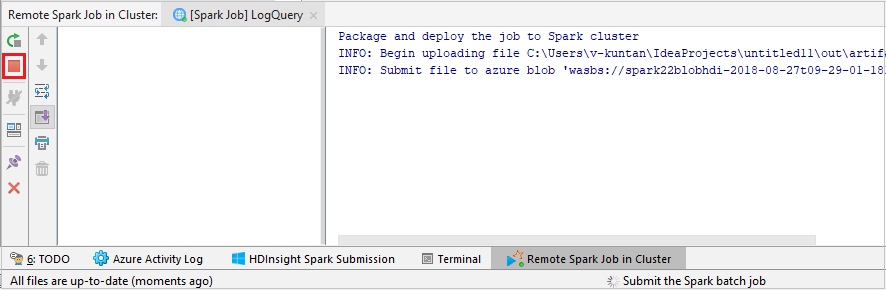
Pilih SparkJobRun untuk mengirimkan proyek Anda ke kluster yang dipilih. Tab Pekerjaan Spark Jarak Jauh di Kluster menampilkan progres pelaksanaan pekerjaan di bagian bawah. Anda dapat menghentikan aplikasi dengan mengklik tombol merah.
Men-debug aplikasi Apache Spark secara lokal atau jarak jauh pada kluster HDInsight
Kami juga merekomendasikan cara lain untuk mengirimkan aplikasi Spark ke kluster. Anda dapat melakukannya dengan mengatur parameter di IDE konfigurasi Run/Debug . Lihat Debug aplikasi Apache Spark secara lokal atau jarak jauh pada kluster HDInsight dengan Azure Toolkit untuk IntelliJ melalui SSH.
Mengakses dan mengelola kluster HDInsight Spark dengan menggunakan Azure Toolkit untuk IntelliJ
Anda dapat melakukan berbagai operasi dengan menggunakan Azure Toolkit untuk IntelliJ. Sebagian besar operasi dimulai dari Azure Explorer. Dari bilah menu, navigasi ke Tampilkan>Alat WindowsAzure >Explorer.
Mengakses tampilan pekerjaan
Dari Azure Explorer, navigasikan ke HDInsight><Kluster>Anda>Pekerjaan.
Di panel kanan, tab Tampilan Pekerjaan Spark menampilkan semua aplikasi yang dijalankan pada kluster. Pilih nama aplikasi yang ingin Anda lihat detail selengkapnya.
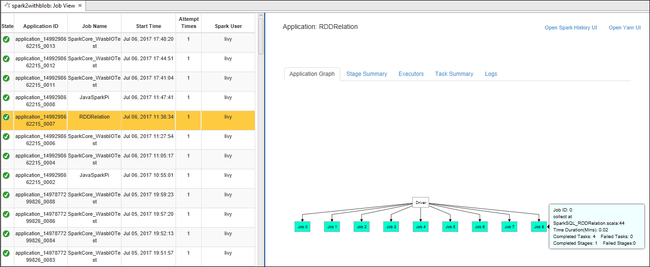
Untuk menampilkan informasi pekerjaan dasar yang sedang berjalan, arahkan mouse ke atas grafik pekerjaan. Untuk melihat grafik tahapan dan informasi yang dihasilkan setiap pekerjaan, pilih simpul pada grafik pekerjaan.
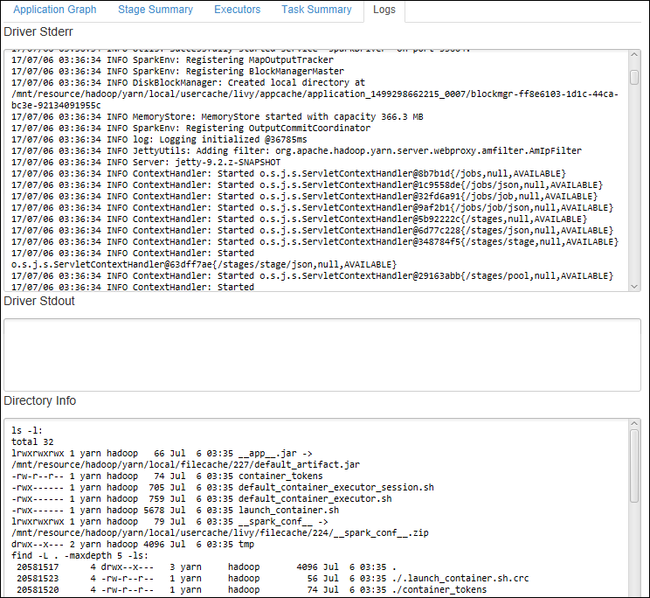
Untuk melihat log yang sering digunakan, seperti Driver Stderr, Driver Stdout, dan Info Direktori, pilih tab Log .
Anda dapat melihat antarmuka pengguna riwayat Spark dan UI YARN (di tingkat aplikasi). Pilih tautan di bagian atas jendela.
Mengakses server riwayat Spark
Dari Azure Explorer, perluas HDInsight, klik kanan nama kluster Spark Anda, lalu pilih Buka UI Riwayat Spark.
Saat diminta, masukkan kredensial admin kluster, yang Anda tentukan saat menyiapkan kluster.
Di dasbor server riwayat Spark, Anda dapat menggunakan nama aplikasi untuk mencari aplikasi yang baru saja Anda selesai jalankan. Dalam kode sebelumnya, Anda mengatur nama aplikasi dengan menggunakan
val conf = new SparkConf().setAppName("myApp"). Nama aplikasi Spark Anda adalah myApp.
Memulai portal Ambari
Dari Azure Explorer, perluas HDInsight, klik kanan nama kluster Spark Anda, lalu pilih Buka Portal Manajemen Kluster (Ambari).
Saat diminta, masukkan kredensial admin untuk kluster. Anda menentukan kredensial ini selama proses penyiapan kluster.
Mengelola langganan Azure
Secara default, Azure Toolkit untuk IntelliJ mencantumkan kluster Spark dari semua langganan Azure Anda. Jika perlu, Anda dapat menentukan langganan yang ingin Anda akses.
Dari Azure Explorer, klik kanan simpul akar Azure , lalu pilih Pilih Langganan.
Dari jendela Pilih Langganan , kosongkan kotak centang di samping langganan yang tidak ingin Anda akses, lalu pilih Tutup.
Konsol Spark
Anda dapat menjalankan Spark Local Console(Scala) atau menjalankan Spark Livy Interactive Session Console(Scala).
Konsol Lokal Spark (Scala)
Pastikan Anda telah memenuhi prasyarat WINUTILS.EXE.
Dari bilah menu, navigasikan ke Jalankan>Edit Konfigurasi....
Dari jendela Konfigurasi Jalankan/Debug , di panel kiri, navigasikan ke Apache Spark di HDInsight>[Spark on HDInsight] myApp.
Dari jendela utama, pilih tab
Locally Run.Berikan nilai berikut, lalu pilih OK:
Harta benda Nilai Kelas utama pekerjaan Nilai default adalah kelas utama dari file yang dipilih. Anda dapat mengubah kelas dengan memilih elipsis(...) dan memilih kelas lain. Variabel lingkungan Pastikan nilai untuk HADOOP_HOME sudah benar. Lokasi WINUTILS.exe Pastikan jalurnya benar. 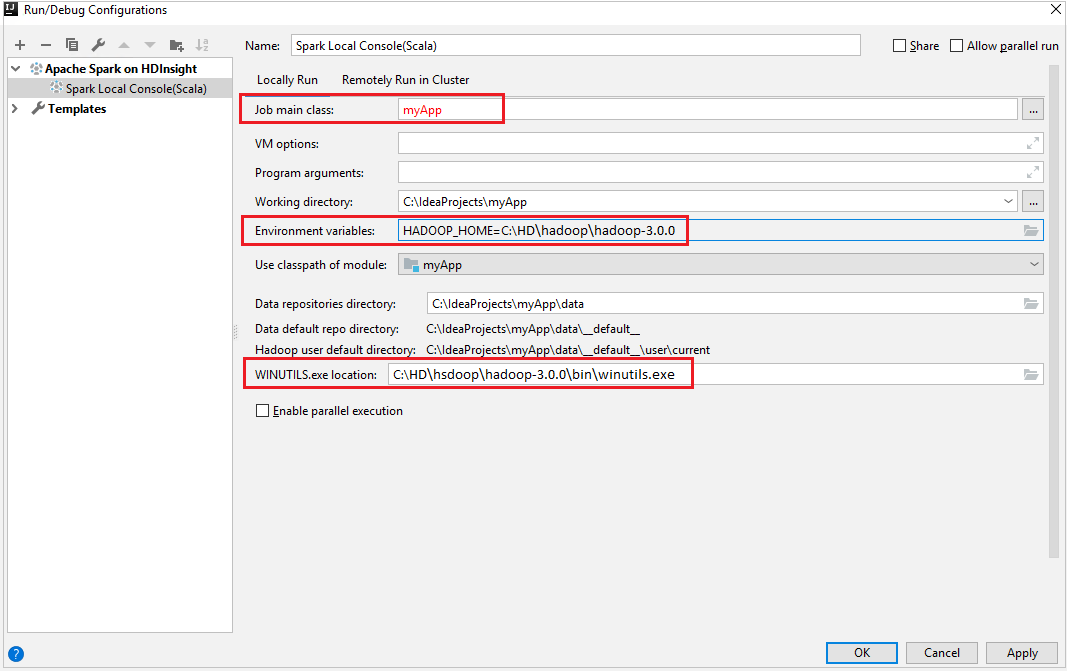
Dari Proyek, navigasikan ke myApp>src>main>scala>myApp.
Dari bilah menu, buka Alat>Konsol Spark>Jalankan Konsol Lokal Spark (Scala).
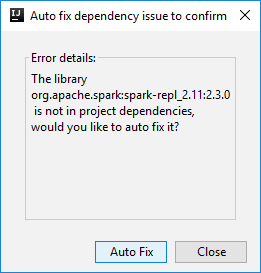
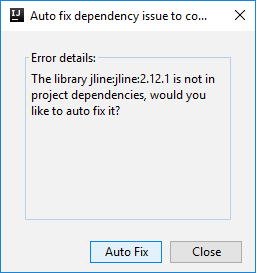
Kemudian dua dialog dapat ditampilkan untuk menanyakan apakah Anda ingin memperbaiki dependensi secara otomatis. Jika demikian, pilih Perbaiki Otomatis.
Konsol harus terlihat mirip dengan gambar di bawah ini. Di jendela konsol, ketik
sc.appName, lalu tekan Ctrl+Enter. Hasilnya akan ditampilkan. Anda dapat mengakhiri konsol lokal dengan mengklik tombol merah.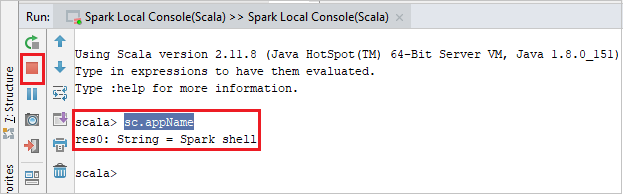
Konsol Sesi Interaktif Spark Livy (Scala)
Dari bilah menu, navigasikan ke Jalankan>Edit Konfigurasi....
Dari jendela Konfigurasi Jalankan/Debug , di panel kiri, navigasikan ke Apache Spark di HDInsight>[Spark on HDInsight] myApp.
Dari jendela utama, pilih tab
Remotely Run in Cluster.Berikan nilai berikut, lalu pilih OK:
Harta benda Nilai Kluster Spark (khusus Linux) Pilih kluster HDInsight Spark tempat Anda ingin menjalankan aplikasi Anda. Nama kelas utama Nilai default adalah kelas utama dari file yang dipilih. Anda dapat mengubah kelas dengan memilih elipsis(...) dan memilih kelas lain. 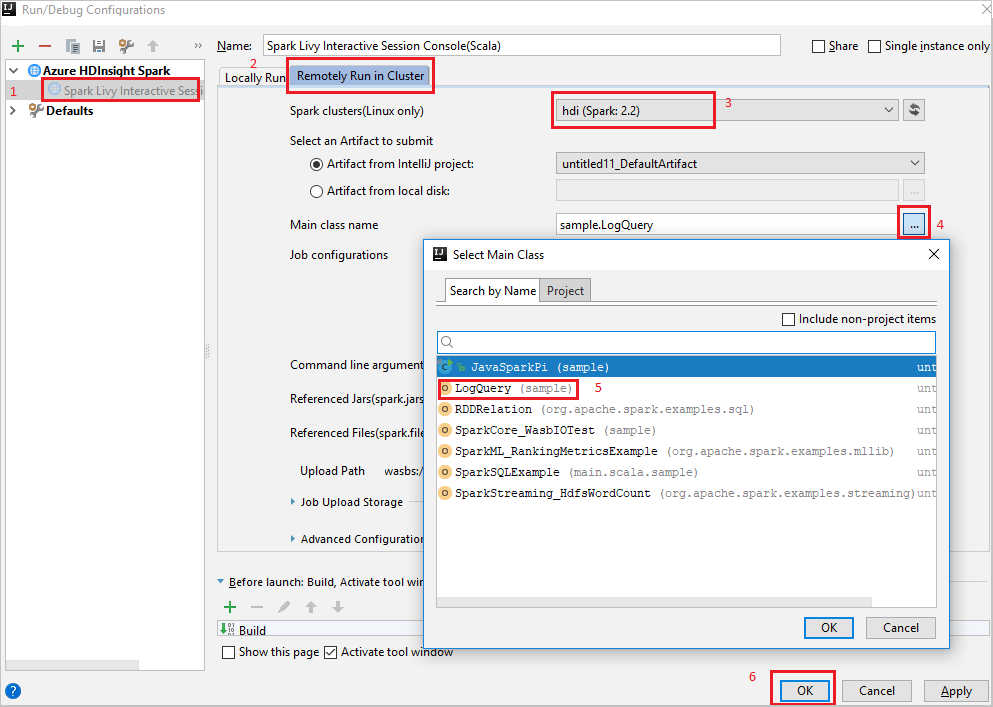
Dari Proyek, navigasikan ke myApp>src>main>scala>myApp.
Dari bilah menu, navigasikan ke Alat>Spark Console>Jalankan Spark Livy Interactive Session Console (Scala).
Konsol harus terlihat mirip dengan gambar di bawah ini. Di jendela konsol, ketik
sc.appName, lalu tekan Ctrl+Enter. Hasilnya akan ditampilkan. Anda dapat mengakhiri konsol lokal dengan mengklik tombol merah.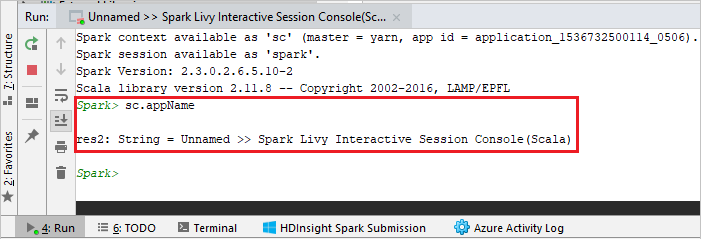
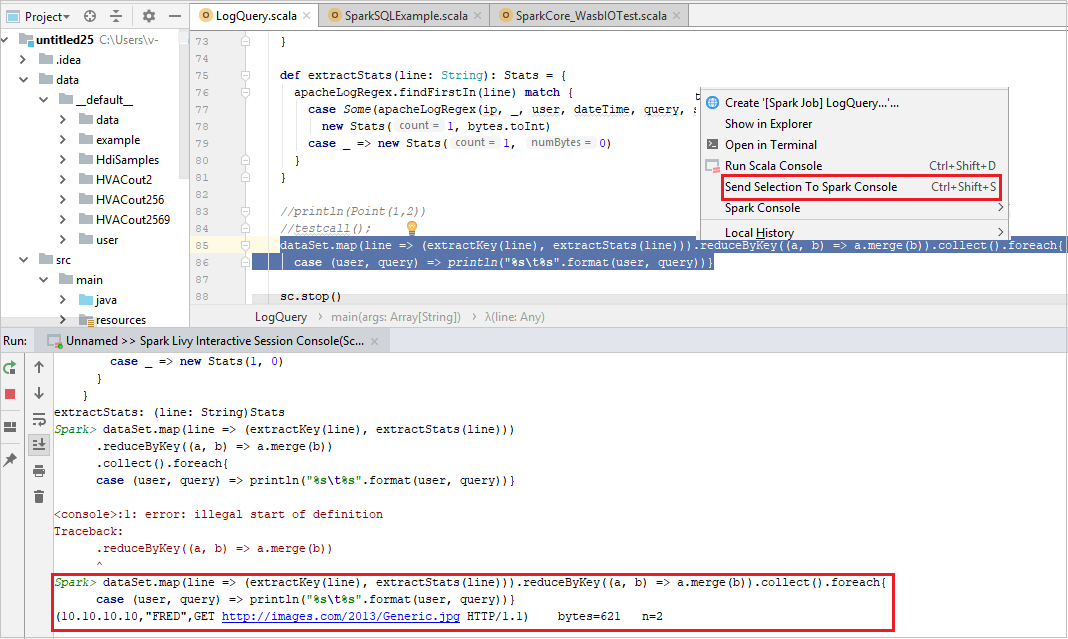
Kirim Pilihan ke Konsol Spark
Lebih mudah bagi Anda untuk memperkirakan hasil skrip dengan mengirim beberapa kode ke konsol lokal atau Livy Interactive Session Console (Scala). Anda dapat menyoroti beberapa kode dalam file Scala, lalu klik kanan Kirim Pilihan Ke Konsol Spark. Kode yang dipilih akan dikirim ke konsol. Hasilnya akan ditampilkan setelah kode di konsol. Konsol akan memeriksa kesalahan jika ada.
Integrasikan dengan Perantara Identitas Microsoft Azure HDInsight (HIB)
Sambungkan ke kluster HDInsight ESP Anda dengan Perantara ID (HIB)
Anda dapat mengikuti langkah-langkah umum untuk masuk ke langganan Azure Anda untuk menyambungkan ke kluster HDInsight ESP Anda dengan Perantara ID (HIB). Setelah masuk, Anda akan melihat daftar kluster di Azure Explorer. Untuk petunjuk selengkapnya, lihat Sambungkan ke kluster Microsoft Azure HDInsight Anda.
Menjalankan aplikasi Spark Scala pada kluster HDInsight ESP dengan ID Broker (HIB)
Anda dapat mengikuti langkah-langkah normal untuk mengirimkan pekerjaan ke kluster HDInsight ESP dengan ID Broker (HIB). Lihat Menjalankan aplikasi Spark Scala pada kluster HDInsight Spark untuk instruksi selengkapnya.
Kami mengunggah file yang diperlukan ke folder bernama dengan akun masuk Anda, dan Anda dapat melihat jalur unggahan dalam file konfigurasi.

Konsol Spark pada kluster HDInsight ESP dengan ID Broker (HIB)
Anda dapat menjalankan Spark Local Console (Scala) atau menjalankan Spark Livy Interactive Session Console (Scala) pada kluster HDInsight ESP dengan ID Broker (HIB). Lihat Konsol Spark untuk petunjuk selengkapnya.
Nota
Untuk kluster HDInsight ESP dengan Id Broker (HIB), tautan kluster dan debug aplikasi Apache Spark dari jarak jauh tidak didukung saat ini.
Peran khusus pembaca
Saat pengguna mengirimkan pekerjaan ke kluster dengan izin peran khusus pembaca, kredensial Ambari diperlukan.
Tautkan kluster dari menu konteks
Masuk dengan akun peran khusus pembaca.
Dari Azure Explorer, perluas HDInsight untuk melihat kluster HDInsight yang ada di langganan Anda. Kluster yang ditandai "Role:Reader" hanya memiliki izin peran khusus pembaca.
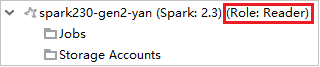
Klik kanan kluster dengan izin peran khusus pembaca. Pilih Tautkan kluster ini dari menu konteks untuk menautkan kluster. Masukkan nama pengguna dan Kata Sandi Ambari.
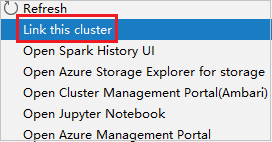
Jika kluster berhasil ditautkan, HDInsight akan di-refresh. Tahap kluster akan dihubungkan.
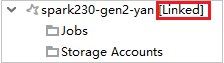
Menghubungkan klaster dengan memperluas node Pekerjaan
Klik Simpul Pekerjaan , jendela Akses Pekerjaan Kluster Ditolak muncul.
Klik Tautkan kluster ini untuk menautkan kluster.

Menghubungkan kluster dari jendela Konfigurasi Run/Debug
Buat Konfigurasi HDInsight. Kemudian pilih Jalankan Secara Jarak Jauh di dalam Kluster.
Pilih kluster, yang memiliki izin peran khusus pembaca untuk kluster Spark (khusus Linux). Pesan peringatan muncul. Anda dapat Mengklik Tautkan kluster ini untuk menautkan kluster.
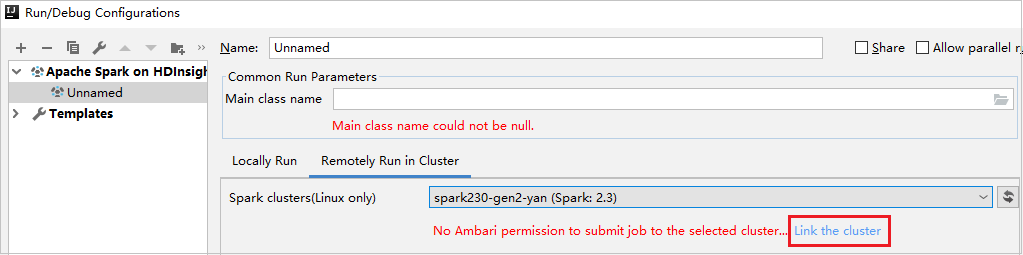
Lihat Akun Penyimpanan
Untuk kluster dengan izin peran khusus pembaca, klik simpul Akun Penyimpanan , jendela Akses Penyimpanan Ditolak muncul. Anda dapat mengklik Buka Azure Storage Explorer untuk membuka Storage Explorer.
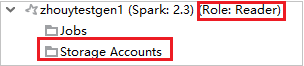

Untuk kluster tertaut, klik simpul Akun Penyimpanan , jendela Akses Penyimpanan Ditolak muncul. Anda dapat mengklik Buka Azure Storage untuk membuka Storage Explorer.

Mengonversi aplikasi IntelliJ IDEA yang ada untuk menggunakan Azure Toolkit untuk IntelliJ
Anda dapat mengonversi aplikasi Spark Scala yang ada yang Anda buat di IntelliJ IDEA agar kompatibel dengan Azure Toolkit untuk IntelliJ. Anda kemudian dapat menggunakan plug-in untuk mengirimkan aplikasi ke kluster HDInsight Spark.
Untuk aplikasi Spark Scala yang ada yang dibuat melalui IntelliJ IDEA, buka file terkait
.iml.Pada tingkat akar, adalah elemen modul seperti teks berikut:
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">Edit elemen untuk ditambahkan
UniqueKey="HDInsightTool"sehingga elemen modul terlihat seperti teks berikut:<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">Simpan perubahan. Aplikasi Anda sekarang harus kompatibel dengan Azure Toolkit untuk IntelliJ. Anda dapat mengujinya dengan mengklik kanan nama proyek di Project. Menu pop-up sekarang memiliki opsi Kirim Aplikasi Spark ke HDInsight.
Membersihkan sumber daya
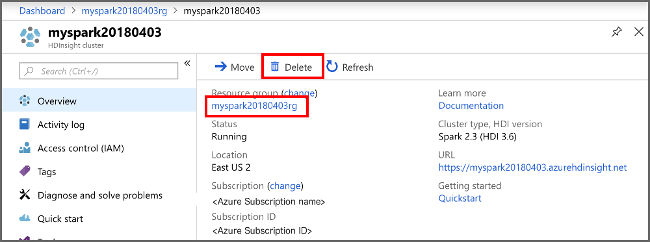
Jika Anda tidak akan terus menggunakan aplikasi ini, hapus kluster yang Anda buat dengan langkah-langkah berikut:
Masuk ke portal Azure.
Dalam kotak Pencarian di bagian atas, ketik Microsoft Azure HDInsight.
Pilih kluster Microsoft Azure HDInsight di Layanan.
Dalam daftar kluster HDInsight yang muncul, pilih ... di samping kluster yang Anda buat untuk artikel ini.
Pilih Hapus. Pilih Ya.
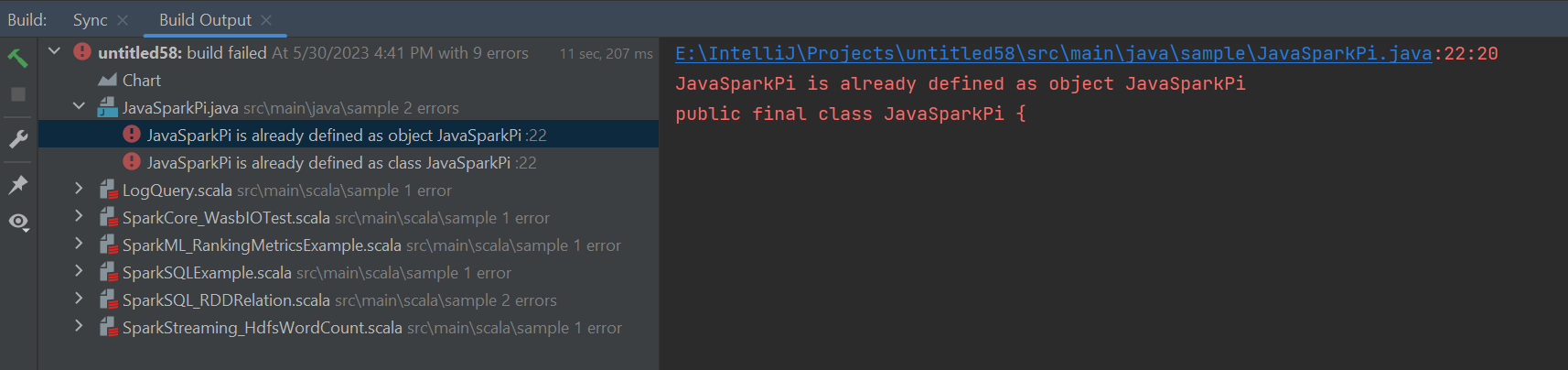
Kesalahan dan solusi
Batalkan tanda folder src sebagai Sumber jika Anda mendapatkan kesalahan build yang gagal seperti di bawah ini:
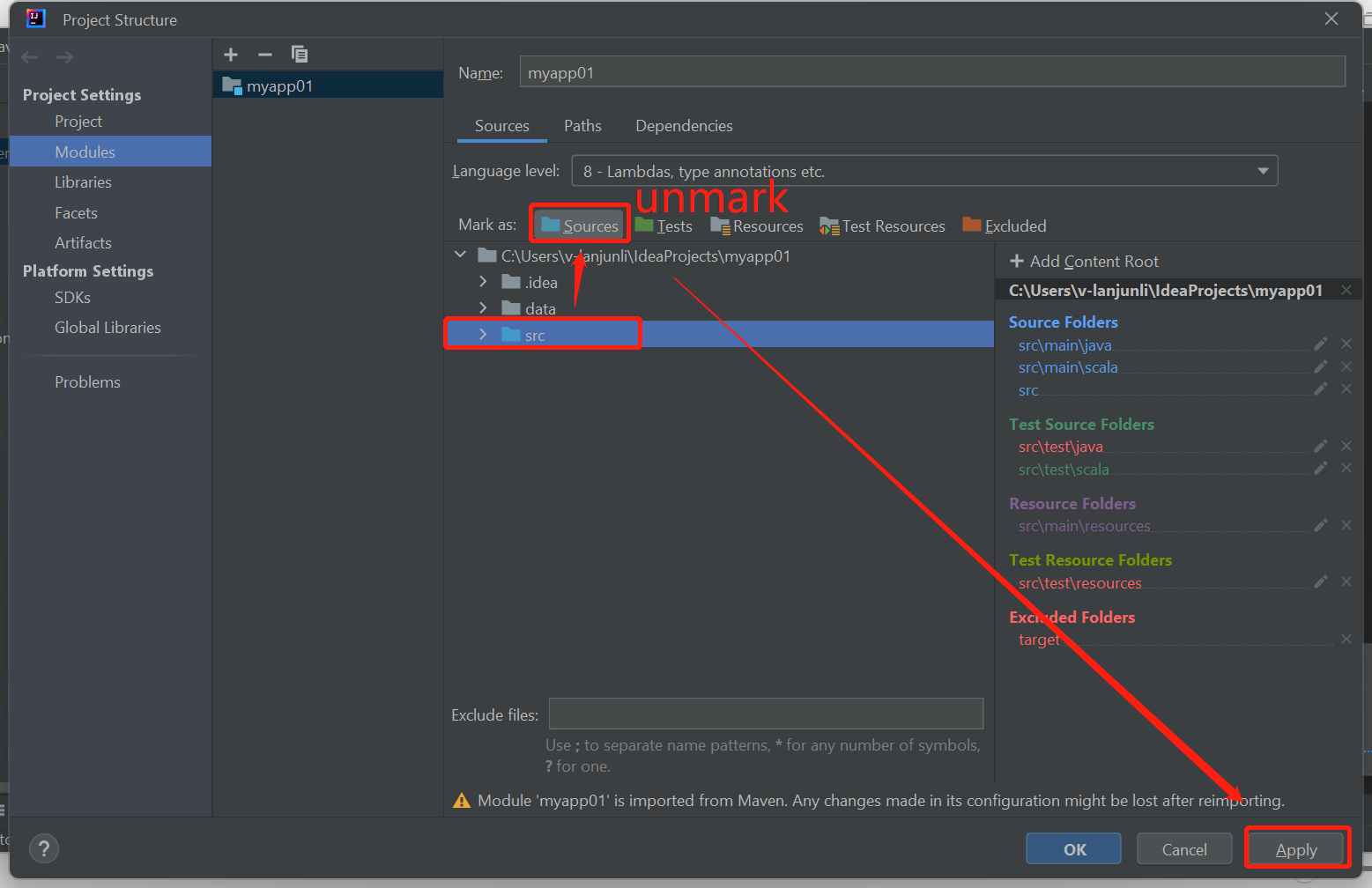
Hapus tanda folder src sebagai Sumber untuk mengatasi masalah ini:
Navigasi ke File dan pilih Struktur Proyek.
Pilih Modul di bawah Pengaturan Proyek.
Pilih file src dan hapus tanda sebagai Sumber.
Klik tombol Terapkan lalu klik tombol OK untuk menutup dialog.
Langkah berikutnya
Dalam artikel ini, Anda mempelajari cara menggunakan plug-in Azure Toolkit for IntelliJ untuk mengembangkan aplikasi Apache Spark yang ditulis di Scala. Kemudian mengirimkannya ke kluster HDInsight Spark langsung dari lingkungan pengembangan terintegrasi IntelliJ (IDE). Lanjutkan ke artikel berikutnya untuk melihat bagaimana data yang Anda daftarkan di Apache Spark dapat ditarik ke dalam alat analitik BI seperti Power BI.