Menerapkan versi dan melacak himpunan data Azure Machine Learning
BERLAKU UNTUK: Python SDK azureml v1
Python SDK azureml v1
Dalam artikel ini, Anda akan mempelajari cara menerapkan versi dan melacak himpunan data Azure Machine Learning untuk kemampuan reproduksi. Penerapan versi himpunan data menandai status tertentu dari data Anda, sehingga Anda dapat menerapkan versi himpunan data tertentu untuk eksperimen di masa mendatang.
Anda mungkin ingin membuat versi sumber daya Azure Pembelajaran Mesin Anda dalam skenario umum ini:
- Saat data baru tersedia untuk pelatihan ulang
- Saat Anda menerapkan berbagai persiapan data atau pendekatan rekayasa fitur
Prasyarat
SDK Azure Machine Learning untuk Python. SDK ini mencakup paket azureml-datasets
Ruang kerja Azure Machine Learning. Buat ruang kerja baru, atau ambil ruang kerja yang sudah ada dengan sampel kode ini:
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()Himpunan data Azure Pembelajaran Mesin
Mendaftarkan dan mengambil versi himpunan data
Anda dapat membuat versi, menggunakan kembali, dan berbagi himpunan data terdaftar di seluruh eksperimen dan dengan kolega Anda. Anda dapat mendaftarkan beberapa himpunan data dengan nama yang sama, dan mengambil versi tertentu berdasarkan nama dan nomor versi.
Mendaftarkan versi himpunan data
Sampel kode ini mengatur create_new_version parameter himpunan data ke True, untuk mendaftarkan versi baru himpunan data tersebuttitanic_ds. Jika ruang kerja tidak memiliki himpunan data yang titanic_ds sudah ada yang terdaftar, kode akan membuat himpunan data baru dengan nama titanic_ds, dan mengatur versinya ke 1.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Mengambil set data menurut nama
Secara default, Dataset metode class get_by_name() mengembalikan versi terbaru himpunan data yang terdaftar di ruang kerja.
Kode ini mengembalikan himpunan titanic_ds data versi 1.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Praktik terbaik penerapan versi
Saat membuat versi himpunan data, Anda tidak membuat salinan data tambahan dengan ruang kerja. Karena himpunan data adalah referensi ke data di layanan penyimpanan Anda, Anda memiliki satu sumber kebenaran, yang dikelola oleh layanan penyimpanan Anda.
Penting
Jika data yang direferensikan oleh himpunan data Anda ditimpa atau dihapus, panggilan ke versi tertentu dari himpunan data tidak mengembalikan perubahan.
Saat Anda memuat data dari himpunan data, konten data saat ini yang direferensikan oleh himpunan data selalu dimuat. Jika Anda ingin memastikan bahwa setiap versi himpunan data dapat direproduksi, kami sarankan Anda menghindari modifikasi konten data yang direferensikan oleh versi himpunan data. Saat data baru masuk, simpan file data baru ke dalam folder data terpisah, lalu buat versi himpunan data baru untuk menyertakan data dari folder baru tersebut.
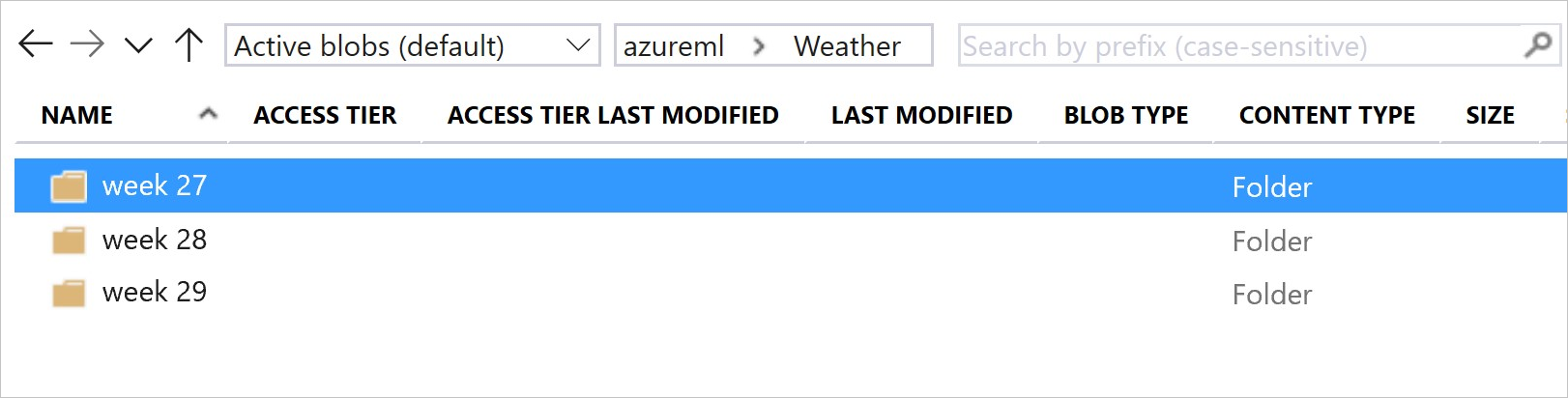
Gambar dan kode sampel ini menunjukkan cara yang direkomendasikan untuk menyusun folder data Anda dan membuat versi himpunan data yang mereferensikan folder tersebut:
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
Menerapkan versi himpunan data output alur ML
Anda dapat menggunakan himpunan data sebagai input dan output dari setiap langkah alur ML. Saat Anda menjalankan ulang alur, output dari setiap langkah alur didaftarkan sebagai versi himpunan data baru.
Pembelajaran Mesin alur mengisi output setiap langkah ke folder baru setiap kali alur dijalankan ulang. Himpunan data output versi kemudian menjadi dapat direproduksi. Untuk informasi selengkapnya, kunjungi himpunan data dalam alur.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Melacak data dalam eksperimen Anda
Azure Machine Learning melacak data di seluruh eksperimen sebagai himpunan data input dan output. Dalam skenario ini, data Anda dilacak sebagai himpunan data input:
DatasetConsumptionConfigSebagai objek, melaluiinputsparameter atauargumentsobjek AndaScriptRunConfig, saat mengirimkan pekerjaan eksperimenKetika skrip Anda memanggil metode tertentu -
get_by_name()atauget_by_id()- misalnya. Nama yang ditetapkan ke himpunan data pada saat Anda mendaftarkan himpunan data tersebut ke ruang kerja adalah nama yang ditampilkan
Dalam skenario ini, data Anda dilacak sebagai himpunan data output:
Teruskan
OutputFileDatasetConfigobjek melaluioutputsparameter atauargumentssaat Anda mengirimkan pekerjaan eksperimen.OutputFileDatasetConfigobjek juga dapat mempertahankan data di antara langkah-langkah alur. Untuk informasi selengkapnya, kunjungi Memindahkan data antara langkah-langkah alur MLMendaftarkan himpunan data di skrip. Nama yang ditetapkan ke himpunan data saat Anda mendaftarkannya ke ruang kerja adalah nama yang ditampilkan. Dalam sampel kode ini,
training_dsadalah nama yang ditampilkan:training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )Pengiriman pekerjaan anak, dengan himpunan data yang tidak terdaftar, dalam skrip. Pengiriman ini menghasilkan himpunan data yang disimpan secara anonim
Melacak himpunan data dalam pekerjaan eksperimen
Untuk setiap eksperimen Pembelajaran Mesin, Anda dapat melacak himpunan data input untuk objek eksperimenJob. Sampel kode ini menggunakan get_details() metode untuk melacak himpunan data input yang digunakan dengan eksekusi eksperimen:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
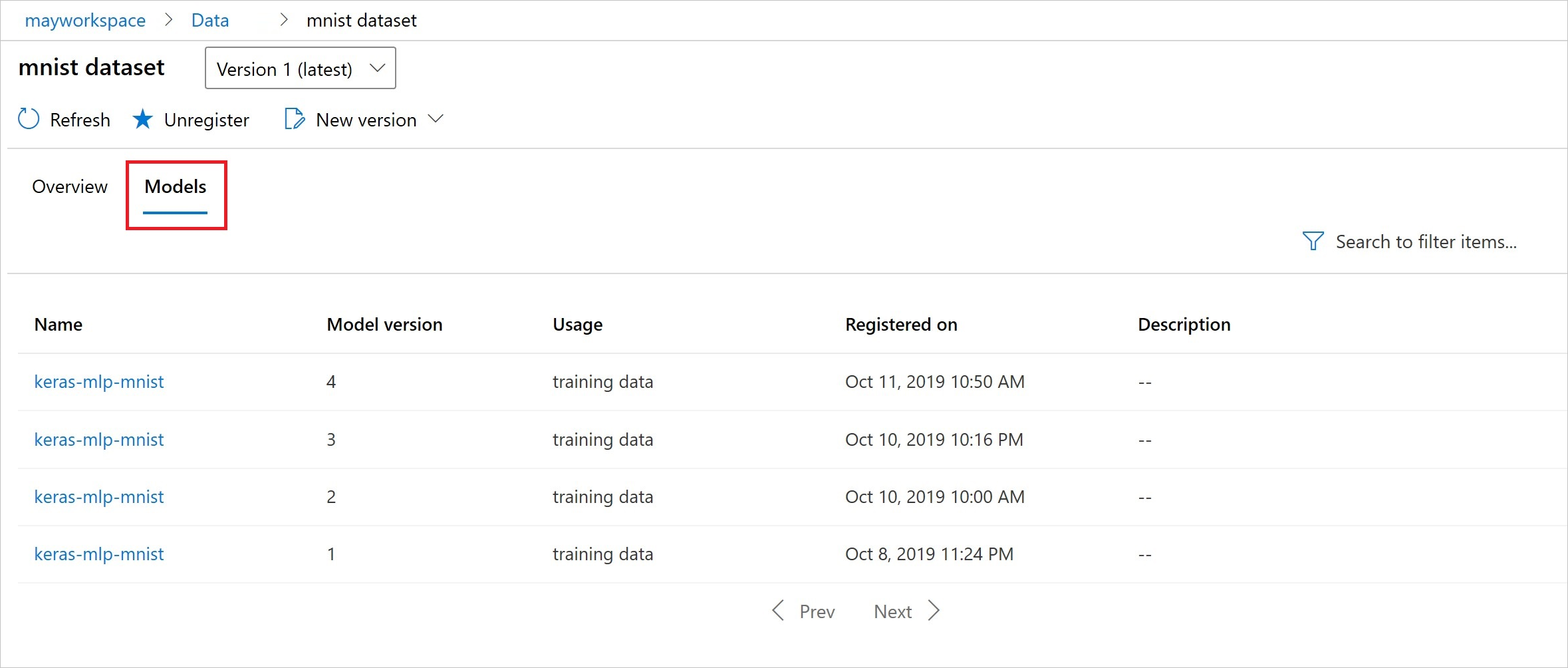
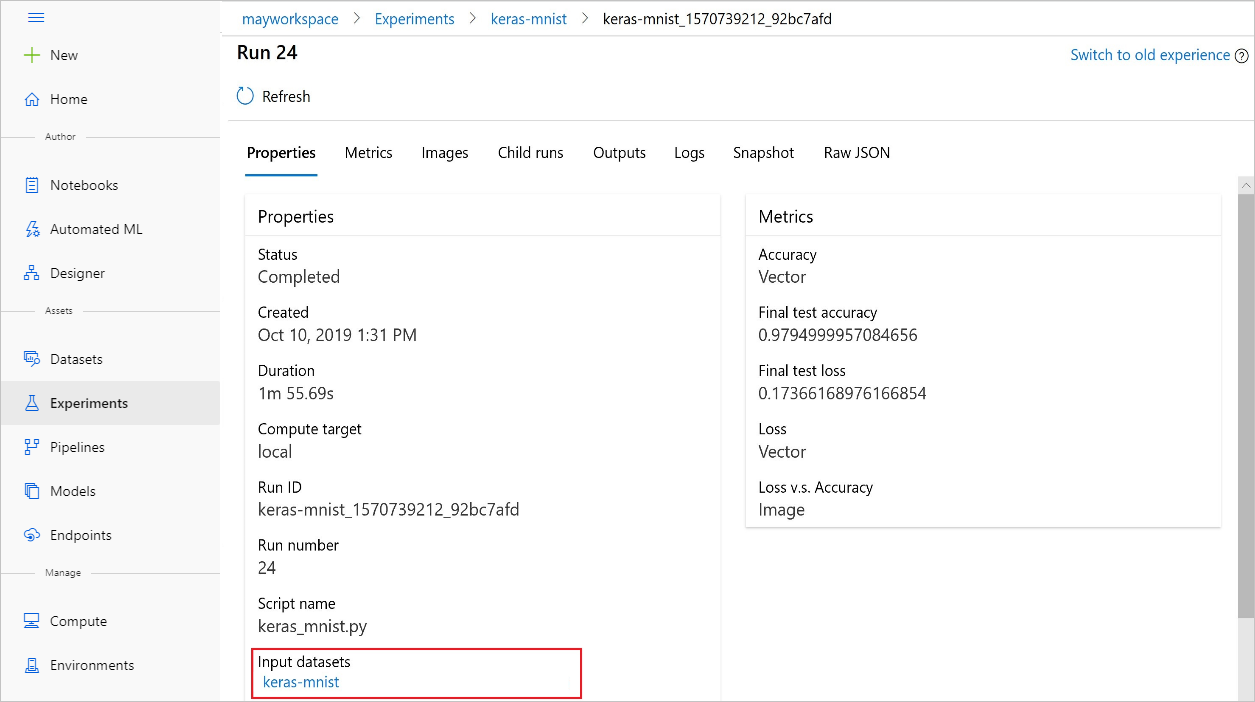
Anda juga dapat menemukan input_datasets dari eksperimen dengan studio Azure Pembelajaran Mesin.
Cuplikan layar ini menunjukkan tempat menemukan himpunan data input eksperimen di studio Azure Pembelajaran Mesin. Untuk contoh ini, mulai di panel Eksperimen Anda, dan buka tab Properti untuk eksekusi eksperimen tertentu, keras-mnist.
Kode ini mendaftarkan model dengan himpunan data:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
Setelah pendaftaran, Anda dapat melihat daftar model yang terdaftar dengan himpunan data dengan Python atau studio.
Cuplikan layar Thia berasal dari panel Himpunan Data di bawah Aset. Pilih himpunan data, lalu pilih tab Model untuk daftar model yang terdaftar dengan himpunan data.