Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
BERLAKU UNTUK: Python SDK azure-ai-ml v2 (saat ini)
Python SDK azure-ai-ml v2 (saat ini)
Pelajari cara menyebarkan model ke titik akhir online menggunakan Azure Machine Learning Python SDK v2.
Dalam tutorial ini, Anda menyebarkan dan menggunakan model yang memprediksi kemungkinan pelanggan default pada pembayaran kartu kredit.
Langkah-langkah yang Anda ambil adalah:
- Mendaftarkan model Anda
- Membuat titik akhir dan penyebaran pertama
- Menyebarkan eksekusi uji coba
- Mengirim data pengujian secara manual ke penyebaran
- Mendapatkan detail penyebaran
- Membuat penyebaran kedua
- Menskalakan penyebaran kedua secara manual
- Memperbarui alokasi lalu lintas produksi antara kedua penyebaran
- Mendapatkan detail penyebaran kedua
- Meluncurkan penyebaran baru dan menghapus yang pertama
Video ini menunjukkan cara memulai di studio Azure Machine Learning sehingga Anda dapat mengikuti langkah-langkah dalam tutorial. Video memperlihatkan cara membuat buku catatan, membuat instans komputasi, dan mengkloning buku catatan. Langkah-langkahnya juga dijelaskan di bagian berikut.
Prasyarat
-
Untuk menggunakan Azure Pembelajaran Mesin, Anda memerlukan ruang kerja. Jika Anda tidak memilikinya, selesaikan Buat sumber daya yang Anda perlukan untuk mulai membuat ruang kerja dan pelajari selengkapnya tentang menggunakannya.
Penting
Jika ruang kerja Azure Pembelajaran Mesin Anda dikonfigurasi dengan jaringan virtual terkelola, Anda mungkin perlu menambahkan aturan keluar untuk mengizinkan akses ke repositori paket Python publik. Untuk informasi selengkapnya, lihat Skenario: Mengakses paket pembelajaran mesin publik.
-
Masuk ke studio dan pilih ruang kerja Anda jika belum dibuka.
-
Buka atau buat buku catatan di ruang kerja Anda:
- Jika Anda ingin menyalin dan menempelkan kode ke dalam sel, buat buku catatan baru.
- Atau, buka tutorial/get-started-notebooks/deploy-model.ipynb dari bagian Sampel studio. Lalu pilih Kloning untuk menambahkan buku catatan ke File Anda. Untuk menemukan contoh buku catatan, lihat Pelajari dari contoh buku catatan.
Lihat kuota VM Anda dan pastikan Anda memiliki cukup kuota yang tersedia untuk membuat penyebaran online. Dalam tutorial ini, Anda memerlukan setidaknya 8 inti
STANDARD_DS3_v2dan 12 intiSTANDARD_F4s_v2. Untuk melihat penggunaan kuota VM Anda dan meminta penambahan kuota, lihat Mengelola kuota sumber daya.
Atur kernel Anda dan buka di Visual Studio Code (Visual Studio Code)
Di bilah atas di atas notebook yang Anda buka, buat instans komputasi jika Anda belum memilikinya.

Jika instans komputasi dihentikan, pilih Mulai komputasi dan tunggu hingga instans berjalan.

Tunggu hingga instans komputasi berjalan. Kemudian pastikan bahwa kernel, yang ditemukan di kanan atas, adalah
Python 3.10 - SDK v2. Jika tidak, gunakan daftar dropdown untuk memilih kernel ini.
Jika Anda tidak melihat kernel ini, verifikasi bahwa instans komputasi Anda sedang berjalan. Jika ya, pilih tombol Refresh di kanan atas buku catatan.
Jika Anda melihat banner yang mengatakan Bahwa Anda perlu diautentikasi, pilih Autentikasi.
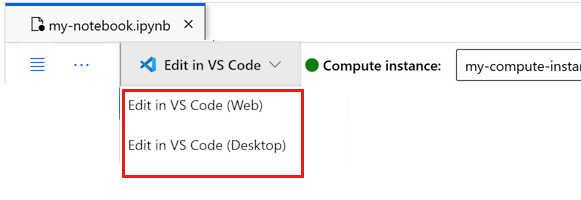
Anda dapat menjalankan buku catatan di sini, atau membukanya di VISUAL Code untuk lingkungan pengembangan terintegrasi penuh (IDE) dengan kekuatan sumber daya Azure Pembelajaran Mesin. Pilih Buka di Visual Studio Code, lalu pilih opsi web atau desktop. Saat diluncurkan dengan cara ini, VISUAL Code dilampirkan ke instans komputasi Anda, kernel, dan sistem file ruang kerja.




Penting
Sisa tutorial ini berisi sel-sel buku catatan tutorial. Salin dan tempelkan ke buku catatan baru Anda, atau beralihlah ke buku catatan sekarang jika Anda mengkloningnya.
Catatan
Spark Compute tanpa server tidak diinstal Python 3.10 - SDK v2 secara default. Kami menyarankan agar Anda membuat instans komputasi dan memilihnya sebelum melanjutkan tutorial.
Membuat handel ke ruang kerja
Sebelum menyelami kode, Anda memerlukan cara untuk mereferensikan ruang kerja Anda. Buat ml_client untuk handel ke ruang kerja dan gunakan ml_client untuk mengelola sumber daya dan pekerjaan.
Di sel berikutnya, masukkan ID Langganan, nama Grup Sumber Daya, dan Nama ruang kerja Anda. Untuk menemukan nilai-nilai ini:
- Di toolbar studio Azure Machine Learning, di kanan atas, pilih nama ruang kerja Anda.
- Salin nilai untuk ruang kerja, grup sumber daya, dan ID langganan ke dalam kode.
- Anda perlu menyalin satu nilai, menutup area, menempelkan, lalu kembali untuk nilai berikutnya.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential, InteractiveBrowserCredential
# authenticate
try:
credential = DefaultAzureCredential()
credential.get_token("https://management.azure.com/.default")
except Exception:
credential = InteractiveBrowserCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Catatan
Membuat MLClient tidak akan tersambung ke ruang kerja. Inisialisasi klien malas dan menunggu pertama kali perlu melakukan panggilan (ini terjadi di sel kode berikutnya).
Mendaftarkan model
Jika Anda sudah menyelesaikan tutorial pelatihan sebelumnya, Latih model, Anda mendaftarkan model MLflow sebagai bagian dari skrip pelatihan dan dapat melompat ke bagian berikutnya.
Jika Anda tidak menyelesaikan tutorial pelatihan, Anda perlu mendaftarkan model. Mendaftarkan model Anda sebelum penyebaran adalah praktik terbaik yang direkomendasikan.
Kode berikut menentukan path (tempat mengunggah file dari) sebaris. Jika Anda mengkloning folder tutorial, jalankan kode berikut apa adanya. Jika tidak, unduh file dan metadata untuk model dari folder credit_defaults_model. Simpan file yang Anda unduh ke folder credit_defaults_model versi lokal di komputer Anda dan perbarui jalur dalam kode berikut ke lokasi file yang diunduh.
SDK secara otomatis mengunggah file dan mendaftarkan model.
Untuk informasi selengkapnya tentang mendaftarkan model Anda sebagai aset, lihat Mendaftarkan model Anda sebagai aset di Pembelajaran Mesin dengan menggunakan SDK.
# Import the necessary libraries
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
# Provide the model details, including the
# path to the model files, if you've stored them locally.
mlflow_model = Model(
path="./deploy/credit_defaults_model/",
type=AssetTypes.MLFLOW_MODEL,
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
Konfirmasikan bahwa model terdaftar
Anda dapat memeriksa halaman Model di studio Azure Pembelajaran Mesin untuk mengidentifikasi versi terbaru model terdaftar.
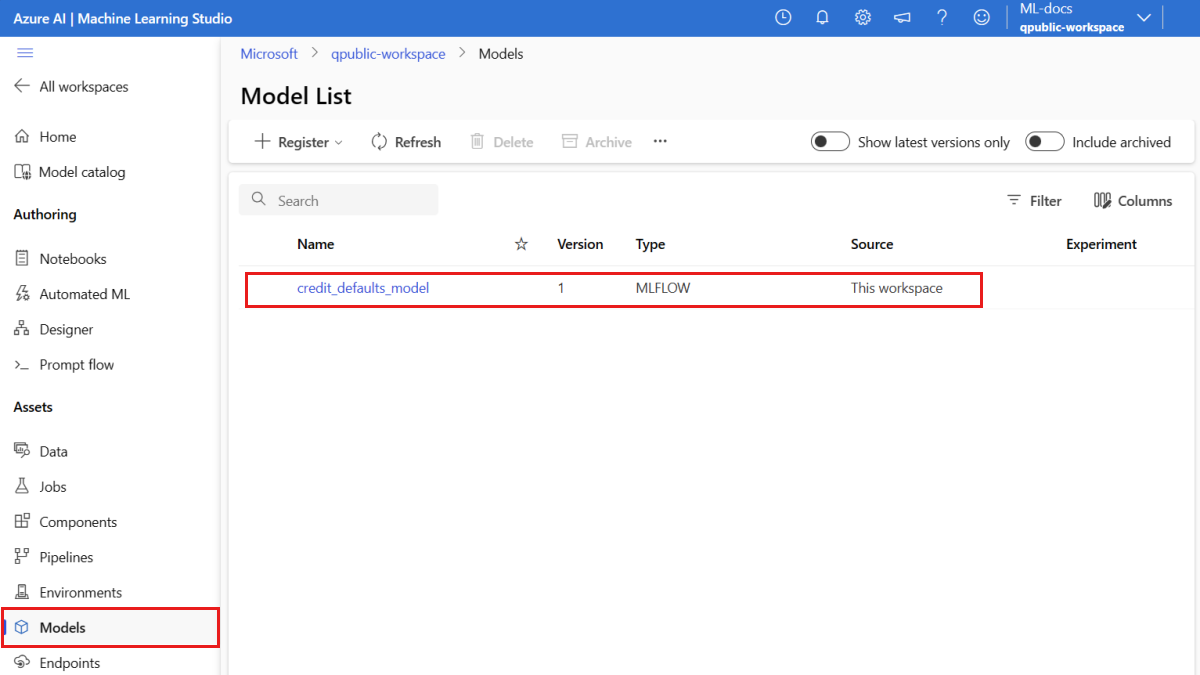
Atau, kode berikut mengambil nomor versi terbaru untuk Anda gunakan.
registered_model_name = "credit_defaults_model"
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version)
Sekarang setelah Anda memiliki model terdaftar, Anda dapat membuat titik akhir dan penyebaran. Bagian berikutnya secara singkat membahas beberapa detail utama tentang topik-topik ini.
Titik akhir dan penyebaran
Setelah melatih model pembelajaran mesin, Anda perlu menyebarkannya sehingga orang lain dapat menggunakannya untuk inferensi. Untuk tujuan ini, Azure Pembelajaran Mesin memungkinkan Anda membuat titik akhir dan menambahkan penyebaran ke titik akhir tersebut.
Titik akhir, dalam konteks ini, adalah jalur HTTPS yang menyediakan antarmuka bagi klien untuk mengirim permintaan (data input) ke model terlatih dan menerima hasil inferensi (penilaian) dari model. Titik akhir menyediakan:
- Autentikasi menggunakan autentikasi berbasis "kunci atau token"
- Penghentian TLS(SSL)
- URI penilaian stabil (endpoint-name.region.inference.ml.azure.com)
Penyebaran adalah kumpulan sumber daya yang diperlukan untuk menghosting model yang melakukan inferensi aktual.
Satu titik akhir dapat berisi beberapa penyebaran. Titik akhir dan penyebaran adalah sumber daya Azure Resource Manager independen yang muncul di portal Microsoft Azure.
Azure Machine Learning memungkinkan Anda menerapkan titik akhir online untuk inferensi real time pada data klien dan titik akhir batch untuk inferensi pada volume data yang besar selama periode waktu tertentu.
Dalam tutorial ini, Anda melalui langkah-langkah penerapan titik akhir online terkelola. Titik akhir online terkelola bekerja dengan mesin CPU dan GPU yang kuat di Azure dengan cara yang dapat diskalakan dan dikelola sepenuhnya yang membebaskan Anda dari overhead pengaturan dan pengelolaan infrastruktur penyebaran yang mendasar.
Membuat titik akhir online
Sekarang setelah Anda memiliki model terdaftar, saatnya untuk membuat titik akhir online Anda. Nama titik akhir harus unik di seluruh wilayah Azure. Untuk tutorial ini, Anda membuat nama unik menggunakan pengidentifikasi UUIDunik universal . Untuk informasi selengkapnya tentang aturan penamaan titik akhir, lihat batas titik akhir.
import uuid
# Create a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Pertama, tentukan titik akhir menggunakan ManagedOnlineEndpoint kelas .
Petunjuk / Saran
auth_mode: Gunakankeyuntuk autentikasi berbasis kunci. Gunakanaml_tokenuntuk autentikasi berbasis token Azure Machine Learning.keytidak kedaluwarsa, tetapiaml_tokenkedaluwarsa. Untuk informasi selengkapnya tentang mengautentikasi, lihat Mengautentikasi klien untuk titik akhir online.Secara opsional, Anda dapat menambahkan deskripsi dan tag ke titik akhir Anda.
from azure.ai.ml.entities import ManagedOnlineEndpoint
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
},
)
Menggunakan yang MLClient dibuat sebelumnya, buat titik akhir di ruang kerja. Perintah ini memulai pembuatan titik akhir dan mengembalikan respons konfirmasi saat pembuatan titik akhir berlanjut.
Catatan
Harapkan pembuatan titik akhir memakan waktu sekitar 2 menit.
# create the online endpoint
# expect the endpoint to take approximately 2 minutes.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Setelah membuat titik akhir, Anda dapat mengambilnya sebagai berikut:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Memahami penyebaran online
Aspek utama penyebaran meliputi:
-
name- Nama penyebaran. -
endpoint_name- Nama titik akhir yang akan berisi penyebaran. -
model- Model yang digunakan untuk penyebaran. Nilai ini dapat berupa referensi ke model berversi yang ada di ruang kerja atau spesifikasi model sebaris. -
environment- Lingkungan yang digunakan untuk penyebaran (atau untuk menjalankan model). Nilai ini dapat berupa referensi ke lingkungan berversi yang ada di ruang kerja atau spesifikasi lingkungan sebaris. Lingkungan dapat menjadi gambar Docker dengan dependensi Conda atau Dockerfile. -
code_configuration- Konfigurasi untuk kode sumber dan skrip penilaian.-
path- Jalur ke direktori kode sumber untuk menilai model. -
scoring_script- Jalur relatif ke file penilaian di direktori kode sumber. Skrip ini menjalankan model pada permintaan input tertentu. Untuk contoh skrip penilaian, lihat Memahami skrip penilaian di artikel "Menyebarkan model ML dengan titik akhir online".
-
-
instance_type- Ukuran VM untuk digunakan untuk penyebaran. Untuk daftar ukuran yang didukung, lihat Daftar SKU titik akhir online terkelola. -
instance_count- Jumlah instans yang akan digunakan untuk penyebaran.
Penyebaran menggunakan model MLflow
Azure Pembelajaran Mesin mendukung penyebaran tanpa kode model yang dibuat dan dicatat dengan MLflow. Ini berarti Anda tidak perlu menyediakan skrip penilaian atau lingkungan selama penyebaran model, karena skrip penilaian dan lingkungan dibuat secara otomatis saat melatih model MLflow. Namun, jika Anda menggunakan model kustom, Anda harus menentukan lingkungan dan skrip penilaian selama penyebaran.
Penting
Jika Anda biasanya menyebarkan model menggunakan skrip penilaian dan lingkungan kustom dan ingin mencapai fungsionalitas yang sama menggunakan model MLflow, sebaiknya baca Panduan untuk menyebarkan model MLflow.
Menyebarkan model ke titik akhir
Mulailah dengan membuat satu penyebaran yang menangani 100% lalu lintas masuk. Pilih nama warna arbitrer (biru) untuk penyebaran. Untuk membuat penyebaran untuk titik akhir, gunakan ManagedOnlineDeployment kelas .
Catatan
Anda tidak perlu menentukan lingkungan atau skrip penilaian karena model yang akan disebarkan adalah model MLflow.
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of the registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
Menggunakan objek yang MLClient dibuat sebelumnya, lakukan penerapan di ruang kerja. Perintah ini memulai pembuatan penyebaran dan mengembalikan respons konfirmasi saat pembuatan penyebaran berlanjut.
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Memeriksa status titik akhir
Anda dapat memeriksa status titik akhir untuk melihat apakah model disebarkan tanpa kesalahan:
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
Menguji titik akhir dengan data sampel
Sekarang setelah model disebarkan ke titik akhir, Anda dapat menjalankan inferensi dengannya. Mulailah dengan membuat file permintaan sampel yang mengikuti desain yang diharapkan dalam metode eksekusi yang ditemukan dalam skrip penilaian.
import os
# Create a directory to store the sample request file.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
Sekarang buat file di direktori deployment. Sel kode berikut menggunakan magic IPython untuk menulis file ke direktori yang Anda buat.
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
Menggunakan yang MLClient dibuat sebelumnya, dapatkan handel ke titik akhir. Anda dapat memanggil titik akhir dengan menggunakan invoke perintah dengan parameter berikut:
-
endpoint_name- Nama titik akhir -
request_file- File dengan data permintaan -
deployment_name- Nama penyebaran tertentu untuk diuji di titik akhir
Uji penyebaran biru dengan data sampel.
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
Mendapatkan log penyebaran
Periksa log untuk melihat apakah titik akhir/penyebaran berhasil dipanggil. Jika Anda menghadapi kesalahan, lihat Pemecahan masalah penyebaran titik akhir online.
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Membuat penyebaran kedua
Sebarkan model sebagai penyebaran kedua yang disebut green. Dalam praktiknya, Anda dapat membuat beberapa penyebaran dan membandingkan performanya. Penyebaran ini dapat menggunakan versi yang berbeda dari model yang sama, model yang berbeda, atau instans komputasi yang lebih kuat.
Dalam contoh ini, Anda menyebarkan versi model yang sama, menggunakan instans komputasi yang lebih kuat yang berpotensi meningkatkan performa.
# pick the model to deploy. Here you use the latest version of the registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment using a more powerful instance type
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
# create the online deployment
# expect the deployment to take approximately 8 to 10 minutes
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
).result()
Menskalakan penyebaran untuk menangani lebih banyak lalu lintas
Dengan menggunakan yang MLClient dibuat sebelumnya, Anda bisa mendapatkan handel ke green penyebaran. Anda kemudian dapat menskalakannya dengan meningkatkan atau mengurangi instance_count.
Dalam kode berikut, Anda meningkatkan instans VM secara manual. Namun, dimungkinkan juga untuk menskalakan titik akhir online secara otomatis. Skala otomatis secara otomatis menjalankan jumlah sumber daya yang tepat untuk menangani beban pada aplikasi Anda. Titik akhir online terkelola mendukung penskalaan otomatis melalui integrasi dengan fitur skala otomatis pemantauan Azure. Untuk mengonfigurasi autoscaling, lihat Titik akhir online skala otomatis.
# update definition of the deployment
green_deployment.instance_count = 2
# update the deployment
# expect the deployment to take approximately 8 to 10 minutes
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
Memperbarui alokasi lalu lintas untuk penyebaran
Anda dapat membagi lalu lintas produksi antar penyebaran. Anda mungkin terlebih dahulu ingin menguji green penyebaran dengan data sampel, seperti yang Anda lakukan untuk blue penyebaran. Setelah Anda menguji penyebaran hijau Anda, alokasikan persentase kecil lalu lintas ke dalamnya.
endpoint.traffic = {"blue": 80, "green": 20}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Uji alokasi lalu lintas dengan memanggil titik akhir beberapa kali:
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
Perlihatkan log dari green penyebaran untuk memeriksa apakah ada permintaan masuk dan model berhasil dinilai.
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Menampilkan metrik menggunakan Azure Monitor
Anda dapat melihat berbagai metrik (nomor permintaan, latensi permintaan, byte jaringan, pemanfaatan CPU/GPU/Disk/Memori, dan lainnya) untuk titik akhir online dan penyebarannya dengan mengikuti tautan dari halaman Detail titik akhir di studio. Mengikuti salah satu tautan ini akan membawa Anda ke halaman metrik yang tepat di portal Azure untuk titik akhir atau penyebaran.

Jika Anda membuka metrik untuk titik akhir online, Anda dapat menyiapkan halaman untuk melihat metrik seperti latensi permintaan rata-rata seperti yang ditunjukkan pada gambar berikut.

Untuk informasi selengkapnya tentang cara menampilkan metrik titik akhir online, lihat Memantau titik akhir online.
Mengirim semua lalu lintas ke penyebaran baru
Setelah Anda sepenuhnya puas dengan penyebaran Anda green , alihkan semua lalu lintas ke penyebaran tersebut.
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
Menghapus penyebaran lama
Hapus penyebaran lama (biru):
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
Membersihkan sumber daya
Jika Anda tidak akan menggunakan titik akhir dan penyebaran setelah menyelesaikan tutorial ini, Anda harus menghapusnya.
Catatan
Harapkan penghapusan lengkap memakan waktu sekitar 20 menit.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
Menghapus semuanya
Gunakan langkah-langkah ini untuk menghapus ruang kerja dan semua sumber daya komputasi Azure Machine Learning Anda.
Penting
Sumber daya yang Anda buat sebagai prasyarat untuk tutorial dan artikel cara penggunaan Azure Machine Learning lainnya.
Jika Anda tidak berencana menggunakan sumber daya yang sudah Anda buat, hapus sehingga Anda tidak dikenakan biaya apa pun:
Di portal Azure, di kotak pencarian, masukkan Grup sumber daya dan pilih dari hasil.
Dari daftar, pilih grup sumber daya yang Anda buat.
Di halaman Gambaran Umum , pilih Hapus grup sumber daya.
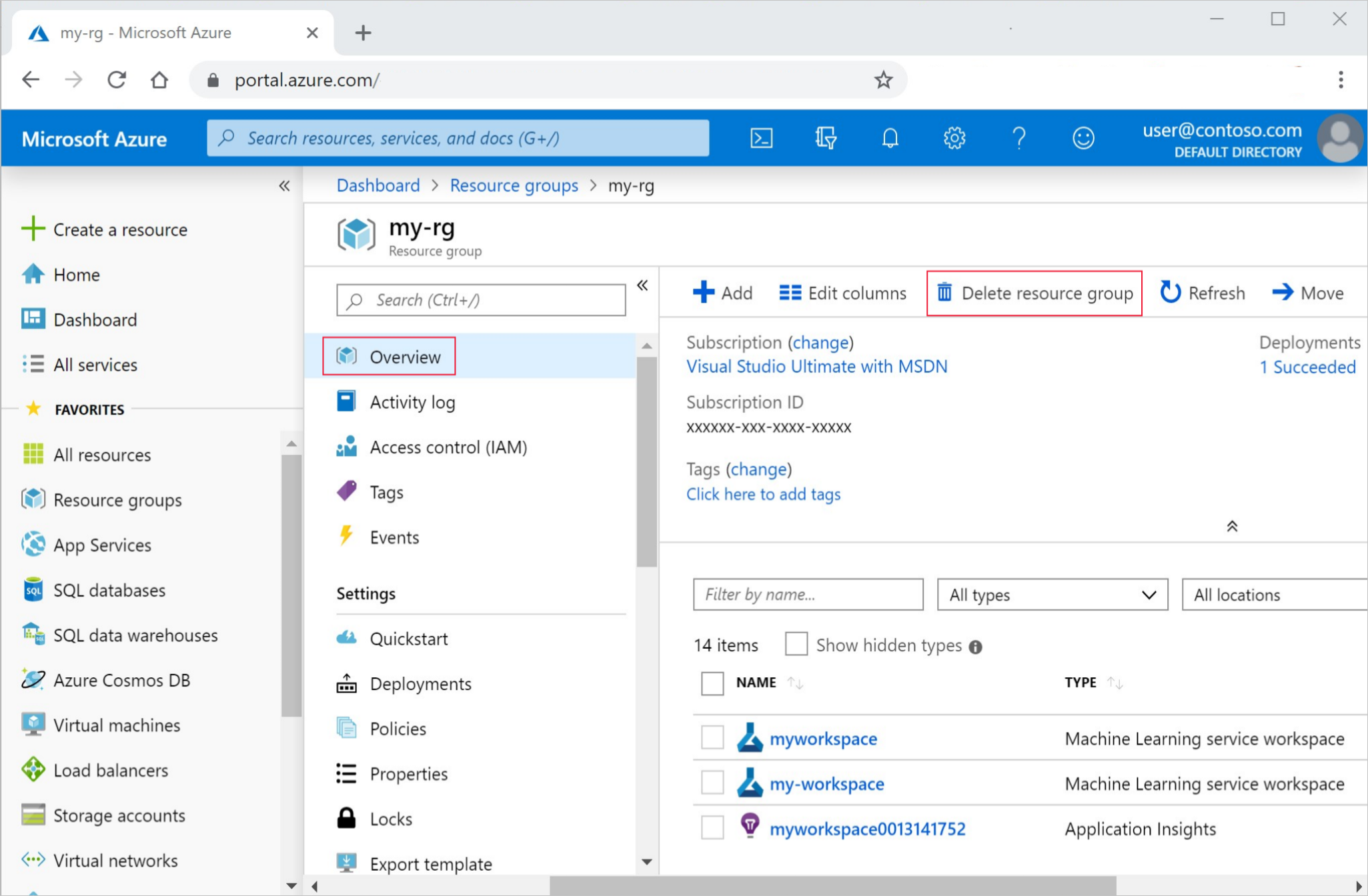
Masukkan nama grup sumber daya. Kemudian pilih Hapus.