Volume NFS v4.1 di Azure NetApp Files untuk SAP Hana
Azure NetApp Files menyediakan bagian NFS asli yang dapat digunakan untuk volume /hana/shared, /hana/data, dan /hana/log. Menggunakan bagian NFS berbasis ANF untuk volume /hana/data dan /hana/log memerlukan penggunaan protokol NFS v4.1. Protokol NFS v3 tidak didukung untuk penggunaan volume /hana/data dan /hana/log saat mendasarkan berbagi pada ANF.
Penting
Protokol NFS v3 yang diterapkan pada Azure NetApp Files tidak didukung untuk digunakan untuk /hana/data dan /hana/log. Penggunaan NFS 4.1 bersifat wajib untuk volume /hana/data dan /hana/log dari sudut pandang fungsional. Sedangkan untuk volume /hana/shared protokol NFS v3 atau NFS v4.1 dapat digunakan dari sudut pandang fungsional.
Pertimbangan penting
Saat mempertimbangkan Azure NetApp Files untuk SAP Netweaver dan SAP HANA, ketahuilah pertimbangan penting berikut:
Pool kapasitas minimumnya adalah 4 TiB
Ukuran volume minimum adalah 100 GiB
Berbagi NFS berbasis ANF dan komputer virtual yang memasang berbagi tersebut harus berada di Azure Virtual Network yang sama atau di jaringan virtual yang di-peering di wilayah yang sama
Jaringan virtual yang dipilih harus memiliki subnet, yang didelegasikan ke Azure NetApp Files. Untuk beban kerja SAP, sangat disarankan untuk mengonfigurasi rentang /25 untuk subnet yang didelegasikan ke ANF.
Penting untuk memiliki komputer virtual yang menyebarkan kedekatan yang memadai dengan penyimpanan Azure NetApp untuk latensi yang lebih rendah seperti, misalnya, yang diminta oleh SAP Hana untuk mengulang penulisan log.
- Azure NetApp Files sementara itu memiliki fungsionalitas untuk menyebarkan volume NFS ke Zona Ketersediaan Azure tertentu. Kedekatan zona seperti itu akan cukup dalam sebagian besar kasus untuk mencapai latensi kurang dari 1 milidetik. Fungsionalitas berada dalam pratinjau publik dan dijelaskan dalam artikel Mengelola penempatan volume zona ketersediaan untuk Azure NetApp Files. Fungsionalitas ini tidak memerlukan proses interaktif dengan Microsoft untuk mencapai kedekatan antara VM Anda dan volume NFS yang Anda alokasikan.
- Untuk mencapai kedekatan yang paling optimal, fungsionalitas Grup Volume Aplikasi tersedia. Fungsionalitas ini tidak hanya mencari kedekatan yang paling optimal, tetapi untuk penempatan volume NFS yang paling optimal, sehingga data HANA dan volume log pengulangan ditangani oleh pengontrol yang berbeda. Kerugiannya adalah metode ini membutuhkan beberapa proses interaktif dengan Microsoft untuk menyematkan VM Anda.
Pastikan latensi dari server database ke volume ANF diukur dan di bawah 1 milidetik
Throughput volume Azure NetApp adalah fungsi dari kuota volume dan tingkat layanan, seperti yang didokumentasikan dalam Tingkat Layanan untuk Azure NetApp Files. Saat mengukur volume HANA Azure NetApp, pastikan throughput yang dihasilkan memenuhi persyaratan sistem HANA. Atau pertimbangkan untuk menggunakan kumpulan kapasitas QoS manual di mana kapasitas volume dan throughput dapat dikonfigurasi dan diskalakan secara independen (contoh spesifik SAP HANA ada dalam dokumen ini
Cobalah untuk "mengkonsolidasikan" volume untuk mencapai kinerja yang lebih besar dalam Volume yang lebih besar misalnya, gunakan satu volume untuk /sapmnt, /usr/sap/trans, ... jika memungkinkan
Azure NetApp Files menawarkan kebijakan ekspor: Anda dapat mengontrol klien yang diizinkan, jenis akses (Baca&Tulis, Baca Saja, dan sebagainya).
ID Pengguna untuk sidadm dan ID Grup untuk
sapsyspada mesin virtual harus sama dengan konfigurasi di Azure NetApp Files.Menerapkan parameter OS Linux yang disebutkan dalam catatan SAP 3024346
Penting
Untuk beban kerja SAP Hana, latensi rendah sangat penting. Bekerjalah dengan perwakilan Microsoft Anda untuk memastikan bahwa komputer virtual dan volume Azure NetApp Files diterapkan dalam jarak dekat.
Penting
Jika ada ketidakcocokan antara ID Pengguna untuk sidadm dan ID Grup untuk sapsys antara mesin virtual dan konfigurasi Azure NetApp, izin untuk file pada volume Azure NetApp, yang dipasang ke Mesin Virtual, akan ditampilkan sebagai nobody. Pastikan untuk menentukan ID Pengguna yang benar untuk sidadm dan ID Grup untuk sapsys, ketika on-boarding sistem baru ke Azure NetApp Files.
Opsi pemasangan NCONNECT
Nconnect adalah opsi pemasangan untuk volume NFS yang dihosting di ANF yang memungkinkan klien NFS untuk membuka beberapa sesi terhadap satu volume NFS. Menggunakan nconnect dengan nilai yang lebih besar dari 1 juga memicu klien NFS untuk menggunakan lebih dari satu sesi RPC di sisi klien (di OS tamu) untuk menangani lalu lintas antara OS tamu dan volume NFS yang dipasang. Penggunaan beberapa sesi yang menangani lalu lintas satu volume NFS, tetapi juga penggunaan beberapa sesi RPC dapat mengatasi skenario performa dan throughput seperti:
- Pemasangan beberapa volume NFS yang dihosting ANF dengan tingkat layanan yang berbeda dalam satu VM
- Throughput maksimum untuk volume dan satu sesi Linux adalah antara 1,2 dan 1,4 GB/dtk. Memiliki beberapa sesi terhadap satu volume NFS yang dihosting ANF dapat meningkatkan throughput
Untuk rilis OS Linux yang mendukung nconnect sebagai opsi pemasangan dan beberapa pertimbangan konfigurasi penting nconnect, terutama dengan titik akhir server NFS yang berbeda, baca dokumen Praktik terbaik opsi pemasangan Linux NFS untuk Azure NetApp Files.
Ukuran untuk database HANA di Azure NetApp Files
Throughput volume Azure NetApp adalah fungsi dari ukuran volume dan tingkat layanan, seperti yang didokumentasikan dalam Tingkat layanan untuk Azure NetApp Files.
Penting untuk dipahami adalah ukuran hubungan performa dan bahwa ada batasan fisik untuk titik akhir penyimpanan layanan. Setiap titik akhir penyimpanan akan disuntikkan secara dinamis ke subnet yang didelegasikan Azure NetApp Files saat pembuatan volume dan menerima alamat IP. Volume Azure NetApp Files dapat – tergantung pada kapasitas dan logika penyebaran yang tersedia – berbagi titik akhir penyimpanan
Tabel di bawah menunjukkan bahwa masuk akal untuk membuat volume “Standar” yang besar guna menyimpan cadangan dan tidak masuk akal untuk membuat volume “Ultra” yang lebih besar dari 12 TB karena kapasitas bandwidth fisik maksimal dari satu volume akan dilampaui.
Jika Anda memerlukan lebih dari throughput tulis maksimum untuk volume /hana/data Anda daripada satu sesi Linux yang dapat disediakan, Anda juga dapat menggunakan partisi volume data SAP Hana sebagai alternatif. Pemartisian volume data SAP Hana melucuti aktivitas I/O selama reload data atau titik penyimpanan HANA di beberapa file data HANA yang terletak di beberapa berbagi NFS. Untuk detail lebih lanjut tentang striping volume data HANA baca artikel ini:
- Panduan Administrator HANA
- Blog tentang SAP HANA - Mempartisi Volume Data
- Catatan SAP #2400005
- Catatan SAP #2700123
| Ukuran | Throughput Standar | Throughput Premium | Throughput Ultra |
|---|---|---|---|
| 1 TB | 16 MB/dtk | 64 MB/dtk | 128 MB/dtk |
| 2 TB | 32 MB/dtk | 128 MB/dtk | 256 MB/dtk |
| 4 TB | 64 MB/dtk | 256 MB/dtk | 512 MB/dtk |
| 10 TB | 160 MB/dtk | 640 MB/dtk | 1.280 MB/dtk |
| 15 TB | 240 MB/dtk | 960 MB/dtk | 1,400 MB/dtk1 |
| 20 TB | 320 MB/dtk | 1.280 MB/dtk | 1,400 MB/dtk1 |
| 40 TB | 640 MB/dtk | 1,400 MB/dtk1 | 1,400 MB/dtk1 |
1: batas throughput tulis atau baca sesi tunggal (jika opsi pemasangan NFS nconnect tidak digunakan)
Penting untuk dipahami bahwa data ditulis ke SSD yang sama di backend penyimpanan. Kuota kinerja dari pool kapasitas dibuat untuk dapat mengelola lingkungan. KPI Penyimpanan sama untuk semua ukuran database HANA. Dalam hampir semua kasus, asumsi ini tidak mencerminkan kenyataan dan harapan pelanggan. Ukuran Sistem HANA tidak selalu berarti bahwa sistem yang kecil memerlukan throughput penyimpanan yang rendah – dan sistem yang besar memerlukan throughput penyimpanan yang tinggi. Tetapi umumnya kita dapat mengharapkan persyaratan throughput yang lebih tinggi untuk instans database HANA yang lebih besar. Sebagai hasil dari aturan pengukuran SAP untuk perangkat keras pokok, instans HANA yang lebih besar tersebut juga menyediakan lebih banyak sumber CPU dan paralelisme yang lebih tinggi dalam tugas-tugas seperti memuat data setelah instans dimulai ulang. Akibatnya ukuran volume harus diadopsi sesuai dengan harapan dan persyaratan pelanggan. Dan tidak hanya didorong oleh persyaratan kapasitas murni.
Saat Anda merancang infrastruktur untuk SAP di Azure, Anda harus mengetahui beberapa persyaratan throughput penyimpanan minimum (untuk Sistem produksi) oleh SAP. Persyaratan ini diterjemahkan ke dalam karakteristik throughput minimum dari:
| Tipe volume dan tipe I/O | Minimum KPI yang diminta oleh SAP | Tingkat layanan premium | Tingkat layanan ultra |
|---|---|---|---|
| Log Volume Write | 250 MB/detik | 4 TB | 2 TB |
| Data Volume Write | 250 MB/detik | 4 TB | 2 TB |
| Data Volume Read | 400 MB/detik | 6,3 TB | 3,2 TB |
Karena ketiga KPI diminta, volume /hana/data perlu diukur sesuai dengan kapasitas yang lebih besar untuk memenuhi persyaratan baca minimum. jika Anda menggunakan kumpulan kapasitas QoS manual, ukuran dan throughput volume dapat ditentukan secara independen. Karena kapasitas dan throughput diambil dari kumpulan kapasitas yang sama, tingkat layanan dan ukuran kumpulan harus cukup besar untuk memberikan kinerja total (lihat contoh di sini)
Untuk sistem HANA, yang tidak memerlukan bandwidth tinggi, throughput volume ANF dapat diturunkan dengan ukuran volume yang lebih kecil atau, menggunakan QoS manual, dengan menyesuaikan throughput secara langsung. Dan jika sistem HANA membutuhkan lebih banyak throughput, volume dapat diadaptasi dengan mengubah ukuran kapasitas secara online. Tidak ada KPI yang didefinisikan untuk volume cadangan. Namun throughput volume cadangan sangat penting untuk lingkungan yang berkinerja baik. Log – dan Kinerja volume data harus dirancang sesuai dengan harapan pelanggan.
Penting
Terlepas dari kapasitas yang Anda sebarkan pada satu volume NFS, throughput, diharapkan untuk tetap mencapai kisaran bandwidth 1,2-1,4 GB/detik yang dimanfaatkan oleh konsumen dalam sesi tunggal. Ini ada hubungannya dengan arsitektur yang mendasari penawaran ANF dan batas sesi Linux terkait di sekitar NFS. Performa dan jumlah throughput seperti yang didokumentasikan dalam artikel Hasil uji tolok ukur performa untuk Azure NetApp Files dilakukan terhadap satu volume NFS bersama dengan beberapa VM klien dan sebagai hasilnya dengan beberapa sesi. Skenario itu berbeda dengan skenario yang kami ukur di SAP. Di mana kami mengukur throughput dari satu VM terhadap volume NFS. Dihosting di ANF.
Untuk memenuhi persyaratan throughput minimum SAP untuk data dan log, dan menurut pedoman untuk /hana/shared, ukuran yang disarankan adalah:
| Volume | Ukuran Tier penyimpanan Premium |
Ukuran Tingkat penyimpanan Ultra |
Protokol NFS yang didukung |
|---|---|---|---|
| /hana/log/ | 4 TiB | 2 TiB | v4.1 |
| /hana/data | 6.3 TiB | 3.2 TiB | v4.1 |
| /hana/shared skala ditingkatkan | Min(1 TB, 1 x RAM) | Min(1 TB, 1 x RAM) | v3 or v4.1 |
| /hana/shared skala disebarkan | 1 x simpul pekerja RAM per empat simpul pekerja |
1 x simpul pekerja RAM per empat simpul pekerja |
v3 or v4.1 |
| /hana/logbackups | 3 x RAM | 3 x RAM | v3 or v4.1 |
| /hana/backup | 2 x RAM | 2 x RAM | v3 or v4.1 |
Untuk semua volume, sebaiknya gunakan NFS v4.1.
Tinjau dengan cermat pertimbangan untuk ukuran /hana/shared, karena volume /hana/shared berukuran tepat berkontribusi pada stabilitas sistem.
Ukuran untuk volume cadangan adalah estimasi. Persyaratan pasti perlu ditentukan berdasarkan beban kerja dan proses operasi. Untuk cadangan, Anda dapat mengkonsolidasikan banyak volume untuk bermacam-macam instans SAP HANA dengan satu (atau dua) volume yang lebih besar, yang dapat memiliki tingkat layanan ANF yang lebih rendah.
Catatan
Azure NetApp Files, yang mengukur rekomendasi yang dinyatakan dalam dokumen ini menargetkan persyaratan minimum yang diungkapkan SAP bagi penyedia infrastruktur mereka. Dalam penggunaan pelanggan nyata dan skenario beban kerja, hal tersebut mungkin tidak cukup. Gunakan rekomendasi ini sebagai titik awal dan sesuaikan, berdasarkan persyaratan beban kerja spesifik Anda.
Oleh karena itu Anda dapat mempertimbangkan untuk menggunakan throughput serupa untuk volume ANF seperti yang tercantum untuk penyimpanan disk Ultra. Pertimbangkan juga ukuran untuk ukuran yang tercantum untuk volume untuk SKU VM yang berbeda seperti yang dilakukan dalam tabel disk Ultra.
Tip
Anda dapat mengubah ukuran volume Azure NetApp Files secara dinamis, tanpa harus unmount volume, menghentikan komputer virtual atau menghentikan SAP HANA. Pendekatan ini memungkinkan fleksibilitas untuk memenuhi permintaan throughput yang diharapkan dan tidak terduga dari aplikasi Anda.
Dokumentasi tentang cara menyebarkan konfigurasi peluasan skala SAP Hana dengan simpul siaga menggunakan volume NFS v4.1 berbasis ANF diterbitkan dalam peluasan skala SAP Hana dengan simpul siaga di Azure VM dengan Azure NetApp Files di SUSE Linux Enterprise Server.
Pengaturan Kernel Linux
Agar berhasil menyebarkan SAP Hana di ANF, pengaturan kernel Linux perlu diimplementasikan sesuai dengan catatan SAP 3024346.
Untuk sistem yang menggunakan Ketersediaan Tinggi (HA) menggunakan pacemaker dan Pengaturan berikut Azure Load Balancer perlu diimplementasikan dalam file /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 0
net.ipv4.tcp_sack = 1
Sistem yang berjalan tanpa pacemaker dan Azure Load Balancer harus menerapkan pengaturan ini di /etc/sysctl.d/91-NetApp-HANA.conf
net.core.rmem_max = 16777216
net.core.wmem_max = 16777216
net.ipv4.tcp_rmem = 4096 131072 16777216
net.ipv4.tcp_wmem = 4096 16384 16777216
net.core.netdev_max_backlog = 300000
net.ipv4.tcp_slow_start_after_idle=0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_sack = 1
Penyebaran dengan kedekatan zona
Untuk mendapatkan kedekatan zona volume NFS dan VM, Anda dapat mengikuti instruksi seperti yang dijelaskan dalam Mengelola penempatan volume zona ketersediaan untuk Azure NetApp Files. Dengan metode ini, VM dan volume NFS akan berada di Zona Ketersediaan Azure yang sama. Di sebagian besar wilayah Azure, jenis kedekatan ini harus cukup untuk mencapai latensi kurang dari 1 milidetik untuk penulisan log pengulangan yang lebih kecil untuk SAP Hana. Metode ini tidak memerlukan pekerjaan interaktif dengan Microsoft untuk menempatkan dan menyematkan VM ke pusat data tertentu. Akibatnya, Anda fleksibel dengan mengubah ukuran VM dan keluarga dalam semua jenis VM dan keluarga yang ditawarkan di Zona Ketersediaan yang Anda sebarkan. Jadi, Anda dapat bereaksi fleksibel pada kondisi chanign atau bergerak lebih cepat ke ukuran atau keluarga VM yang lebih hemat biaya. Kami merekomendasikan metode ini untuk sistem non-produksi dan sistem produksi yang dapat bekerja dengan latensi log pengulangan yang lebih dekat ke 1 milidetik. Fungsionalitas tersebut saat ini dalam pratinjau publik.
Penyebaran melalui grup volume aplikasi Azure NetApp Files untuk SAP Hana (AVG)
Untuk menyebarkan volume ANF dengan kedekatan dengan Mesin Virtual Anda, fungsionalitas baru yang disebut grup volume aplikasi Azure NetApp Files untuk SAP Hana (AVG) telah dikembangkan. Ada serangkaian artikel yang mendokumentasikan fungsionalitas tersebut. Yang terbaik adalah memulai dengan artikel Memahami grup volume aplikasi Azure NetApp Files untuk SAP Hana. Saat Anda membaca artikel, menjadi jelas bahwa penggunaan AVG melibatkan penggunaan grup penempatan kedekatan Azure juga. Grup penempatan kedekatan digunakan oleh fungsionalitas baru untuk dikaitkan dengan volume yang sedang dibuat. Untuk memastikan bahwa selama masa pakai sistem HANA, VM tidak akan dipindahkan dari volume ANF, sebaiknya gunakan kombinasi Avset/ PPG untuk setiap zona yang Anda sebarkan. Urutan penyebaran akan terlihat seperti:
- Dengan menggunakan formulir, Anda perlu meminta penyematan AvSet kosong ke HW komputasi untuk memastikan bahwa Mesin Virtual tidak akan dipindahkan
- Menetapkan PPG ke Kumpulan Ketersediaan dan memulai Mesin Virtual yang ditetapkan ke Kumpulan Ketersediaan ini
- Menggunakan grup volume aplikasi Azure NetApp Files untuk fungsionalitas SAP Hana guna menyebarkan volume HANA Anda
Konfigurasi grup penempatan kedekatan untuk menggunakan AVG secara optimal akan terlihat seperti:
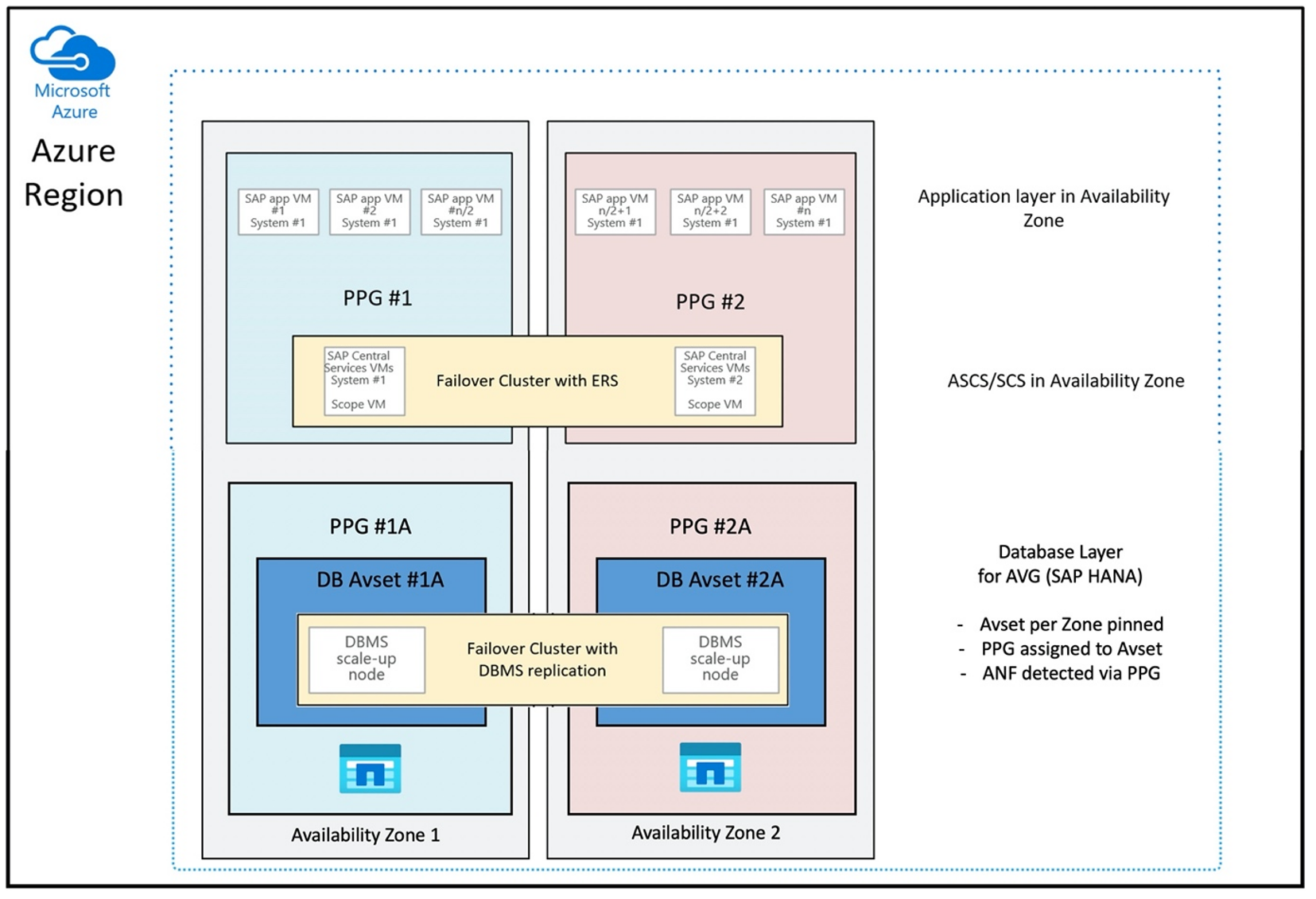
Diagram menunjukkan bahwa Anda akan menggunakan grup penempatan kedekatan Azure untuk lapisan DBMS. Sehingga dapat digunakan bersama dengan AVG. Yang terbaik adalah hanya menyertakan VM yang menjalankan instans HANA dalam grup penempatan kedekatan. Grup penempatan kedekatan diperlukan, meskipun hanya satu Mesin Virtual dengan satu instans HANA yang digunakan, agar AVG mengidentifikasi kedekatan terdekat dari perangkat keras ANF. Dan untuk mengalokasikan volume NFS pada ANF sedekat mungkin dengan Mesin Virtual yang menggunakan volume NFS.
Metode ini menghasilkan hasil yang paling optimal karena berkaitan dengan latensi rendah. Tidak hanya dengan mendapatkan volume NFS dan VM sedekat mungkin. Tetapi pertimbangan menempatkan data dan mengulang volume log di berbagai pengontrol pada backend NetApp juga diperhitungkan. Meskipun, kerugiannya adalah penyebaran VM Anda disematkan ke satu pusat data. Dengan itu Anda kehilangan fleksibilitas dalam mengubah jenis dan keluarga VM. Akibatnya, Anda harus membatasi metode ini ke sistem yang benar-benar memerlukan latensi penyimpanan yang rendah. Untuk semua sistem lainnya, Anda harus mencoba penyebaran dengan penyebaran zona tradisional VM dan ANF. Dalam kebanyakan kasus, ini cukup dalam hal latensi rendah. Ini juga memastikan pemeliharaan dan administrasi VM dan ANF yang mudah.
Ketersediaan
Pembaruan dan peningkatan sistem ANF diterapkan tanpa memengaruhi lingkungan pelanggan. SLA yang ditentukan adalah 99.99%.
Volume dan alamat IP dan pool kapasitas
Dengan ANF, penting untuk memahami cara infrastruktur yang mendasari dibangun. Kumpulan kapasitas hanyalah konstruksi, yang menyediakan kapasitas dan anggaran performa dan unit penagihan, berdasarkan tingkat layanan kumpulan kapasitas. Pool kapasitas tidak memiliki hubungan fisik dengan infrastruktur yang mendasarinya. Saat Anda membuat volume pada layanan, titik akhir penyimpanan dibuat. Alamat IP tunggal ditugaskan ke titik akhir penyimpanan ini untuk menyediakan akses data ke volume. Jika Anda membuat beberapa volume, semua volume didistribusikan di seluruh armada bare metal yang mendasarinya, terkait dengan titik akhir penyimpanan ini. ANF memiliki logika yang secara otomatis mendistribusikan beban kerja pelanggan setelah volume atau/dan kapasitas penyimpanan yang dikonfigurasi mencapai tingkat yang ditentukan sebelumnya secara internal. Anda mungkin melihat kasus-kasus seperti itu karena titik akhir penyimpanan baru, dengan alamat IP baru, akan dibuat secara otomatis untuk mengakses volume. Layanan ANF tidak memberikan kontrol pelanggan atas logika distribusi ini.
Volume log dan volume pencadangan log
"Log volume" (/hana/log)digunakan untuk menulis log redo online. Dengan demikian, ada file terbuka yang terletak di volume ini dan tidak masuk akal untuk merekam jepret (snapshot) volume ini. Logfil redo online diarsipkan atau dicadangkan ke volume pencadangan log setelah file log redo online penuh atau pencadangan log ulang dieksekusi. Untuk memberikan performa pencadangan yang wajar, volume pencadangan log memerlukan throughput yang baik. Untuk mengoptimalkan biaya penyimpanan, masuk akal untuk mengonsolidasikan volume pencadangan log dari beberapa instans HANA. Sehingga beberapa instans HANA memanfaatkan volume yang sama dan menulis cadangannya ke direktori yang berbeda. Dengan menggunakan konsolidasi seperti itu, Anda bisa mendapatkan lebih banyak throughput karena Anda perlu membuat volume sedikit lebih besar.
Hal yang sama berlaku untuk volume yang Anda gunakan untuk menulis cadangan database HANA secara penuh.
Cadangan
Selain pencadangan streaming dan layanan Azure Back yang mencadangkan database SAP Hana seperti, yang dijelaskan dalam artikel Panduan pencadangan untuk SAP Hana di Azure Virtual Machines, Azure NetApp Files membuka kemungkinan untuk melakukan pencadangan rekam jepret berbasis penyimpanan.
SAP HANA mendukung:
- Dukungan pencadangan snapshot berbasis penyimpanan untuk sistem kontainer tunggal dengan SAP HANA 1.0 SPS7 dan lebih tinggi
- Dukungan pencadangan snapshot berbasis penyimpanan untuk lingkungan HANA Multi Database Container (MDC) dengan penyewa tunggal dengan SAP HANA 2.0 SPS1 dan lebih tinggi
- Dukungan pencadangan snapshot berbasis penyimpanan untuk lingkungan HANA Multi Database Container (MDC) dengan banyak penyewa dengan SAP HANA 2.0 SPS4 dan lebih tinggi
Membuat cadangan snapshot berbasis penyimpanan adalah prosedur empat langkah sederhana,
- Membuat snapshot database HANA (internal) - aktivitas yang perlu Anda atau alat lakukan
- SAP HANA menulis data ke datafiles untuk membuat status yang konsisten pada penyimpanan - HANA melakukan langkah ini sebagai hasil dari membuat snapshot HANA
- Buat snapshot pada volume /hana/data pada penyimpanan - langkah yang perlu Anda atau alat lakukan. Tidak perlu melakukan snapshot pada volume /hana/log
- Hapus snapshot database HANA (internal) dan lanjutkan operasi normal - langkah yang perlu Anda atau alat lakukan
Peringatan
Melewatkan langkah terakhir atau gagal melakukan langkah terakhir berdampak parah pada permintaan memori SAP HANA dan dapat menyebabkan terhentinya SAP HANA
BACKUP DATA FOR FULL SYSTEM CREATE SNAPSHOT COMMENT 'SNAPSHOT-2019-03-18:11:00';

az netappfiles snapshot create -g mygroup --account-name myaccname --pool-name mypoolname --volume-name myvolname --name mysnapname
BACKUP DATA FOR FULL SYSTEM CLOSE SNAPSHOT BACKUP_ID 47110815 SUCCESSFUL SNAPSHOT-2020-08-18:11:00';
Prosedur pencadangan rekam jepret ini dapat dikelola dengan berbagai cara, dengan menggunakan berbagai alat. Salah satu contohnya adalah skrip Python “ntaphana_azure.py” yang tersedia di GitHub https://github.com/netapp/ntaphana Ini adalah contoh kode, disediakan “apa adanya” tanpa pemeliharaan atau dukungan apa pun.
Perhatian
Snapshot itu sendiri bukanlah cadangan yang dilindungi karena terletak di penyimpanan fisik yang sama dengan volume yang baru saja Anda ambil snapshotnya. Menjadi hal yang wajib untuk “melindungi” setidaknya satu snapshot per hari ke lokasi yang berbeda. Hal ini dapat dilakukan di lingkungan yang sama, di wilayah Azure terpencil atau di penyimpanan Azure Blob.
Solusi yang tersedia untuk cadangan konsisten aplikasi berbasis snapshot penyimpanan:
- Microsoft Apa itu alat Azure Application Consistent Snapshot adalah alat baris perintah yang memungkinkan perlindungan data untuk database pihak ketiga. Ini menangani semua orkestrasi yang diperlukan untuk menempatkan database ke dalam status konsisten aplikasi sebelum mengambil rekam jepret penyimpanan. Setelah rekam jepret penyimpanan diambil, alat mengembalikan database ke status operasional. AzAcSnap mendukung pencadangan berbasis snapshot untuk HANA Large Instance dan Azure NetApp Files. untuk detail selengkapnya, baca artikel Apa itu alat Azure Application Consistent Snapshot
- Untuk pengguna produk cadangan Commvault, opsi lainnya adalah Commvault IntelliSnap V.11.21 dan yang lebih baru. Versi Commvault ini atau yang lebih baru menawarkan dukungan snapshot Azure NetApp Files. Artikel Commvault IntelliSnap 11.21 menyediakan informasi lebih lanjut.
Cadangkan snapshot dengan menggunakan penyimpanan Azure Blob
Pencadangan ke penyimpanan Azure Blob adalah metode yang efektif dan cepat untuk menghemat cadangan snapshot penyimpanan database HANA berbasis ANF. Untuk menyimpan rekam jepret ke penyimpanan Azure Blob, alat AzCopy lebih disarankan. Unduh versi terbaru alat ini dan instal alat, misalnya, di direktori bin tempat skrip Python dari GitHub diinstal. Unduh alat AzCopy terbaru:
root # wget -O azcopy_v10.tar.gz https://aka.ms/downloadazcopy-v10-linux && tar -xf azcopy_v10.tar.gz --strip-components=1
Saving to: ‘azcopy_v10.tar.gz’
Fitur yang paling canggih adalah opsi SYNC. Jika Anda menggunakan opsi SYNC, azcopy menjaga sumber dan direktori tujuan tetap sinkron. Penggunaan parameter --delete-destination adalah penting. Tanpa parameter ini, azcopy tidak menghapus file di situs tujuan dan pemanfaatan ruang di sisi tujuan akan bertambah. Buat kontainer Block Blob di akun penyimpanan Azure Anda. Kemudian buat kunci SAS untuk kontainer Blob dan sinkronkan folder snapshot ke kontainer Azure Blob.
Misalnya, jika snapshot harian harus disinkronkan dengan kontainer Azure Blob untuk melindungi data. Dan hanya satu snapshot tersebut yang harus disimpan, perintah di bawah ini dapat digunakan.
root # > azcopy sync '/hana/data/SID/mnt00001/.snapshot' 'https://azacsnaptmytestblob01.blob.core.windows.net/abc?sv=2021-02-02&ss=bfqt&srt=sco&sp=rwdlacup&se=2021-02-04T08:25:26Z&st=2021-02-04T00:25:26Z&spr=https&sig=abcdefghijklmnopqrstuvwxyz' --recursive=true --delete-destination=true
Langkah berikutnya
Baca artikel:
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk