Mulai Cepat: Memulai Azure Machine Learning
BERLAKU UNTUK: Python SDK azure-ai-ml v2 (saat ini)
Python SDK azure-ai-ml v2 (saat ini)
Tutorial ini adalah pengantar beberapa fitur yang paling banyak digunakan dari layanan Azure Pembelajaran Mesin. Di dalamnya, Anda akan membuat, mendaftarkan, dan menyebarkan model. Tutorial ini akan membantu Anda terbiasa dengan konsep inti Azure Pembelajaran Mesin dan penggunaannya yang paling umum.
Anda akan mempelajari cara menjalankan pekerjaan pelatihan pada sumber daya komputasi yang dapat diskalakan, lalu menyebarkannya, dan akhirnya menguji penyebaran.
Anda akan membuat skrip pelatihan untuk menangani persiapan data, melatih, dan mendaftarkan model. Setelah melatih model, Anda akan menyebarkannya sebagai titik akhir, lalu memanggil titik akhir untuk inferensi.
Langkah-langkah yang akan Anda ambil adalah:
- Menyiapkan handel ke ruang kerja Azure Pembelajaran Mesin Anda
- Membuat skrip pelatihan Anda
- Membuat sumber daya komputasi yang dapat diskalakan, kluster komputasi
- Membuat dan menjalankan pekerjaan perintah yang akan menjalankan skrip pelatihan pada kluster komputasi, dikonfigurasi dengan lingkungan pekerjaan yang sesuai
- Melihat output skrip pelatihan Anda
- Menyebarkan model yang baru dilatih sebagai titik akhir
- Memanggil titik akhir Azure Pembelajaran Mesin untuk inferensi
Tonton video ini untuk gambaran umum langkah-langkah dalam mulai cepat ini.
Prasyarat
-
Untuk menggunakan Azure Pembelajaran Mesin, Anda memerlukan ruang kerja terlebih dahulu. Jika Anda tidak memilikinya, selesaikan Buat sumber daya yang Anda perlukan untuk mulai membuat ruang kerja dan pelajari selengkapnya tentang menggunakannya.
-
Masuk ke studio dan pilih ruang kerja Anda jika belum dibuka.
-
Buka atau buat buku catatan di ruang kerja Anda:
- Buat buku catatan baru, jika Anda ingin menyalin/menempelkan kode ke dalam sel.
- Atau, buka tutorial/get-started-notebooks/quickstart.ipynb dari bagian Sampel studio. Lalu pilih Kloning untuk menambahkan buku catatan ke File Anda. (Lihat tempat menemukan Sampel.)
Atur kernel Anda
Di bilah atas di atas notebook yang Anda buka, buat instans komputasi jika Anda belum memilikinya.

Jika instans komputasi dihentikan, pilih Mulai komputasi dan tunggu hingga instans berjalan.

Pastikan bahwa kernel, yang ditemukan di kanan atas, adalah
Python 3.10 - SDK v2. Jika tidak, gunakan dropdown untuk memilih kernel ini.
Jika Anda melihat banner yang mengatakan Bahwa Anda perlu diautentikasi, pilih Autentikasi.



Penting
Sisa tutorial ini berisi sel-sel buku catatan tutorial. Salin/tempelkan ke buku catatan baru Anda, atau beralihlah ke buku catatan sekarang jika Anda mengkloningnya.
Membuat handel ke ruang kerja
Sebelum kami menyelami kode, Anda memerlukan cara untuk mereferensikan ruang kerja Anda. Ruang kerja adalah sumber daya tingkat teratas untuk Azure Machine Learning, menyediakan tempat terpusat untuk bekerja dengan semua artefak yang Anda buat saat Anda menggunakan Azure Machine Learning.
Anda akan membuat ml_client handel ke ruang kerja. Anda kemudian akan menggunakan ml_client untuk mengelola sumber daya dan pekerjaan.
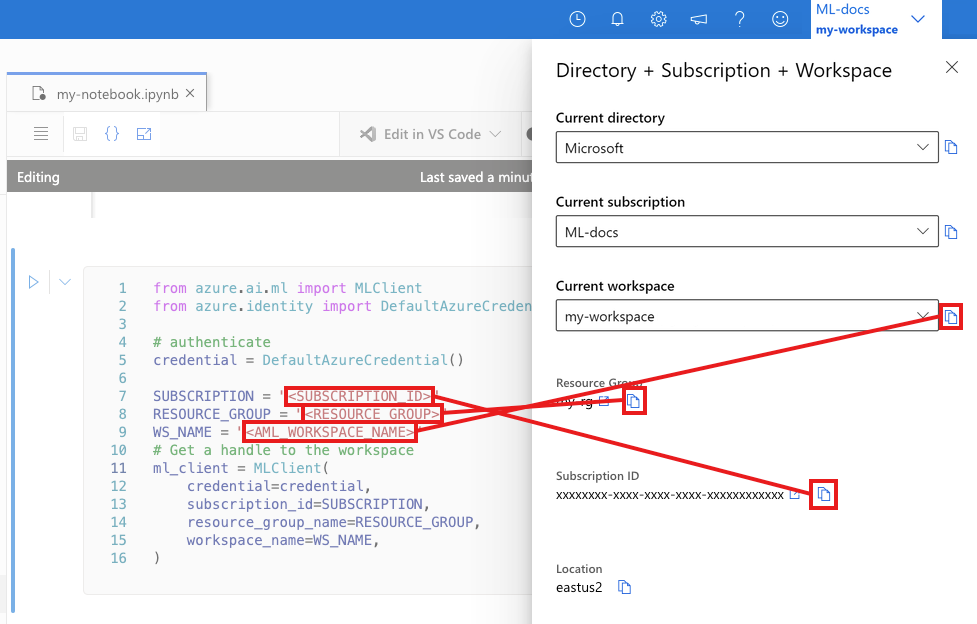
Di sel berikutnya, masukkan ID Langganan, nama Grup Sumber Daya, dan nama Ruang Kerja Anda. Untuk menemukan nilai-nilai ini:
- Di toolbar studio Azure Machine Learning, di kanan atas, pilih nama ruang kerja Anda.
- Salin nilai untuk ruang kerja, grup sumber daya, dan ID langganan ke dalam kode.
- Anda harus menyalin satu nilai, menutup area dan menempelkan, lalu kembali untuk nilai berikutnya.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION="<SUBSCRIPTION_ID>"
RESOURCE_GROUP="<RESOURCE_GROUP>"
WS_NAME="<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Catatan
Membuat MLClient tidak akan menghubungkan ke ruang kerja. Inisialisasi klien malas, ia akan menunggu untuk pertama kalinya perlu melakukan panggilan (ini akan terjadi di sel kode berikutnya).
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location,":", ws.resource_group)
Membuat skrip pelatihan
Mari kita mulai dengan membuat skrip pelatihan - file Python main.py .
Pertama-tama buat folder sumber untuk skrip:
import os
train_src_dir = "./src"
os.makedirs(train_src_dir, exist_ok=True)
Skrip ini menangani pra-pemrosesan data, membaginya menjadi data pengujian dan pelatihan. Kemudian menggunakan data ini untuk melatih model berbasis pohon dan mengembalikan model output.
MLFlow akan digunakan untuk mencatat parameter dan metrik selama proses alur kami.
Sel di bawah ini menggunakan sihir IPython untuk menulis skrip pelatihan ke direktori yang baru saja Anda buat.
%%writefile {train_src_dir}/main.py
import os
import argparse
import pandas as pd
import mlflow
import mlflow.sklearn
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
from sklearn.model_selection import train_test_split
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
###################
#<prepare the data>
###################
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
train_df, test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
####################
#</prepare the data>
####################
##################
#<train the model>
##################
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
###################
#</train the model>
###################
##########################
#<save and register model>
##########################
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.registered_model_name, "trained_model"),
)
###########################
#</save and register model>
###########################
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Seperti yang Anda lihat dalam skrip ini, setelah model dilatih, file model disimpan dan didaftarkan ke ruang kerja. Sekarang Anda dapat menggunakan model terdaftar dalam menyimpulkan titik akhir.
Anda mungkin perlu memilih Refresh untuk melihat folder dan skrip baru di File Anda.
Mengonfigurasi perintah
Sekarang setelah Anda memiliki skrip yang dapat melakukan tugas yang diinginkan, dan kluster komputasi untuk menjalankan skrip, Anda akan menggunakan perintah tujuan umum yang dapat menjalankan tindakan baris perintah. Tindakan baris perintah ini dapat langsung memanggil perintah sistem atau menjalankan skrip.
Di sini, Anda akan membuat variabel input untuk menentukan data input, rasio pemisahan, tingkat pembelajaran, dan nama model terdaftar. Skrip perintah akan:
- Gunakan lingkungan yang menentukan pustaka perangkat lunak dan runtime yang diperlukan untuk skrip pelatihan. Azure Pembelajaran Mesin menyediakan banyak lingkungan yang dikumpulkan atau siap pakai, yang berguna untuk skenario pelatihan dan inferensi umum. Anda akan menggunakan salah satu lingkungan tersebut di sini. Dalam Tutorial: Melatih model di Azure Pembelajaran Mesin, Anda akan mempelajari cara membuat lingkungan kustom.
- Konfigurasikan tindakan baris perintah itu sendiri -
python main.pydalam hal ini. Input/output dapat diakses dalam perintah melalui${{ ... }}notasi. - Dalam sampel ini, kami mengakses data dari file di internet.
- Karena sumber daya komputasi tidak ditentukan, skrip akan dijalankan pada kluster komputasi tanpa server yang dibuat secara otomatis.
from azure.ai.ml import command
from azure.ai.ml import Input
registered_model_name = "credit_defaults_model"
job = command(
inputs=dict(
data=Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csv",
),
test_train_ratio=0.2,
learning_rate=0.25,
registered_model_name=registered_model_name,
),
code="./src/", # location of source code
command="python main.py --data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} --learning_rate ${{inputs.learning_rate}} --registered_model_name ${{inputs.registered_model_name}}",
environment="AzureML-sklearn-1.0-ubuntu20.04-py38-cpu@latest",
display_name="credit_default_prediction",
)
Mengirimkan pekerjaan
Sekarang saatnya untuk mengirimkan pekerjaan untuk dijalankan di Azure Pembelajaran Mesin. Kali ini Anda akan menggunakan create_or_update pada ml_client.
ml_client.create_or_update(job)
Lihat output pekerjaan dan tunggu penyelesaian pekerjaan
Lihat pekerjaan di studio Azure Pembelajaran Mesin dengan memilih tautan dalam output sel sebelumnya.
Output pekerjaan ini akan terlihat seperti ini di studio Azure Pembelajaran Mesin. Jelajahi tab untuk berbagai detail seperti metrik, output, dll. Setelah selesai, pekerjaan akan mendaftarkan model di ruang kerja Anda sebagai hasil dari pelatihan.
Penting
Tunggu hingga status pekerjaan selesai sebelum kembali ke buku catatan ini untuk melanjutkan. Pekerjaan akan memakan waktu 2 hingga 3 menit untuk dijalankan. Bisa memakan waktu lebih lama (hingga 10 menit) jika kluster komputasi telah diturunkan menjadi nol simpul dan lingkungan kustom masih dibangun.
Menyebarkan model sebagai titik akhir online
Sekarang sebarkan model pembelajaran mesin Anda sebagai layanan web di cloud Azure, online endpoint.
Untuk menyebarkan layanan pembelajaran mesin, Anda akan menggunakan model yang Anda daftarkan.
Membuat titik akhir online baru
Sekarang setelah Anda memiliki model terdaftar, saatnya untuk membuat titik akhir online Anda. Nama titik akhir harus unik di seluruh wilayah Azure. Untuk tutorial ini, Anda akan membuat nama unik menggunakan UUID.
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Buat titik akhir:
# Expect the endpoint creation to take a few minutes
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
"model_type": "sklearn.GradientBoostingClassifier",
},
)
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
print(f"Endpoint {endpoint.name} provisioning state: {endpoint.provisioning_state}")
Catatan
Harapkan pembuatan titik akhir memakan waktu beberapa menit.
Setelah titik akhir dibuat, Anda dapat mengambilnya seperti di bawah ini:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Menyebarkan model ke titik akhir
Setelah titik akhir dibuat, sebarkan model dengan skrip entri. Setiap titik akhir dapat memiliki beberapa penyebaran. Lalu lintas langsung ke penyebaran ini dapat ditentukan menggunakan aturan. Di sini Anda akan membuat penyebaran tunggal yang menangani 100% lalu lintas masuk. Kami telah memilih nama warna untuk penyebaran, misalnya, penyebaran biru, hijau, merah, yang bersifat arbitrer.
Anda dapat memeriksa halaman Model di studio Azure Pembelajaran Mesin, untuk mengidentifikasi versi terbaru model terdaftar Anda. Atau, kode di bawah ini akan mengambil nomor versi terbaru untuk Anda gunakan.
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(f'Latest model is version "{latest_model_version}" ')
Sebarkan versi model terbaru.
# picking the model to deploy. Here we use the latest version of our registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# Expect this deployment to take approximately 6 to 8 minutes.
# create an online deployment.
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()
Catatan
Penyebaran ini diperkirakan akan memakan waktu sekitar 6 hingga 8 menit.
Setelah penyebaran selesai, Anda siap untuk mengujinya.
Menguji dengan sampel kueri
Setelah model disebarkan ke titik akhir, Anda dapat menjalankan inferensi dengannya.
Buat file permintaan sampel dengan mengikuti desain yang diharapkan dalam metode run di skrip skor.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
# test the blue deployment with some sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
deployment_name="blue",
)
Membersihkan sumber daya
Jika Anda tidak akan menggunakan titik akhir, hapus untuk berhenti menggunakan sumber daya. Pastikan tidak ada penyebaran lain yang menggunakan titik akhir sebelum Anda menghapusnya.
Catatan
Harapkan penghapusan lengkap memakan waktu sekitar 20 menit.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)
Menghentikan instans komputasi
Jika Anda tidak akan menggunakannya sekarang, hentikan instans komputasi:
- Di studio, di area navigasi kiri, pilih Komputasi.
- Di tab atas, pilih Instans komputasi
- Pilih instans komputasi dalam daftar.
- Di toolbar atas, pilih Hentikan.
Menghapus semua sumber daya
Penting
Sumber daya yang Anda buat sebagai prasyarat untuk tutorial dan artikel cara penggunaan Azure Machine Learning lainnya.
Jika Anda tidak berencana menggunakan sumber daya yang sudah Anda buat, hapus sehingga Anda tidak dikenakan biaya apa pun:
Dari portal Microsoft Azure, pilih Grup sumber daya dari sisi sebelah kiri.
Dari daftar, pilih grup sumber daya yang Anda buat.
Pilih Hapus grup sumber daya.
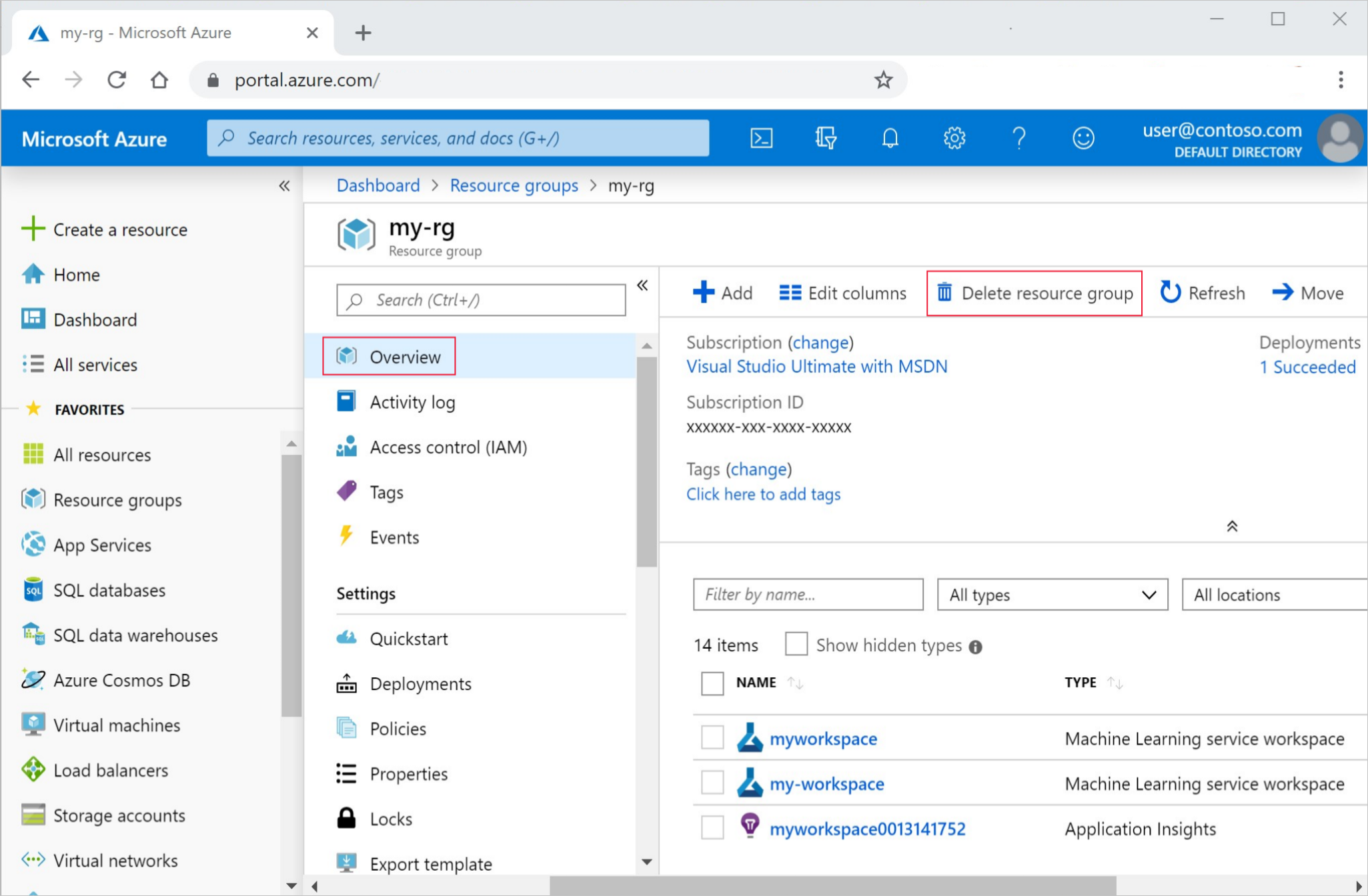
Masukkan nama grup sumber daya. Kemudian pilih Hapus.
Langkah berikutnya
Sekarang setelah Anda memiliki gambaran tentang apa yang terlibat dalam pelatihan dan penyebaran model, pelajari lebih lanjut tentang proses dalam tutorial ini:
| Tutorial | Deskripsi |
|---|---|
| Mengunggah, mengakses, dan menjelajahi data Anda di Azure Pembelajaran Mesin | Menyimpan data besar di cloud dan mengambilnya dari notebook dan skrip |
| Pengembangan model di stasiun kerja cloud | Mulai membuat prototipe dan mengembangkan model pembelajaran mesin |
| Melatih model di Azure Pembelajaran Mesin | Menyelami detail pelatihan model |
| Menyebarkan model sebagai titik akhir online | Menyelami detail penyebaran model |
| Membuat alur pembelajaran mesin produksi | Pisahkan tugas pembelajaran mesin lengkap menjadi alur kerja multistep. |