Pengecualian OutOfMemoryError untuk Apache Spark di Azure HDInsight
Artikel ini menjelaskan langkah-langkah pemecahan masalah dan kemungkinan resolusi untuk masalah saat menggunakan komponen Apache Spark di kluster Microsoft Azure HDInsight.
Skenario: Pengecualian OutOfMemoryError untuk Apache Spark
Masalah
Aplikasi Apache Spark Anda gagal dengan pengecualian tidak tertangani OutOfMemoryError. Anda mungkin menerima pesan eror yang mirip dengan:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
Penyebab
Penyebab paling mungkin dari pengecualian ini adalah bahwa tidak ada cukup memori heap yang dialokasikan untuk komputer virtual Java (JVMs). JVM ini diluncurkan sebagai eksekutor atau driver sebagai bagian dari aplikasi Apache Spark.
Resolusi
Tentukan ukuran maksimum data yang ditangani aplikasi Spark. Buat perkiraan ukuran berdasarkan ukuran maksimum data input, data menengah yang dihasilkan dengan mengubah data input, dan data output yang dihasilkan dengan mengubah data menengah lebih lanjut. Jika perkiraan awal tidak memadai, tingkatkan ukurannya sedikit-sedikit, dan ulangi hingga kesalahan memorinya hilang.
Pastikan klaster HDInsight yang akan digunakan memiliki cukup sumber daya dalam hal memori dan juga inti untuk mengakomodasi aplikasi Spark. Ini dapat ditentukan dengan melihat bagian Metrik Klaster dari YARN UI klaster untuk nilai Memory yang Digunakan vs. Total Memori dan VCore yang Digunakan vs. Total VCore.

Atur konfigurasi Spark berikut ini ke nilai yang sesuai. Seimbangkan persyaratan aplikasi dengan sumber daya yang tersedia di klaster. Nilai-nilai ini tidak boleh melebihi 90% dari memori dan inti yang tersedia seperti yang dilihat oleh YARN, dan juga harus memenuhi persyaratan memori minimum aplikasi Spark:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)Total memori yang digunakan oleh semua eksekutor =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)Total memori yang digunakan oleh driver =
spark.driver.memory + spark.yarn.driver.memoryOverhead
Skenario: Eror ruang heap Java ketika mencoba membuka server riwayat Apache Spark
Masalah
Anda menerima eror berikut saat membuka peristiwa di Spark History server:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
Penyebab
Masalah ini sering disebabkan oleh kurangnya sumber daya saat membuka file peristiwa spark besar. Ukuran heap Spark diatur ke 1 GB secara default, tetapi file peristiwa Spark besar mungkin memerlukan lebih dari ini.
Jika Anda ingin memverifikasi ukuran file yang coba Anda muat, Anda dapat melakukan perintah berikut:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
Resolusi
Anda dapat meningkatkan memori Spark History Server dengan mengedit properti SPARK_DAEMON_MEMORY di konfigurasi Spark dan memulai ulang semua layanan.
Anda dapat melakukan ini dari dalam UI browser Ambari dengan memilih bagian Spark2/Config/Advanced spark2-env.
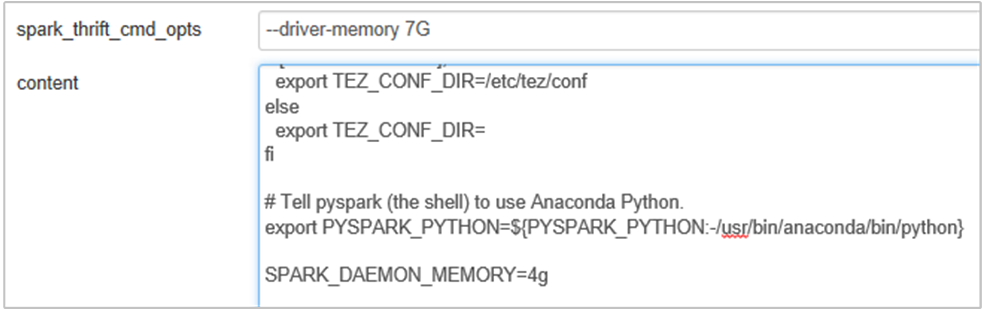
Tambahkan properti berikut ini untuk mengubah memori Spark History Server dari 1g ke 4g: SPARK_DAEMON_MEMORY=4g.
Pastikan untuk memulai ulang semua layanan yang terdampak dari Ambari.
Skenario: Server Livy gagal memulai pada klaster Apache Spark
Masalah
Livy Server tidak dapat dimulai pada Apache Spark [(Spark 2.1 di Linux (HDI 3.6)]. Percobaan untuk memulai ulang hasil dalam tumpukan eror berikut, dari log Livy:
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
Penyebab
java.lang.OutOfMemoryError: unable to create new native thread menyoroti OS tidak dapat menetapkan utas asli lainnya ke JVM. Terkonfirmasi bahwa Pengecualian ini disebabkan oleh pelanggaran batas jumlah rangkaian per proses.
Ketika Livy Server berakhir secara tak terduga, semua koneksi ke Kluster Spark juga dihentikan, yang berarti bahwa semua pekerjaan dan data terkait hilang. Dalam mekanisme pemulihan sesi HDP 2.6 yang diperkenalkan, Livy menyimpan rincian sesi di Zookeeper untuk dipulihkan setelah Server Livy kembali.
Ketika begitu banyak pekerjaan yang dikirimkan melalui Livy, sebagai bagian dari Ketersediaan Tinggi untuk Livy Server menyimpan status sesi ini di ZK (pada kluster HDInsight) dan memulihkan sesi tersebut ketika layanan Livy dimulai ulang. Saat memulai ulang setelah penghentian tak terduga, Livy membuat satu utas per sesi dan ini mengakumulasi beberapa sesi yang akan dipulihkan menyebabkan terlalu banyak utas dibuat.
Resolusi
Hapus semua entri menggunakan langkah-langkah berikut.
Dapatkan alamat IP Node zookeeper menggunakan
grep -R zk /etc/hadoop/confPerintah di atas mencantumkan semua zookeepers untuk kluster
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>Dapatkan semua alamat IP simpul zookeeper menggunakan ping Atau Anda juga dapat terhubung ke zookeeper dari headnode menggunakan nama zookeeper
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181Setelah Terhubung, ke zookeeper jalankan perintah berikut untuk mencantumkan semua sesi yang dicoba untuk memulai ulang.
Sebagian besar kasus ini bisa menjadi daftar bagi lebih dari 8000 sesi ####
ls /livy/v1/batchPerintah berikut bertujuan untuk menghapus semua sesi yang akan dipulihkan. #####
rmr /livy/v1/batch
Tunggu hingga perintah di atas selesai dan kursor menampilkan prompt lalu mulai ulang layanan Livy dari Ambari, yang seharusnya berhasil.
Catatan
DELETE sesi livy setelah menyelesaikan eksekusinya. Sesi batch Livy tidak akan dihapus secara otomatis segera setelah aplikasi spark selesai, yang memang disengaja. Sesi Livy adalah entitas yang dibuat oleh permintaan POST terhadap server Livy REST. Perintah DELETE diperlukan untuk menghapus entitas tersebut. Atau kita harus menunggu GC untuk bereaksi.
Langkah berikutnya
Jika Anda tidak melihat masalah atau tidak dapat memecahkan masalah, kunjungi salah satu saluran berikut untuk mendapatkan dukungan lebih lanjut:
Penelusuran kesalahan aplikasi Spark pada klaster HDInsight.
Dapatkan jawaban dari para ahli Azure melalui Dukungan Komunitas Azure.
Hubungi @AzureSupport - akun Microsoft Azure resmi untuk meningkatkan pengalaman pelanggan. Menghubungkan komunitas Microsoft Azure ke sumber daya yang tepat: jawaban, dukungan, dan pakar.
Jika Anda memerlukan bantuan lainnya, Anda dapat mengirimkan permintaan dukungan dari portal Microsoft Azure. Pilih Dukungan dari bilah menu atau buka hub Bantuan + Dukungan. Untuk informasi selengkapnya, tinjau Cara membuat permintaan dukungan Microsoft Azure. Akses ke Manajemen Langganan dan dukungan tagihan disertakan dengan langganan Microsoft Azure, dan Dukungan Teknis disediakan melalui salah satu Paket Dukungan Azure.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk