Memicu alur pembelajaran mesin
BERLAKU UNTUK: Python SDK azureml v1
Python SDK azureml v1
Dalam artikel ini, Anda akan mempelajari cara menjadwalkan alur untuk dijalankan di Azure secara terprogram. Anda dapat membuat jadwal berdasarkan waktu yang berlalu atau pada perubahan sistem file. Jadwal berbasis waktu dapat digunakan untuk mengurus tugas rutin, seperti pemantauan untuk drift data. Jadwal berbasis perubahan dapat digunakan untuk bereaksi terhadap perubahan yang tidak teratur atau tidak dapat diprediksi, seperti data baru yang diunggah atau data lama yang diedit. Setelah mempelajari cara membuat jadwal, Anda akan mempelajari cara mengambil dan menonaktifkannya. Terakhir, Anda akan mempelajari cara menggunakan layanan Azure lainnya, Azure Logic App dan Azure Data Factory, untuk menjalankan alur. Azure Logic App memungkinkan logika atau perilaku pemicu yang lebih kompleks. Alur Azure Data Factory memungkinkan Anda memanggil alur pembelajaran mesin sebagai bagian dari alur perencanaan data yang lebih besar.
Prasyarat
Langganan Azure. Jika Anda tidak memiliki langganan Azure, buat akun gratis.
Lingkungan Python tempat Azure Machine Learning SDK untuk Python dipasang. Untuk informasi selengkapnya, lihat Membuat dan mengelola lingkungan yang dapat digunakan kembali untuk pelatihan dan penyebaran dengan Azure Machine Learning.
Ruang kerja Pembelajaran Mesin dengan alur yang diterbitkan. Anda dapat menggunakan ruang kerja yang dibangun di Membuat dan menjalankan alur pembelajaran mesin dengan Azure Machine Learning SDK.
Memicu alur dengan Azure Machine Learning SDK untuk Python
Untuk menjadwalkan alur, Anda memerlukan referensi ke ruang kerja, pengidentifikasi alur yang diterbitkan, dan nama eksperimen tempat Anda ingin membuat jadwal. Anda bisa mendapatkan nilai-nilai ini dengan kode berikut:
import azureml.core
from azureml.core import Workspace
from azureml.pipeline.core import Pipeline, PublishedPipeline
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
experiments = Experiment.list(ws)
for experiment in experiments:
print(experiment.name)
published_pipelines = PublishedPipeline.list(ws)
for published_pipeline in published_pipelines:
print(f"{published_pipeline.name},'{published_pipeline.id}'")
experiment_name = "MyExperiment"
pipeline_id = "aaaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
Membuat jadwal
Untuk menjalankan alur secara berulang, Anda akan membuat jadwal. Sebuah Schedule mengasosiasi alur, percobaan, dan pemicu. Pemicunya dapat berupaScheduleRecurrence yang menjelaskan waktu tunggu di antara pekerjaan atau jalur Datastore yang menetapkan direktori untuk melihat perubahan. Dalam kedua kasus, Anda akan memerlukan pengidentifikasi alur dan nama eksperimen untuk membuat jadwal.
Di bagian atas file Python, impor kelas Schedule dan ScheduleRecurrence:
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
Membuat jadwal berbasis waktu
Konstruktor ScheduleRecurrence memiliki argumen frequency yang diperlukan, yang harus merupakan salah satu string berikut: "Menit", "Jam", "Hari", "Minggu", atau "Bulan". Konstruktor juga memerlukan argumen bilangan bulat interval yang menentukan jumlah unit frequency yang harus berjalan di antara awal jadwal. Argumen opsional memungkinkan Anda lebih spesifik tentang waktu mulai, sebagaimana dirinci dalam dokumen ScheduleRecurrence SDK.
Buat Schedule yang memulai pekerjaan setiap 15 menit:
recurrence = ScheduleRecurrence(frequency="Minute", interval=15)
recurring_schedule = Schedule.create(ws, name="MyRecurringSchedule",
description="Based on time",
pipeline_id=pipeline_id,
experiment_name=experiment_name,
recurrence=recurrence)
Membuat jadwal berbasis perubahan
Alur yang dipicu oleh perubahan file mungkin lebih efisien daripada jadwal berbasis waktu. Saat Anda ingin melakukan sesuatu sebelum file diubah atau saat file baru ditambahkan ke direktori data, Anda dapat melakukan prapemrosesan file tersebut. Anda dapat memantau semua perubahan pada penyimpanan data atau dalam direktori tertentu pada penyimpanan data. Jika Anda memantau direktori tertentu, perubahan dalam subdirektori dari direktori tersebut tidak akan memicu pekerjaan.
Catatan
Jadwal berbasis perubahan hanya mendukung pemantauan penyimpanan Blob Azure.
Untuk membuat Schedule yang reaktif terhadap file, Anda harus mengatur parameter datastore dalam panggilan ke Schedule.create. Untuk memantau folder, atur argumen path_on_datastore.
Argumen polling_interval memungkinkan Anda menentukan frekuensi dalam hitungan menit saat penyimpanan data diperiksa jika ada perubahan.
Jika alur dibangun dengan DataPath PipelineParameter, Anda dapat mengatur variabel tersebut ke nama file yang diubah dengan mengatur argumen data_path_parameter_name.
datastore = Datastore(workspace=ws, name="workspaceblobstore")
reactive_schedule = Schedule.create(ws, name="MyReactiveSchedule", description="Based on input file change.",
pipeline_id=pipeline_id, experiment_name=experiment_name, datastore=datastore, data_path_parameter_name="input_data")
Argumen opsional saat membuat jadwal
Selain argumen yang dibahas sebelumnya, Anda dapat mengatur argumen status ke "Disabled" untuk membuat jadwal yang tidak aktif. Akhirnya, continue_on_step_failure memungkinkan Anda melewati Boolean yang akan mengambil alih perilaku kegagalan default alur.
Menampilkan alur terjadwal Anda
Di browser Web, buka Azure Machine Learning. Dari bagian Titik Akhir panel navigasi, pilih Titik akhir alur. Tindakan ini membawa Anda ke daftar alur yang diterbitkan di Ruang Kerja.
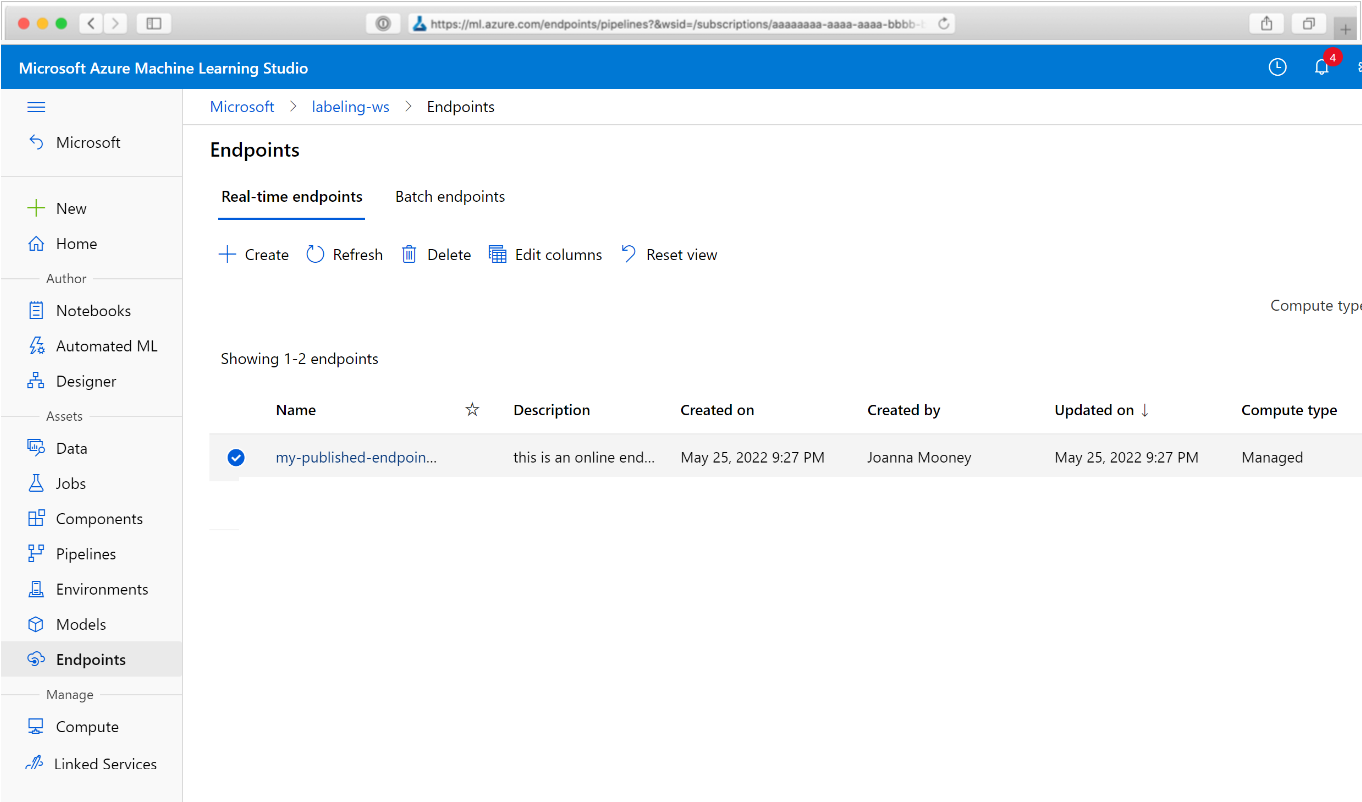
Di halaman ini Anda dapat melihat informasi ringkasan tentang semua alur di Ruang Kerja: nama, deskripsi, status, dan sebagainya. Telusuri dengan mengeklik di alur. Pada halaman yang dihasilkan, terdapat detail selengkapnya tentang alur Anda dan Anda dapat menelusuri paling detail pekerjaan individu.
Menonaktifkan alur
Jika Anda memiliki Pipeline yang diterbitkan tetapi tidak terjadwal, Anda dapat menonaktifkannya dengan:
pipeline = PublishedPipeline.get(ws, id=pipeline_id)
pipeline.disable()
Jika alur dijadwalkan, Anda harus membatalkan jadwal terlebih dahulu. Ambil pengidentifikasi jadwal dari portal atau dengan menjalankan:
ss = Schedule.list(ws)
for s in ss:
print(s)
Setelah Anda menemukan schedule_id yang ingin Anda nonaktifkan, jalankan:
def stop_by_schedule_id(ws, schedule_id):
s = next(s for s in Schedule.list(ws) if s.id == schedule_id)
s.disable()
return s
stop_by_schedule_id(ws, schedule_id)
Jika Anda kemudian menjalankan Schedule.list(ws) lagi, Anda akan mendapatkan daftar kosong.
Menggunakan Azure Logic Apps untuk pemicu kompleks
Aturan atau perilaku pemicu yang lebih kompleks dapat dibuat menggunakan Azure Logic App.
Untuk menggunakan Azure Logic App untuk memicu alur Machine Learning, Anda memerlukan titik akhir REST untuk alur Pembelajaran Mesin yang diterbitkan. Buat dan terbitkan alur Anda. Kemudian temukan titik akhir REST dari PublishedPipeline Anda dengan menggunakan ID alur:
# You can find the pipeline ID in Azure Machine Learning studio
published_pipeline = PublishedPipeline.get(ws, id="<pipeline-id-here>")
published_pipeline.endpoint
Membuat aplikasi logika di Azure
Sekarang buat instans Azure Logic App. Setelah aplikasi logika Anda disediakan, gunakan langkah-langkah ini untuk mengonfigurasi pemicu untuk alur Anda:
Buat identitas terkelola yang ditetapkan sistem untuk memberi aplikasi akses ke Ruang Kerja Azure Machine Learning Anda.
Buka tampilan Perancang Logic App dan pilih templat Logic App Kosong.
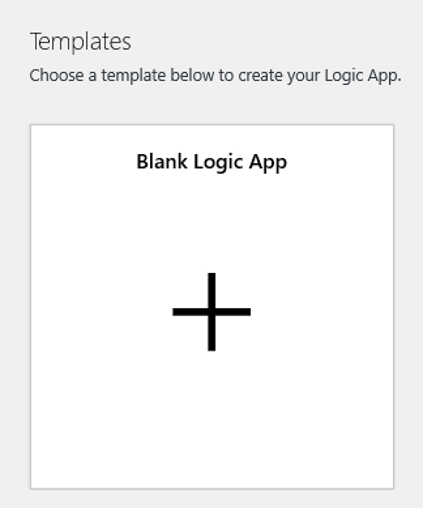
Dalam Perancang, cari blob. Pilih pemicu Saat blob ditambahkan atau dimodifikasi (properti saja) dan tambahkan pemicu ini ke Logic App Anda.
Isi info koneksi untuk akun penyimpanan Blob yang ingin Anda pantau untuk penambahan atau modifikasi blob. Pilih Kontainer untuk dipantau.
Pilih Interval dan Frekuensi ke polling untuk pembaruan yang sesuai untuk Anda.
Catatan
Pemicu ini akan memantau Kontainer yang dipilih tetapi tidak memantau subfolder.
Tambahkan tindakan HTTP yang akan berjalan saat blob baru atau yang dimodifikasi terdeteksi. Pilih + Langkah Baru, lalu cari dan pilih tindakan HTTP.
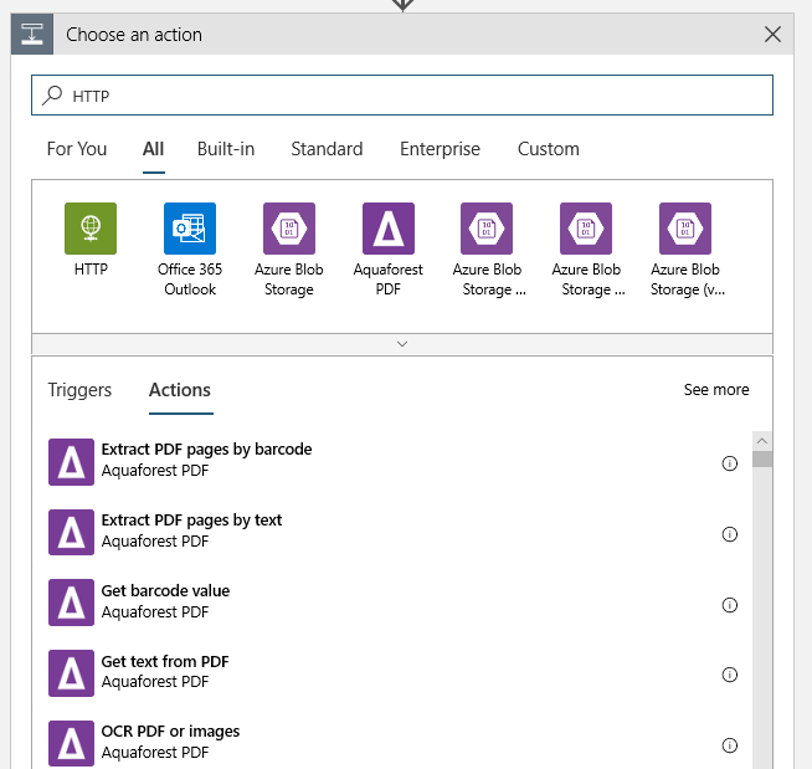
Gunakan pengaturan berikut untuk mengonfigurasi tindakan Anda:
| Pengaturan | Nilai |
|---|---|
| Tindakan HTTP | POST |
| URI | titik akhir ke alur yang diterbitkan yang Anda temukan sebagai Prasyarat |
| Mode autentikasi | Identitas Terkelola |
Siapkan jadwal Anda untuk menetapkan nilai DataPath PipelineParameter apa pun yang mungkin Anda miliki:
{ "DataPathAssignments": { "input_datapath": { "DataStoreName": "<datastore-name>", "RelativePath": "@{triggerBody()?['Name']}" } }, "ExperimentName": "MyRestPipeline", "ParameterAssignments": { "input_string": "sample_string3" }, "RunSource": "SDK" }Gunakan
DataStoreNameyang Anda tambahkan ke ruang kerja sebagai Prasyarat.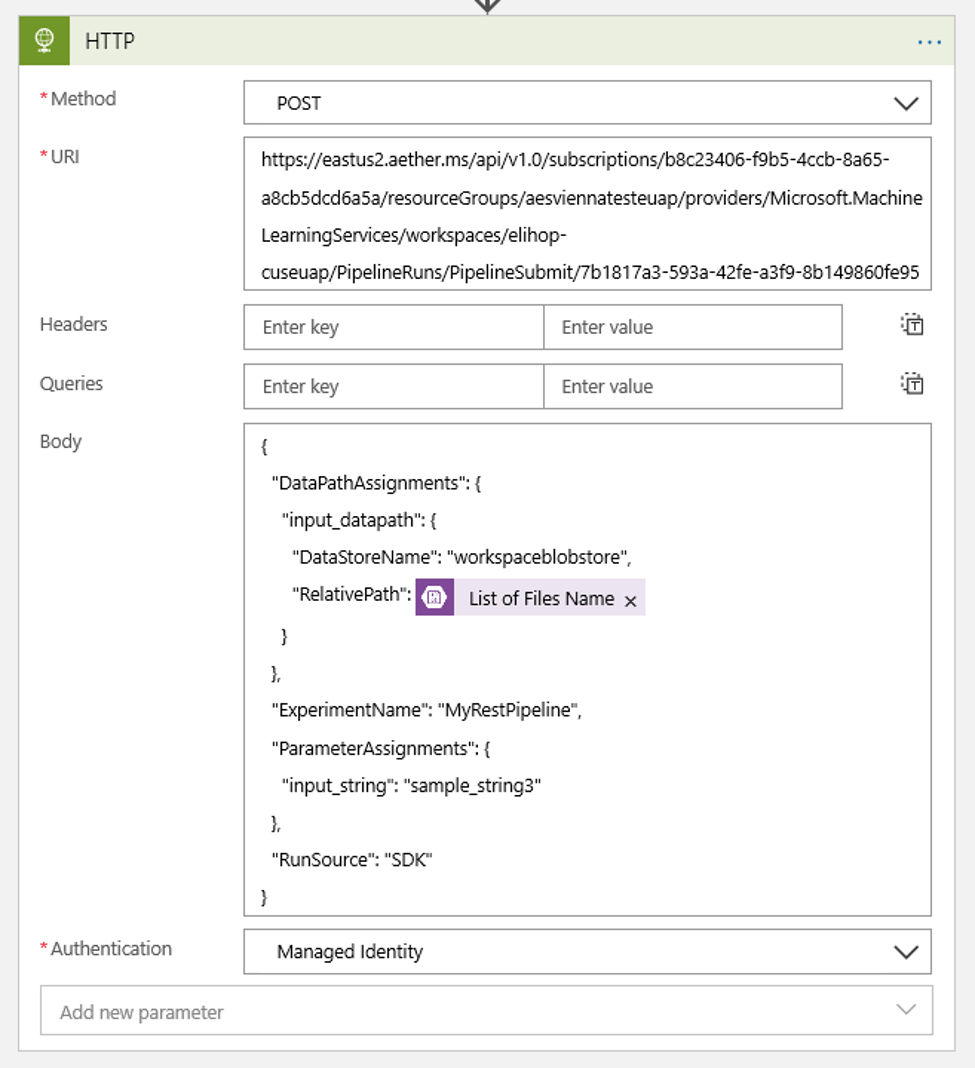
Pilih Simpan dan kini jadwal Anda telah siap.
Penting
Jika Anda menggunakan kontrol akses berbasis peran Azure (RBAC Azure) untuk mengelola akses ke alur Anda, atur izin untuk skenario alur Anda (pelatihan atau penilaian).
Memanggil alur pembelajaran mesin dari alur Azure Data Factory
Dalam alur Azure Data Factory, aktivitas Alur Eksekusi Pembelajaran Mesin menjalankan alur Azure Machine Learning. Anda dapat menemukan aktivitas ini di halaman penulisan Data Factory di kategori Pembelajaran Mesin:
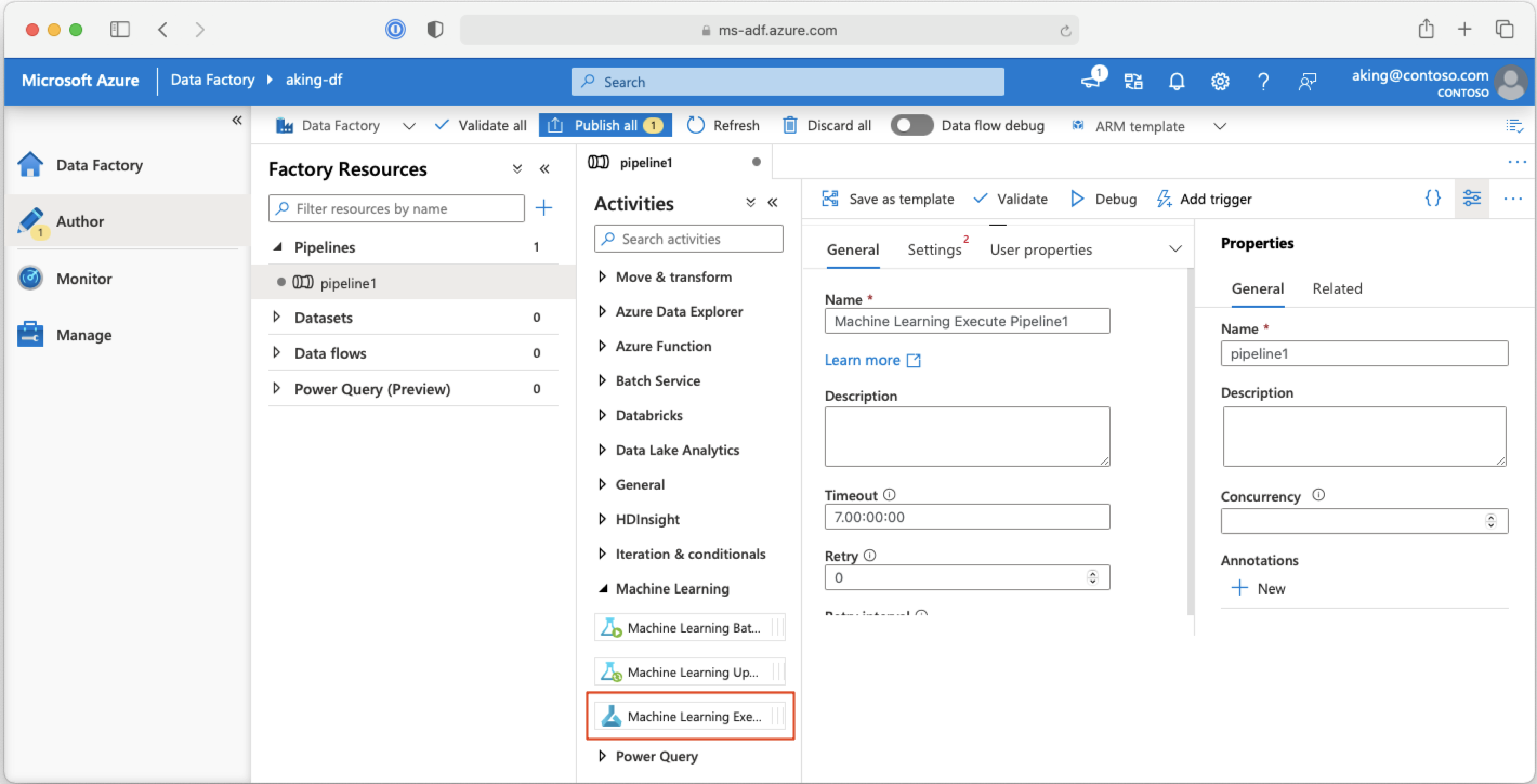
Langkah berikutnya
Dalam artikel ini, Anda menggunakan Azure Machine Learning SDK untuk Python guna menjadwalkan alur dengan dua cara berbeda. Satu jadwal diulang kembali berdasarkan waktu jam yang telah berlalu. Pekerjaan jadwal lainnya jika file dimodifikasi pada Datastore tertentu atau di dalam direktori di penyimpanan tersebut. Anda melihat cara menggunakan portal untuk memeriksa jalur alur dan pekerjaan individu. Anda mempelajari cara menonaktifkan jadwal sehingga alur berhenti berjalan. Terakhir, Anda membuat Azure Logic App untuk memicu alur.
Untuk informasi selengkapnya, lihat:
- Pelajari selengkapnya tentang alur
- Pelajari selengkapnya tentang menjelajahi Azure Machine Learning dengan Jupyter