Skrip penilaian penulis untuk penyebaran batch
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Titik akhir batch memungkinkan Anda untuk menyebarkan model yang melakukan inferensi jangka panjang dalam skala besar. Saat menyebarkan model, Anda harus membuat dan menentukan skrip penilaian (juga dikenal sebagai skrip driver batch) untuk menunjukkan cara menggunakannya melalui data input untuk membuat prediksi. Dalam artikel ini, Anda akan mempelajari cara menggunakan skrip penilaian dalam penyebaran model untuk skenario yang berbeda. Anda juga akan mempelajari tentang praktik terbaik untuk titik akhir batch.
Tip
Model MLflow tidak memerlukan skrip penilaian. Ini dibuat secara otomatis untuk Anda. Untuk informasi selengkapnya tentang cara kerja titik akhir batch dengan model MLflow, kunjungi tutorial menggunakan model MLflow dalam penyebaran batch khusus.
Peringatan
Untuk menyebarkan model ML Otomatis di bawah titik akhir batch, perhatikan bahwa ML Otomatis menyediakan skrip penilaian yang hanya berfungsi untuk Titik Akhir Online. Skrip penilaian tersebut tidak dirancang untuk eksekusi batch. Ikuti panduan ini untuk informasi selengkapnya tentang cara membuat skrip penilaian, yang disesuaikan untuk apa yang dilakukan model Anda.
Memahami skrip penilaian
Skrip penilaian adalah file Python (.py) yang menentukan cara menjalankan model, dan membaca data input yang dikirimkan pelaksana penyebaran batch. Setiap penyebaran model menyediakan skrip penilaian (bersama dengan semua dependensi lain yang diperlukan) pada waktu pembuatan. Skrip penilaian biasanya terlihat seperti ini:
deployment.yml
code_configuration:
code: code
scoring_script: batch_driver.py
Skrip penilaian harus berisi dua metode:
Metode init
init() Gunakan metode untuk persiapan yang mahal atau umum. Misalnya, gunakan untuk memuat model ke dalam memori. Awal seluruh pekerjaan batch memanggil fungsi ini satu kali. File model Anda tersedia di jalur yang ditentukan oleh variabel AZUREML_MODEL_DIRlingkungan . Bergantung pada bagaimana model Anda didaftarkan, filenya mungkin terkandung dalam folder. Dalam contoh berikutnya, model memiliki beberapa file dalam folder bernama model. Untuk informasi selengkapnya, kunjungi bagaimana Anda dapat menentukan folder yang digunakan model Anda.
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
# load the model
model = load_model(model_path)
Dalam contoh ini, kami menempatkan model dalam variabel modelglobal . Untuk menyediakan aset yang diperlukan untuk melakukan inferensi pada fungsi penilaian Anda, gunakan variabel global.
Metode run
run(mini_batch: List[str]) -> Union[List[Any], pandas.DataFrame] Gunakan metode untuk menangani penilaian setiap batch mini yang dihasilkan penyebaran batch. Metode ini dipanggil sekali untuk setiap mini_batch yang dihasilkan untuk data input Anda. Penyebaran batch membaca data dalam batch sesuai dengan bagaimana konfigurasi penyebaran.
import pandas as pd
from typing import List, Any, Union
def run(mini_batch: List[str]) -> Union[List[Any], pd.DataFrame]:
results = []
for file in mini_batch:
(...)
return pd.DataFrame(results)
Metode ini menerima daftar jalur file sebagai parameter (mini_batch). Anda dapat menggunakan daftar ini untuk melakukan iterasi dan memproses setiap file secara individual, atau untuk membaca seluruh batch dan memproses semuanya sekaligus. Opsi terbaik tergantung pada memori komputasi Anda dan throughput yang perlu Anda capai. Untuk contoh yang menjelaskan cara membaca seluruh batch data sekaligus, kunjungi Penyebaran throughput tinggi.
Catatan
Bagaimana cara kerja didistribusikan?
Penyebaran batch mendistribusikan pekerjaan di tingkat file, yang berarti bahwa folder yang berisi 100 file, dengan batch mini 10 file, menghasilkan masing-masing 10 batch dari 10 file. Perhatikan bahwa ukuran file yang relevan tidak memiliki relevansi. Agar file terlalu besar untuk diproses dalam batch mini besar, kami sarankan Anda membagi file menjadi file yang lebih kecil untuk mencapai tingkat paralelisme yang lebih tinggi, atau mengurangi jumlah file per batch mini. Saat ini, penyebaran batch tidak dapat memperhitungkan penyimpangan dalam distribusi ukuran file.
Metode run() harus mengembalikan Panda atau DataFrame array/daftar. Setiap elemen output yang ditampilkan menunjukkan eksekusi yang berhasil satu kali dari elemen input di input mini_batch. Untuk aset data file atau folder, setiap baris/elemen yang dikembalikan mewakili satu file yang diproses. Untuk aset data tabular, setiap baris/elemen yang dikembalikan mewakili baris dalam file yang diproses.
Penting
Bagaimana cara menulis prediksi?
Semua yang dikembalikan run() fungsi akan ditambahkan dalam file prediksi output yang dihasilkan oleh pekerjaan batch. Penting untuk mengembalikan jenis data yang tepat dari fungsi ini. Mengembalikan array saat Anda perlu menghasilkan satu prediksi. Mengembalikan DataFrames panda saat Anda perlu mengembalikan beberapa informasi. Misalnya, untuk data tabular, Anda mungkin ingin menambahkan prediksi Anda ke rekaman asli. Gunakan Pandas DataFrame untuk melakukan ini. Meskipun DataFrame panda mungkin berisi nama kolom, file output tidak menyertakan nama tersebut.
untuk menulis prediksi dengan cara yang berbeda, Anda dapat menyesuaikan output dalam penyebaran batch.
Peringatan
run Dalam fungsi , jangan keluarkan jenis data kompleks (atau daftar jenis data kompleks) alih-alih pandas.DataFrame. Output tersebut akan diubah menjadi string dan akan menjadi sulit dibaca.
DataFrame atau array yang dihasilkan ditambahkan ke file output yang ditunjukkan. Tidak ada persyaratan tentang kardinalitas hasil. Satu file dapat menghasilkan 1 atau banyak baris/elemen dalam output. Semua elemen dalam hasil DataFrame atau array ditulis ke file output apa adanya (mengingat output_action tidak summary_only).
Paket Python untuk penilaian
Anda harus menunjukkan pustaka apa pun yang diperlukan skrip penilaian Anda untuk dijalankan di lingkungan tempat penyebaran batch Anda berjalan. Untuk skrip penilaian, lingkungan ditunjukkan per penyebaran. Biasanya, Anda menunjukkan persyaratan Anda menggunakan conda.yml file dependensi, yang mungkin terlihat seperti ini:
mnist/environment/conda.yaml
name: mnist-env
channels:
- conda-forge
dependencies:
- python=3.8.5
- pip<22.0
- pip:
- torch==1.13.0
- torchvision==0.14.0
- pytorch-lightning
- pandas
- azureml-core
- azureml-dataset-runtime[fuse]
Kunjungi Membuat penyebaran batch untuk informasi selengkapnya tentang cara menunjukkan lingkungan untuk model Anda.
Menulis prediksi dengan cara yang berbeda
Secara default, penyebaran batch menulis prediksi model dalam satu file seperti yang ditunjukkan dalam penyebaran. Namun, dalam beberapa kasus, Anda harus menulis prediksi dalam beberapa file. Misalnya, untuk data input yang dipartisi, Anda mungkin juga ingin menghasilkan output yang dipartisi. Dalam kasus tersebut, Anda dapat Menyesuaikan output dalam penyebaran batch untuk menunjukkan:
- Format file (CSV, parkquet, json, dll) yang digunakan untuk menulis prediksi
- Cara data dipartisi dalam output
Kunjungi Menyesuaikan output dalam penyebaran batch untuk informasi selengkapnya tentang cara mencapainya.
Kontrol sumber skrip penilaian
Sangat disarankan untuk menempatkan skrip penilaian di bawah kontrol sumber.
Praktik terbaik untuk menulis skrip penilaian
Saat menulis skrip penilaian yang menangani data dalam jumlah besar, Anda harus mempertimbangkan beberapa faktor, termasuk
- Ukuran setiap file
- Jumlah data pada setiap file
- Jumlah memori yang diperlukan untuk membaca setiap file
- Jumlah memori yang diperlukan untuk membaca seluruh batch file
- Jejak memori model
- Jejak memori model, saat berjalan di atas data input
- Memori yang tersedia dalam komputasi Anda
Penyebaran batch mendistribusikan pekerjaan di tingkat file. Ini berarti bahwa folder yang berisi 100 file, dalam batch mini 10 file, menghasilkan 10 batch masing-masing 10 file (terlepas dari ukuran file yang terlibat). Agar file terlalu besar untuk diproses dalam batch mini besar, kami sarankan Anda membagi file menjadi file yang lebih kecil, untuk mencapai tingkat paralelisme yang lebih tinggi, atau Anda mengurangi jumlah file per batch mini. Saat ini, penyebaran batch tidak dapat memperhitungkan penyimpangan dalam distribusi ukuran file.
Hubungan antara tingkat paralelisme dan skrip penilaian
Konfigurasi penyebaran Anda mengontrol ukuran setiap batch mini dan jumlah pekerja pada setiap simpul. Ini menjadi penting ketika Anda memutuskan apakah akan membaca seluruh batch mini atau tidak untuk melakukan inferensi, menjalankan file inferensi menurut file, atau menjalankan baris inferensi menurut baris (untuk tabular). Kunjungi Menjalankan inferensi pada batch mini, file, atau tingkat baris untuk informasi selengkapnya.
Saat menjalankan beberapa pekerja pada instans yang sama, Anda harus memperhitungkan fakta bahwa memori dibagikan di semua pekerja. Peningkatan jumlah pekerja per simpul umumnya harus menyertai penurunan ukuran batch mini, atau dengan perubahan strategi penilaian jika ukuran data dan SKU komputasi tetap sama.
Menjalankan inferensi pada batch mini, file, atau tingkat baris
Titik akhir batch memanggil run() fungsi dalam skrip penilaian sekali per batch mini. Namun, Anda dapat memutuskan apakah Anda ingin menjalankan inferensi di seluruh batch, lebih dari satu file pada satu waktu, atau lebih dari satu baris pada satu waktu untuk data tabular.
Tingkat batch mini
Anda biasanya ingin menjalankan inferensi melalui batch sekaligus, untuk mencapai throughput tinggi dalam proses penilaian batch Anda. Ini terjadi jika Anda menjalankan inferensi melalui GPU, di mana Anda ingin mencapai kejenuhan perangkat inferensi. Anda mungkin juga mengandalkan pemuat data yang dapat menangani batching itu sendiri jika data tidak sesuai dengan memori, seperti TensorFlow atau PyTorch pemuat data. Dalam kasus ini, Anda mungkin ingin menjalankan inferensi pada seluruh batch.
Peringatan
Menjalankan inferensi pada tingkat batch mungkin memerlukan kontrol ketat atas ukuran data input, untuk memperhitungkan persyaratan memori dengan benar dan untuk menghindari pengecualian kehabisan memori. Apakah Anda dapat memuat seluruh batch mini dalam memori tergantung pada ukuran batch mini, ukuran instans dalam kluster, jumlah pekerja pada setiap simpul, dan ukuran mini-batch.
Kunjungi Penyebaran throughput tinggi untuk mempelajari cara mencapainya. Contoh ini memproses seluruh batch file pada satu waktu.
Tingkat file
Salah satu cara termampu untuk melakukan inferensi adalah iterasi atas semua file dalam batch mini, dan kemudian menjalankan model di atasnya. Dalam beberapa kasus, misalnya pemrosesan gambar, ini mungkin ide yang baik. Untuk data tabular, Anda mungkin perlu membuat estimasi yang baik tentang jumlah baris di setiap file. Perkiraan ini dapat menunjukkan apakah model Anda dapat menangani persyaratan memori untuk memuat seluruh data ke dalam memori dan untuk melakukan inferensi di atasnya. Beberapa model (terutama model tersebut berdasarkan jaringan neural berulang) terungkap dan menyajikan jejak memori dengan jumlah baris yang berpotensi nonlinear. Untuk model dengan pengeluaran memori tinggi, pertimbangkan untuk menjalankan inferensi di tingkat baris.
Tip
Pertimbangkan untuk memecah file terlalu besar untuk dibaca sekaligus ke dalam beberapa file yang lebih kecil, untuk memperhitungkan paralelisasi yang lebih baik.
Kunjungi Pemrosesan gambar dengan penyebaran batch untuk mempelajari cara melakukannya. Contoh tersebut memproses file pada satu waktu.
Tingkat baris (tabular)
Untuk model yang menyajikan tantangan dengan ukuran inputnya, Anda mungkin ingin menjalankan inferensi di tingkat baris. Penyebaran batch Anda masih menyediakan skrip penilaian Anda dengan batch mini file. Namun, Anda akan membaca satu file, satu baris dalam satu waktu. Ini mungkin tampak tidak efisien, tetapi untuk beberapa model pembelajaran mendalam mungkin satu-satunya cara untuk melakukan inferensi tanpa meningkatkan sumber daya perangkat keras Anda.
Kunjungi Pemrosesan teks dengan penyebaran batch untuk mempelajari cara melakukannya. Contoh tersebut memproses baris pada satu waktu.
Menggunakan model yang merupakan folder
AZUREML_MODEL_DIR Variabel lingkungan berisi jalur ke lokasi model yang dipilih, dan init() fungsi biasanya menggunakannya untuk memuat model ke dalam memori. Namun, beberapa model mungkin berisi filenya dalam folder, dan Anda mungkin perlu memperhitungkannya saat memuatnya. Anda dapat mengidentifikasi struktur folder model Anda seperti yang ditunjukkan di sini:
Buka portal Azure Pembelajaran Mesin.
Buka bagian Model.
Pilih model yang ingin Anda sebarkan, dan pilih tab Artefak .
Perhatikan folder yang ditampilkan. Folder ini ditunjukkan ketika model terdaftar.
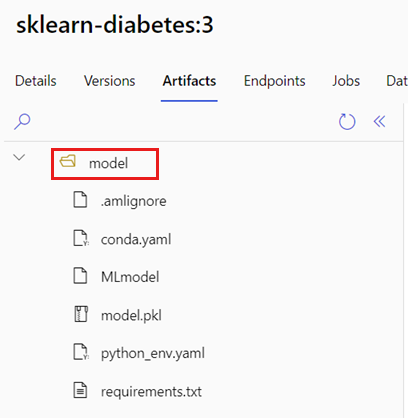

Gunakan jalur ini untuk memuat model:
def init():
global model
# AZUREML_MODEL_DIR is an environment variable created during deployment
# The path "model" is the name of the registered model's folder
model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model")
model = load_model(model_path)
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk