Cara menggunakan model fondasi Sumber Terbuka yang dikurasi oleh Azure Pembelajaran Mesin
Dalam artikel ini, Anda mempelajari cara menyempurnakan, mengevaluasi, dan menyebarkan model fondasi di Katalog Model.
Anda dapat dengan cepat menguji model yang telah dilatih sebelumnya menggunakan formulir Inferensi Sampel pada kartu model, memberikan input sampel Anda sendiri untuk menguji hasilnya. Selain itu, kartu model untuk setiap model menyertakan deskripsi singkat tentang model dan tautan ke sampel untuk inferensi berbasis kode, penyempurnaan, dan evaluasi model.
Cara mengevaluasi model fondasi menggunakan data pengujian Anda sendiri
Anda dapat mengevaluasi Model Foundation terhadap himpunan data pengujian Anda, menggunakan formulir Evaluasi UI atau dengan menggunakan sampel berbasis kode, yang ditautkan dari kartu model.
Mengevaluasi menggunakan studio
Anda dapat memanggil formulir Evaluasi model dengan memilih tombol Evaluasi pada kartu model untuk model fondasi apa pun.
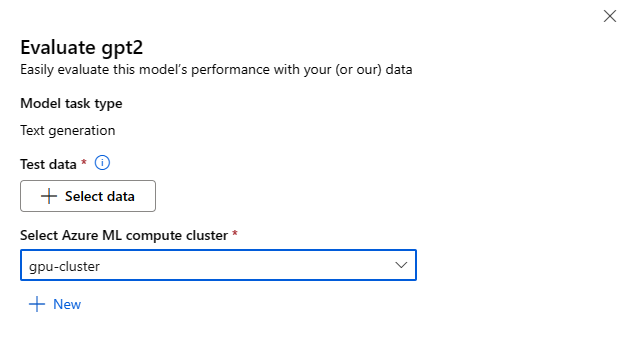
Setiap model dapat dievaluasi untuk tugas inferensi tertentu yang akan digunakan model.
Data Pengujian:
- Berikan data pengujian yang ingin Anda gunakan untuk mengevaluasi model Anda. Anda dapat memilih untuk mengunggah file lokal (dalam format JSONL) atau memilih himpunan data terdaftar yang ada dari ruang kerja Anda.
- Setelah memilih himpunan data, Anda perlu memetakan kolom dari data input Anda, berdasarkan skema yang diperlukan untuk tugas tersebut. Misalnya, petakan nama kolom yang sesuai dengan kunci 'kalimat' dan 'label' untuk Klasifikasi Teks

Komputasi:
Berikan kluster Azure Pembelajaran Mesin Compute yang ingin Anda gunakan untuk menyempurnakan model. Evaluasi perlu berjalan pada komputasi GPU. Pastikan Anda memiliki kuota komputasi yang memadai untuk SKU komputasi yang ingin Anda gunakan.
Pilih Selesai dalam formulir Evaluasi untuk mengirimkan pekerjaan evaluasi Anda. Setelah pekerjaan selesai, Anda dapat melihat metrik evaluasi untuk model. Berdasarkan metrik evaluasi, Anda dapat memutuskan apakah Anda ingin menyempurnakan model menggunakan data pelatihan Anda sendiri. Selain itu, Anda dapat memutuskan apakah Anda ingin mendaftarkan model dan menyebarkannya ke titik akhir.
Mengevaluasi menggunakan sampel berbasis kode
Untuk memungkinkan pengguna memulai evaluasi model, kami telah menerbitkan sampel (baik buku catatan Python maupun contoh CLI) dalam sampel Evaluasi di repositori git azureml-examples. Setiap kartu model juga menautkan ke sampel evaluasi untuk tugas yang sesuai
Cara menyempurnakan model fondasi menggunakan data pelatihan Anda sendiri
Untuk meningkatkan performa model dalam beban kerja, Anda mungkin ingin menyelaraskan model dasar menggunakan data pelatihan Anda sendiri. Anda dapat dengan mudah menyempurnakan model fondasi ini dengan menggunakan pengaturan penyempurnaan di studio atau dengan menggunakan sampel berbasis kode yang ditautkan dari kartu model.
Menyempurnakan menggunakan studio
Anda dapat memanggil formulir pengaturan penyempurnaan dengan memilih tombol Sesuaikan pada kartu model untuk model dasar apa pun.
Menyempurnakan Pengaturan:
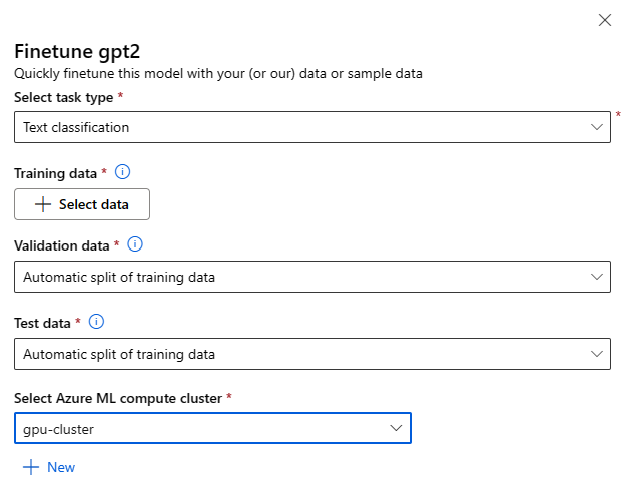
Jenis tugas penyempurnaan
- Setiap model yang telah dilatih sebelumnya dari katalog model dapat disempurnakan untuk serangkaian tugas tertentu (Misalnya: Klasifikasi teks, Klasifikasi token, Jawaban atas pertanyaan). Pilih tugas yang ingin Anda gunakan dari menu drop-down.
Data Pelatihan
Teruskan data pelatihan yang ingin Anda gunakan untuk menyempurnakan model Anda. Anda dapat memilih untuk mengunggah file lokal (dalam format JSONL, CSV, atau TSV) atau memilih himpunan data terdaftar yang ada dari ruang kerja Anda.
Setelah memilih himpunan data, Anda perlu memetakan kolom dari data input Anda, berdasarkan skema yang diperlukan untuk tugas tersebut. Misalnya: memetakan nama kolom yang sesuai dengan kunci 'kalimat' dan 'label' untuk Klasifikasi Teks

- Data validasi: Berikan data yang ingin Anda gunakan untuk memvalidasi model Anda. Memilih Pemisahan otomatis mencadangkan pemisahan data pelatihan otomatis untuk validasi. Atau, Anda dapat memberikan himpunan data validasi yang berbeda.
- Data pengujian: Berikan data pengujian yang ingin Anda gunakan untuk mengevaluasi model yang disempurnakan. Memilih Pemisahan otomatis mencadangkan pemisahan data pelatihan otomatis untuk pengujian.
- Komputasi: Berikan kluster Azure Pembelajaran Mesin Compute yang ingin Anda gunakan untuk menyempurnakan model. Penyempurnaan perlu dijalankan pada komputasi GPU. Sebaiknya gunakan SKU komputasi dengan GPU A100 / V100 saat menyempurnakan. Pastikan Anda memiliki kuota komputasi yang memadai untuk SKU komputasi yang ingin Anda gunakan.
- Pilih Selesai dalam formulir penyempurnaan untuk mengirimkan pekerjaan penyempurnaan Anda. Setelah pekerjaan selesai, Anda dapat melihat metrik evaluasi untuk model yang disempurnakan. Anda kemudian dapat mendaftarkan output model yang disempurnakan oleh pekerjaan penyempurnaan dan menyebarkan model ini ke titik akhir untuk inferensi.
Menyempurnakan menggunakan sampel berbasis kode
Saat ini, Azure Pembelajaran Mesin mendukung model penyempurnaan untuk tugas bahasa berikut:
- Klasifikasi teks
- Klasifikasi token
- Jawaban atas pertanyaan
- Ringkasan
- Terjemahan
Untuk memungkinkan pengguna memulai penyempurnaan dengan cepat, kami telah menerbitkan sampel (baik buku catatan Python maupun contoh CLI) untuk setiap tugas dalam sampel Finetune repositori git azureml-examples. Setiap kartu model juga menautkan ke sampel penyempurnaan untuk tugas penyempurnaan yang didukung.
Menyebarkan model fondasi ke titik akhir untuk inferensi
Anda dapat menyebarkan model fondasi (baik model yang telah dilatih sebelumnya dari katalog model, dan model yang disempurnakan, setelah didaftarkan ke ruang kerja Anda) ke titik akhir yang kemudian dapat digunakan untuk inferensi. Penyebaran ke API tanpa server dan komputasi terkelola didukung. Anda dapat menyebarkan model ini dengan menggunakan wizard Sebarkan UI atau dengan menggunakan sampel berbasis kode yang ditautkan dari kartu model.
Menyebarkan menggunakan studio
Anda dapat memanggil formulir Sebarkan UI dengan memilih tombol Sebarkan pada kartu model untuk model dasar apa pun, dan memilih API Tanpa Server dengan Konten Azure AI Brankas ty atau Komputasi Terkelola tanpa Konten Azure AI Brankas ty

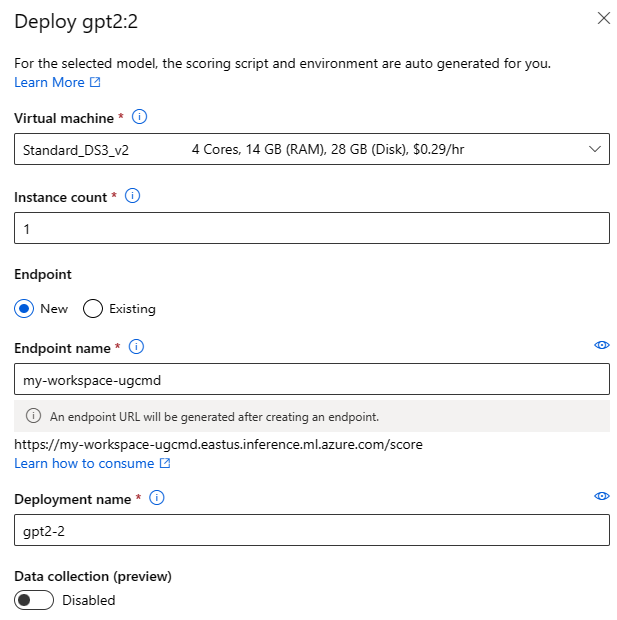
Pengaturan penyebaran
Karena skrip penilaian dan lingkungan secara otomatis disertakan dengan model fondasi, Anda hanya perlu menentukan SKU Komputer virtual yang akan digunakan, jumlah instans, dan nama titik akhir yang akan digunakan untuk penyebaran.
Kuota bersama
Jika Anda menyebarkan model Llama-2, Phi, Nemotron, Mistral, Dolly, atau Deci-DeciLM dari katalog model tetapi tidak memiliki cukup kuota yang tersedia untuk penyebaran, Azure Pembelajaran Mesin memungkinkan Anda menggunakan kuota dari kumpulan kuota bersama untuk waktu yang terbatas. Untuk informasi selengkapnya tentang kuota bersama, lihat Kuota bersama Azure Machine Learning.

Menyebarkan menggunakan sampel berbasis kode
Untuk memungkinkan pengguna memulai penyebaran dan inferensi dengan cepat, kami telah menerbitkan sampel dalam sampel Inferensi di repositori git azureml-examples. Sampel yang diterbitkan termasuk buku catatan Python dan contoh CLI. Setiap kartu model juga menautkan ke sampel Inferensi untuk inferensi Real time dan Batch.
Mengimpor model fondasi
Jika Anda ingin menggunakan model sumber terbuka yang tidak disertakan dalam katalog model, Anda dapat mengimpor model dari Hugging Face ke ruang kerja Azure Pembelajaran Mesin Anda. Hugging Face adalah pustaka sumber terbuka untuk pemrosesan bahasa alami (NLP) yang menyediakan model yang telah dilatih sebelumnya untuk tugas NLP populer. Saat ini, impor model mendukung impor model untuk tugas berikut, selama model memenuhi persyaratan yang tercantum dalam Buku Catatan Impor Model:
- fill-mask
- klasifikasi token
- jawaban atas pertanyaan
- ringkasan
- pembuatan teks
- klasifikasi teks
- terjemahan
- klasifikasi gambar
- teks ke gambar
Catatan
Model dari Hugging Face tunduk pada persyaratan lisensi pihak ketiga yang tersedia di halaman detail model Hugging Face. Anda bertanggung jawab untuk mematuhi persyaratan lisensi model.
Anda dapat memilih tombol Impor di kanan atas katalog model untuk menggunakan Buku Catatan Impor Model.
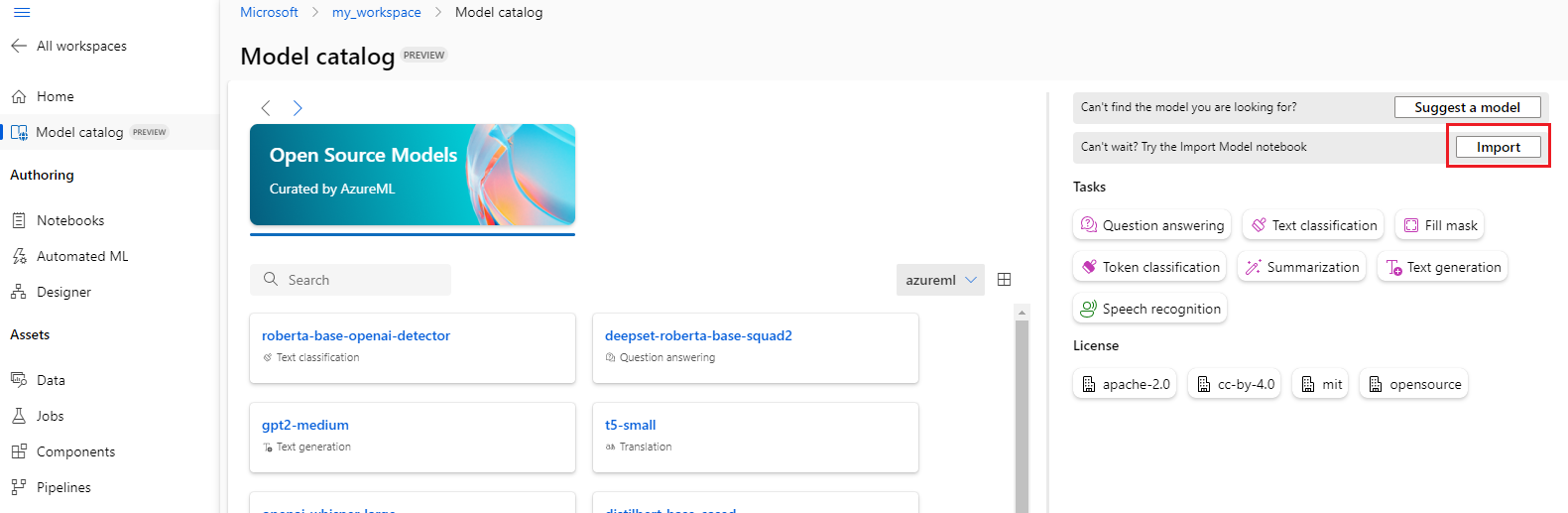
Notebook impor model juga disertakan dalam repositori git azureml-examples di sini.
Untuk mengimpor model, Anda perlu meneruskan MODEL_ID model yang ingin Anda impor dari Hugging Face. Telusuri model di Hugging Face hub dan identifikasi model yang akan diimpor. Pastikan jenis tugas model berada di antara jenis tugas yang didukung. Salin ID model, yang tersedia di URI halaman atau dapat disalin menggunakan ikon salin di samping nama model. Tetapkan ke variabel 'MODEL_ID' di buku catatan impor model. Contohnya:
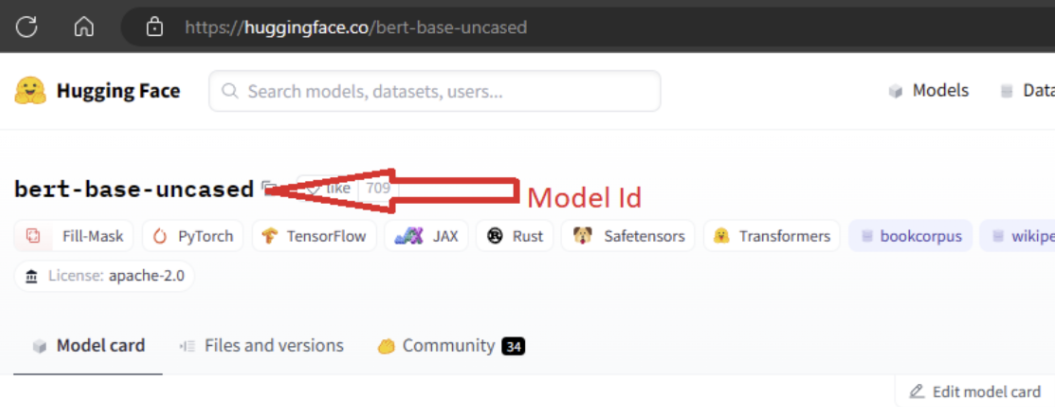
Anda perlu menyediakan komputasi agar impor Model berjalan. Menjalankan hasil Impor Model dalam model yang ditentukan yang diimpor dari Hugging Face dan didaftarkan ke ruang kerja Azure Pembelajaran Mesin Anda. Anda kemudian dapat menyempurnakan model ini atau menyebarkannya ke titik akhir untuk inferensi.
Pelajari lebih lanjut
- Jelajahi Katalog Model di studio Azure Pembelajaran Mesin. Anda memerlukan ruang kerja Azure Pembelajaran Mesin untuk menjelajahi katalog.
- Menjelajahi Katalog dan Koleksi Model
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk