Menyebarkan model pembelajaran mesin ke Azure
BERLAKU UNTUK: Ekstensi ml Azure CLI v1Python SDK azureml v1
Ekstensi ml Azure CLI v1Python SDK azureml v1
Pelajari cara menyebarkan pembelajaran mesin atau model pembelajaran mendalam sebagai layanan web di cloud Azure.
Catatan
Azure Pembelajaran Mesin Endpoints (v2) memberikan pengalaman penyebaran yang lebih baik dan lebih sederhana. Titik akhir mendukung skenario inferensi real-time dan batch. Titik akhir menyediakan antarmuka terpadu untuk menjalankan dan mengelola penyebaran model di seluruh jenis komputasi. Lihat Apa itu titik akhir Azure Pembelajaran Mesin?.
Alur kerja untuk menyebarkan model
Alur kerjanya mirip di mana pun Anda menyebarkan model Anda:
- Daftarkan modelnya.
- Siapkan skrip entri.
- Siapkan konfigurasi inferensi.
- Sebarkan model secara lokal untuk memastikan semuanya berfungsi.
- Pilih target komputasi.
- Sebarkan model ke cloud.
- Uji layanan web yang dihasilkan.
Untuk informasi selengkapnya tentang konsep yang terlibat dalam alur kerja penyebaran pembelajaran mesin, lihat Mengelola, menyebarkan, dan memantau model dengan Pembelajaran Mesin Microsoft Azure.
Prasyarat
BERLAKU UNTUK: Ekstensi ml Azure CLI v1
Penting
Beberapa perintah CLI Azure dalam artikel ini menggunakan ekstensi azure-cli-ml, atau v1, untuk Azure Machine Learning. Dukungan untuk ekstensi v1 akan berakhir pada 30 September 2025. Anda dapat memasang dan menggunakan ekstensi v1 hingga tanggal tersebut.
Kami menyarankan agar Anda beralih ke ekstensi ml, atau v2 sebelum 30 September 2025. Untuk informasi selengkapnya mengenai ekstensi v2, lihat Ekstensi Azure ML CLI dan Python SDK v2.
- Ruang kerja Azure Machine Learning. Untuk informasi selengkapnya, lihat Membuat sumber daya ruang kerja.
- Sebuah model. Contoh dalam artikel ini menggunakan model yang sudah dilatih.
- Komputer yang dapat menjalankan Docker, seperti instans komputasi.
Menyambungkan ke ruang kerja Anda
BERLAKU UNTUK: Ekstensi ml Azure CLI v1
Untuk melihat ruang kerja yang dapat Anda akses, gunakan perintah berikut:
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
Mendaftarkan model
Situasi umum untuk layanan pembelajaran mesin yang disebarkan adalah Anda memerlukan komponen berikut:
- Sumber daya yang mewakili model tertentu yang ingin Anda sebarkan (misalnya: file model pytorch).
- Kode yang akan Anda jalankan dalam layanan yang menjalankan model pada input tertentu.
Pembelajaran Mesin Microsoft Azure memungkinkan Anda memisahkan penyebaran menjadi dua komponen terpisah, sehingga Anda dapat menyimpan kode yang sama, tetapi hanya memperbarui model. Kami mendefinisikan mekanisme yang mana Anda mengunggah model secara terpisah dari kode Anda sebagai "mendaftarkan model".
Saat Anda mendaftarkan model, kami mengunggah model ke cloud (di akun penyimpanan default ruang kerja Anda), lalu memasangnya ke komputasi yang sama tempat layanan web Anda berjalan.
Contoh berikut menunjukkan cara mendaftarkan model.
Penting
Anda hanya boleh menggunakan model yang Anda buat atau peroleh dari sumber tepercaya. Anda harus memperlakukan model berseri sebagai kode, karena kerentanan keamanan telah ditemukan dalam sejumlah format yang populer. Selain itu, model mungkin sengaja dilatih dengan niat jahat untuk memberikan output yang tidak netral atau tidak akurat.
BERLAKU UNTUK: Ekstensi ml Azure CLI v1
Perintah berikut mengunduh model, kemudian mendaftarkannya ke ruang kerja Azure Machine Learning Anda:
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
Atur -p ke jalur folder atau file yang ingin Anda daftarkan.
Untuk mendapatkan informasi selengkapnya tentang az ml model register, lihat dokumentasi referensi.
Mendaftarkan model dari pekerjaan pelatihan Azure Pembelajaran Mesin
Jika Anda perlu mendaftarkan model yang dibuat sebelumnya melalui pekerjaan pelatihan Azure Machine Learning, Anda dapat menentukan eksperimen, eksekusi, dan jalur ke model:
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
Parameter --asset-path mengacu pada lokasi cloud model. Dalam contoh ini, jalur dari satu file digunakan. Untuk menyertakan beberapa file dalam pendaftaran model, atur --asset-path ke jalur folder yang berisi file.
Untuk mendapatkan informasi selengkapnya tentang az ml model register, lihat dokumentasi referensi.
Catatan
Anda juga dapat mendaftarkan model dari file lokal melalui portal UI Ruang Kerja.
Saat ini, ada dua opsi untuk mengunggah file model lokal di UI:
- Dari file lokal, yang akan mendaftarkan model v2.
- Dari file lokal (berdasarkan kerangka kerja), yang akan mendaftarkan model v1.
Perhatikan bahwa hanya model yang terdaftar melalui pintu masuk Dari file lokal (berdasarkan kerangka kerja) (yang dikenal sebagai model v1) yang dapat disebarkan sebagai layanan web menggunakan SDKv1/CLIv1.
Menentukan skrip entri dummy
Skrip entri menerima data yang dikirimkan ke layanan web yang disebarkan dan meneruskannya ke model. Kemudian mengembalikan respons model ke klien. Skrip khusus untuk model Anda. Skrip entri harus memahami data yang diharapkan dan dimunculkan oleh model.
Dua hal yang perlu Anda capai dalam skrip entri adalah:
- Memuat model Anda (menggunakan fungsi yang disebut
init()) - Menjalankan model Anda pada data input (menggunakan fungsi yang disebut
run())
Untuk penyebaran awal Anda, gunakan skrip entri contoh yang mencetak data yang diterimanya.
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
Simpan file ini sebagai echo_score.py di dalam direktori bernama source_dir. Skrip dummy ini mengembalikan data yang Anda kirim, sehingga model tidak digunakan. Tetapi, hal ini berguna untuk menguji apakah skrip penilaian berjalan.
Menentukan konfigurasi inferensi
Konfigurasi inferensi menjelaskan kontainer dan file Docker untuk digunakan saat menginisialisasi layanan web Anda. Semua file dalam direktori sumber Anda, termasuk subdirektori, akan di-zip dan diunggah ke cloud saat Anda menyebarkan layanan web Anda.
Konfigurasi inferensi di bawah ini menetapkan bahwa penyebaran pembelajaran mesin akan menggunakan file echo_score.py dalam direktori ./source_dir untuk memproses permintaan masuk dan bahwa ia akan menggunakan gambar Docker dengan paket Python yang ditentukan di lingkungan project_environment.
Anda dapat menggunakan lingkungan yang dikumpulkan Azure Machine Learning sebagai gambar Docker dasar saat membuat lingkungan proyek Anda. Kami akan menginstal dependensi yang diperlukan di atas dan menyimpan gambar Docker yang dihasilkan ke dalam repositori yang terkait dengan ruang kerja Anda.
Catatan
Unggahan direktori sumber inferensi Azure Machine Learning tidak mematuhi .gitignore atau .amlignore
BERLAKU UNTUK: Ekstensi ml Azure CLI v1
Konfigurasi inferensi minimal dapat ditulis sebagai:
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
Simpan berkas ini dengan nama dummyinferenceconfig.json.
Lihat artikel ini untuk diskusi yang lebih menyeluruh tentang konfigurasi inferensi.
Menentukan konfigurasi penyebaran
Konfigurasi penyebaran menentukan jumlah memori dan core yang dibutuhkan layanan web Anda agar dapat dijalankan. Konfigurasi ini juga menyediakan detail konfigurasi dari layanan web yang mendasarinya. Misalnya, konfigurasi penyebaran memungkinkan Anda menentukan bahwa layanan Anda memerlukan 2 gigabyte memori, 2 inti CPU, 1 inti GPU, dan Anda ingin penskalaan otomatis diaktifkan.
Opsi yang tersedia untuk konfigurasi penyebaran berbeda tergantung pada target komputasi yang Anda pilih. Dalam penyebaran lokal, yang dapat Anda tentukan adalah port mana layanan web Anda akan dilayani.
BERLAKU UNTUK: Ekstensi ml Azure CLI v1
Entri dalam dokumen deploymentconfig.json dipetakan ke parameter untuk LocalWebservice.deploy_configuration. Tabel berikut menjelaskan pemetaan antara entitas dalam dokumen JSON dan parameter untuk metode:
| Entitas JSON | Parameter metode | Deskripsi |
|---|---|---|
computeType |
NA | Target komputasi. Untuk target lokal, nilainya harus local. |
port |
port |
Port lokal tempat mengekspos titik akhir HTTP layanan. |
JSON ini adalah contoh konfigurasi penyebaran untuk digunakan dengan CLI:
{
"computeType": "local",
"port": 32267
}
Simpan JSON ini sebagai file yang disebut deploymentconfig.json.
Untuk mendapatkan informasi selengkapnya, lihat skema penyebaran.
Sebarkan model pembelajaran mesin Anda
Anda sekarang siap untuk menyebarkan model Anda.
BERLAKU UNTUK: Ekstensi ml Azure CLI v1
Ganti bidaf_onnx:1 dengan nama model Anda dan nomor versinya.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Menghubungi model Anda
Mari kita periksa bahwa model gema Anda berhasil disebarkan. Anda seharusnya dapat melakukan permintaan keaktifan sederhana, begitu juga dengan permintaan penilaian:
BERLAKU UNTUK: Ekstensi ml Azure CLI v1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Tentukan skrip entri
Sekarang saatnya untuk benar-benar memuat model Anda. Pertama, ubah skrip entri Anda:
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
Simpan file ini seperti score.py di dalam source_dir.
Perhatikan penggunaan variabel lingkungan AZUREML_MODEL_DIR untuk menemukan model terdaftar Anda. Sekarang setelah Anda menambahkan beberapa paket pip.
BERLAKU UNTUK: Ekstensi ml Azure CLI v1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
Simpan file ini sebagai inferenceconfig.json
Menyebarkan ulang dan menghubungi layanan Anda
Sebarkan layanan Anda lagi:
BERLAKU UNTUK: Ekstensi ml Azure CLI v1
Ganti bidaf_onnx:1 dengan nama model Anda dan nomor versinya.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Kemudian, pastikan Anda dapat mengirim permintaan posting ke layanan:
BERLAKU UNTUK: Ekstensi ml Azure CLI v1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
Pilih target komputasi
Target komputasi yang Anda gunakan untuk menghosting model Anda akan memengaruhi biaya dan ketersediaan titik akhir yang disebarkan. Gunakan tabel ini untuk memilih target komputasi yang sesuai.
| Target komputasi | Digunakan untuk | Dukungan GPU | Deskripsi |
|---|---|---|---|
| Layanan web lokal | Pengujian/debug | Gunakan untuk pengujian dan pemecahan masalah terbatas. Akselerasi perangkat keras tergantung pada penggunaan pustaka di sistem lokal. | |
| Azure Machine Learning Kubernetes | Inferensi waktu nyata | Ya | Jalankan beban kerja inferensi di cloud. |
| Azure Container Instances | Inferensi real time Direkomendasikan untuk tujuan pengembangan/pengujian saja. |
Gunakan untuk beban kerja berbasis CPU skala rendah yang membutuhkan RAM kurang dari 48 GB. Tidak mengharuskan Anda untuk mengelola kluster. Hanya cocok untuk model berukuran kurang dari 1 GB. Didukung dalam desainer. |
Catatan
Saat memilih SKU kluster, pertama-tama perbesar, lalu perkecil. Mulailah dengan komputer yang memiliki 150% RAM yang dibutuhkan model Anda, buat profil hasilnya dan temukan komputer yang memiliki performa yang Anda butuhkan. Setelah Anda mempelajarinya, tingkatkan jumlah komputer agar sesuai dengan kebutuhan Anda untuk inferensi bersamaan.
Catatan
Azure Pembelajaran Mesin Endpoints (v2) memberikan pengalaman penyebaran yang lebih baik dan lebih sederhana. Titik akhir mendukung skenario inferensi real-time dan batch. Titik akhir menyediakan antarmuka terpadu untuk menjalankan dan mengelola penyebaran model di seluruh jenis komputasi. Lihat Apa itu titik akhir Azure Pembelajaran Mesin?.
Menyebarkan ke cloud
Setelah mengonfirmasi bahwa layanan Anda berfungsi secara lokal dan memilih target komputasi jarak jauh, Anda siap untuk menyebarkan ke cloud.
Ubah konfigurasi penyebaran Anda agar sesuai dengan target komputasi yang Anda pilih, dalam hal ini Azure Container Instances:
BERLAKU UNTUK: Ekstensi ml Azure CLI v1
Opsi yang tersedia untuk konfigurasi penyebaran berbeda tergantung pada target komputasi yang Anda pilih.
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
Simpan file ini sebagai re-deploymentconfig.json.
Untuk informasi selengkapnya, lihat referensi ini.
Sebarkan layanan Anda lagi:
BERLAKU UNTUK: Ekstensi ml Azure CLI v1
Ganti bidaf_onnx:1 dengan nama model Anda dan nomor versinya.
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
Untuk melihat log layanan, gunakan perintah berikut:
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
Mengubungi layanan web jarak jauh Anda
Ketika Anda menyebarkan dari jarak jauh, mungkin autentikasi kunci Anda aktif. Contoh di bawah ini menunjukkan cara mendapatkan kunci layanan Anda dengan Python untuk membuat permintaan inferensi.
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())Lihat artikel tentang aplikasi klien untuk menggunakan layanan web untuk contoh klien lainnya dalam bahasa lain.
Cara mengonfigurasi email di studio
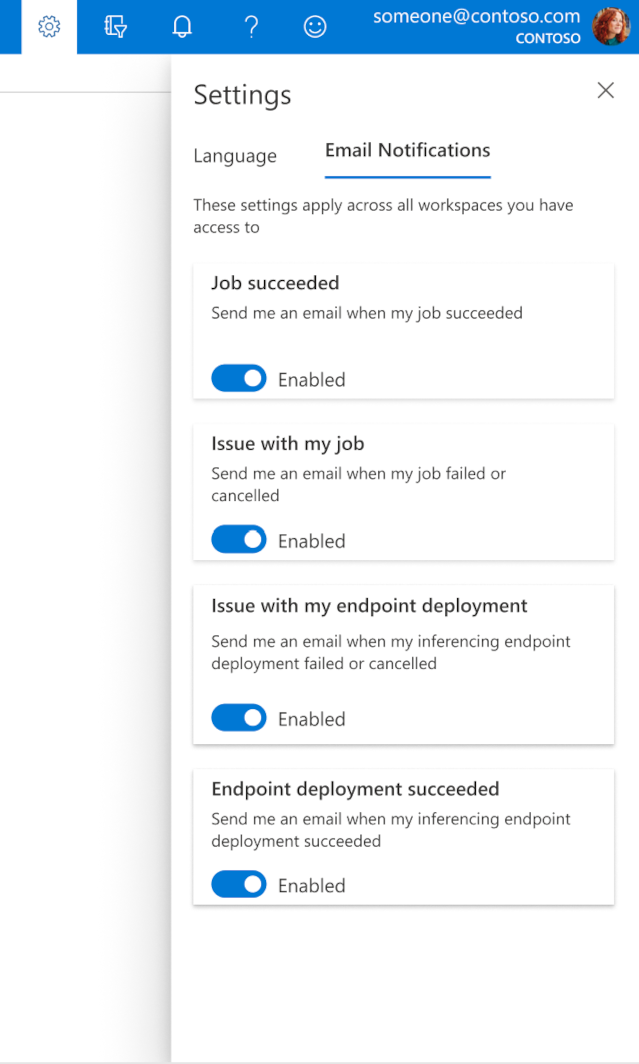
Untuk mulai menerima email saat pekerjaan, titik akhir online, atau titik akhir batch Anda selesai atau jika ada masalah (gagal, dibatalkan), gunakan langkah-langkah berikut:
- Di studio Azure ML, buka pengaturan dengan memilih ikon gigi.
- Pilih tab Pemberitahuan email.
- Alihkan untuk mengaktifkan atau menonaktifkan pemberitahuan email untuk peristiwa tertentu.
Memahami status layanan
Selama penyebaran model, Anda mungkin melihat status layanan berubah saat sepenuhnya disebarkan.
Tabel berikut ini menjelaskan berbagai status layanan:
| Status layanan web | Deskripsi | Status terakhir? |
|---|---|---|
| Transisi | Layanan ini sedang dalam proses penyebaran. | No |
| Tidak sehat | Layanan telah disebarkan, tetapi saat ini tidak dapat dijangkau. | No |
| Tidak dapat dijadwalkan | Layanan tidak dapat digunakan saat ini karena kurangnya sumber daya. | No |
| Gagal | Layanan gagal digunakan karena timbul kesalahan atau crash. | Ya |
| Sehat | Layanan ini sehat dan titik akhir tersedia. | Ya |
Tip
Saat menyebarkan, gambar Docker untuk target komputasi dibangun dan dimuat dari Azure Container Registry (ACR). Secara default, Azure Machine Learning membuat ACR yang menggunakan tingkat layanan dasar. Mengubah ACR untuk ruang kerja Anda ke tingkat standar atau premium dapat mengurangi waktu yang diperlukan untuk membangun dan menyebarkan gambar ke target komputasi Anda. Untuk informasi selengkapnya, lihat Tingkat layanan Azure Container Registry.
Catatan
Jika Anda menyebarkan model ke Azure Kubernetes Service (AKS), kami menyarankan untuk mengaktifkan Azure Monitor untuk kluster tersebut. Ini akan membantu Anda memahami kesehatan kluster dan penggunaan sumber daya secara keseluruhan. Anda mungkin memerlukan sumber daya berikut ini:
- Memeriksa peristiwa Kesehatan Sumber Daya yang memengaruhi kluster AKS Anda
- Diagnostik Azure Kubernetes Service
Jika Anda mencoba menyebarkan model ke kluster yang tidak sehat atau kelebihan beban, diperkirakan Anda akan mengalami masalah. Jika Anda memerlukan bantuan pemecahan masalah kluster AKS, silakan hubungi Dukungan AKS.
Menghapus sumber daya
BERLAKU UNTUK: Ekstensi ml Azure CLI v1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
Untuk menghapus layanan web yang disebarkan, gunakan az ml service delete <name of webservice>.
Untuk menghapus model terdaftar dari ruang kerja Anda, gunakan az ml model delete <model id>
Baca selengkapnya tentang menghapus layanan web dan menghapus model.
Langkah berikutnya
- Memecahkan masalah penyebaran yang gagal
- Memperbarui layanan web
- Penyebaran satu klik untuk eksekusi ML otomatis di studio Pembelajaran Mesin Microsoft Azure
- Menggunakan TLS untuk mengamankan layanan web melalui Azure Machine Learning
- Memantau model Azure Machine Learning Anda dengan Application Insights
- Membuat pemberitahuan dan pemicu peristiwa untuk penyebaran model
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk