Menyebarkan model untuk penilaian di titik akhir batch
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Titik akhir batch menyediakan cara mudah untuk menyebarkan model yang menjalankan inferensi atas data dalam volume besar. Titik akhir ini menyederhanakan proses hosting model Anda untuk penilaian batch, sehingga fokus Anda adalah pada pembelajaran mesin, bukan infrastruktur.
Gunakan titik akhir batch untuk penyebaran model saat:
- Anda memiliki model mahal yang membutuhkan waktu lebih lama untuk menjalankan inferensi.
- Anda perlu melakukan inferensi atas sejumlah besar data yang didistribusikan dalam beberapa file.
- Anda tidak memiliki persyaratan latensi rendah.
- Anda dapat memanfaatkan paralelisasi.
Dalam artikel ini, Anda menggunakan titik akhir batch untuk menyebarkan model pembelajaran mesin yang memecahkan masalah pengenalan digit MNIST (Modified National Institute of Standards and Technology) klasik. Model yang Anda sebarkan kemudian melakukan inferensi batch melalui data dalam jumlah besar—dalam hal ini, file gambar. Anda mulai dengan membuat penyebaran batch model yang dibuat menggunakan Torch. Penyebaran ini menjadi default di titik akhir. Kemudian, Anda membuat penyebaran kedua mode yang dibuat dengan TensorFlow (Keras), menguji penyebaran kedua, lalu mengaturnya sebagai penyebaran default titik akhir.
Untuk mengikuti sampel kode dan file yang diperlukan untuk menjalankan perintah dalam artikel ini secara lokal, lihat bagian Mengkloning repositori contoh. Sampel kode dan file terkandung dalam repositori azureml-examples .
Prasyarat
Sebelum Mengikuti langkah-langkah dalam artikel ini, pastikan Anda memiliki prasyarat berikut:
Langganan Azure. Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai. Coba versi gratis atau berbayar Azure Machine Learning.
Ruang kerja Azure Machine Learning. Jika Anda tidak memilikinya, gunakan langkah-langkah dalam artikel Cara mengelola ruang kerja untuk membuatnya.
Untuk melakukan tugas berikut, pastikan Anda memiliki izin ini di ruang kerja:
Untuk membuat/mengelola titik akhir dan penyebaran batch: Gunakan peran pemilik, peran kontributor, atau peran kustom yang memungkinkan
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*.Untuk membuat penyebaran ARM di grup sumber daya ruang kerja: Gunakan peran pemilik, peran kontributor, atau peran kustom yang memungkinkan
Microsoft.Resources/deployments/writedalam grup sumber daya tempat ruang kerja disebarkan.
Anda perlu menginstal perangkat lunak berikut untuk bekerja dengan Azure Pembelajaran Mesin:
BERLAKU UNTUK:
Ekstensi ml Azure CLI v2 (saat ini)Azure CLI dan
mlekstensi untuk Azure Pembelajaran Mesin.az extension add -n ml
Mengkloning repositori contoh
Contoh dalam artikel ini didasarkan pada sampel kode yang terkandung dalam repositori azureml-examples . Untuk menjalankan perintah secara lokal tanpa harus menyalin/menempelkan YAML dan file lainnya, pertama-tama kloning repositori lalu ubah direktori ke folder:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli/endpoints/batch/deploy-models/mnist-classifier
Siapkan sistem Anda
Menyambungkan ke ruang kerja Anda
Pertama, sambungkan ke ruang kerja Azure Pembelajaran Mesin tempat Anda akan bekerja.
Jika belum mengatur default untuk Azure CLI, simpan pengaturan default Anda. Untuk menghindari meneruskan nilai untuk langganan, ruang kerja, grup sumber daya, dan lokasi Anda beberapa kali, jalankan kode ini:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Membuat komputasi
Titik akhir batch berjalan pada kluster komputasi dan mendukung kluster komputasi Azure Pembelajaran Mesin (AmlCompute) dan kluster Kubernetes. Kluster adalah sumber daya bersama, oleh karena itu, satu kluster dapat menghosting satu atau banyak penyebaran batch (bersama dengan beban kerja lain, jika diinginkan).
Buat komputasi bernama batch-cluster, seperti yang ditunjukkan dalam kode berikut. Anda dapat menyesuaikan sesuai kebutuhan dan mereferensikan komputasi Anda menggunakan azureml:<your-compute-name>.
az ml compute create -n batch-cluster --type amlcompute --min-instances 0 --max-instances 5
Catatan
Anda tidak dikenakan biaya untuk komputasi pada saat ini, karena kluster tetap pada 0 node sampai titik akhir batch dipanggil dan pekerjaan penilaian batch dikirimkan. Untuk informasi selengkapnya tentang biaya komputasi, lihat Mengelola dan mengoptimalkan biaya untuk AmlCompute.
Membuat titik akhir batch
Titik akhir batch adalah titik akhir HTTPS yang dapat dipanggil klien untuk memicu pekerjaan penilaian batch. Pekerjaan penilaian batch adalah pekerjaan yang mencetak beberapa input. Penyebaran batch adalah sekumpulan sumber daya komputasi yang menghosting model yang melakukan penilaian batch aktual (atau inferensi batch). Satu titik akhir batch dapat memiliki beberapa penyebaran batch. Untuk informasi selengkapnya tentang titik akhir batch, lihat Apa itu titik akhir batch?.
Tip
Salah satu penyebaran batch berfungsi sebagai penyebaran default untuk titik akhir. Ketika titik akhir dipanggil, penyebaran default melakukan penilaian batch aktual. Untuk informasi selengkapnya tentang titik akhir dan penyebaran batch, lihat titik akhir batch dan penyebaran batch.
Beri nama titik akhir. Nama titik akhir harus unik dalam wilayah Azure, karena namanya disertakan dalam URI titik akhir. Misalnya, hanya ada satu titik akhir batch dengan nama
mybatchendpointdiwestus2.Mengonfigurasi titik akhir batch
File YAML berikut mendefinisikan titik akhir batch. Anda dapat menggunakan file ini dengan perintah CLI untuk pembuatan titik akhir batch.
endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: mnist-batch description: A batch endpoint for scoring images from the MNIST dataset. tags: type: deep-learningTabel berikut ini menjelaskan properti kunci titik akhir. Untuk skema YAML titik akhir batch lengkap, lihat skema YAML titik akhir batch CLI (v2).
Kunci Deskripsi nameNama titik akhir batch. Harus unik di tingkat wilayah Azure. descriptionDeskripsi titik akhir batch. Properti ini bersifat opsional. tagsTag yang akan disertakan dalam titik akhir. Properti ini bersifat opsional. Buat titik akhir:
Buat penyebaran batch
Penyebaran model adalah sekumpulan sumber daya yang diperlukan untuk menghosting model yang melakukan inferensi aktual. Untuk membuat penyebaran model batch, Anda memerlukan item berikut:
- Model terdaftar di ruang kerja
- Kode untuk menilai model
- Lingkungan dengan dependensi model terinstal
- Pengaturan komputasi dan sumber daya yang telah dibuat sebelumnya
Mulailah dengan mendaftarkan model yang akan disebarkan—model Obor untuk masalah pengenalan digit populer (MNIST). Penyebaran Batch hanya dapat menyebarkan model yang terdaftar di ruang kerja. Anda dapat melewati langkah ini jika model yang ingin Anda sebarkan sudah terdaftar.
Tip
Model dikaitkan dengan penyebaran, bukan dengan titik akhir. Ini berarti bahwa satu titik akhir dapat melayani model yang berbeda (atau versi model) di bawah titik akhir yang sama, asalkan model yang berbeda (atau versi model) disebarkan dalam penyebaran yang berbeda.
Sekarang saatnya untuk membuat skrip penilaian. Penyebaran batch memerlukan skrip penilaian yang menunjukkan bagaimana model tertentu harus dijalankan dan bagaimana data input harus diproses. Titik akhir batch mendukung skrip yang dibuat di Python. Dalam hal ini, Anda menyebarkan model yang membaca file gambar yang mewakili digit dan menghasilkan digit yang sesuai. Skrip penilaian adalah sebagai berikut:
Catatan
Untuk model MLflow, Azure Pembelajaran Mesin secara otomatis menghasilkan skrip penilaian, sehingga Anda tidak diharuskan untuk menyediakannya. Jika model Anda adalah model MLflow, Anda dapat melewati langkah ini. Untuk informasi selengkapnya tentang cara kerja titik akhir batch dengan model MLflow, lihat artikel Menggunakan model MLflow dalam penyebaran batch.
Peringatan
Jika Anda menyebarkan model Pembelajaran mesin otomatis (AutoML) di bawah titik akhir batch, perhatikan bahwa skrip penilaian yang disediakan AutoML hanya berfungsi untuk titik akhir online dan tidak dirancang untuk eksekusi batch. Untuk informasi tentang cara membuat skrip penilaian untuk penyebaran batch Anda, lihat Menulis skrip penilaian untuk penyebaran batch.
deployment-torch/code/batch_driver.py
import os import pandas as pd import torch import torchvision import glob from os.path import basename from mnist_classifier import MnistClassifier from typing import List def init(): global model global device # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder model_path = os.environ["AZUREML_MODEL_DIR"] model_file = glob.glob(f"{model_path}/*/*.pt")[-1] model = MnistClassifier() model.load_state_dict(torch.load(model_file)) model.eval() device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] with torch.no_grad(): for image_path in mini_batch: image_data = torchvision.io.read_image(image_path).float() batch_data = image_data.expand(1, -1, -1, -1) input = batch_data.to(device) # perform inference predict_logits = model(input) # Compute probabilities, classes and labels predictions = torch.nn.Softmax(dim=-1)(predict_logits) predicted_prob, predicted_class = torch.max(predictions, axis=-1) results.append( { "file": basename(image_path), "class": predicted_class.numpy()[0], "probability": predicted_prob.numpy()[0], } ) return pd.DataFrame(results)Buat lingkungan tempat penyebaran batch Anda akan berjalan. Lingkungan harus mencakup paket
azureml-coredanazureml-dataset-runtime[fuse], yang diperlukan oleh titik akhir batch, ditambah dependensi apa pun yang diperlukan kode Anda untuk berjalan. Dalam hal ini, dependensi telah diambil dalamconda.yamlfile:deployment-torch/environment/conda.yaml
name: mnist-env channels: - conda-forge dependencies: - python=3.8.5 - pip<22.0 - pip: - torch==1.13.0 - torchvision==0.14.0 - pytorch-lightning - pandas - azureml-core - azureml-dataset-runtime[fuse]Penting
Paket
azureml-coredanazureml-dataset-runtime[fuse]diperlukan oleh penyebaran batch dan harus disertakan dalam dependensi lingkungan.Tentukan lingkungan sebagai berikut:
Definisi lingkungan akan disertakan dalam definisi penyebaran itu sendiri sebagai lingkungan anonim. Anda akan melihat di baris berikut dalam penyebaran:
environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlPeringatan
Lingkungan yang dikumpulkan tidak didukung dalam penyebaran batch. Anda perlu menentukan lingkungan Anda sendiri. Anda selalu dapat menggunakan gambar dasar lingkungan yang dikumpulkan sebagai milik Anda untuk menyederhanakan proses.
Membuat definisi penyebaran
deployment-torch/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-torch-dpl description: A deployment using Torch to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-torch path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-torch-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 30 error_threshold: -1 logging_level: infoTabel berikut ini menjelaskan properti utama penyebaran batch. Untuk skema YAML penyebaran batch lengkap, lihat skema YAML penyebaran batch CLI (v2).
Kunci Deskripsi nameNama penyebaran. endpoint_nameNama titik akhir untuk membuat penyebaran di bawah. modelModel yang akan digunakan untuk penilaian batch. Contoh menentukan model sebaris menggunakan path. Definisi ini memungkinkan file model untuk diunggah dan didaftarkan secara otomatis dengan nama dan versi yang dibuat secara otomatis. Lihat Skema model untuk opsi lainnya. Sebagai praktik terbaik untuk skenario produksi, Anda harus membuat model secara terpisah dan mereferensikannya di sini. Untuk mereferensikan model yang ada, gunakan sintaksazureml:<model-name>:<model-version>.code_configuration.codeDirektori lokal yang berisi semua kode sumber Python untuk menilai model. code_configuration.scoring_scriptFile Python di code_configuration.codedirektori. Berkas ini harus memiliki fungsiinit()dan fungsirun().init()Gunakan fungsi untuk persiapan yang mahal atau umum (misalnya, untuk memuat model dalam memori).init()hanya akan dipanggil sekali pada awal proses. Gunakanrun(mini_batch)untuk menilai setiap entri; nilaimini_batchadalah daftar jalur file. Fungsirun()harus menampilkan pandas DataFrame atau array. Setiap elemen yang ditampilkan menunjukkan satu elemen input yang berhasil dijalankan dimini_batch. Untuk informasi selengkapnya tentang cara menulis skrip penilaian, lihat Memahami skrip penilaian.environmentLingkungan untuk menilai model. Contoh menentukan lingkungan sebaris menggunakan conda_filedanimage. Dependensiconda_fileakan diinstal di atasimage. Lingkungan akan secara otomatis terdaftar dengan nama dan versi yang dibuat secara otomatis. Lihat Skema lingkungan untuk opsi lainnya. Sebagai praktik terbaik untuk skenario produksi, Anda harus membuat lingkungan secara terpisah dan mereferensikannya di sini. Untuk mereferensikan lingkungan yang ada, gunakan sintaksazureml:<environment-name>:<environment-version>.computeKomputasi untuk menjalankan penilaian batch. Contoh menggunakan yang batch-clusterdibuat di awal dan mereferensikannya menggunakanazureml:<compute-name>sintaks.resources.instance_countJumlah instans yang akan digunakan untuk setiap pekerjaan penilaian batch. settings.max_concurrency_per_instance[Opsional] Jumlah maksimum paralel scoring_scriptyang berjalan per instans.settings.mini_batch_size[Opsional] Jumlah file scoring_scriptyang dapat diproses dalam saturun()panggilan.settings.output_action[Opsional] Bagaimana output harus diatur dalam file output. append_rowakan menggabungkan semuarun()hasil output yang ditampilkan menjadi satu file tunggal bernamaoutput_file_name.summary_onlytidak akan menggabungkan hasil output dan hanya akan menghitungerror_threshold.settings.output_file_name[Opsional] Nama file output penilaian batch untuk append_rowoutput_action.settings.retry_settings.max_retries[Opsional] Jumlah maksimum mencoba untuk scoring_scriptrun()yang gagal.settings.retry_settings.timeout[Opsional] Batas waktu dalam detik bagi scoring_scriptrun()untuk menilai batch mini.settings.error_threshold[Opsional] Jumlah kegagalan penilaian file input yang harus diabaikan. Jika jumlah kesalahan untuk seluruh input melebihi nilai ini, pekerjaan penilaian batch akan dihentikan. Contoh menggunakan -1, yang menunjukkan bahwa sejumlah kegagalan diperbolehkan tanpa menghentikan pekerjaan penilaian batch.settings.logging_level[Opsional] Verbositas log. Nilai dalam meningkatkan verbositas adalah: WARNING, INFO, dan DEBUG. settings.environment_variables[Opsional] Kamus pasangan nilai nama variabel lingkungan yang akan diatur untuk setiap pekerjaan penilaian batch. Buat penyebaran:
Jalankan kode berikut untuk membuat penyebaran batch di bawah titik akhir batch, dan atur sebagai penyebaran default.
az ml batch-deployment create --file deployment-torch/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultTip
Parameter
--set-defaultmengatur penyebaran yang baru dibuat sebagai penyebaran default titik akhir. Ini adalah cara yang mudah untuk membuat penyebaran default baru dari titik akhir, terutama untuk pembuatan penyebaran pertama. Sebagai praktik terbaik untuk skenario produksi, Anda mungkin ingin membuat penyebaran baru tanpa mengaturnya sebagai default. Verifikasi bahwa penyebaran berfungsi seperti yang Anda harapkan, lalu perbarui penyebaran default nanti. Untuk informasi selengkapnya tentang menerapkan proses ini, lihat bagian Menyebarkan model baru.Periksa titik akhir batch dan detail penyebaran.

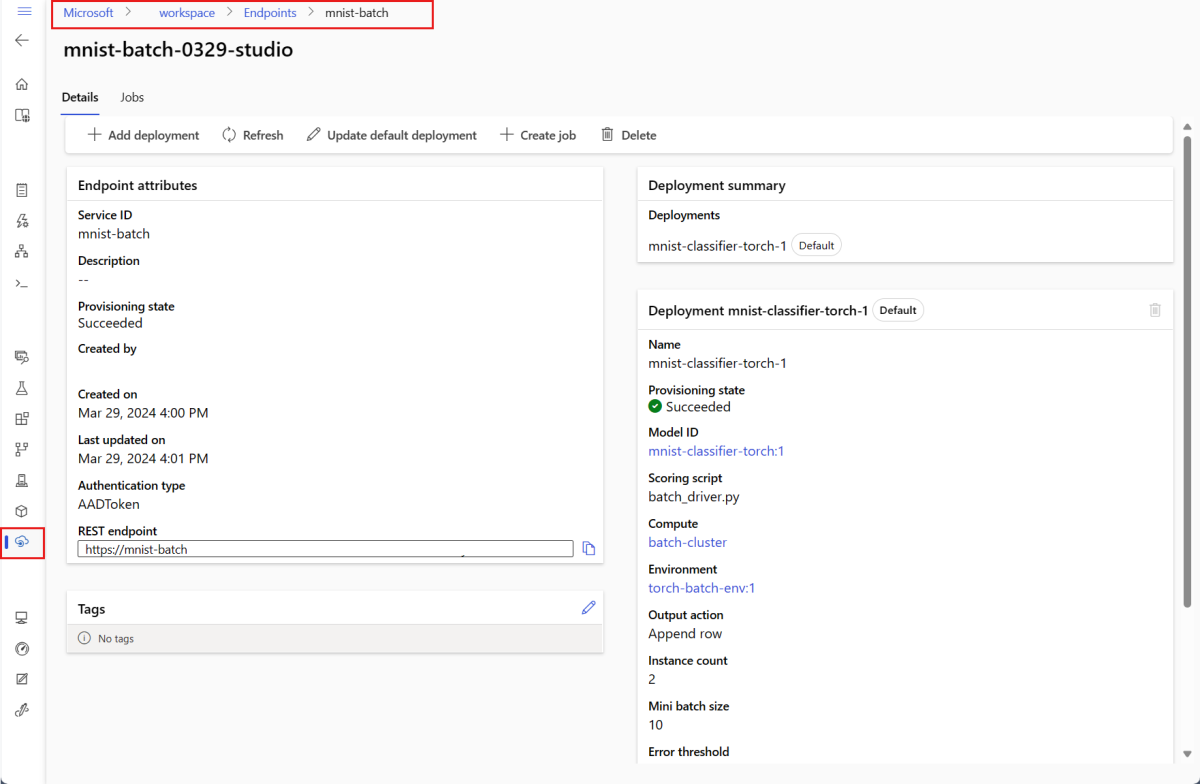
Menjalankan titik akhir batch dan mengakses hasil
Memanggil titik akhir batch memicu pekerjaan penilaian batch. Pekerjaan name dikembalikan dari respons pemanggilan dan dapat digunakan untuk melacak kemajuan penilaian batch. Saat menjalankan model untuk penilaian di titik akhir batch, Anda perlu menentukan jalur ke data input sehingga titik akhir dapat menemukan data yang ingin Anda nilai. Contoh berikut menunjukkan cara memulai pekerjaan baru melalui data sampel himpunan data MNIST yang disimpan di Akun Azure Storage.
Anda dapat menjalankan dan memanggil titik akhir batch menggunakan Titik akhir Azure CLI, Azure Pembelajaran Mesin SDK, atau REST. Untuk detail selengkapnya tentang opsi ini, lihat Membuat pekerjaan dan memasukkan data untuk titik akhir batch.
Catatan
Bagaimana cara kerja paralelisasi?
Penyebaran batch mendistribusikan pekerjaan di tingkat file, yang berarti bahwa folder yang berisi 100 file dengan batch mini 10 file akan menghasilkan 10 batch masing-masing 10 file. Perhatikan bahwa ini terjadi terlepas dari ukuran file yang terlibat. Jika file Anda terlalu besar untuk diproses dalam batch mini besar, kami sarankan Anda membagi file menjadi file yang lebih kecil untuk mencapai tingkat paralelisme yang lebih tinggi atau Anda mengurangi jumlah file per mini-batch. Saat ini, penyebaran batch tidak dapat memperhitungkan penyimpangan dalam distribusi ukuran file.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)



Titik akhir batch mendukung pembacaan file atau folder yang terletak di lokasi yang berbeda. Untuk mempelajari selengkapnya tentang jenis yang didukung dan cara menentukannya, lihat Mengakses data dari pekerjaan titik akhir batch.
Memantau kemajuan eksekusi pekerjaan batch
Pekerjaan penilaian batch biasanya membutuhkan waktu untuk memproses seluruh rangkaian input.
Kode berikut memeriksa status pekerjaan dan menghasilkan tautan ke studio Azure Pembelajaran Mesin untuk detail lebih lanjut.
az ml job show -n $JOB_NAME --web

Periksa hasil penilaian batch
Output pekerjaan disimpan dalam penyimpanan cloud, baik di penyimpanan blob default ruang kerja, atau penyimpanan yang Anda tentukan. Untuk mempelajari cara mengubah default, lihat Mengonfigurasi lokasi output. Langkah-langkah berikut memungkinkan Anda melihat hasil penilaian di Azure Storage Explorer saat pekerjaan selesai:
Jalankan kode berikut untuk membuka pekerjaan penilaian batch di studio Azure Pembelajaran Mesin. Tautan studio pekerjaan juga disertakan dalam respons
invoke, sebagai nilaiinteractionEndpoints.Studio.endpoint.az ml job show -n $JOB_NAME --webPada grafik pekerjaan, pilih langkah
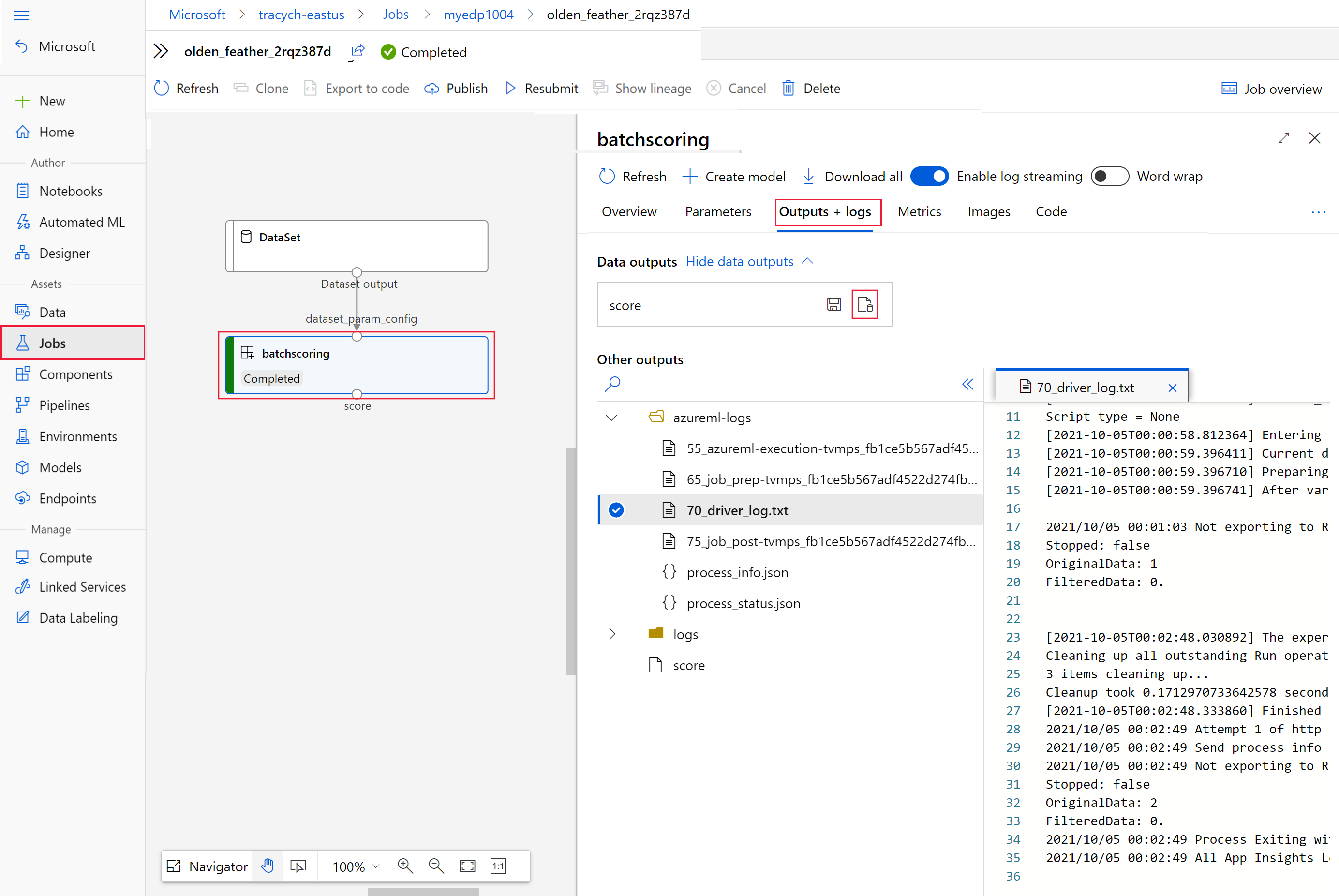
batchscoring.Pilih tab Output + log, lalu pilih Tampilkan output data.
Dari Output data, pilih ikon untuk membuka Penjelajah Penyimpanan.
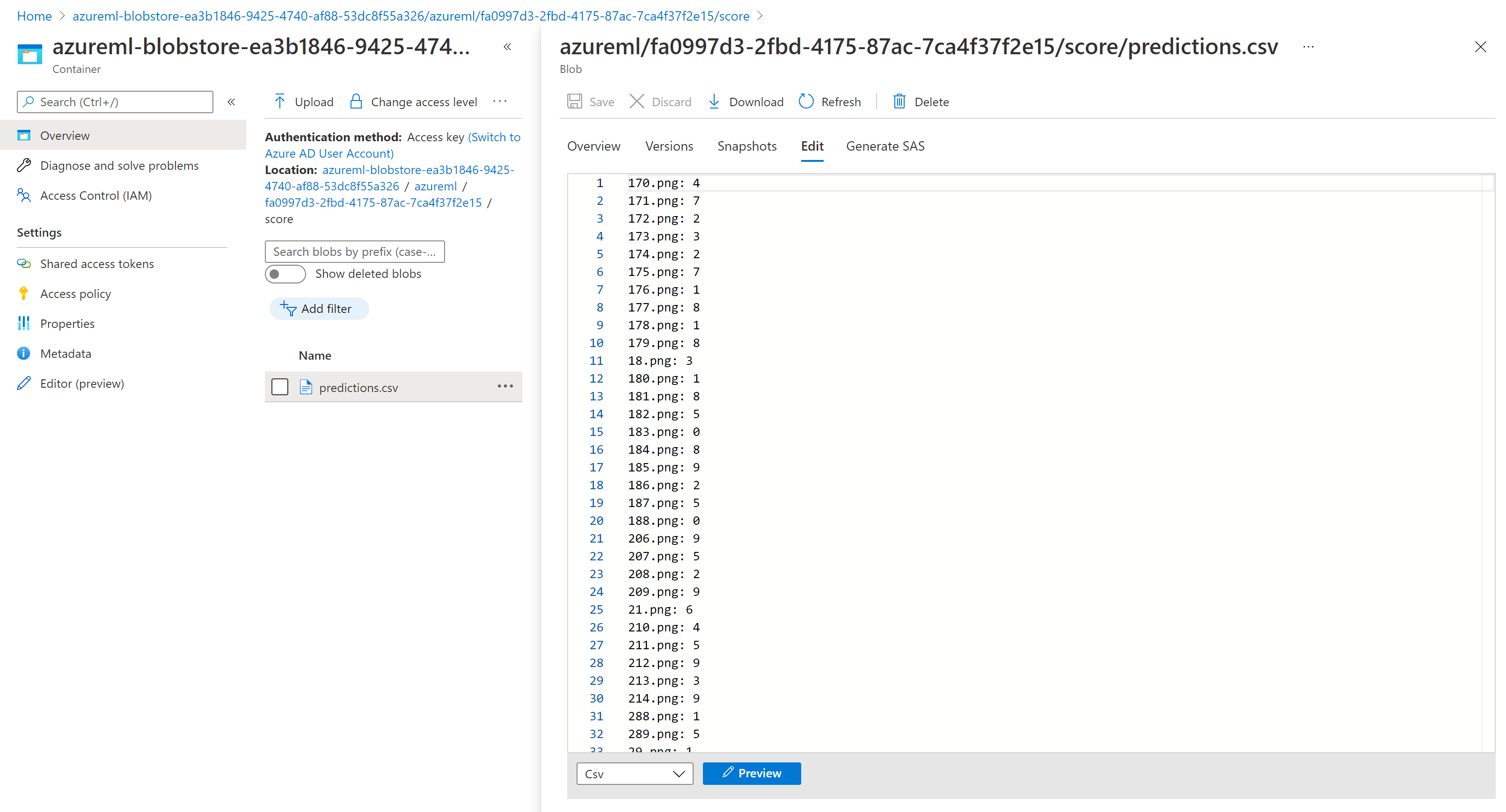
Hasil penilaian di Penjelajah Penyimpanan mirip dengan halaman sampel berikut:


Mengonfigurasikan lokasi output
Secara default, hasil penilaian batch disimpan di penyimpanan blob default ruang kerja dalam folder bernama berdasarkan nama pekerjaan (GUID yang dihasilkan sistem). Anda dapat mengonfigurasi tempat untuk menyimpan output penilaian saat Anda memanggil titik akhir batch.
Gunakan output-path untuk mengonfigurasi folder apa pun di datastore terdaftar Azure Machine Learning. Sintaks untuk --output-path sama seperti --input saat Anda menentukan folder, yaitu azureml://datastores/<datastore-name>/paths/<path-on-datastore>/. Gunakan --set output_file_name=<your-file-name> untuk mengonfigurasi nama file output baru.
OUTPUT_FILE_NAME=predictions_`echo $RANDOM`.csv
OUTPUT_PATH="azureml://datastores/workspaceblobstore/paths/$ENDPOINT_NAME"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --output-path $OUTPUT_PATH --set output_file_name=$OUTPUT_FILE_NAME --query name -o tsv)

Peringatan
Anda harus menggunakan lokasi output yang unik. Jika file output ada, maka tugas penilaian batch akan gagal.
Penting
Tidak seperti input, output hanya dapat disimpan di penyimpanan data Azure Pembelajaran Mesin yang berjalan pada akun penyimpanan blob.
Timpa konfigurasi penyebaran untuk setiap pekerjaan
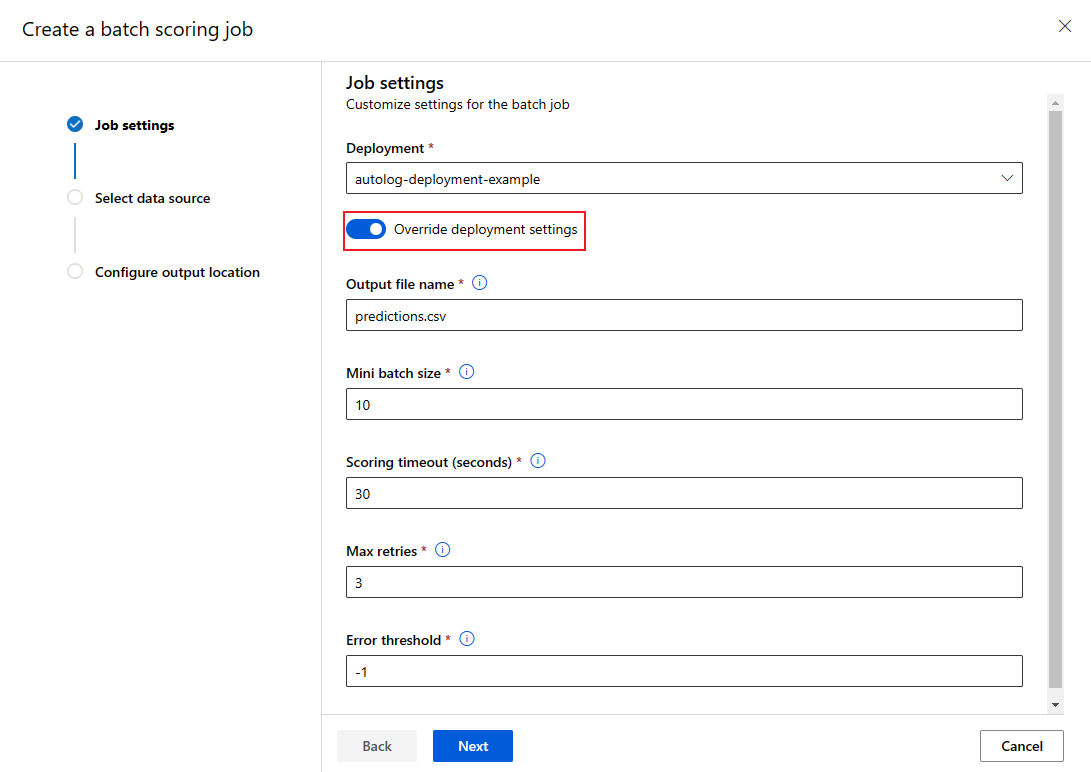
Saat Anda memanggil titik akhir batch, beberapa pengaturan dapat ditimpa untuk memanfaatkan sumber daya komputasi dengan sebaik-baiknya dan untuk meningkatkan performa. Pengaturan berikut dapat dikonfigurasi berdasarkan per pekerjaan:
- Jumlah instans: gunakan pengaturan ini untuk menimpa jumlah instans yang akan diminta dari kluster komputasi. Misalnya, untuk volume input data yang lebih besar, Anda mungkin ingin menggunakan lebih banyak instans untuk mempercepat penilaian batch dari ujung ke ujung.
- Ukuran batch mini: gunakan pengaturan ini untuk menimpa jumlah file yang akan disertakan dalam setiap batch mini. Jumlah batch mini diputuskan oleh jumlah total file input dan ukuran batch mini. Ukuran batch mini yang lebih kecil menghasilkan lebih banyak batch mini. Batch mini dapat dijalankan secara paralel, tetapi mungkin ada penjadwalan tambahan dan atashulu pemanggilan.
- Pengaturan lain, seperti percobaan ulang maks, batas waktu, dan ambang kesalahan dapat ditimpa. Pengaturan ini dapat memengaruhi waktu penilaian batch end-to-end untuk beban kerja yang berbeda.
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --mini-batch-size 20 --instance-count 5 --query name -o tsv)
Menambahkan penyebaran ke titik akhir
Setelah Anda memiliki titik akhir batch dengan penyebaran, Anda dapat terus menyempurnakan model Anda dan menambahkan penyebaran baru. Titik akhir batch akan terus melayani penyebaran default saat Anda mengembangkan dan menyebarkan model baru di bawah titik akhir yang sama. Penyebaran tidak memengaruhi satu dengan yang lain.
Dalam contoh ini, Anda menambahkan penyebaran kedua yang menggunakan model yang dibangun dengan Keras dan TensorFlow untuk menyelesaikan masalah MNIST yang sama.
Menambahkan penyebaran kedua
Buat lingkungan tempat penyebaran batch Anda akan berjalan. Sertakan dalam lingkungan dependensi apa pun yang diperlukan kode Anda untuk berjalan. Anda juga perlu menambahkan pustaka
azureml-core, karena diperlukan agar penyebaran batch berfungsi. Definisi lingkungan berikut memiliki pustaka yang diperlukan untuk menjalankan model dengan TensorFlow.Definisi lingkungan disertakan dalam definisi penyebaran itu sendiri sebagai lingkungan anonim.
environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlFile conda yang digunakan terlihat sebagai berikut:
deployment-keras/environment/conda.yaml
name: tensorflow-env channels: - conda-forge dependencies: - python=3.8.5 - pip - pip: - pandas - tensorflow - pillow - azureml-core - azureml-dataset-runtime[fuse]Buat skrip penilaian untuk model:
deployment-keras/code/batch_driver.py
import os import numpy as np import pandas as pd import tensorflow as tf from typing import List from os.path import basename from PIL import Image from tensorflow.keras.models import load_model def init(): global model # AZUREML_MODEL_DIR is an environment variable created during deployment model_path = os.path.join(os.environ["AZUREML_MODEL_DIR"], "model") # load the model model = load_model(model_path) def run(mini_batch: List[str]) -> pd.DataFrame: print(f"Executing run method over batch of {len(mini_batch)} files.") results = [] for image_path in mini_batch: data = Image.open(image_path) data = np.array(data) data_batch = tf.expand_dims(data, axis=0) # perform inference pred = model.predict(data_batch) # Compute probabilities, classes and labels pred_prob = tf.math.reduce_max(tf.math.softmax(pred, axis=-1)).numpy() pred_class = tf.math.argmax(pred, axis=-1).numpy() results.append( { "file": basename(image_path), "class": pred_class[0], "probability": pred_prob, } ) return pd.DataFrame(results)Membuat definisi penyebaran
deployment-keras/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json name: mnist-keras-dpl description: A deployment using Keras with TensorFlow to solve the MNIST classification dataset. endpoint_name: mnist-batch type: model model: name: mnist-classifier-keras path: model code_configuration: code: code scoring_script: batch_driver.py environment: name: batch-tensorflow-py38 image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml compute: azureml:batch-cluster resources: instance_count: 1 settings: max_concurrency_per_instance: 2 mini_batch_size: 10 output_action: append_row output_file_name: predictions.csvBuat penyebaran:
Jalankan kode berikut untuk membuat penyebaran batch di bawah titik akhir batch dan atur sebagai penyebaran default.
az ml batch-deployment create --file deployment-keras/deployment.yml --endpoint-name $ENDPOINT_NAMETip
Parameter
--set-defaulthilang dalam kasus ini. Sebagai praktik terbaik untuk skenario produksi, buat penyebaran baru tanpa mengaturnya sebagai default. Kemudian verifikasi, dan perbarui penyebaran default nanti.
Uji penyebaran batch non-default
Untuk menguji penyebaran non-default baru, Anda perlu mengetahui nama penyebaran yang ingin Anda jalankan.
DEPLOYMENT_NAME="mnist-keras-dpl"
JOB_NAME=$(az ml batch-endpoint invoke --name $ENDPOINT_NAME --deployment-name $DEPLOYMENT_NAME --input https://azuremlexampledata.blob.core.windows.net/data/mnist/sample --input-type uri_folder --query name -o tsv)
Pemberitahuan --deployment-name digunakan untuk menentukan penyebaran yang akan dijalankan. Parameter ini memungkinkan Anda untuk invoke penyebaran non-default tanpa memperbarui penyebaran default titik akhir batch.
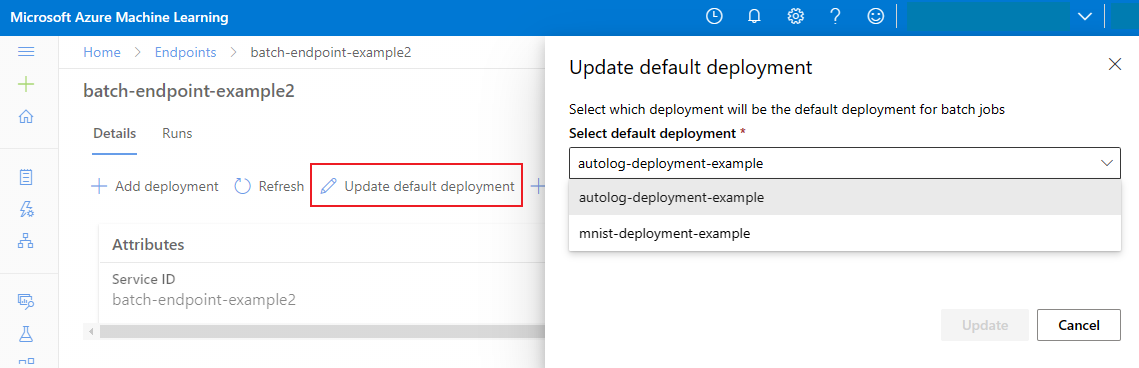
Perbarui penyebaran batch default
Meskipun Anda dapat memanggil penyebaran tertentu di dalam titik akhir, Anda biasanya ingin memanggil titik akhir itu sendiri dan membiarkan titik akhir memutuskan penyebaran mana yang akan digunakan—penyebaran default. Anda dapat mengubah penyebaran default (dan akibatnya, mengubah model yang melayani penyebaran) tanpa mengubah kontrak Anda dengan pengguna yang memanggil titik akhir. Gunakan kode berikut untuk memperbarui penyebaran default:
az ml batch-endpoint update --name $ENDPOINT_NAME --set defaults.deployment_name=$DEPLOYMENT_NAME
Hapus titik akhir batch dan penyebaran
Jika Anda tidak akan menggunakan penyebaran batch lama, hapus dengan menjalankan kode berikut. --yes digunakan untuk mengonfirmasi penghapusan.
az ml batch-deployment delete --name mnist-torch-dpl --endpoint-name $ENDPOINT_NAME --yes
Jalankan kode berikut untuk menghapus titik akhir batch dan semua penyebaran yang mendasarinya. Pekerjaan penilaian batch tidak akan dihapus.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes
Konten terkait
- Mengakses data dari pekerjaan titik akhir batch.
- Autentikasi pada titik akhir batch.
- Isolasi jaringan di titik akhir batch.
- Pemecahan masalah titik akhir batch.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk