Menyiapkan proyek pelabelan teks dan mengekspor label
Di Azure Pembelajaran Mesin, pelajari cara membuat dan menjalankan proyek pelabelan data untuk memberi label data teks. Tentukan label tunggal atau beberapa label untuk diterapkan ke setiap item teks.
Anda juga dapat menggunakan alat pelabelan data di Azure Pembelajaran Mesin untuk membuat proyek pelabelan gambar.
Kemampuan pelabelan teks
Pelabelan data Azure Pembelajaran Mesin adalah alat yang dapat Anda gunakan untuk membuat, mengelola, dan memantau proyek pelabelan data. Gunakan untuk:
- Koordinasikan data, label, dan anggota tim untuk mengelola tugas pelabelan secara efisien.
- Lacak kemajuan dan pertahankan antrean tugas pelabelan yang tidak lengkap.
- Mulai dan hentikan proyek, dan kontrol kemajuan pelabelan.
- Tinjau dan ekspor data berlabel sebagai himpunan data Azure Pembelajaran Mesin.
Penting
Data teks yang Anda gunakan di alat pelabelan data Azure Pembelajaran Mesin harus tersedia di datastore Azure Blob Storage. Jika Anda tidak memiliki datastore yang sudah ada, Anda dapat mengunggah file data ke datastore baru saat membuat proyek.
Format data ini tersedia untuk data teks:
- .txt: Setiap file mewakili satu item yang akan diberi label.
- .csv atau .tsv: Setiap baris mewakili satu item yang disajikan kepada pelabel. Anda memutuskan kolom mana yang dapat dilihat pelabel saat memberi label pada baris.
Prasyarat
Anda menggunakan item ini untuk menyiapkan pelabelan teks di Azure Pembelajaran Mesin:
- Data yang ingin Anda beri label, baik di file lokal atau di Azure Blob Storage.
- Kumpulan label yang ingin diterapkan.
- Petunjuk pelabelan.
- Langganan Azure. Jika Anda tidak memiliki langganan Azure, buat akun gratis sebelum Anda memulai.
- Ruang kerja Azure Machine Learning. Lihat Membuat ruang kerja Azure Machine Learning.
Buat proyek pelabelan teks
Proyek pelabelan dikelola di Azure Pembelajaran Mesin. Gunakan halaman Pelabelan Data di Pembelajaran Mesin untuk mengelola proyek Anda.
Jika data Anda sudah ada di Azure Blob Storage, pastikan data tersebut tersedia sebagai datastore sebelum Anda membuat proyek pelabelan.
Untuk membuat proyek, pilih Tambahkan proyek.
Untuk Nama proyek, masukkan nama proyek.
Anda tidak dapat menggunakan kembali nama proyek, meskipun Anda menghapus proyek.
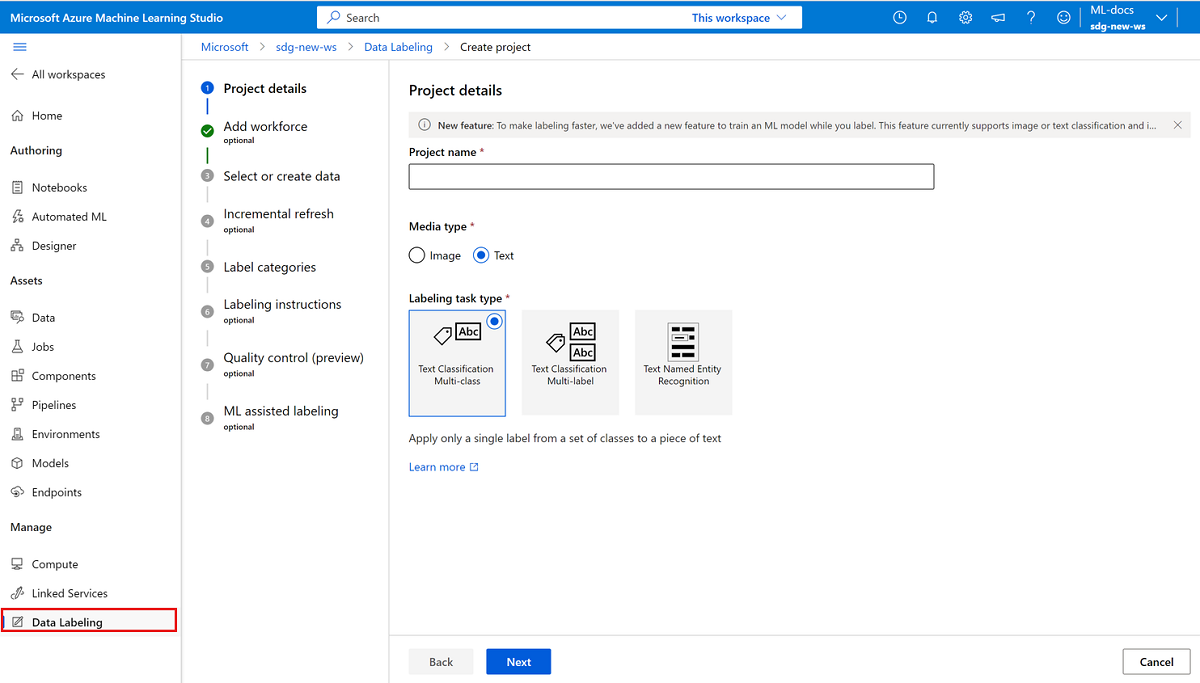
Untuk membuat proyek pelabelan teks, untuk Jenis media, pilih Teks.
Untuk Jenis tugas Pelabelan, pilih opsi untuk skenario Anda:
- Untuk menerapkan hanya satu label ke setiap bagian teks dari sekumpulan label, pilih Klasifikasi Teks Multi-kelas.
- Untuk menerapkan satu atau beberapa label ke setiap bagian teks dari sekumpulan label, pilih Multi-label Klasifikasi Teks.
- Untuk menerapkan label ke kata teks individual atau ke beberapa kata teks di setiap entri, pilih Pengenalan Entitas Teks Bernama.
Untuk melanjutkan, klik Berikutnya.
Menambahkan tenaga kerja (opsional)
Pilih Gunakan perusahaan pelabelan vendor dari Marketplace Azure hanya jika Anda telah melibatkan perusahaan pelabelan data dari Marketplace Azure. Kemudian pilih vendor. Jika vendor Anda tidak muncul dalam daftar, kosongkan opsi ini.
Pastikan Anda terlebih dahulu menghubungi vendor dan menandatangani kontrak. Untuk informasi selengkapnya, lihat Bekerja dengan perusahaan vendor pelabelan data (pratinjau).
Untuk melanjutkan, klik Berikutnya.
Pilih atau buat himpunan data
Jika Anda sudah membuat himpunan data yang berisi data Anda, pilih di menu dropdown Pilih himpunan data yang sudah ada. Anda juga dapat memilih Buat himpunan data untuk menggunakan datastore Azure yang sudah ada atau untuk mengunggah file lokal.
Catatan
Proyek tidak boleh berisi lebih dari 500.000 file. Jika himpunan data Anda melebihi jumlah file ini, hanya 500.000 file pertama yang dimuat.
Membuat himpunan data dari penyimpanan data Azure
Dalam banyak kasus, Anda dapat mengunggah file lokal. Namun, Azure Storage Explorer menyediakan cara yang lebih cepat dan lebih kuat untuk mentransfer sejumlah besar data. Kami menyarankan Storage Explorer sebagai cara default untuk memindahkan file.
Untuk membuat himpunan data dari data yang sudah disimpan di Blob Storage:
- Pilih Buat.
- Untuk Nama, masukkan nama untuk himpunan data Anda. Secara opsional, masukkan deskripsi.
- Pilih jenis Himpunan Data:
- Jika Anda menggunakan file .csv atau .tsv dan setiap baris berisi respons, pilih Tabular.
- Jika Anda menggunakan file .txt terpisah untuk setiap respons, pilih File.
- Pilih Selanjutnya.
- Pilih Dari penyimpanan Azure, lalu pilih Berikutnya.
- Pilih datastore, lalu pilih Berikutnya.
- Jika data Anda berada di subfolder dalam Blob Storage, pilih Telusuri untuk memilih jalur.
- Untuk menyertakan semua file dalam subfolder jalur yang dipilih, tambahkan
/**ke jalur. - Untuk menyertakan semua data dalam kontainer saat ini dan subfoldernya, tambahkan
**/*.*ke jalur .
- Untuk menyertakan semua file dalam subfolder jalur yang dipilih, tambahkan
- Pilih Buat.
- Pilih aset data yang Anda buat.
Membuat himpunan data dari data yang diunggah
Untuk mengunggah data secara langsung:
- Pilih Buat.
- Untuk Nama, masukkan nama untuk himpunan data Anda. Secara opsional, masukkan deskripsi.
- Pilih jenis Himpunan Data:
- Jika Anda menggunakan file .csv atau .tsv dan setiap baris berisi respons, pilih Tabular.
- Jika Anda menggunakan file .txt terpisah untuk setiap respons, pilih File.
- Pilih Selanjutnya.
- Pilih Dari file lokal, lalu pilih Berikutnya.
- (Opsional) Pilih datastore. Pengunggahan default ke penyimpanan blob default (workspaceblobstore) untuk ruang kerja Pembelajaran Mesin Anda.
- Pilih Selanjutnya.
- Pilih Unggah>Unggah file atau Unggah folder unggah>untuk memilih file atau folder lokal yang akan diunggah.
- Temukan file atau folder Anda di jendela browser, lalu pilih Buka.
- Lanjutkan untuk memilih Unggah hingga Anda menentukan semua file dan folder Anda.
- Secara opsional pilih kotak centang Timpa jika sudah ada . Verifikasi daftar file dan folder.
- Pilih Selanjutnya.
- Konfirmasi detailnya. Pilih Kembali untuk mengubah pengaturan, atau pilih Buat untuk membuat himpunan data.
- Terakhir, pilih aset data yang Anda buat.
Mengonfigurasi refresh inkremental
Jika Anda berencana untuk menambahkan file data baru ke himpunan data Anda, gunakan refresh bertahap untuk menambahkan file ke proyek Anda.
Saat Aktifkan refresh bertahap pada interval reguler diatur, himpunan data dicentang secara berkala agar file baru ditambahkan ke proyek berdasarkan tingkat penyelesaian pelabelan. Pemeriksaan data baru berhenti jika proyek berisi maksimum 500.000 file.
Pilih Aktifkan refresh bertambah bertahap dengan interval reguler jika ingin proyek Anda terus memantau data baru di penyimpanan data.
Hapus pilihan jika Anda tidak ingin file baru di datastore ditambahkan secara otomatis ke proyek Anda.
Penting
Jangan membuat versi baru untuk himpunan data yang ingin Anda perbarui. Jika Anda melakukannya, pembaruan tidak akan terlihat karena proyek pelabelan data disematkan ke versi awal. Sebagai gantinya, gunakan Azure Storage Explorer untuk memodifikasi data Anda di folder yang sesuai di Blob Storage.
Selain itu, jangan hapus data. Menghapus data dari himpunan data yang digunakan proyek Anda menyebabkan kesalahan dalam proyek.
Setelah proyek dibuat, gunakan tab Detail untuk mengubah refresh bertahap, lihat stempel waktu untuk refresh terakhir, dan minta refresh data segera.
Catatan
Proyek yang menggunakan input himpunan data tabular (.csv atau .tsv) dapat menggunakan refresh bertahap. Tetapi refresh inkremental hanya menambahkan file tabular baru. Refresh tidak mengenali perubahan pada file tabular yang ada.
Tentukan kategori label
Pada halaman Kategori label , tentukan sekumpulan kelas untuk mengategorikan data Anda.
Akurasi dan kecepatan pelabel Anda dipengaruhi oleh kemampuan mereka untuk memilih di antara kelas. Misalnya, alih-alih mengeja genus dan spesies lengkap tanaman atau hewan, gunakan kode bidang atau singkat genus.
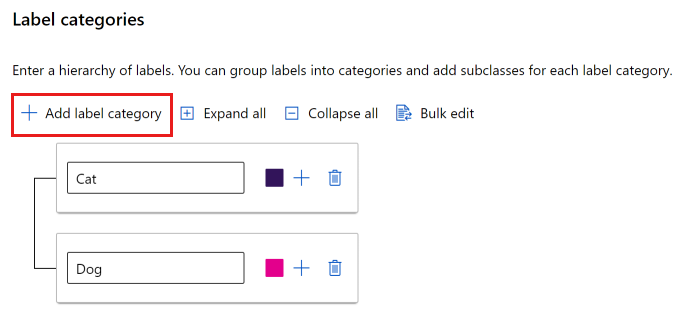
Anda dapat menggunakan daftar datar atau membuat grup label.
Untuk membuat daftar datar, pilih Tambahkan kategori label untuk membuat setiap label.
Untuk membuat label di grup yang berbeda, pilih Tambahkan kategori label untuk membuat label tingkat atas. Kemudian pilih tanda plus (+) di bawah setiap tingkat atas untuk membuat tingkat label berikutnya untuk kategori tersebut. Anda dapat membuat hingga enam tingkat untuk pengelompokan apa pun.
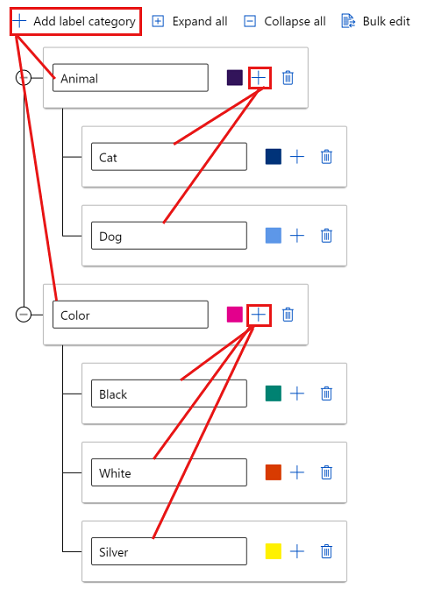
Anda dapat memilih label di tingkat apa pun selama proses pemberian tag. Misalnya, label Animal, , Animal/Cat, Animal/DogColor, Color/Black, Color/White, dan Color/Silver adalah semua pilihan yang tersedia untuk label. Dalam proyek multi-label, tidak ada persyaratan untuk memilih salah satu dari setiap kategori. Jika itu adalah niat Anda, pastikan untuk menyertakan informasi ini dalam instruksi Anda.
Menjelaskan tugas pelabelan teks
Tugas pelabelan perlu dijelaskan secara mendetail. Pada halaman Instruksi pelabelan, Anda bisa menambahkan tautan ke situs eksternal yang memiliki instruksi pelabelan, atau Anda bisa memberikan instruksi dalam kotak edit di halaman. Pertahankan petunjuk tetap berorientasi pada tugas dan sesuai untuk audiens. Pertimbangkan pertanyaan berikut:
- Apa saja label yang akan dilihat pelabel, dan bagaimana mereka akan memilih di antara mereka? Apakah ada teks referensi untuk dirujuk?
- Apa yang harus mereka lakukan jika tidak ada label yang tampaknya sesuai?
- Apa yang harus mereka lakukan jika beberapa label tampaknya sesuai?
- Ambang batas keyakinan apa yang harus mereka terapkan pada label? Apakah Anda ingin tebakan terbaik pelabel jika mereka tidak yakin?
- Apa yang harus mereka lakukan dengan objek ketertarikan yang tumpang tindih atau tertutup sebagian?
- Apa yang harus mereka lakukan jika objek ketertarikan terpotong oleh tepi gambar?
- Apa yang harus mereka lakukan jika mereka merasa melakukan kesalahan setelah mengirimkan label?
- Apa yang harus mereka lakukan jika menemukan masalah kualitas gambar, termasuk kondisi pencahayaan yang buruk, pantulan, hilangnya fokus, latar belakang yang tidak diinginkan termasuk, sudut kamera abnormal, dan sebagainya?
- Apa yang harus mereka lakukan jika beberapa peninjau memiliki pendapat yang berbeda tentang menerapkan label?
Catatan
Pelabel dapat memilih sembilan label pertama dengan menggunakan tombol angka 1 hingga 9.
Kontrol kualitas (pratinjau)
Untuk mendapatkan label yang lebih akurat, gunakan halaman Kontrol kualitas untuk mengirim setiap item ke beberapa pelabel.
Penting
Pelabelan konensus saat ini dalam pratinjau publik.
Versi pratinjau disediakan tanpa perjanjian tingkat layanan, dan tidak disarankan untuk beban kerja produksi. Fitur tertentu mungkin tidak didukung atau mungkin memiliki kemampuan terbatas.
Untuk mengetahui informasi selengkapnya, lihat Ketentuan Penggunaan Tambahan untuk Pratinjau Microsoft Azure.
Untuk meminta setiap item dikirim ke beberapa pelabel, pilih Aktifkan pelabelan konsekuensi (pratinjau). Kemudian atur nilai untuk Pelabel minimum dan Pelabel maksimum untuk menentukan berapa banyak pelabel yang akan digunakan. Pastikan Anda memiliki pelabel sebanyak yang tersedia sebagai jumlah maksimum Anda. Anda tidak dapat mengubah pengaturan ini setelah proyek dimulai.
Jika konsekuensi tercapai dari jumlah minimum pelabel, item akan diberi label. Jika konsekuensi tidak tercapai, item dikirim ke lebih banyak pelabel. Jika tidak ada konensi setelah item masuk ke jumlah maksimum pelabel, statusnya adalah Perlu Ditinjau, dan pemilik proyek bertanggung jawab untuk memberi label item.
Menggunakan pelabelan data terbantu ML
Untuk mempercepat tugas pelabelan, halaman pelabelan yang dibantu ML dapat memicu model pembelajaran mesin otomatis. Pelabelan yang dibantu pembelajaran mesin (ML) dapat menangani input data teks file (.txt) dan tabular (.csv).
Untuk menggunakan pelabelan yang didukung ML:
- Pilih Aktifkan pelabelan yang didukung ML.
- Pilih Bahasa himpunan data untuk proyek. Daftar ini memperlihatkan semua bahasa yang didukung Kelas TextDNNLanguages.
- Tentukan target komputasi yang digunakan. Jika Anda tidak memiliki target komputasi di ruang kerja Anda, langkah ini akan membuat kluster komputasi dan menambahkannya ke ruang kerja Anda. Kluster dibuat dengan minimal nol simpul, dan tidak dikenakan biaya apa pun saat tidak digunakan.
Informasi selengkapnya tentang pelabelan yang dibantu ML
Pada awal proyek pelabelan Anda, item diacak ke dalam urutan acak untuk mengurangi potensi bias. Namun, model terlatih mencerminkan bias apa pun yang ada dalam himpunan data. Misalnya, jika 80 persen item Anda berasal dari satu kelas, maka sekitar 80 persen dari data yang digunakan untuk melatih model mendarat di kelas tersebut.
Untuk melatih model DNN teks yang digunakan pelabelan yang dibantu ML, teks input per contoh pelatihan dibatasi hingga sekitar 128 kata pertama dalam dokumen. Untuk input tabular, semua kolom teks digabungkan sebelum batas ini diterapkan. Batas praktis ini memungkinkan pelatihan model selesai dalam jumlah waktu yang wajar. Teks aktual dalam dokumen (untuk input file) atau set kolom teks (untuk input tabular) dapat melebihi 128 kata. Batas hanya berkaitan dengan apa yang digunakan secara internal model selama proses pelatihan.
Jumlah item berlabel yang diperlukan untuk memulai pelabelan terbantu bukanlah angka tetap. Jumlah ini dapat bervariasi secara signifikan dari satu proyek pelabelan ke proyek pelabelan lainnya. Varians tergantung pada banyak faktor, termasuk jumlah kelas label dan distribusi label.
Saat Anda menggunakan pelabelan konensus, label konensus digunakan untuk pelatihan.
Karena label akhir masih mengandalkan input dari pelabel, teknologi ini terkadang disebut pelabelan human-in-the-loop .
Catatan
Pelabelan data yang dibantu ML tidak mendukung akun penyimpanan default yang diamankan di belakang jaringan virtual. Anda harus menggunakan akun penyimpanan non-default untuk pelabelan data yang dibantu ML. Akun penyimpanan non-default dapat diamankan di belakang jaringan virtual.
Pra-pelabelan
Setelah Anda mengirimkan label yang cukup untuk pelatihan, model terlatih digunakan untuk memprediksi tag. Pelabel sekarang melihat halaman yang memperlihatkan label yang diprediksi sudah ada di setiap item. Tugas ini kemudian melibatkan peninjauan prediksi ini dan memperbaiki item yang salah label sebelum pengiriman halaman.
Setelah Anda melatih model pembelajaran mesin pada data berlabel manual Anda, model dievaluasi pada serangkaian pengujian item berlabel manual. Evaluasi membantu menentukan akurasi model pada ambang keyakinan yang berbeda. Proses evaluasi menetapkan ambang batas keyakinan di mana model cukup akurat untuk menampilkan pra-label. Model kemudian dievaluasi terhadap data yang tidak berlabel. Item yang memiliki prediksi yang lebih yakin daripada ambang batas digunakan untuk pra-pelabelan.
Menginisialisasi proyek pelabelan teks
Setelah proyek pelabelan diinisialisasi, beberapa aspek proyek tidak dapat diubah. Anda tidak bisa mengubah jenis tugas atau himpunan data. Anda dapat mengubah label dan URL untuk deskripsi tugas. Tinjau pengaturan secara seksama sebelum membuat proyek. Setelah mengirimkan proyek, Anda kembali ke halaman gambaran umum Pelabelan Data, yang memperlihatkan proyek sebagai Inisialisasi.
Catatan
Halaman ini mungkin tidak otomatis di-refresh. Setelah jeda, refresh halaman secara manual untuk melihat status proyek sebagai Dibuat.
Pemecahan Masalah
Untuk masalah dalam membuat proyek atau mengakses data, lihat Memecahkan masalah pelabelan data.