Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
BERLAKU UNTUK: Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Ekstensi ml Azure CLI v2 (saat ini)Python SDK azure-ai-ml v2 (saat ini)
Di Azure Machine Learning, Anda dapat menggunakan pemantauan model untuk terus melacak performa model pembelajaran mesin dalam produksi. Pemantauan model memberi Anda pandangan menyeluruh tentang sinyal pemantauan. Ini juga memberi tahu Anda potensi masalah. Saat memantau sinyal dan metrik performa model dalam produksi, Anda dapat mengevaluasi risiko model yang melekat secara kritis. Anda juga dapat mengidentifikasi titik buta yang mungkin berdampak buruk pada bisnis Anda.
Dalam artikel ini, Anda akan melihat cara melakukan tugas berikut:
- Mengatur pemantauan siap pakai dan tingkat lanjut untuk model yang disebarkan ke titik akhir online Azure Machine Learning
- Memantau metrik performa untuk model dalam produksi
- Memantau model yang disebarkan di luar Azure Pembelajaran Mesin atau disebarkan ke titik akhir batch Azure Pembelajaran Mesin
- Menyiapkan sinyal dan metrik kustom untuk digunakan dalam pemantauan model
- Menginterpretasikan hasil pemantauan
- Mengintegrasikan pemantauan model Azure Pembelajaran Mesin dengan Azure Event Grid
Prasyarat
Azure CLI dan
mlekstensi untuk Azure CLI, telah diinstal dan dikonfigurasi. Untuk informasi selengkapnya, lihat Menginstal dan menyiapkan CLI (v2).Shell Bash atau shell yang kompatibel, misalnya, shell pada sistem Linux atau Subsistem Windows untuk Linux. Contoh Azure CLI dalam artikel ini mengasumsikan bahwa Anda menggunakan jenis shell ini.
Ruang kerja Azure Machine Learning. Untuk instruksi membuat ruang kerja, lihat Menyiapkan.
Akun pengguna yang memiliki setidaknya salah satu peran kontrol akses berbasis peran Azure (Azure RBAC) berikut:
- Peran Pemilik untuk ruang kerja Azure Machine Learning
- Peran Kontributor untuk ruang kerja Azure Machine Learning
- Peran kustom yang memiliki
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*izin
Untuk informasi selengkapnya, lihat Mengelola akses ke ruang kerja Azure Pembelajaran Mesin.
Untuk memantau titik akhir online terkelola Azure Machine Learning atau titik akhir online Kubernetes:
Model yang diimplementasikan ke endpoint online Azure Machine Learning. Titik akhir online terkelola dan titik akhir online Kubernetes didukung. Untuk instruksi untuk menyebarkan model ke titik akhir online Azure Machine Learning, lihat Menyebarkan dan menilai model pembelajaran mesin dengan menggunakan titik akhir online.
Pengumpulan data diaktifkan untuk penyebaran model Anda. Anda dapat mengaktifkan pengumpulan data selama langkah penyebaran untuk titik akhir online Azure Pembelajaran Mesin. Untuk informasi selengkapnya, lihat Mengumpulkan data produksi dari model yang disebarkan untuk inferensi real time.
Untuk memantau model yang disebarkan ke titik akhir batch Azure Machine Learning atau disebarkan di luar Azure Machine Learning:
- Sarana untuk mengumpulkan data produksi dan mendaftarkannya sebagai aset data Azure Machine Learning
- Sarana untuk memperbarui aset data terdaftar terus menerus untuk pemantauan model
- (Disarankan) Pendaftaran model di ruang kerja Azure Machine Learning, untuk pelacakan silsilah data
Mengonfigurasi kumpulan komputasi Spark tanpa server
Pekerjaan pemantauan model dijadwalkan untuk berjalan pada kumpulan komputasi Spark tanpa server. Jenis instans Azure Virtual Machines berikut ini didukung:
- Standard_E4s_v3
- Standard_E8s_v3
- Standard_E16s_v3
- Standard_E32s_v3
- Standard_E64s_v3
Untuk menentukan jenis instans komputer virtual saat Anda mengikuti prosedur dalam artikel ini, lakukan langkah-langkah berikut:
Saat Anda menggunakan Azure CLI untuk membuat monitor, Anda menggunakan file konfigurasi YAML. Dalam file tersebut, atur nilai create_monitor.compute.instance_type ke jenis yang ingin Anda gunakan.
Menyiapkan pemantauan model di luar kotak
Pertimbangkan skenario di mana Anda menyebarkan model ke produksi di titik akhir online Azure Machine Learning dan mengaktifkan pengumpulan data pada waktu penyebaran. Dalam hal ini, Azure Machine Learning mengumpulkan data inferensi produksi dan secara otomatis menyimpannya di Azure Blob Storage. Anda dapat menggunakan pemantauan model Azure Machine Learning untuk terus memantau data inferensi produksi ini.
Anda dapat menggunakan Azure CLI, Python SDK, atau studio untuk penyiapan pemantauan model di luar kotak. Konfigurasi pemantauan model di luar kotak menyediakan kemampuan pemantauan berikut:
- Azure Machine Learning secara otomatis mendeteksi aset data inferensi produksi yang terkait dengan penyebaran online Azure Machine Learning dan menggunakan aset data untuk pemantauan model.
- Aset data referensi perbandingan ditetapkan sebagai aset data inferensi produksi baru-baru ini.
- Penyiapan pemantauan secara otomatis menyertakan dan melacak sinyal pemantauan bawaan berikut: penyimpangan data, penyimpangan prediksi, dan kualitas data. Untuk setiap sinyal pemantauan, Azure Pembelajaran Mesin menggunakan:
- Aset data inferensi produksi lalu baru-baru ini sebagai aset data referensi perbandingan.
- Nilai default cerdas untuk metrik dan ambang batas.
- Pekerjaan pemantauan dikonfigurasi untuk berjalan pada jadwal reguler. Tugas tersebut memperoleh sinyal pemantauan dan mengevaluasi setiap hasil metrik terhadap ambang batas yang bersesuaian. Secara default, ketika ambang batas apa pun terlampaui, Azure Machine Learning mengirimkan email pemberitahuan kepada pengguna yang menyiapkan monitor.
Untuk menyiapkan pemantauan model di luar kotak, lakukan langkah-langkah berikut.
Di Azure CLI, Anda menggunakan az ml schedule untuk menjadwalkan pekerjaan pemantauan.
Buat definisi pemantauan dalam file YAML. Untuk contoh definisi di luar kotak, lihat kode YAML berikut, yang juga tersedia di repositori azureml-examples.
Sebelum Anda menggunakan definisi ini, sesuaikan nilai agar sesuai dengan lingkungan Anda. Untuk
endpoint_deployment_id, gunakan nilai dalam formatazureml:<endpoint-name>:<deployment-name>.# out-of-box-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: credit_default_model_monitoring display_name: Credit default model monitoring description: Credit default model monitoring setup with minimal configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: # specify a spark compute for monitoring job instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification # model task type: [classification, regression, question_answering] endpoint_deployment_id: azureml:credit-default:main # azureml endpoint deployment id alert_notification: # emails to get alerts emails: - abc@example.com - def@example.comJalankan perintah berikut untuk membuat model:
az ml schedule create -f ./out-of-box-monitoring.yaml


Menyiapkan pemantauan model tingkat lanjut
Azure Pembelajaran Mesin menyediakan banyak kemampuan untuk pemantauan model berkelanjutan. Untuk daftar komprehensif fungsionalitas ini, lihat Kemampuan pemantauan model. Dalam banyak kasus, Anda perlu menyiapkan pemantauan model yang mendukung tugas pemantauan tingkat lanjut. Bagian berikut ini menyediakan beberapa contoh pemantauan tingkat lanjut:
- Penggunaan beberapa sinyal pemantauan untuk tampilan yang luas
- Penggunaan data pelatihan model historis atau data validasi sebagai aset data referensi perbandingan
- Pemantauan fitur N yang paling penting dan fitur individual
Mengonfigurasi kepentingan fitur
Kepentingan fitur mewakili kepentingan relatif dari setiap fitur input ke output model. Misalnya, suhu mungkin lebih penting untuk prediksi model daripada elevasi. Dengan mengaktifkan fitur penting, Anda dapat memberikan visibilitas terhadap fitur mana yang tidak ingin mengalami pergeseran atau masalah mutu data di lingkungan produksi.
Untuk mengaktifkan pentingnya fitur dengan salah satu sinyal yang Anda miliki, seperti penyimpangan data atau kualitas data, Anda perlu menyediakan:
- Aset data pelatihan Anda sebagai
reference_dataaset data. - Properti
reference_data.data_column_names.target_column, yang merupakan nama kolom output model Anda, atau kolom prediksi.
Setelah mengaktifkan kepentingan fitur, Anda akan melihat kepentingan fitur untuk setiap fitur yang Anda pantau di studio Azure Machine Learning.
Anda dapat mengaktifkan atau menonaktifkan pemberitahuan untuk setiap sinyal dengan mengatur alert_enabled properti saat Anda menggunakan Python SDK atau Azure CLI.
Anda dapat menggunakan Azure CLI, Python SDK, atau studio untuk menyiapkan pemantauan model tingkat lanjut.
Buat definisi pemantauan dalam file YAML. Untuk contoh definisi lanjutan, lihat kode YAML berikut, yang juga tersedia di repositori azureml-examples.
Sebelum Anda menggunakan definisi ini, sesuaikan pengaturan berikut dan lainnya untuk memenuhi kebutuhan lingkungan Anda:
- Untuk
endpoint_deployment_id, gunakan nilai dalam formatazureml:<endpoint-name>:<deployment-name>. - Untuk
pathdi bagian data input referensi, gunakan nilai dalam formatazureml:<reference-data-asset-name>:<version>. - Untuk
target_column, gunakan nama kolom output yang berisi nilai yang diprediksi model, sepertiDEFAULT_NEXT_MONTH. - Untuk
features, cantumkan fitur sepertiSEX,EDUCATION, danAGEyang ingin Anda gunakan dalam sinyal kualitas data tingkat lanjut. - Di bawah
emails, cantumkan alamat email yang ingin Anda gunakan untuk pemberitahuan.
# advanced-model-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with advanced configurations trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:credit-default:main monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # reference_dataset is optional. By default referece_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 # use training data as comparison reference dataset type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH features: top_n_feature_importance: 10 # monitor drift for top 10 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_data_quality: type: data_quality # reference_dataset is optional. By default reference_dataset is the production inference data associated with Azure Machine Learning online endpoint reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training features: # monitor data quality for 3 individual features only - SEX - EDUCATION alert_enabled: true metric_thresholds: numerical: null_value_rate: 0.05 categorical: out_of_bounds_rate: 0.03 feature_attribution_drift_signal: type: feature_attribution_drift # production_data: is not required input here # Please ensure Azure Machine Learning online endpoint is enabled to collected both model_inputs and model_outputs data # Azure Machine Learning model monitoring will automatically join both model_inputs and model_outputs data and used it for computation reference_data: input_data: path: azureml:credit-reference:1 type: mltable data_context: training data_column_names: target_column: DEFAULT_NEXT_MONTH alert_enabled: true metric_thresholds: normalized_discounted_cumulative_gain: 0.9 alert_notification: emails: - abc@example.com - def@example.com- Untuk
Jalankan perintah berikut untuk membuat model:
az ml schedule create -f ./advanced-model-monitoring.yaml






Menyiapkan pemantauan performa model
Saat Anda menggunakan pemantauan model Azure Machine Learning, Anda dapat melacak performa model Anda dalam produksi dengan menghitung metrik performanya. Metrik performa model berikut saat ini didukung:
- Untuk model klasifikasi:
- Presisi
- Akurasi
- Tarik Kembali
- Untuk model regresi:
- Kesalahan absolut rata-rata (MAE)
- Kesalahan kuadrat rata-rata (MSE)
- Kesalahan akar kuadrat rata-rata (RMSE)
Prasyarat untuk pemantauan performa model
Data output untuk model produksi (prediksi model) dengan ID unik untuk setiap baris. Jika Anda menggunakan pengumpul data Azure Machine Learning untuk mengumpulkan data produksi, ID korelasi disediakan untuk setiap permintaan inferensi untuk Anda. Pengumpul data juga menawarkan opsi pengelogan ID unik Anda sendiri dari aplikasi Anda.
Catatan
Untuk pemantauan performa model Azure Machine Learning, kami sarankan Anda menggunakan pengumpul data Azure Machine Learning untuk mencatat ID unik Anda di kolomnya sendiri.
Data kebenaran dasar (aktual) dengan ID unik untuk setiap baris. ID unik untuk baris tertentu harus cocok dengan ID unik untuk data output model untuk permintaan inferensi tertentu. ID unik ini digunakan untuk menggabungkan aset data kebenaran dasar Anda dengan data output model.
Jika Anda tidak memiliki data kebenaran dasar, Anda tidak dapat melakukan pemantauan performa model. Data kebenaran dasar ditemui di tingkat aplikasi, jadi Anda bertanggung jawab untuk mengumpulkannya saat tersedia. Anda juga harus mempertahankan aset data di Azure Pembelajaran Mesin yang berisi data kebenaran dasar ini.
(Opsional) Aset data tabular yang sudah digabungkan sebelumnya dengan data output model dan data ground truth yang sudah disatukan.
Persyaratan untuk pemantauan performa model saat Anda menggunakan pengumpul data
Azure Machine Learning menghasilkan ID korelasi untuk Anda saat Anda memenuhi kriteria berikut:
- Anda menggunakan pengumpul data Azure Machine Learning untuk mengumpulkan data inferensi produksi.
- Anda tidak memberikan ID unik Anda sendiri untuk setiap baris sebagai kolom terpisah.
ID korelasi yang dihasilkan disertakan dalam objek JSON yang dicatat. Namun, pengumpul data mengumpulkan baris yang dikirim dalam interval waktu singkat satu sama lain. Baris batch berada dalam objek JSON yang sama. Dalam setiap objek, semua baris memiliki ID korelasi yang sama.
Untuk membedakan antara baris dalam objek JSON, pemantauan performa model Azure Machine Learning menggunakan pengindeksan untuk menentukan urutan baris dalam objek. Misalnya, jika batch berisi tiga baris dan ID korelasi adalah test, baris pertama memiliki ID , test_0baris kedua memiliki ID , test_1dan baris ketiga memiliki ID .test_2 Untuk mencocokkan ID unik aset data kebenaran dasar Anda dengan ID data output model inferensi produksi yang dikumpulkan, terapkan indeks ke setiap ID korelasi dengan tepat. Jika objek JSON anda yang dicatat hanya memiliki satu baris, gunakan correlationid_0 sebagai correlationid nilai .
Untuk menghindari penggunaan pengindeksan ini, kami sarankan Anda mencatat ID unik Anda di kolomnya sendiri. Letakkan kolom tersebut dalam DataFrame Pandas yang dicatatkan oleh pengumpul data Azure Machine Learning. Dalam konfigurasi pemantauan model, Anda kemudian dapat menentukan nama kolom ini untuk menggabungkan data output model Anda dengan data kebenaran dasar Anda. Selama ID untuk setiap baris di kedua aset data sama, pemantauan model Azure Machine Learning dapat melakukan pemantauan performa model.
Contoh alur kerja untuk memantau performa model
Untuk memahami konsep yang terkait dengan pemantauan performa model, pertimbangkan contoh alur kerja berikut. Ini berlaku untuk skenario di mana Anda menyebarkan model untuk memprediksi apakah transaksi kartu kredit penipuan:
- Konfigurasikan penyebaran Anda untuk menggunakan pengumpul data untuk mengumpulkan data inferensi produksi model (data input dan output). Simpan data output dalam kolom yang disebut
is_fraud. - Untuk setiap baris data inferensi yang dikumpulkan, catat ID unik. ID unik dapat berasal dari aplikasi Anda, atau Anda dapat menggunakan
correlationidnilai yang dihasilkan secara unik Azure Machine Learning untuk setiap objek JSON yang dicatat. - Saat data kebenaran dasar (atau aktual)
is_fraudtersedia, catat dan petakan setiap baris ke ID unik yang sama yang dicatat untuk baris yang sesuai dalam data output model. - Daftarkan aset data di Azure Machine Learning, dan gunakan untuk mengumpulkan dan memelihara data kebenaran
is_frauddasar. - Buat sinyal pemantauan performa model yang menggunakan kolom ID unik untuk menggabungkan inferensi produksi model dan aset data kebenaran dasar.
- Menghitung metrik performa model.
Setelah Anda memenuhi prasyarat untuk pemantauan performa model, lakukan langkah-langkah berikut untuk menyiapkan pemantauan model:
Buat definisi pemantauan dalam file YAML. Spesifikasi sampel berikut mendefinisikan pemantauan model dengan data inferensi produksi. Sebelum Anda menggunakan definisi ini, sesuaikan pengaturan berikut dan lainnya untuk memenuhi kebutuhan lingkungan Anda:
- Untuk
endpoint_deployment_id, gunakan nilai dalam formatazureml:<endpoint-name>:<deployment-name>. - Untuk setiap
pathnilai di bagian data input, gunakan nilai dalam formatazureml:<data-asset-name>:<version>. - Untuk nilai ,
predictiongunakan nama kolom output yang berisi nilai yang diprediksi model. - Untuk nilai ,
actualgunakan nama kolom kebenaran dasar yang berisi nilai aktual yang coba diprediksi model. -
correlation_idUntuk nilai, gunakan nama kolom yang digunakan untuk menggabungkan data output dan data kebenaran dasar. - Di bawah
emails, cantumkan alamat email yang ingin Anda gunakan untuk pemberitahuan.
# model-performance-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: model_performance_monitoring display_name: Credit card fraud model performance description: Credit card fraud model performance trigger: type: recurrence frequency: day interval: 7 schedule: hours: 10 minutes: 15 create_monitor: compute: instance_type: standard_e8s_v3 runtime_version: "3.3" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:loan-approval-endpoint:loan-approval-deployment monitoring_signals: fraud_detection_model_performance: type: model_performance production_data: input_data: path: azureml:credit-default-main-model_outputs:1 type: mltable data_column_names: prediction: is_fraud correlation_id: correlation_id reference_data: input_data: path: azureml:my_model_ground_truth_data:1 type: mltable data_column_names: actual: is_fraud correlation_id: correlation_id data_context: ground_truth alert_enabled: true metric_thresholds: tabular_classification: accuracy: 0.95 precision: 0.8 alert_notification: emails: - abc@example.com- Untuk
Jalankan perintah berikut untuk membuat model:
az ml schedule create -f ./model-performance-monitoring.yaml





Menyiapkan pemantauan model data produksi
Anda juga dapat memantau model yang Anda sebarkan ke titik akhir batch Azure Machine Learning atau yang Anda sebarkan di luar Azure Machine Learning. Jika Anda tidak memiliki penyebaran tetapi memiliki data produksi, Anda dapat menggunakan data untuk melakukan pemantauan model berkelanjutan. Untuk memantau model ini, Anda harus dapat:
- Kumpulkan data inferensi produksi dari model yang disebarkan dalam produksi.
- Daftarkan data inferensi produksi sebagai aset data Azure Pembelajaran Mesin, dan pastikan pembaruan data berkelanjutan.
- Sediakan komponen pra-pemrosesan data kustom dan daftarkan sebagai komponen Azure Machine Learning jika Anda tidak menggunakan pengumpul data untuk mengumpulkan data. Tanpa komponen praproses data kustom ini, sistem pemantauan model Azure Machine Learning tidak dapat memproses data Anda ke dalam bentuk tabular yang mendukung jendela waktu.
Komponen praproses kustom Anda harus memiliki tanda tangan input dan output berikut:
| Input atau output | Nama tanda tangan | Tipe | Deskripsi | Contoh nilai |
|---|---|---|---|---|
| Masukan | data_window_start |
literal, string | Waktu mulai jendela data dalam format ISO8601 | 2023-05-01T04:31:57.012Z |
| Masukan | data_window_end |
literal, string | Waktu akhir jendela data dalam format ISO8601 | 2023-05-01T04:31:57.012Z |
| Masukan | input_data |
uri_folder | Data inferensi produksi yang dikumpulkan, yang terdaftar sebagai aset data Azure Machine Learning | azureml:myproduction_inference_data:1 |
| keluaran | preprocessed_data |
mltable | Aset data tabular yang cocok dengan subset skema data referensi |
Untuk contoh komponen pra-pemrosesan data kustom, lihat custom_preprocessing di repositori GitHub azuremml-examples.
Untuk petunjuk mendaftarkan komponen Azure Machine Learning, lihat Mendaftarkan komponen di ruang kerja Anda.
Setelah mendaftarkan data produksi dan komponen pra-pemrosesan, Anda dapat menyiapkan pemantauan model.
Buat file YAML definisi pemantauan yang mirip dengan yang berikut ini. Sebelum Anda menggunakan definisi ini, sesuaikan pengaturan berikut dan lainnya untuk memenuhi kebutuhan lingkungan Anda:
- Untuk
endpoint_deployment_id, gunakan nilai dalam formatazureml:<endpoint-name>:<deployment-name>. - Untuk
pre_processing_component, gunakan nilai dalam formatazureml:<component-name>:<component-version>. Tentukan versi yang tepat, seperti1.0.0, bukan1. - Untuk setiap
path, gunakan nilai dalam formatazureml:<data-asset-name>:<version>. - Untuk nilai ,
target_columngunakan nama kolom output yang berisi nilai yang diprediksi model. - Di bawah
emails, cantumkan alamat email yang ingin Anda gunakan untuk pemberitahuan.
# model-monitoring-with-collected-data.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: fraud_detection_model_monitoring display_name: Fraud detection model monitoring description: Fraud detection model monitoring with your own production data trigger: # perform model monitoring activity daily at 3:15am type: recurrence frequency: day #can be minute, hour, day, week, month interval: 1 # #every day schedule: hours: 3 # at 3am minutes: 15 # at 15 mins after 3am create_monitor: compute: instance_type: standard_e4s_v3 runtime_version: "3.4" monitoring_target: ml_task: classification endpoint_deployment_id: azureml:fraud-detection-endpoint:fraud-detection-deployment monitoring_signals: advanced_data_drift: # monitoring signal name, any user defined name works type: data_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_inputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_inputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_training_data:1 # use training data as comparison baseline type: mltable data_context: training data_column_names: target_column: is_fraud features: top_n_feature_importance: 20 # monitor drift for top 20 features alert_enabled: true metric_thresholds: numerical: jensen_shannon_distance: 0.01 categorical: pearsons_chi_squared_test: 0.02 advanced_prediction_drift: # monitoring signal name, any user defined name works type: prediction_drift # define production dataset with your collected data production_data: input_data: path: azureml:my_production_inference_data_model_outputs:1 # your collected data is registered as Azure Machine Learning asset type: uri_folder data_context: model_outputs pre_processing_component: azureml:production_data_preprocessing:1.0.0 reference_data: input_data: path: azureml:my_model_validation_data:1 # use training data as comparison reference dataset type: mltable data_context: validation alert_enabled: true metric_thresholds: categorical: pearsons_chi_squared_test: 0.02 alert_notification: emails: - abc@example.com - def@example.com- Untuk
Jalankan perintah berikut untuk membuat model.
az ml schedule create -f ./model-monitoring-with-collected-data.yaml
Menyiapkan pemantauan model dengan sinyal dan metrik kustom
Saat Anda menggunakan pemantauan model Azure Machine Learning, Anda dapat menentukan sinyal kustom dan menerapkan metrik apa pun dari pilihan Anda untuk memantau model Anda. Anda dapat mendaftarkan sinyal kustom Anda sebagai komponen Azure Machine Learning. Saat pekerjaan pemantauan model Anda berjalan pada jadwal yang ditentukan, ia menghitung metrik yang ditentukan dalam sinyal kustom Anda, seperti halnya untuk penyimpangan data, penyimpangan prediksi, dan sinyal bawaan kualitas data.
Untuk menyiapkan sinyal kustom yang akan digunakan untuk pemantauan model, Anda harus terlebih dahulu menentukan sinyal kustom dan mendaftarkannya sebagai komponen Azure Pembelajaran Mesin. Komponen Azure Machine Learning harus memiliki tanda tangan input dan output berikut.
Tanda tangan input komponen
Bingkai data input komponen harus berisi item berikut:
- Struktur
mltableyang berisi data yang diproses dari komponen praproses. - Sejumlah literal, masing-masing mewakili metrik yang diimplementasikan sebagai bagian dari komponen sinyal kustom. Misalnya, jika Anda menerapkan
std_deviationmetrik, Anda memerlukan input untukstd_deviation_threshold. Umumnya, harus ada satu input dengan nama<metric-name>_thresholdper metrik.
| Nama tanda tangan | Tipe | Deskripsi | Contoh nilai |
|---|---|---|---|
production_data |
mltable | Aset data tabular yang cocok dengan subset skema data referensi | |
std_deviation_threshold |
literal, string | Ambang masing-masing untuk metrik yang diimplementasikan | 2 |
Tanda tangan output komponen
Port output komponen harus memiliki tanda tangan berikut:
| Nama tanda tangan | Tipe | Deskripsi |
|---|---|---|
signal_metrics |
mltable | Struktur mltable yang berisi metrik yang dihitung. Untuk skema tanda tangan ini, lihat bagian berikutnya, signal_metrics skema. |
skema signal_metrics
Bingkai data output komponen harus berisi empat kolom: group, , metric_namemetric_value, dan threshold_value.
| Nama tanda tangan | Tipe | Deskripsi | Contoh nilai |
|---|---|---|---|
group |
literal, string | Pengelompokan logis tingkat atas yang akan diterapkan ke metrik kustom | JUMLAHTRANSAKSI |
metric_name |
literal, string | Nama metrik kustom | std_deviation |
metric_value |
Numerik | Nilai metrik kustom | 44,896.082 |
threshold_value |
Numerik | Ambang batas untuk metrik kustom | 2 |
Tabel berikut ini memperlihatkan contoh output dari komponen sinyal kustom yang menghitung std_deviation metrik:
| grup | nilai_metrik | nama metrik | nilai ambang |
|---|---|---|---|
| JUMLAHTRANSAKSI | 44,896.082 | std_deviation | 2 |
| LOCALHOUR | 3.983 | std_deviation | 2 |
| JUMLAHTRANSAKSIUSD | 54.004,902 | std_deviation | 2 |
| DIGITALITEMCOUNT | 7.238 | std_deviation | 2 |
| PHYSICALITEMCOUNT | 5.509 | std_deviation | 2 |
Untuk melihat contoh definisi komponen sinyal kustom dan kode komputasi metrik, lihat custom_signal di repositori azureml-examples.
Untuk petunjuk mendaftarkan komponen Azure Machine Learning, lihat Mendaftarkan komponen di ruang kerja Anda.
Setelah Anda membuat dan mendaftarkan komponen sinyal kustom Anda di Azure Machine Learning, lakukan langkah-langkah berikut untuk menyiapkan pemantauan model:
Buat definisi pemantauan dalam file YAML yang mirip dengan yang berikut ini. Sebelum Anda menggunakan definisi ini, sesuaikan pengaturan berikut dan lainnya untuk memenuhi kebutuhan lingkungan Anda:
- Untuk
component_id, gunakan nilai dalam formatazureml:<custom-signal-name>:1.0.0. - Untuk
pathdi bagian data input, gunakan nilai dalam formatazureml:<production-data-asset-name>:<version>. - Untuk
pre_processing_component:- Jika Anda menggunakan pengumpul data untuk mengumpulkan data, Anda dapat menghilangkan
pre_processing_componentproperti . - Jika Anda tidak menggunakan pengumpul data dan ingin menggunakan komponen untuk memproses data produksi sebelumnya, gunakan nilai dalam format
azureml:<custom-preprocessor-name>:<custom-preprocessor-version>.
- Jika Anda menggunakan pengumpul data untuk mengumpulkan data, Anda dapat menghilangkan
- Di bawah
emails, cantumkan alamat email yang ingin Anda gunakan untuk pemberitahuan.
# custom-monitoring.yaml $schema: http://azureml/sdk-2-0/Schedule.json name: my-custom-signal trigger: type: recurrence frequency: day # Possible frequency values include "minute," "hour," "day," "week," and "month." interval: 7 # Monitoring runs every day when you use the value 1. create_monitor: compute: instance_type: "standard_e4s_v3" runtime_version: "3.3" monitoring_signals: customSignal: type: custom component_id: azureml:my_custom_signal:1.0.0 input_data: production_data: input_data: type: uri_folder path: azureml:my_production_data:1 data_context: test data_window: lookback_window_size: P30D lookback_window_offset: P7D pre_processing_component: azureml:custom_preprocessor:1.0.0 metric_thresholds: - metric_name: std_deviation threshold: 2 alert_notification: emails: - abc@example.com- Untuk
Jalankan perintah berikut untuk membuat model:
az ml schedule create -f ./custom-monitoring.yaml
Menginterpretasikan hasil pemantauan
Setelah mengonfigurasi monitor model dan proses pertama selesai, Anda dapat melihat hasilnya di studio Azure Machine Learning.
Di studio, di bawah Kelola, pilih Pemantauan. Di halaman Pemantauan, pilih nama monitor model Anda untuk melihat halaman ikhtisarnya. Halaman ini memperlihatkan model pemantauan, titik akhir, dan penyebaran. Ini juga menyediakan informasi terperinci tentang sinyal yang dikonfigurasi. Gambar berikut menunjukkan halaman gambaran umum pemantauan yang menyertakan penyimpangan data dan sinyal kualitas data.

Lihat di bagian Pemberitahuan dari halaman gambaran umum. Di bagian ini, Anda dapat melihat fitur untuk setiap sinyal yang melanggar ambang batas yang dikonfigurasi untuk metrik masing-masing.
Di bagian Sinyal , pilih data_drift untuk melihat informasi terperinci tentang sinyal penyimpangan data. Pada halaman detail, Anda dapat melihat nilai metrik penyimpangan data untuk setiap fitur numerik dan kategoris yang disertakan oleh konfigurasi pemantauan Anda. Jika monitor Anda memiliki lebih dari satu sesi pemantauan, Anda akan melihat garis tren untuk setiap fitur.
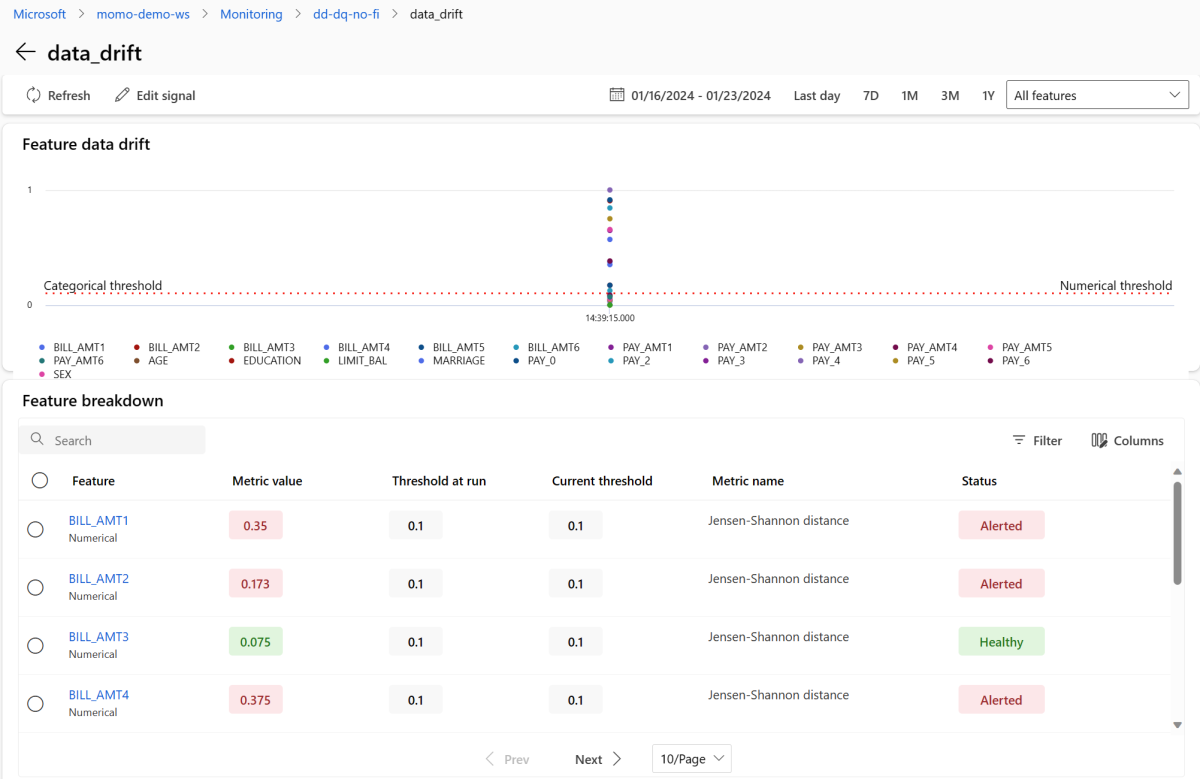
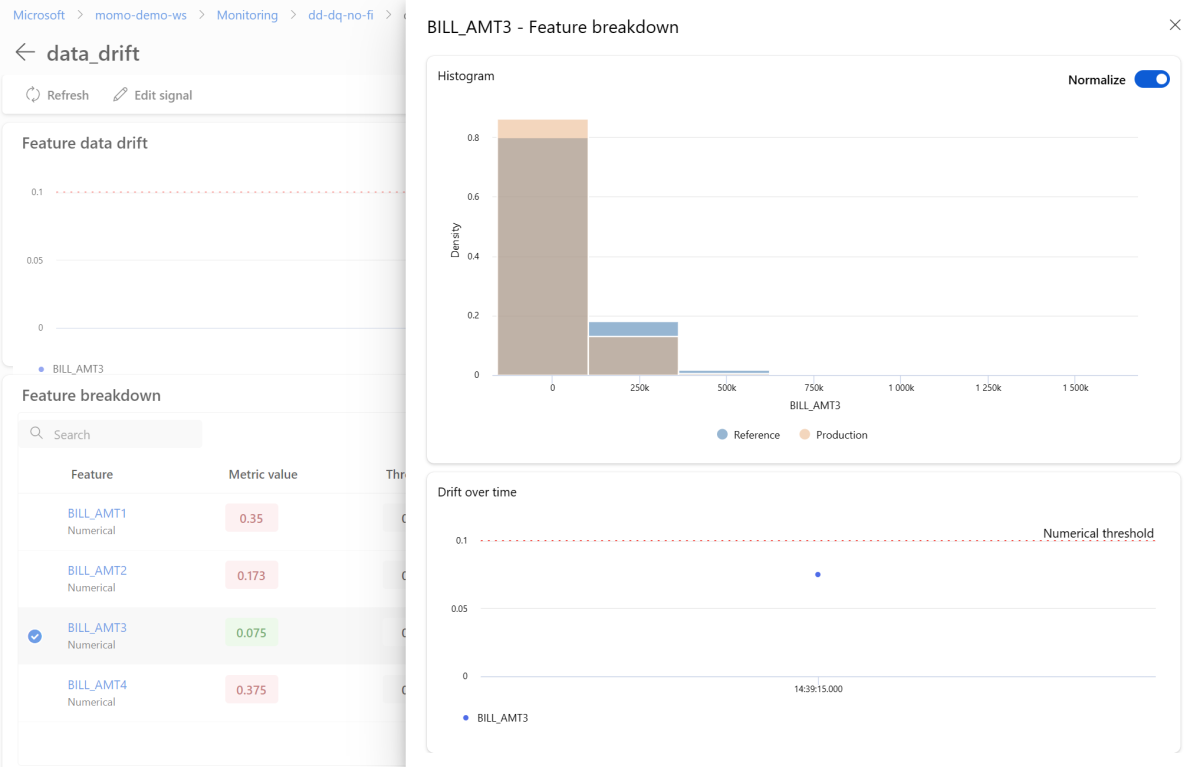
Pada halaman detail, pilih nama fitur individual. Tampilan terperinci terbuka yang menunjukkan distribusi produksi dibandingkan dengan distribusi referensi. Anda juga dapat menggunakan tampilan ini untuk melacak penyimpangan dari waktu ke waktu untuk fitur tersebut.
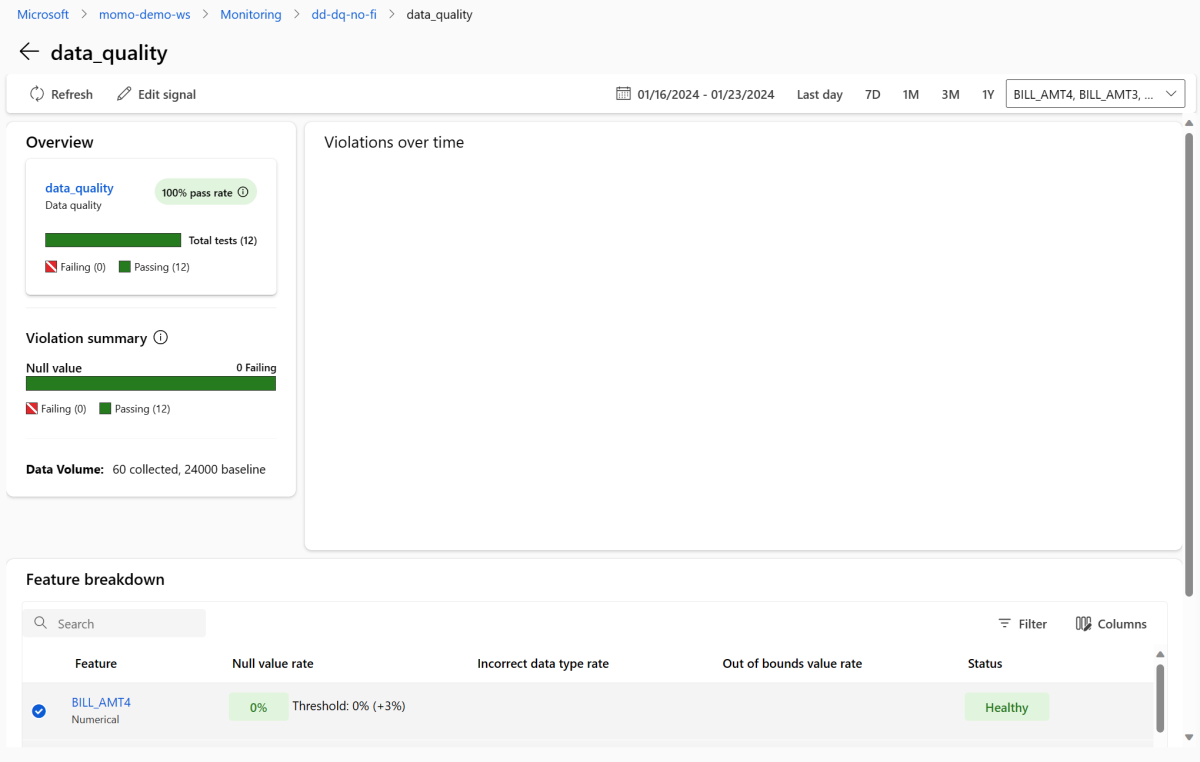
Kembali ke halaman gambaran umum pemantauan. Di bagian Sinyal , pilih data_quality untuk melihat informasi terperinci tentang sinyal ini. Pada halaman ini, Anda dapat melihat tingkat nilai null, tingkat di luar batas, dan tingkat kesalahan jenis data untuk setiap fitur yang Anda pantau.




Pemantauan model adalah proses berkelanjutan. Saat Anda menggunakan pemantauan model Azure Machine Learning, Anda dapat mengonfigurasi beberapa sinyal pemantauan untuk mendapatkan tampilan luas tentang performa model Anda dalam produksi.
Mengintegrasikan pemantauan model Azure Machine Learning dengan Event Grid
Saat menggunakan Event Grid, Anda dapat mengonfigurasi peristiwa yang dihasilkan oleh pemantauan model Azure Machine Learning untuk memicu aplikasi, proses, dan alur kerja CI/CD. Anda dapat mengonsumsi event melalui berbagai pengelola event, seperti Azure Event Hubs, Azure Functions, dan Azure Logic Apps. Saat monitor mendeteksi penyimpangan, Anda dapat mengambil tindakan secara terprogram, seperti dengan menjalankan alur pembelajaran mesin untuk melatih kembali model dan menyebarkannya kembali.
Untuk mengintegrasikan pemantauan model Azure Machine Learning dengan Event Grid, lakukan langkah-langkah di bagian berikut.
Membuat topik sistem
Jika Anda tidak memiliki topik sistem Event Grid untuk digunakan untuk pemantauan, buat topik tersebut. Untuk petunjuknya, lihat Membuat, melihat, dan mengelola topik sistem Event Grid di portal Microsoft Azure.
Membuat langganan peristiwa
Di portal Microsoft Azure, buka ruang kerja Azure Machine Learning Anda.
Pilih Aktivitas, lalu pilih Langganan Aktivitas.
Di samping Nama, masukkan nama untuk langganan peristiwa Anda, seperti MonitoringEvent.
Di bawah Jenis Peristiwa, pilih hanya Jalankan status yang diubah.
Peringatan
Pilih hanya Jalankan status yang diubah untuk jenis peristiwa. Jangan pilih Penyimpangan himpunan data terdeteksi, yang berlaku untuk penyimpangan data v1, bukan pemantauan model Azure Machine Learning.
Pilih tab Filter . Di bawah Filter Tingkat Lanjut, pilih Tambahkan filter baru, lalu masukkan nilai berikut:
- Pada Kunci, masukkan data.RunTags.azureml_modelmonitor_threshold_breached.
- Di bawah Operator, pilih String berisi.
- Di bawah Nilai, enter telah gagal karena satu atau beberapa fitur yang melanggar ambang batas metrik.
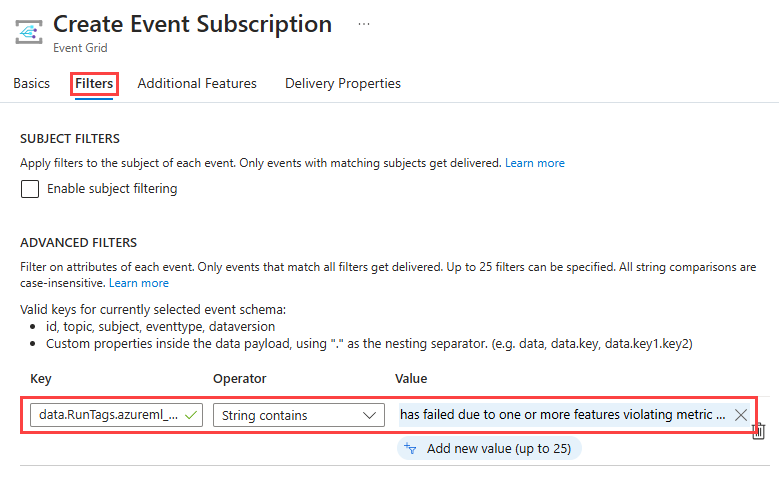
Saat Anda menggunakan filter ini, peristiwa dihasilkan saat status eksekusi monitor apa pun di ruang kerja Azure Machine Learning Anda berubah. Status dapat berubah dari selesai menjadi gagal atau dari gagal menjadi selesai.
Untuk memfilter di tingkat pemantauan, pilih Tambahkan filter baru lagi, lalu masukkan nilai berikut:
- Pada Kunci, masukkan data.RunTags.azureml_modelmonitor_threshold_breached.
- Di bawah Operator, pilih String berisi.
- Di bawah Nilai, masukkan nama sinyal monitor yang ingin Anda filter peristiwanya, seperti credit_card_fraud_monitor_data_drift. Nama yang Anda masukkan harus cocok dengan nama sinyal pemantauan Anda. Sinyal apa pun yang Anda gunakan dalam pemfilteran harus memiliki nama dalam format
<monitor-name>_<signal-description>yang menyertakan nama monitor dan deskripsi sinyal.
Pilih tab Dasar . Konfigurasikan titik akhir yang ingin Anda layani sebagai penanganan aktivitas Anda, seperti Azure Event Hubs.
Pilih Buat untuk membuat langganan peristiwa.

Menampilkan kejadian
Setelah mengambil peristiwa, Anda dapat melihatnya di halaman titik akhir penanganan aktivitas:

Anda juga dapat melihat peristiwa di tab Metrik Azure Monitor:
