Pembelajaran mendalam vs. pembelajaran mesin pada Azure Machine Learning
Artikel ini menjelaskan pembelajaran mendalam vs. pembelajaran mesin dan bagaimana mereka masuk ke kategori kecerdasan buatan yang lebih luas. Pelajari tentang solusi pembelajaran mendalam yang bisa Anda buat di Azure Machine Learning, seperti deteksi penipuan, pengenalan suara dan wajah, analisis sentimen, dan perkiraan rangkaian waktu.
Untuk panduan tentang memilih algoritme untuk solusi Anda, lihat Cheat Sheet Algoritma Pembelajaran Mesin.
Model Dasar di Azure Pembelajaran Mesin adalah model pembelajaran mendalam pra-terlatih yang dapat disempurnakan untuk kasus penggunaan tertentu. Pelajari selengkapnya tentang Model Foundation (pratinjau) di Azure Pembelajaran Mesin, dan cara menggunakan Model Foundation di Azure Pembelajaran Mesin (pratinjau).
Pembelajaran mendalam, pembelajaran mesin, dan AI
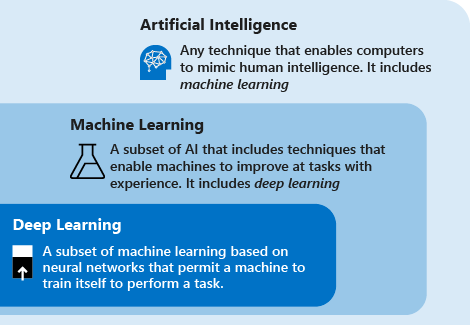
Pertimbangkan definisi berikut ini untuk memahami pembelajaran mendalam vs. pembelajaran mesin vs.AI:
Pembelajaran mendalam adalah subset pembelajaran mesin yang didasarkan pada jaringan saraf buatan. Proses pembelajarannya sangat dalam karena struktur jaringan saraf buatan terdiri dari beberapa lapisan input, output, dan tersembunyi. Setiap lapisan berisi unit yang mengubah data input menjadi informasi yang bisa digunakan oleh lapisan berikutnya untuk tugas prediktif tertentu. Berkat struktur ini, mesin bisa belajar melalui pemrosesan datanya sendiri.
Pembelajaran mesin adalah subset kecerdasan buatan yang menggunakan teknik (seperti pembelajaran mendalam) yang memungkinkan mesin menggunakan pengalaman untuk meningkatkan performa pada tugas. Proses pembelajarannya didasarkan pada langkah-langkah berikut:
- Umpan data ke algoritma. (Dalam langkah ini Anda bisa memberikan informasi tambahan ke model, misalnya, dengan melakukan ekstraksi fitur.)
- Gunakan data ini untuk melatih model.
- Uji dan sebarkan model.
- Konsumsi model yang disebarkan untuk melakukan tugas prediktif otomatis. (Dengan kata lain, hubungi dan gunakan model yang disebarkan untuk menerima prediksi yang dikembalikan lagi oleh model.)
Kecerdasan buatan (AI) adalah sebuah teknik yang memungkinkan komputer untuk meniru kecerdasan manusia. Ini termasuk pembelajaran mesin.
AI generatif adalah subset kecerdasan buatan yang menggunakan teknik (seperti pembelajaran mendalam) untuk menghasilkan konten baru. Misalnya, Anda dapat menggunakan AI generatif untuk membuat gambar, teks, atau audio. Model-model ini memanfaatkan pengetahuan besar yang telah dilatih sebelumnya untuk menghasilkan konten ini.
Dengan menggunakan teknik pembelajaran mesin dan pembelajaran mendalam, Anda bisa membangun sistem komputer dan aplikasi yang melakukan tugas yang umumnya berasosiasi dengan kecerdasan manusia. Tugas-tugas ini termasuk pengenalan gambar, pengenalan ucapan, dan penterjemahan bahasa.
Teknik pembelajaran mendalam vs. pembelajaran mesin
Kini setelah Anda memiliki gambaran pembelajaran mesin vs pembelajaran mendalam, mari kita bandingkan dua teknik tersebut. Dalam pembelajaran mesin, algoritma perlu diberitahu cara membuat prediksi yang akurat dengan memakai lebih banyak informasi (misalnya, dengan melakukan ekstraksi fitur). Pada pembelajaran mendalam, algoritma dapat mempelajari cara membuat prediksi yang akurat melalui pemrosesan datanya sendiri, berkat struktur jaringan saraf buatan.
Tabel berikut membandingkan dua teknik tersebut secara lebih rinci:
| Semua pembelajaran mesin | Hanya pembelajaran mendalam | |
|---|---|---|
| Jumlah titik data | Bisa menggunakan sejumlah kecil data untuk membuat prediksi. | Harus menggunakan data pelatihan dalam jumlah besar untuk membuat prediksi. |
| Dependensi perangkat keras | Dapat bekerja pada mesin kelas bawah. Tidak memerlukan sejumlah besar kekuatan komputasi. | Tergantung pada mesin kelas atas. Secara inheren melakukan sejumlah besar operasi perkalian matriks. GPU dapat mengoptimalkan operasi ini secara efisien. |
| Proses fiturisasi | Membutuhkan fitur untuk diidentifikasi dan dibuat secara akurat oleh pengguna. | Mempelajari fitur tingkat tinggi dari data dan membuat fitur baru dengan sendirinya. |
| Pendekatan pembelajaran | Membagi proses pembelajaran menjadi langkah-langkah yang lebih kecil. Lalu menggabungkan hasil dari setiap langkah menjadi satu output. | Melewati proses pembelajaran dengan menyelesaikan masalah secara end-to-end. |
| Waktu eksekusi | Membutuhkan waktu yang relatif sedikit untuk berlatih, mulai dari beberapa detik hingga beberapa jam. | Biasanya membutuhkan waktu lama untuk berlatih karena algoritma pembelajaran mendalam melibatkan banyak lapisan. |
| Hasil | Output biasanya merupakan nilai numerik, seperti skor atau klasifikasi. | Output bisa memiliki beberapa format, seperti teks, skor, atau suara. |
Apa itu pembelajaran transfer?
Pelatihan model pembelajaran mendalam seringkali memerlukan sejumlah besar data pelatihan, sumber daya komputasi kelas atas (GPU, TPU), dan waktu pelatihan yang lebih lama. Dalam skenario ketika Anda tidak memiliki salah satu dari hal tersebut tersedia untuk Anda, Anda dapat mempersingkat proses pelatihan menggunakan teknik yang dikenal sebagai transfer learning.
Pembelajaran transfer adalah teknik yang menerapkan pengetahuan yang diperoleh dari pemecahan satu masalah ke masalah lain tetapi masih terkait.
Karena struktur jaringan neuralnya, set lapisan pertama biasanya berisi fitur tingkat bawah, sedangkan set akhir lapisan berisi fitur tingkat yang lebih tinggi yang lebih dekat dengan domain yang dimaksud. Dengan mengganti lapisan final untuk digunakan di domain atau masalah baru, Anda dapat secara signifikan mengurangi jumlah waktu, data, dan sumber daya komputasi yang diperlukan untuk melatih model baru. Misalnya, jika Anda sudah memiliki model yang mengenali mobil, Anda bisa mengubah model itu menggunakan transfer learning untuk juga mengenali truk, sepeda motor, dan jenis kendaraan lainnya.
Pelajari cara menerapkan pembelajaran transfer untuk klasifikasi gambar dengan kerangka kerja sumber terbuka di Azure Machine Learning : Melatih model PyTorch pembelajaran mendalam menggunakan pembelajaran transfer.
Kasus penggunaan pembelajaran mendalam
Karena struktur jaringan saraf buatannya, pembelajaran mendalam unggul dalam mengidentifikasi pola dalam data yang tidak terstruktur seperti gambar, suara, video, dan teks. Untuk alasan ini, pembelajaran mendalam mengubah banyak industri, termasuk perawatan kesehatan, energi, keuangan, dan transportasi dengan cepat. Industri-industri tersebut kini memikirkan kembali proses bisnis tradisional.
Beberapa aplikasi yang paling umum untuk pembelajaran mendalam dijelaskan dalam paragraf berikut ini. Di Azure Pembelajaran Mesin, Anda dapat menggunakan model yang Anda buat dari kerangka kerja sumber terbuka atau membangun model menggunakan alat yang disediakan.
Pengenalan entitas bernama
Pengenalan entitas bernama adalah metode pembelajaran mendalam yang mengambil sepotong teks sebagai input lalu mengubahnya menjadi kelas yang telah ditentukan sebelumnya. Informasi baru ini bisa berupa kode pos, tanggal, ID produk. Informasi tersebut lalu bisa disimpan dalam skema terstruktur untuk membuat daftar alamat atau berfungsi sebagai tolok ukur untuk mesin validasi identitas.
Deteksi objek
Pembelajaran mendalam telah diterapkan dalam banyak kasus penggunaan deteksi objek. Deteksi objek digunakan untuk mengidentifikasi objek dalam gambar (seperti mobil atau orang) dan menyediakan lokasi tertentu untuk setiap objek dengan kotak pembatas.
Deteksi objek sudah digunakan di industri seperti game, ritel, pariwisata, dan mobil swakemudi.
Pembuatan keterangan gambar
Seperti pengenalan gambar, pada keterangan gambar, untuk gambar tertentu, sistem harus menghasilkan keterangan yang menjelaskan isi gambar. Saat Anda bisa mendeteksi dan memberi label objek dalam foto, langkah selanjutnya adalah mengubah label tersebut menjadi kalimat deskriptif.
Biasanya, aplikasi keterangan gambar menggunakan jaringan saraf yang berbelit untuk mengidentifikasi objek dalam gambar lalu menggunakan jaringan saraf berulang untuk mengubah label menjadi kalimat yang konsisten.
Penterjemahan mesin
Penterjemahan mesin mengambil kata atau kalimat dari satu bahasa dan secara otomatis menerjemahkannya ke dalam bahasa lain. Penterjemahan mesin telah ada untuk waktu yang lama, tetapi pembelajaran mendalam mencapai hasil yang mengesankan di dua bidang khusus: terjemahan teks otomatis (dan terjemahan ucapan ke teks) dan terjemahan otomatis gambar.
Dengan transformasi data yang sesuai, jaringan saraf bisa memahami sinyal teks, audio, dan visual. Terjemahan mesin bisa digunakan untuk mengidentifikasi cuplikan suara dalam file audio yang lebih besar dan mentranskripsi kata atau gambar yang diucapkan sebagai teks.
Analitik Teks
Analitik teks berdasarkan metode pembelajaran mendalam melibatkan analisis data teks dalam jumlah besar (misalnya, dokumen medis atau tanda terima pengeluaran), mengenali pola, serta membuat informasi yang terorganisir dan ringkas darinya.
Perusahaan menggunakan pembelajaran mendalam untuk melakukan analisis teks untuk mendeteksi perdagangan orang dalam dan kepatuhan kepada peraturan pemerintah. Contoh umum lainnya adalah penipuan asuransi: analitik teks sering digunakan untuk menganalisis sejumlah besar dokumen untuk mengenali kemungkinan penipuan klaim asuransi.
Jaringan saraf buatan
Jaringan saraf buatan dibentuk oleh lapisan simpul yang saling terhubung. Model pembelajaran mendalam menggunakan jaringan saraf yang mempunyai sejumlah besar lapisan.
Bagian berikut menjelajahi topologi jaringan neural buatan paling populer.
Jaringan saraf feedforward
Jaringan saraf feedforward adalah jenis jaringan saraf buatan yang paling sederhana. Dalam jaringan feedforward, informasi hanya bergerak ke satu arah dari lapisan input ke lapisan output. Jaringan saraf feedforward mengubah input dengan menaruhnya melalui serangkaian lapisan tersembunyi. Setiap lapisan terdiri dari satu set neuron, dan setiap lapisan sepenuhnya terhubung ke semua neuron pada lapisan sebelumnya. Lapisan terakhir yang sepenuhnya terhubung (lapisan output) mewakili prediksi yang dihasilkan.
Jaringan saraf berulang (Recurrent Neural Network, RNN)
Jaringan saraf berulang adalah jaringan saraf buatan yang banyak digunakan. Jaringan ini menyimpan output lapisan lalu mengembalikannya ke lapisan input untuk membantu memprediksi hasil lapisan. Jaringan saraf berulang memiliki kemampuan belajar yang hebat. Jaringan ini banyak digunakan untuk tugas-tugas kompleks seperti perkiraan rangkaian waktu, belajar tulisan tangan, dan mengenali bahasa.
Jaringan saraf konvolusional (CNN)
Jaringan saraf konvolusional adalah jaringan saraf buatan yang sangat efektif, serta menyajikan arsitektur yang unik. Lapisan diatur dalam tiga dimensi: lebar, tinggi, dan kedalaman. Neuron pada satu lapisan tidak terhubung ke semua neuron di lapisan berikutnya, tetapi hanya ke wilayah kecil neuron lapisan. Output akhir dikurangi menjadi vektor tunggal skor probabilitas, yang ditata di sepanjang dimensi kedalaman.
Jaringan saraf konvolusional telah digunakan di area seperti pengenalan video, pengenalan gambar, serta sistem rekomendasi.
Jaringan adversarial generatif (GAN)
Jaringan adversarial generatif adalah model generatif yang dilatih untuk membuat konten yang realistis seperti gambar. Jaringan ini terdiri dari dua jaringan yang dikenal sebagai generator dan diskriminator. Kedua jaringan dilatih secara bersamaan. Selama pelatihan, generator menggunakan kebisingan acak untuk membuat data sintetis baru yang sangat menyerupai data asli. Diskriminator mengambil output dari generator sebagai input dan memakai data nyata untuk menentukan apakah konten yang dihasilkan asli atau sintetis. Setiap jaringan bersaing satu sama lain. Generator mencoba menghasilkan konten sintetis yang tidak bisa dibedakan dari konten asli dan diskriminator mencoba mengklasifikasikan input dengan benar sebagai asli atau sintetis. Output lalu digunakan untuk memperbarui bobot kedua jaringan untuk membantu mereka mencapai tujuan masing-masing dengan lebih baik.
Jaringan adversarial generatif digunakan untuk memecahkan masalah seperti terjemahan gambar dan perkembangan usia.
Transformer
Transformer adalah arsitektur model yang cocok untuk memecahkan masalah yang berisi urutan seperti teks atau data seri waktu. Model ini terdiri dari lapisan encoder dan decoder. Encoder mengambil input dan memetakannya pada representasi numerik yang berisi informasi seperti konteks. Decoder menggunakan informasi dari encoder untuk menghasilkan output seperti teks yang diterjemahkan. Apa yang membuat transformer berbeda dari arsitektur lain yang mengandung encoder dan decoder adalah sub-layer perhatiannya. Perhatian adalah gagasan untuk berfokus pada bagian-bagian tertentu dari input berdasarkan pentingnya konteks mereka pada kaitannya dengan input lain secara berurutan. Misalnya, saat meringkas artikel berita, tidak semua kalimat relevan dalam menggambarkan ide utama. Dengan berfokus pada kata-kata kunci di seluruh artikel, ringkasan bisa dilakukan dalam satu kalimat, yaitu judulnya.
Transformer telah digunakan untuk memecahkan masalah pemrosesan bahasa alami seperti terjemahan, pembuatan teks, jawaban pertanyaan, dan ringkasan teks.
Beberapa implementasi transformer yang terkenal adalah:
- Bidirectional Encoder Representations from Transformers (BERT)
- Generative Pre-trained Transformer 2 (GPT-2)
- Generative Pre-trained Transformer 3 (GPT-3)
Langkah berikutnya
Artikel berikut ini menunjukkan kepada Anda lebih banyak opsi untuk menggunakan model pembelajaran mendalam open-source di Azure Machine Learning: