TDSP adalah metodologi ilmu data yang tangkas dan berulang yang dapat Anda gunakan untuk memberikan solusi analitik prediktif dan aplikasi AI secara efisien. TDSP meningkatkan kolaborasi dan pembelajaran tim dengan merekomendasikan cara optimal bagi peran tim untuk bekerja sama. TDSP menggabungkan praktik dan kerangka kerja terbaik dari Microsoft dan pemimpin industri lainnya untuk membantu tim Anda menerapkan inisiatif ilmu data secara efektif. TDSP memungkinkan Anda untuk sepenuhnya mewujudkan manfaat program analitik Anda.
Artikel ini memberikan gambaran umum tentang TDSP dan komponen utamanya. Ini menyajikan panduan tentang cara menerapkan TDSP dengan menggunakan alat dan infrastruktur Microsoft. Anda dapat menemukan sumber daya yang lebih rinci di seluruh artikel.
Komponen utama TDSP
TDSP memiliki komponen utama berikut:
- Definisi siklus hidup ilmu data
- Struktur proyek standar
- Infrastruktur dan sumber daya yang ideal untuk proyek ilmu data
- AI yang bertanggung jawab: dan komitmen terhadap kemajuan AI, didorong oleh prinsip etika
Siklus hidup data science
TDSP menyediakan siklus hidup yang dapat Anda gunakan untuk menyusun pengembangan proyek ilmu data Anda. Siklus hidup menguraikan langkah-langkah lengkap yang diikuti oleh proyek yang berhasil.
Anda dapat menggabungkan TDSP berbasis tugas dengan siklus hidup ilmu data lainnya, seperti proses standar lintas industri untuk penambangan data (CRISP-DM), penemuan pengetahuan dalam proses database (KDD), atau proses kustom lainnya. Pada tingkat tinggi, metodologi yang berbeda ini memiliki banyak kesamaan.
Gunakan siklus hidup ini jika Anda memiliki proyek ilmu data yang merupakan bagian dari aplikasi cerdas. Aplikasi cerdas menyebarkan pembelajaran mesin atau model AI untuk analitik prediktif. Anda juga dapat menggunakan proses ini untuk proyek ilmu data eksplorasi dan proyek analitik improvisasi.
Siklus hidup TDSP terdiri dari lima tahap utama yang dilakukan tim Anda secara berulang. Tahapan ini meliputi:
Berikut adalah representasi visual siklus hidup TDSP:
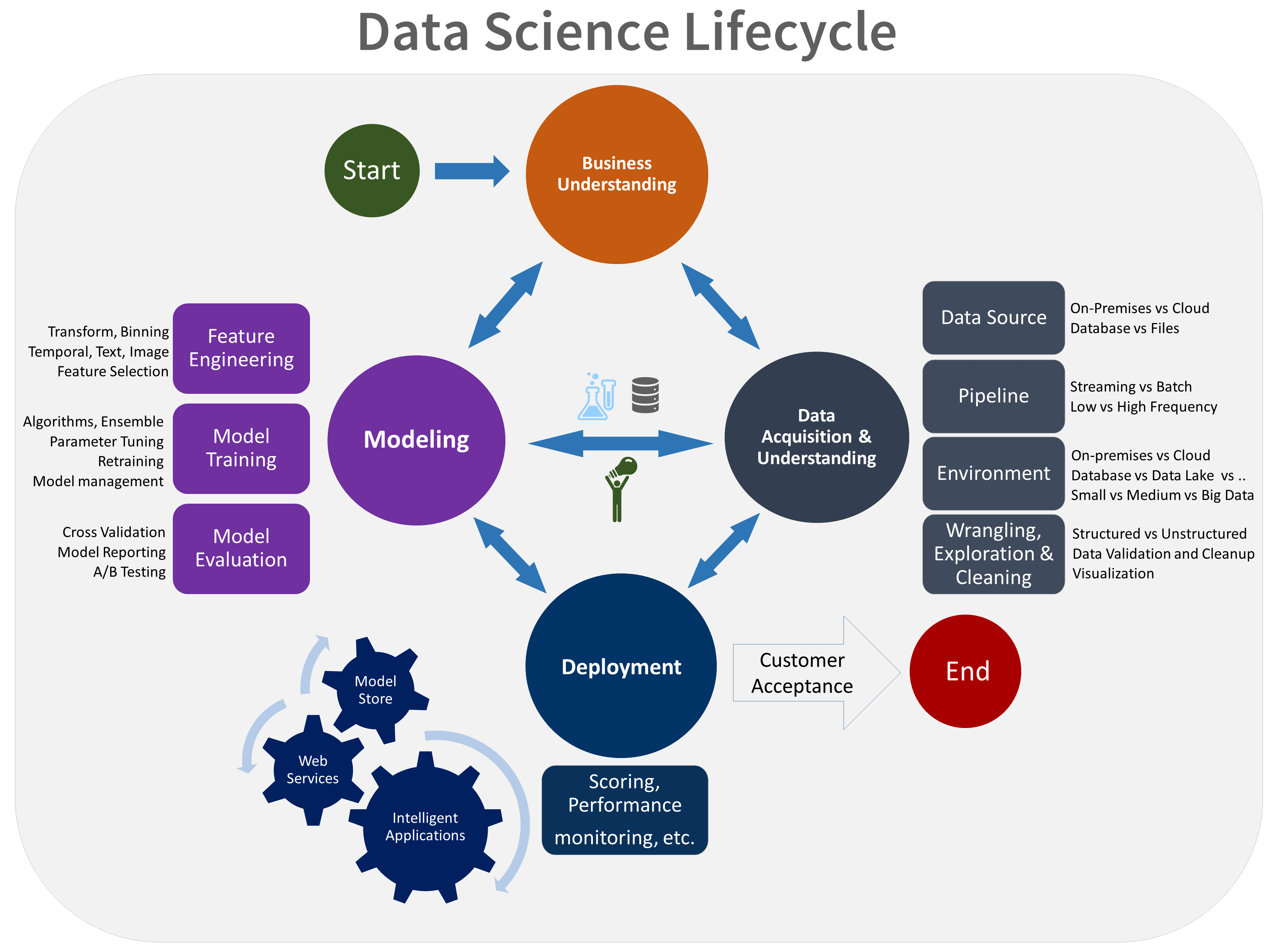
Untuk informasi selengkapnya tentang tujuan, tugas, dan artefak dokumentasi untuk setiap tahap, lihat Siklus hidup TDSP.
Tugas dan artefak ini selaras dengan peran proyek, seperti:
- Arsitek solusi
- Manajer Proyek
- Teknisi data
- Saintis data
- Pengembang aplikasi
- Pemimpin proyek
Diagram berikut menunjukkan tugas (berwarna biru) dan artefak (berwarna hijau) yang sesuai dengan setiap tahap siklus hidup yang digambarkan pada sumbu horizontal dan untuk peran yang digambarkan pada sumbu vertikal.

Struktur proyek yang terstandardisasi
Tim Anda dapat menggunakan infrastruktur Azure untuk mengatur aset ilmu data Anda.
Azure Pembelajaran Mesin mendukung MLflow sumber terbuka. Kami menyarankan agar Anda menggunakan MLflow untuk ilmu data dan manajemen proyek AI. MLflow dirancang untuk mengelola siklus hidup pembelajaran mesin lengkap. Ini melatih dan melayani model pada platform yang berbeda, sehingga Anda dapat menggunakan serangkaian alat yang konsisten terlepas dari tempat eksperimen Anda berjalan. Anda dapat menggunakan MLflow secara lokal di komputer Anda, pada target komputasi jarak jauh, pada komputer virtual, atau pada instans komputasi pembelajaran mesin.
MLflow terdiri dari beberapa fungsi utama:
Melacak eksperimen: Anda dapat menggunakan MLflow untuk melacak eksperimen, termasuk parameter, versi kode, metrik, dan file output. Fitur ini membantu Anda membandingkan eksekusi yang berbeda dan mengelola proses eksperimen secara efisien.
Kode paket: Ini menyediakan format standar untuk mengemas kode pembelajaran mesin, yang mencakup dependensi dan konfigurasi. Kemasan ini memudahkan untuk mereproduksi eksekusi dan berbagi kode dengan orang lain.
Mengelola model: MLflow menyediakan fungsionalitas untuk mengelola dan membuat versi model. Ini mendukung berbagai kerangka kerja pembelajaran mesin sehingga Anda dapat menyimpan, membuat versi, dan melayani model.
Melayani dan menyebarkan model: MLflow mengintegrasikan kemampuan penyajian dan penyebaran model sehingga Anda dapat dengan mudah menyebarkan model di lingkungan yang beragam.
Mendaftarkan model: Anda dapat mengelola siklus hidup model, yang mencakup penerapan versi, transisi tahap, dan anotasi. Anda dapat menggunakan MLflow untuk mempertahankan penyimpanan model terpusat di lingkungan kolaboratif.
Gunakan API dan UI: Di dalam Azure, MLflow dibundel dalam API Pembelajaran Mesin versi 2, sehingga Anda dapat berinteraksi dengan sistem secara terprogram. Anda dapat menggunakan portal Azure untuk berinteraksi dengan UI.
MLflow menyederhanakan dan menstandarkan proses pengembangan pembelajaran mesin, dari eksperimen hingga penyebaran.
Pembelajaran Mesin terintegrasi dengan repositori Git, sehingga Anda dapat menggunakan layanan yang kompatibel dengan Git, seperti GitHub, GitLab, Bitbucket, Azure DevOps, atau layanan lain yang kompatibel dengan Git. Selain aset yang sudah dilacak di Pembelajaran Mesin, tim Anda dapat mengembangkan taksonomi mereka sendiri dalam layanan yang kompatibel dengan Git mereka untuk menyimpan data proyek lain, seperti:
- Dokumentasi
- Data proyek: seperti, laporan proyek akhir
- Laporan data: seperti, kamus data atau laporan kualitas data
- Model: seperti, laporan model
- Kode
- Penyiapan data
- Pengembangan model
- Operasionalisasi, yang mencakup keamanan dan kepatuhan
Infrastruktur dan sumber daya
TDSP memberikan rekomendasi tentang cara mengelola analitik bersama dan infrastruktur penyimpanan dalam kategori berikut:
- Sistem file cloud untuk menyimpan himpunan data
- Database cloud
- Kluster big data yang menggunakan SQL atau Spark
- AI dan layanan pembelajaran mesin
Sistem file cloud untuk menyimpan himpunan data
Sistem file cloud sangat penting bagi TDSP karena beberapa alasan:
Penyimpanan data terpusat: Sistem file cloud menyediakan lokasi terpusat untuk menyimpan himpunan data, yang penting untuk kolaborasi di antara anggota tim ilmu data. Sentralisasi memastikan bahwa semua anggota tim dapat mengakses data terbaru, dan mengurangi risiko bekerja dengan himpunan data yang ketinggalan jaman atau tidak konsisten.
Skalabilitas: Sistem file cloud dapat menangani data dalam volume besar, yang umum dalam proyek ilmu data. Sistem file menyediakan solusi penyimpanan yang dapat diskalakan yang tumbuh dengan kebutuhan proyek. Mereka memungkinkan tim untuk menyimpan dan memproses himpunan data besar-besaran tanpa khawatir tentang keterbatasan perangkat keras.
Aksesibilitas: Dengan sistem file cloud, Anda dapat mengakses data dari mana saja dengan koneksi internet. Akses ini penting untuk tim terdistribusi atau ketika anggota tim perlu bekerja dari jarak jauh. Sistem file cloud memfasilitasi kolaborasi yang mulus dan memastikan bahwa data selalu dapat diakses.
Keamanan dan kepatuhan: Penyedia cloud sering menerapkan langkah-langkah keamanan yang kuat, yang mencakup enkripsi, kontrol akses, dan kepatuhan terhadap standar dan peraturan industri. Langkah-langkah keamanan yang kuat dapat melindungi data sensitif dan membantu tim Anda memenuhi persyaratan hukum dan peraturan.
Kontrol versi: Sistem file cloud sering menyertakan fitur kontrol versi, yang dapat digunakan tim untuk melacak perubahan pada himpunan data dari waktu ke waktu. Kontrol versi sangat penting untuk menjaga integritas data dan mereproduksi hasil dalam proyek ilmu data. Ini juga membantu Anda mengaudit dan memecahkan masalah apa pun yang muncul.
Integrasi dengan alat: Sistem file cloud dapat diintegrasikan dengan mulus dengan berbagai alat dan platform ilmu data. Integrasi alat mendukung penyerapan data, pemrosesan data, dan analisis data yang lebih mudah. Misalnya, Azure Storage terintegrasi dengan baik dengan Pembelajaran Mesin, Azure Databricks, dan alat ilmu data lainnya.
Kolaborasi dan berbagi: Sistem file cloud memudahkan untuk berbagi himpunan data dengan anggota tim atau pemangku kepentingan lainnya. Sistem ini mendukung fitur kolaboratif seperti folder bersama dan manajemen izin. Fitur kolaborasi memfasilitasi kerja tim dan memastikan bahwa orang yang tepat memiliki akses ke data yang mereka butuhkan.
Efisiensi biaya: Sistem file cloud dapat lebih hemat biaya daripada mempertahankan solusi penyimpanan lokal. Penyedia cloud memiliki model harga fleksibel yang mencakup opsi bayar sesuai penggunaan, yang dapat membantu mengelola biaya berdasarkan persyaratan penggunaan dan penyimpanan aktual proyek ilmu data Anda.
Pemulihan bencana: Sistem file cloud biasanya menyertakan fitur untuk pencadangan data dan pemulihan bencana. Fitur-fitur ini membantu melindungi data dari kegagalan perangkat keras, penghapusan yang tidak disengaja, dan bencana lainnya. Ini memberikan ketenangan pikiran dan mendukung kelangsungan dalam operasi ilmu data.
Otomatisasi dan integrasi alur kerja: Sistem penyimpanan cloud dapat diintegrasikan ke dalam alur kerja otomatis, yang memungkinkan transfer data yang mulus antara berbagai tahap proses ilmu data. Otomatisasi dapat membantu meningkatkan efisiensi dan mengurangi upaya manual yang diperlukan untuk mengelola data.
Sumber daya Azure yang direkomendasikan untuk sistem file cloud
- Azure Blob Storage - Dokumentasi komprehensif tentang Azure Blob Storage, yang merupakan layanan penyimpanan objek yang dapat diskalakan untuk data yang tidak terstruktur.
- Azure Data Lake Storage - Informasi tentang Azure Data Lake Storage Gen2, dirancang untuk analitik big data dan mendukung himpunan data skala besar.
- Azure Files - Detail tentang Azure Files, yang menyediakan berbagi file yang dikelola sepenuhnya di cloud.
Singkatnya, sistem file cloud sangat penting bagi TDSP karena menyediakan solusi penyimpanan yang dapat diskalakan, aman, dan dapat diakses yang mendukung seluruh siklus hidup data. Sistem file cloud memungkinkan integrasi data yang mulus dari berbagai sumber, yang mendukung akuisisi dan pemahaman data yang komprehensif. Ilmuwan data dapat menggunakan sistem file cloud untuk menyimpan, mengelola, dan mengakses himpunan data besar secara efisien. Fungsionalitas ini sangat penting untuk melatih dan menyebarkan model pembelajaran mesin. Sistem ini juga meningkatkan kolaborasi dengan memungkinkan anggota tim untuk berbagi dan mengerjakan data secara bersamaan dalam lingkungan terpadu. Sistem file cloud menyediakan fitur keamanan yang kuat yang membantu melindungi data dan membuatnya sesuai dengan persyaratan peraturan, yang sangat penting untuk menjaga integritas dan kepercayaan data.
Database cloud
Database cloud memainkan peran penting dalam TDSP karena beberapa alasan:
Skalabilitas: Database cloud menyediakan solusi yang dapat diskalakan yang dapat dengan mudah tumbuh untuk memenuhi kebutuhan data proyek yang meningkat. Skalabilitas sangat penting untuk proyek ilmu data yang sering menangani himpunan data besar dan rumit. Database cloud dapat menangani berbagai beban kerja tanpa perlu intervensi manual atau peningkatan perangkat keras.
Pengoptimalan performa: Pengembang mengoptimalkan database cloud untuk performa dengan menggunakan kemampuan seperti pengindeksan otomatis, pengoptimalan kueri, dan penyeimbangan beban. Fitur-fitur ini membantu memastikan bahwa pengambilan dan pemrosesan data cepat dan efisien, yang sangat penting untuk tugas ilmu data yang memerlukan akses data real time atau hampir real-time.
Aksesibilitas dan kolaborasi: Teams dapat mengakses data yang disimpan di database cloud dari lokasi mana pun. Aksesibilitas ini menumbuhkan kolaborasi di antara anggota tim yang mungkin tersebar secara geografis. Aksesibilitas dan kolaborasi penting bagi tim terdistribusi atau orang yang bekerja dari jarak jauh. Database cloud mendukung lingkungan multi-pengguna yang memungkinkan akses dan kolaborasi simultan.
Integrasi dengan alat ilmu data: Database cloud terintegrasi dengan mulus dengan berbagai alat dan platform ilmu data. Misalnya, database cloud Azure terintegrasi dengan baik dengan Pembelajaran Mesin, Power BI, dan alat analitik data lainnya. Integrasi ini menyederhanakan alur data, dari penyerapan dan penyimpanan hingga analisis dan visualisasi.
Keamanan dan kepatuhan: Penyedia cloud menerapkan langkah-langkah keamanan yang kuat yang mencakup enkripsi data, kontrol akses, dan kepatuhan terhadap standar dan peraturan industri. Langkah-langkah keamanan melindungi data sensitif dan membantu tim Anda memenuhi persyaratan hukum dan peraturan. Fitur keamanan sangat penting untuk menjaga integritas dan privasi data.
Efisiensi biaya: Database cloud sering beroperasi pada model bayar sesuai penggunaan, yang bisa lebih hemat biaya daripada mempertahankan sistem database lokal. Fleksibilitas harga ini memungkinkan organisasi mengelola anggaran mereka secara efektif dan hanya membayar penyimpanan dan sumber daya komputasi yang mereka gunakan.
Pencadangan otomatis dan pemulihan bencana: Database cloud menyediakan solusi pencadangan otomatis dan pemulihan bencana. Solusi ini membantu mencegah kehilangan data jika ada kegagalan perangkat keras, penghapusan yang tidak disengaja, atau bencana lainnya. Keandalan sangat penting untuk menjaga kelangsungan dan integritas data dalam proyek ilmu data.
Pemrosesan data real time: Banyak database cloud mendukung pemrosesan dan analitik data real time, yang penting untuk tugas ilmu data yang memerlukan informasi terbaru. Kemampuan ini membantu ilmuwan data membuat keputusan tepat waktu berdasarkan data terbaru yang tersedia.
Integrasi data: Database cloud dapat dengan mudah diintegrasikan dengan sumber data, database, data lake, dan umpan data eksternal lainnya. Integrasi membantu ilmuwan data menggabungkan data dari berbagai sumber dan memberikan tampilan yang komprehensif dan analisis yang lebih canggih.
Fleksibilitas dan variasi: Database cloud hadir dalam berbagai bentuk, seperti database relasional, database NoSQL, dan gudang data. Variasi ini memungkinkan tim ilmu data memilih jenis database terbaik untuk kebutuhan spesifik mereka, apakah mereka memerlukan penyimpanan data terstruktur, penanganan data yang tidak terstruktur, atau analitik data skala besar.
Dukungan untuk analitik tingkat lanjut: Database cloud sering dilengkapi dengan dukungan bawaan untuk analitik tingkat lanjut dan pembelajaran mesin. Misalnya, Azure SQL Database menyediakan layanan pembelajaran mesin bawaan. Layanan ini membantu ilmuwan data melakukan analitik tingkat lanjut langsung dalam lingkungan database.
Sumber daya Azure yang direkomendasikan untuk database cloud
- Azure SQL Database - Dokumentasi di Azure SQL Database, layanan database relasional yang dikelola sepenuhnya.
- Azure Cosmos DB - Informasi tentang Azure Cosmos DB, layanan database multi-model yang didistribusikan secara global.
- Azure Database for PostgreSQL - Panduan untuk Azure Database for PostgreSQL, layanan database terkelola untuk pengembangan dan penyebaran aplikasi.
- Azure Database for MySQL - Detail tentang Azure Database for MySQL, layanan terkelola untuk database MySQL.
Singkatnya, database cloud sangat penting untuk TDSP karena menyediakan solusi penyimpanan dan manajemen data yang dapat diskalakan, andal, dan efisien yang mendukung proyek berbasis data. Mereka memfasilitasi integrasi data yang mulus, yang membantu ilmuwan data menelan, melakukan praproses, dan menganalisis himpunan data besar dari berbagai sumber. Database cloud memungkinkan kueri dan pemrosesan data yang cepat, yang penting untuk mengembangkan, menguji, dan menyebarkan model pembelajaran mesin. Selain itu, database cloud meningkatkan kolaborasi dengan menyediakan platform terpusat bagi anggota tim untuk mengakses dan bekerja dengan data secara bersamaan. Terakhir, database cloud menyediakan fitur keamanan tingkat lanjut dan dukungan kepatuhan untuk menjaga data tetap terlindungi dan sesuai dengan standar peraturan, yang sangat penting untuk menjaga integritas dan kepercayaan data.
Kluster big data yang menggunakan SQL atau Spark
Kluster big data, seperti yang menggunakan SQL atau Spark, sangat mendasar bagi TDSP karena beberapa alasan:
Menangani data dalam volume besar: Kluster big data dirancang untuk menangani data dalam volume besar secara efisien. Proyek ilmu data sering melibatkan himpunan data besar-besaran yang melebihi kapasitas database tradisional. Kluster big data berbasis SQL dan Spark dapat mengelola dan memproses data ini dalam skala besar.
Komputasi terdistribusi: Kluster big data menggunakan komputasi terdistribusi untuk menyebarkan data dan tugas komputasi di beberapa simpul. Kemampuan pemrosesan paralel secara signifikan mempercepat tugas pemrosesan dan analisis data, yang penting untuk mendapatkan wawasan tepat waktu dalam proyek ilmu data.
Skalabilitas: Kluster big data memberikan skalabilitas tinggi, baik secara horizontal dengan menambahkan lebih banyak simpul dan secara vertikal dengan meningkatkan daya simpul yang ada. Skalabilitas membantu memastikan bahwa infrastruktur data tumbuh dengan kebutuhan proyek dengan menangani peningkatan ukuran dan kompleksitas data.
Integrasi dengan alat ilmu data: Kluster big data terintegrasi dengan baik dengan berbagai alat dan platform ilmu data. Misalnya, Spark terintegrasi dengan mulus dengan Hadoop, dan kluster SQL berfungsi dengan berbagai alat analisis data. Integrasi memfasilitasi alur kerja yang lancar dari penyerapan data hingga analisis dan visualisasi.
Analitik tingkat lanjut: Kluster big data mendukung analitik tingkat lanjut dan pembelajaran mesin. Misalnya, Spark menyediakan pustaka bawaan berikut:
- Pembelajaran mesin, MLlib
- Pemrosesan grafik, GraphX
- Pemrosesan streaming, Spark Streaming
Kemampuan ini membantu ilmuwan data melakukan analitik kompleks langsung dalam kluster.
Pemrosesan data real time: Kluster big data, terutama yang menggunakan Spark, mendukung pemrosesan data real time. Kemampuan ini sangat penting untuk proyek yang memerlukan analisis data up-to-the-minute dan pengambilan keputusan. Pemrosesan real time membantu dalam skenario seperti deteksi penipuan, rekomendasi real-time, dan harga dinamis.
Transformasi dan ekstrak data, transformasi, pemuatan (ETL): Kluster big data sangat ideal untuk transformasi data dan proses ETL. Mereka dapat menangani transformasi data, pembersihan, dan tugas agregasi yang kompleks secara efisien, yang sering diperlukan sebelum data dapat dianalisis.
Efisiensi biaya: Kluster big data dapat hemat biaya, terutama ketika Anda menggunakan solusi berbasis cloud seperti Azure Databricks dan layanan cloud lainnya. Layanan ini menyediakan model harga fleksibel yang mencakup bayar sesuai pemakaian, yang bisa lebih ekonomis daripada mempertahankan infrastruktur big data lokal.
Toleransi kesalahan: Kluster big data dirancang dengan ingat toleransi kesalahan. Mereka mereplikasi data di seluruh simpul untuk membantu memastikan bahwa sistem tetap beroperasi meskipun beberapa simpul gagal. Keandalan ini sangat penting untuk menjaga integritas dan ketersediaan data dalam proyek ilmu data.
Integrasi data lake: Kluster big data sering diintegrasikan dengan mulus dengan data lake, yang memungkinkan ilmuwan data mengakses dan menganalisis sumber data yang beragam dengan cara terpadu. Integrasi menumbuhkan analisis yang lebih komprehensif dengan mendukung kombinasi data terstruktur dan tidak terstruktur.
Pemrosesan berbasis SQL: Untuk ilmuwan data yang terbiasa dengan SQL, kluster big data yang bekerja dengan kueri SQL, seperti Spark SQL atau SQL di Hadoop, menyediakan antarmuka yang familier untuk mengkueri dan menganalisis big data. Kemudahan penggunaan ini dapat mempercepat proses analisis dan membuatnya lebih mudah diakses oleh berbagai pengguna.
Kolaborasi dan berbagi: Kluster big data mendukung lingkungan kolaboratif di mana beberapa ilmuwan dan analis data dapat bekerja sama pada himpunan data yang sama. Mereka menyediakan fitur untuk berbagi kode, notebook, dan hasil yang menumbuhkan kerja tim dan berbagi pengetahuan.
Keamanan dan kepatuhan: Kluster big data menyediakan fitur keamanan yang kuat, seperti enkripsi data, kontrol akses, dan kepatuhan terhadap standar industri. Fitur keamanan melindungi data sensitif dan membantu tim Anda memenuhi persyaratan peraturan.
Sumber daya Azure yang direkomendasikan untuk kluster big data
- Apache Spark dalam Pembelajaran Mesin: integrasi Pembelajaran Mesin dengan Azure Synapse Analytics menyediakan akses mudah ke sumber daya komputasi terdistribusi melalui kerangka kerja Apache Spark.
- Azure Synapse Analytics: Dokumentasi komprehensif untuk Azure Synapse Analytics, yang mengintegrasikan big data dan pergudangan data.
Singkatnya, kluster big data, baik SQL atau Spark, sangat penting untuk TDSP, karena memberikan daya komputasi dan skalabilitas yang diperlukan untuk menangani data dalam jumlah besar secara efisien. Kluster big data memungkinkan ilmuwan data untuk melakukan kueri kompleks dan analitik tingkat lanjut pada himpunan data besar yang memfasilitasi wawasan mendalam, dan pengembangan model yang akurat. Saat Anda menggunakan komputasi terdistribusi, kluster ini memungkinkan pemrosesan dan analisis data yang cepat, yang mempercepat alur kerja ilmu data secara keseluruhan. Kluster big data juga mendukung integrasi yang mulus dengan berbagai sumber dan alat data, yang meningkatkan kemampuan untuk menyerap, memproses, dan menganalisis data dari beberapa lingkungan. Kluster big data juga mempromosikan kolaborasi dan reproduksi dengan menyediakan platform terpadu di mana tim dapat berbagi sumber daya, alur kerja, dan hasil secara efektif.
AI dan layanan pembelajaran mesin
Layanan AI dan pembelajaran mesin (ML) terintegrasi dengan TDSP karena beberapa alasan:
Analitik tingkat lanjut: Layanan AI dan ML memungkinkan analitik tingkat lanjut. Ilmuwan data dapat menggunakan analitik tingkat lanjut untuk mengungkap pola kompleks, membuat prediksi, dan menghasilkan wawasan yang tidak dimungkinkan dengan metode analitik tradisional. Kemampuan canggih ini sangat penting untuk menciptakan solusi ilmu data berdampak tinggi.
Otomatisasi tugas berulang: Layanan AI dan ML dapat mengotomatiskan tugas berulang, seperti pembersihan data, rekayasa fitur, dan pelatihan model. Automation menghemat waktu dan membantu ilmuwan data berfokus pada aspek proyek yang lebih strategis, yang meningkatkan produktivitas secara keseluruhan.
Peningkatan akurasi dan performa: Model ML dapat meningkatkan akurasi dan performa prediksi dan analisis dengan belajar dari data. Model-model ini dapat terus meningkat saat terekspos ke lebih banyak data, yang mengarah pada pengambilan keputusan yang lebih baik dan hasil yang lebih andal.
Skalabilitas: Layanan AI dan ML yang disediakan oleh platform cloud, seperti Pembelajaran Mesin, sangat dapat diskalakan. Mereka dapat menangani data dalam volume besar dan komputasi kompleks, yang membantu tim ilmu data menskalakan solusi mereka untuk memenuhi tuntutan yang berkembang tanpa khawatir tentang keterbatasan infrastruktur yang mendasar.
Integrasi dengan alat lain: Layanan AI dan ML terintegrasi dengan mulus dengan alat dan layanan lain dalam ekosistem Microsoft, seperti Azure Data Lake, Azure Databricks, dan Power BI. Integrasi mendukung alur kerja yang disederhanakan dari penyerapan dan pemrosesan data ke penyebaran dan visualisasi model.
Penyebaran dan manajemen model: Layanan AI dan ML menyediakan alat yang kuat untuk menyebarkan dan mengelola model pembelajaran mesin dalam produksi. Fitur seperti kontrol versi, pemantauan, dan pelatihan ulang otomatis membantu memastikan bahwa model tetap akurat dan efektif dari waktu ke waktu. Pendekatan ini menyederhanakan pemeliharaan solusi ML.
Pemrosesan real time: Layanan AI dan ML mendukung pemrosesan data real time dan pengambilan keputusan. Pemrosesan real time sangat penting untuk aplikasi yang memerlukan wawasan dan tindakan langsung, seperti deteksi penipuan, harga dinamis, dan sistem rekomendasi.
Penyesuaian dan fleksibilitas: Layanan AI dan ML menyediakan berbagai opsi yang dapat disesuaikan, mulai dari model dan API bawaan hingga kerangka kerja untuk membangun model kustom dari awal. Fleksibilitas ini membantu tim ilmu data menyesuaikan solusi dengan kebutuhan bisnis dan kasus penggunaan tertentu.
Akses ke algoritma mutakhir: Layanan AI dan ML memberi ilmuwan data akses ke algoritma dan teknologi mutakhir yang dikembangkan oleh peneliti terkemuka. Access memastikan bahwa tim dapat menggunakan kemajuan terbaru dalam AI dan ML untuk proyek mereka.
Kolaborasi dan berbagi: Platform AI dan ML mendukung lingkungan pengembangan kolaboratif, di mana beberapa anggota tim dapat bekerja sama pada proyek yang sama, berbagi kode, dan mereproduksi eksperimen. Kolaborasi meningkatkan kerja tim dan membantu memastikan konsistensi dalam pengembangan model.
Efisiensi biaya: Layanan AI dan ML di cloud bisa lebih hemat biaya daripada membangun dan memelihara solusi lokal. Penyedia cloud memiliki model harga fleksibel yang mencakup opsi bayar sesuai penggunaan, yang dapat mengurangi biaya dan mengoptimalkan penggunaan sumber daya.
Keamanan dan kepatuhan yang ditingkatkan: Layanan AI dan ML dilengkapi dengan fitur keamanan yang kuat, yang mencakup enkripsi data, kontrol akses yang aman, dan kepatuhan terhadap standar dan peraturan industri. Fitur-fitur ini membantu melindungi data dan model Anda dan memenuhi persyaratan hukum dan peraturan.
Model dan API bawaan: Banyak layanan AI dan ML menyediakan model dan API bawaan untuk tugas umum seperti pemrosesan bahasa alami, pengenalan gambar, dan deteksi anomali. Solusi bawaan dapat mempercepat pengembangan dan penyebaran dan membantu tim dengan cepat mengintegrasikan kemampuan AI ke dalam aplikasi mereka.
Eksperimen dan prototipe: Platform AI dan ML menyediakan lingkungan untuk eksperimen dan prototipe yang cepat. Ilmuwan data dapat dengan cepat menguji algoritma, parameter, dan himpunan data yang berbeda untuk menemukan solusi terbaik. Eksperimen dan prototipe mendukung pendekatan berulang untuk pengembangan model.
Sumber daya Azure yang direkomendasikan untuk layanan AI dan ML
Pembelajaran Mesin adalah sumber daya utama yang kami rekomendasikan untuk aplikasi ilmu data dan TDSP. Selain itu, Azure menyediakan layanan AI yang memiliki model AI siap digunakan untuk aplikasi tertentu.
- Pembelajaran Mesin: Halaman dokumentasi utama untuk Pembelajaran Mesin yang mencakup penyiapan, pelatihan model, penyebaran, dan sebagainya.
- Layanan Azure AI: Informasi tentang layanan AI yang menyediakan model AI bawaan untuk tugas visi, ucapan, bahasa, dan pengambilan keputusan.
Singkatnya, layanan AI dan ML sangat penting untuk TDSP, karena mereka menyediakan alat dan kerangka kerja yang kuat yang menyederhanakan pengembangan, pelatihan, dan penyebaran model pembelajaran mesin. Layanan ini mengotomatiskan tugas kompleks seperti pemilihan algoritma dan penyetelan hiperparameter, yang sangat mempercepat proses pengembangan model. Layanan ini juga menyediakan infrastruktur yang dapat diskalakan yang membantu ilmuwan data menangani himpunan data besar secara efisien dan tugas intensif komputasi. Alat AI dan ML terintegrasi dengan mulus dengan layanan Azure lainnya dan meningkatkan penyerapan data, praproses, dan penyebaran model. Integrasi membantu memastikan alur kerja end-to-end yang lancar. Selain itu, layanan ini menumbuhkan kolaborasi dan reproduktifitas. Tim dapat berbagi wawasan dan bereksperimen secara efektif dengan hasil dan model sambil mempertahankan standar keamanan dan kepatuhan yang tinggi.
AI yang Bertanggung Jawab
Dengan solusi AI atau ML, Microsoft mempromosikan alat AI yang bertanggung jawab dalam solusi AI dan ML-nya. Alat-alat ini mendukung Microsoft Responsible AI Standard. Beban kerja Anda masih harus mengatasi bahaya terkait AI secara individual.
Kutipan yang ditinjau serekan
TDSP adalah metodologi mapan yang digunakan tim di seluruh keterlibatan Microsoft. TDSP didokumenkan dan dipelajari dalam sastra yang ditinjau serekan. Kutipan memberikan kesempatan untuk menyelidiki fitur dan aplikasi TDSP. Untuk informasi selengkapnya dan daftar kutipan, lihat Siklus hidup TDSP.