Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menjelaskan cara mengembangkan skrip pelatihan dengan menggunakan buku catatan di stasiun kerja cloud Azure Machine Learning. Tutorial ini mencakup langkah-langkah dasar yang Anda butuhkan untuk memulai:
- Siapkan dan konfigurasikan stasiun kerja cloud. Stasiun kerja cloud Anda didukung oleh instans komputasi Azure Machine Learning, yang telah dikonfigurasi sebelumnya dengan lingkungan untuk mendukung kebutuhan pengembangan model Anda.
- Gunakan lingkungan pengembangan berbasis cloud.
- Gunakan MLflow untuk melacak metrik model Anda.
Prasyarat
Untuk menggunakan Azure Pembelajaran Mesin, Anda memerlukan ruang kerja. Jika Anda tidak memilikinya, selesaikan Buat sumber daya yang Anda perlukan untuk mulai membuat ruang kerja dan pelajari selengkapnya tentang menggunakannya.
Penting
Jika ruang kerja Azure Pembelajaran Mesin Anda dikonfigurasi dengan jaringan virtual terkelola, Anda mungkin perlu menambahkan aturan keluar untuk mengizinkan akses ke repositori paket Python publik. Untuk informasi selengkapnya, lihat Skenario: Mengakses paket pembelajaran mesin publik.
Membuat atau memulai komputasi
Anda dapat membuat sumber daya komputasi di bagian Komputasi di ruang kerja Anda. Instans komputasi adalah stasiun kerja berbasis cloud yang dikelola sepenuhnya oleh Azure Machine Learning. Seri tutorial ini menggunakan instans komputasi. Anda juga dapat menggunakannya untuk menjalankan kode Anda sendiri, dan untuk mengembangkan dan menguji model.
- Masuk ke Studio Azure Machine Learning.
- Pilih ruang kerja Anda jika belum terbuka.
- Di panel kiri, pilih Komputasi.
- Jika Anda tidak memiliki instans komputasi, Anda akan melihat Baru di tengah halaman. Pilih Baru dan isi formulir. Anda dapat menggunakan semua default.
- Jika Anda memiliki instans komputasi, pilih instans tersebut dari daftar. Jika dihentikan, pilih Mulai.
Buka Visual Studio Code (VISUAL Code)
Setelah Anda memiliki instans komputasi yang sedang berjalan, Anda dapat mengaksesnya dengan berbagai cara. Tutorial ini menjelaskan cara menggunakan instans komputasi dari Visual Studio Code. Visual Studio Code menyediakan lingkungan pengembangan terintegrasi penuh (IDE) untuk membuat instans komputasi.
Dalam daftar instans komputasi, pilih tautan Visual Studio Code (Web) atau VISUAL Code (Desktop) untuk instans komputasi yang ingin Anda gunakan. Jika Anda memilih Visual Studio Code (Desktop), Anda mungkin melihat pesan yang menanyakan apakah Anda ingin membuka aplikasi.

Instans Visual Studio Code ini dilampirkan ke instans komputasi dan sistem file ruang kerja Anda. Bahkan jika Anda membukanya di desktop, file yang Anda lihat adalah file di ruang kerja Anda.
Menyiapkan lingkungan baru untuk pembuatan prototipe
Agar skrip Anda berjalan, Anda harus bekerja di lingkungan yang dikonfigurasi dengan ketergantungan dan pustaka yang diperlukan oleh kode. Bagian ini membantu Anda membuat lingkungan yang disesuaikan dengan kode Anda. Untuk membuat kernel Jupyter baru yang tersambung dengan notebook Anda, Anda menggunakan file YAML yang menentukan dependensi.
Unggah file.
File yang Anda unggah disimpan dalam berbagi file Azure, dan file-file ini dipasang ke setiap instans komputasi dan dibagikan dalam ruang kerja.
Buka azureml-examples/tutorials/get-started-notebooks/workstation_env.yml.
Unduh file lingkungan Conda workstation_env.yml ke komputer Anda dengan memilih tombol elipsis (...) di sudut kanan atas halaman lalu pilih Unduh.
Seret file dari komputer Anda ke jendela Visual Studio Code. File diunggah ke ruang kerja Anda.
Pindahkan file ke folder nama pengguna Anda.
Pilih file untuk mempratinjaunya. Tinjau dependensi yang ditentukannya. Anda seharusnya melihat sesuatu seperti berikut:
name: workstation_env # This file serves as an example - you can update packages or versions to fit your use case dependencies: - python=3.8 - pip=21.2.4 - scikit-learn=0.24.2 - scipy=1.7.1 - pandas>=1.1,<1.2 - pip: - mlflow-skinny - azureml-mlflow - psutil>=5.8,<5.9 - ipykernel~=6.0 - matplotlibBuat kernel.
Sekarang gunakan terminal untuk membuat kernel Jupyter baru yang didasarkan pada file workstation_env.yml .
- Di menu di bagian atas Visual Studio Code, pilih Terminal Baru>.
Lihat lingkungan Conda Anda saat ini. Lingkungan aktif ditandai dengan tanda bintang (*).
conda env listGunakan
cduntuk menavigasi ke folder tempat Anda mengunggah file workstation_env.yml . Misalnya, jika Anda mengunggahnya ke folder pengguna, gunakan perintah ini:cd Users/myusernamePastikan workstation_env.yml ada di folder .
lsBuat lingkungan berdasarkan file Conda yang disediakan. Dibutuhkan beberapa menit untuk membangun lingkungan.
conda env create -f workstation_env.ymlAktifkan lingkungan baru.
conda activate workstation_envCatatan
Jika Anda melihat CommandNotFoundError, ikuti instruksi untuk menjalankan
conda init bash, tutup terminal, lalu buka yang baru. Kemudian coba perintah lagiconda activate workstation_env.Pastikan bahwa lingkungan yang benar sedang aktif, kemudian cari lagi lingkungan yang ditandai dengan *.
conda env listBuat kernel Jupyter baru yang didasarkan pada lingkungan aktif Anda.
python -m ipykernel install --user --name workstation_env --display-name "Tutorial Workstation Env"Tutup jendela terminal.
Anda sekarang memiliki kernel baru. Selanjutnya, Anda akan membuka notebook dan menggunakan kernel ini.
Membuat notebook
- Di menu di bagian atas Visual Studio Code, pilih File > File Baru.
- Beri nama file baru Anda develop-tutorial.ipynb (atau gunakan nama lain). Pastikan untuk menggunakan ekstensi .ipynb .
Mengatur kernel
- Di sudut kanan atas file baru, pilih Pilih Kernel.
- Pilih instans komputasi Azure ML (computeinstance-name).
- Pilih kernel yang Anda buat: Tutorial Workstation Env. Jika Anda tidak melihat kernel, pilih tombol refresh di atas daftar.
Mengembangkan skrip pelatihan
Di bagian ini, Anda mengembangkan skrip pelatihan Python yang memprediksi pembayaran default kartu kredit dengan menggunakan himpunan data pengujian dan pelatihan yang disiapkan dari himpunan data UCI.
Kode ini menggunakan sklearn untuk melatih dan MLflow untuk pencatatan metrik.
Mulailah dengan kode yang mengimpor paket dan pustaka yang akan Anda gunakan dalam skrip pelatihan.
import os import argparse import pandas as pd import mlflow import mlflow.sklearn from sklearn.ensemble import GradientBoostingClassifier from sklearn.metrics import classification_report from sklearn.model_selection import train_test_splitSelanjutnya, muat dan proses data untuk eksperimen. Dalam tutorial ini, Anda membaca data dari file di internet.
# load the data credit_df = pd.read_csv( "https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv", header=1, index_col=0, ) train_df, test_df = train_test_split( credit_df, test_size=0.25, )Siapkan data untuk pelatihan.
# Extracting the label column y_train = train_df.pop("default payment next month") # convert the dataframe values to array X_train = train_df.values # Extracting the label column y_test = test_df.pop("default payment next month") # convert the dataframe values to array X_test = test_df.valuesTambahkan kode untuk memulai autologging dengan MLflow sehingga Anda dapat melacak metrik dan hasilnya. Dengan sifat iteratif pengembangan model, MLflow membantu Anda mencatat parameter dan hasil model. Lihat berbagai eksekusi untuk membandingkan dan memahami performa model Anda. Log juga menyediakan konteks saat Anda siap untuk berpindah dari fase pengembangan ke fase pelatihan alur kerja Anda dalam Azure Pembelajaran Mesin.
# set name for logging mlflow.set_experiment("Develop on cloud tutorial") # enable autologging with MLflow mlflow.sklearn.autolog()Melatih model.
# Train Gradient Boosting Classifier print(f"Training with data of shape {X_train.shape}") mlflow.start_run() clf = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1) clf.fit(X_train, y_train) y_pred = clf.predict(X_test) print(classification_report(y_test, y_pred)) # Stop logging for this model mlflow.end_run()Catatan
Anda dapat mengabaikan peringatan MLflow. Hasil yang Anda butuhkan masih akan dilacak.
Pilih Jalankan Semua di atas kode.
Mengulangi
Sekarang setelah Anda memiliki hasil model, ubah sesuatu dan jalankan model lagi. Misalnya, coba teknik klasifikasi yang berbeda:
# Train AdaBoost Classifier
from sklearn.ensemble import AdaBoostClassifier
print(f"Training with data of shape {X_train.shape}")
mlflow.start_run()
ada = AdaBoostClassifier()
ada.fit(X_train, y_train)
y_pred = ada.predict(X_test)
print(classification_report(y_test, y_pred))
# Stop logging for this model
mlflow.end_run()Catatan
Anda dapat mengabaikan peringatan MLflow. Hasil yang Anda butuhkan masih akan dilacak.
Pilih Jalankan Semua untuk menjalankan model.
Periksa hasilnya
Sekarang setelah Anda mencoba dua model berbeda, gunakan hasil yang dilacak oleh MLFfow untuk memutuskan model mana yang lebih baik. Anda dapat mereferensikan metrik seperti akurasi, atau indikator lain yang paling penting untuk skenario Anda. Anda dapat meninjau hasil ini secara lebih rinci dengan melihat pekerjaan yang dibuat oleh MLflow.
Kembali ke ruang kerja Anda di studio Azure Pembelajaran Mesin.
Di panel kiri, pilih Pekerjaan.
Pilih Kembangkan di tutorial cloud.
Ada dua pekerjaan yang ditampilkan, satu untuk setiap model yang Anda coba. Nama-nama tersebut dibuat secara otomatis. Jika Anda ingin mengganti nama pekerjaan, arahkan mouse ke atas nama dan pilih tombol pensil di sampingnya.
Pilih tautan untuk pekerjaan pertama. Nama muncul di bagian atas halaman. Anda juga dapat mengganti namanya di sini dengan menggunakan tombol pensil.
Halaman menunjukkan detail pekerjaan, seperti properti, output, tag, dan parameter. Di bawah Tag, Anda akan melihat estimator_name, yang menjelaskan jenis model.
Pilih tab Metrik untuk melihat metrik yang dicatat oleh MLflow. (Hasil Anda akan berbeda karena Anda memiliki set pelatihan yang berbeda.)
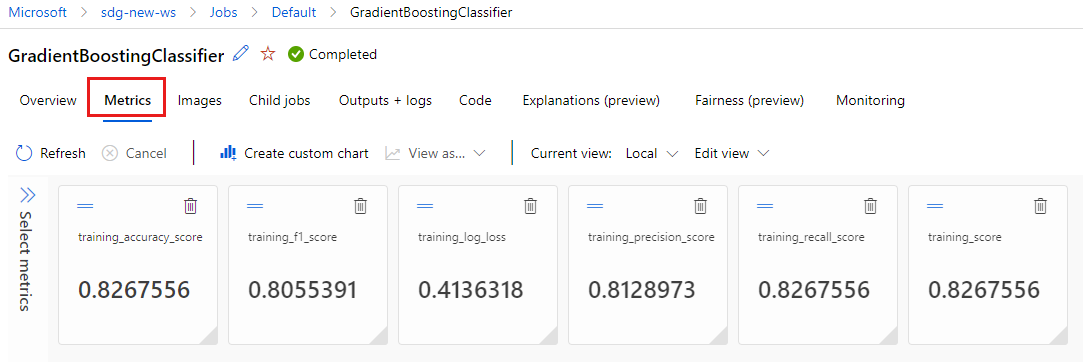
Pilih tab Gambar untuk melihat gambar yang dihasilkan oleh MLflow.
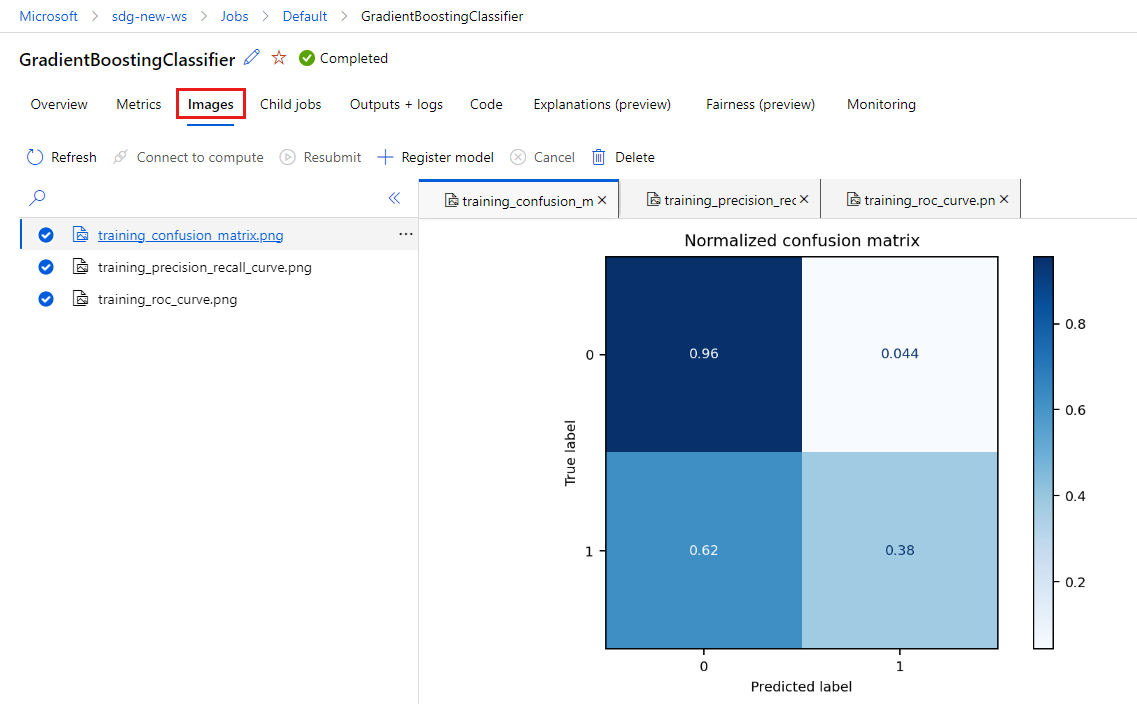
Kembali dan tinjau metrik dan gambar untuk model lain.

Membuat skrip Python
Sekarang Anda akan membuat skrip Python dari buku catatan Anda untuk pelatihan model.
Di Visual Studio Code, klik kanan nama file buku catatan dan pilih Impor Buku Catatan ke Skrip.
Pilih Simpan File > untuk menyimpan file skrip baru. Sebut saja train.py.
Lihat file dan hapus kode yang tidak Anda inginkan dalam skrip pelatihan. Misalnya, simpan kode untuk model yang ingin Anda gunakan, dan hapus kode untuk model yang tidak ingin Anda gunakan.
- Pastikan Anda menyimpan kode yang mulai melakukan autologging (
mlflow.sklearn.autolog()). - Saat Anda menjalankan skrip Python secara interaktif (seperti yang Anda lakukan di sini), Anda dapat menyimpan baris yang menentukan nama eksperimen (
mlflow.set_experiment("Develop on cloud tutorial")). Atau Anda dapat memberinya nama yang berbeda untuk melihatnya sebagai entri yang berbeda di bagian Pekerjaan . Tetapi ketika Anda menyiapkan skrip untuk pekerjaan pelatihan, baris tersebut tidak berlaku dan harus dihilangkan: definisi pekerjaan menyertakan nama eksperimen. - Saat Anda melatih satu model, baris kode untuk memulai dan mengakhiri proses (
mlflow.start_run()danmlflow.end_run()) tidak diperlukan (tidak berpengaruh), tetapi Anda dapat membiarkannya tetap ada.
- Pastikan Anda menyimpan kode yang mulai melakukan autologging (
Setelah selesai dengan pengeditan, simpan file.
Anda sekarang memiliki skrip Python untuk digunakan untuk melatih model pilihan Anda.
Menjalankan skrip Python
Untuk saat ini, Anda menjalankan kode ini pada instans komputasi, yang merupakan lingkungan pengembangan Azure Pembelajaran Mesin Anda. Tutorial: Melatih model menunjukkan cara menjalankan skrip pelatihan dengan cara yang lebih dapat diskalakan pada sumber daya komputasi yang lebih kuat.
Pilih lingkungan yang Anda buat sebelumnya dalam tutorial ini sebagai versi Python Anda (workstations_env). Di sudut kanan bawah notebook, Anda akan melihat nama lingkungan. Pilih itu, lalu pilih lingkungan untuk di bagian atas antarmuka Visual Studio Code.
Jalankan skrip Python dengan memilih tombol Jalankan Semua di atas kode.


Catatan
Anda dapat mengabaikan peringatan MLflow. Anda masih akan mendapatkan semua metrik dan gambar dari autologging.
Memeriksa hasil skrip
Kembali ke Pekerjaan di ruang kerja Anda di studio Azure Pembelajaran Mesin untuk melihat hasil skrip pelatihan Anda. Perlu diingat bahwa data pelatihan berubah dengan setiap pemisahan, sehingga hasilnya berbeda di antara eksekusi.
Membersihkan sumber daya
Jika Anda berencana untuk melanjutkan ke tutorial lain, lewati ke Langkah berikutnya.
Menghentikan instans komputasi
Jika Anda tidak akan menggunakannya sekarang, hentikan instans komputasi:
- Di studio, di panel kiri, pilih Komputasi.
- Di bagian atas halaman, pilih Instans komputasi.
- Dalam daftar, pilih instans komputasi.
- Di bagian atas halaman, pilih Hentikan.
Menghapus semua sumber daya
Penting
Sumber daya yang Anda buat sebagai prasyarat untuk tutorial dan artikel cara penggunaan Azure Machine Learning lainnya.
Jika Anda tidak berencana menggunakan sumber daya yang sudah Anda buat, hapus sehingga Anda tidak dikenakan biaya apa pun:
Di portal Azure, di kotak pencarian, masukkan Grup sumber daya dan pilih dari hasil.
Dari daftar, pilih grup sumber daya yang Anda buat.
Di halaman Gambaran Umum , pilih Hapus grup sumber daya.
Masukkan nama grup sumber daya. Kemudian pilih Hapus.
Langkah berikutnya
Lihat sumber daya berikut untuk mempelajari selengkapnya:
- Artefak dan model dalam MLflow
- Menggunakan Git dengan Azure Pembelajaran Mesin
- Menjalankan notebook Jupyter di ruang kerja Anda
- Bekerja dengan terminal instans komputasi di ruang kerja Anda
- Mengelola sesi buku catatan dan terminal
Tutorial ini menunjukkan langkah-langkah awal membuat model, membuat prototipe pada komputer yang sama tempat kode berada. Untuk pelatihan produksi Anda, pelajari cara menggunakan skrip pelatihan tersebut pada sumber daya komputasi jarak jauh yang lebih kuat: