Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini untuk pengembang yang membutuhkan pemahaman yang lebih mendalam tentang komposisi skillset, dan mengasumsikan keakraban dengan konsep pengayaan AI tingkat tinggi, atau AI yang diterapkan, di Azure AI Search.
Skillset adalah objek yang dapat digunakan kembali di Azure AI Search yang dilampirkan ke pengindeks. Ini berisi satu atau beberapa keterampilan yang memanggil AI bawaan atau pemrosesan kustom eksternal atas dokumen yang diambil dari sumber data eksternal.
Diagram berikut mengilustrasikan aliran data dasar eksekusi skillset.
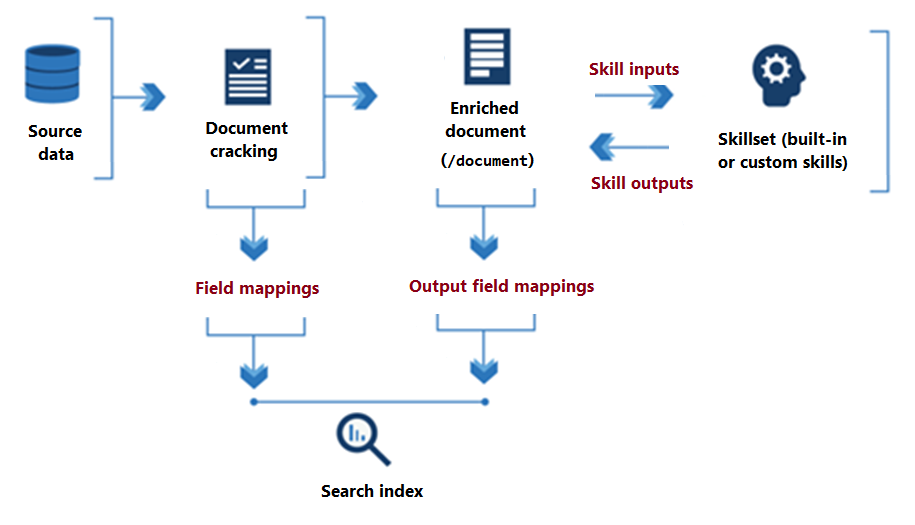
Dari awal pemrosesan set keterampilan hingga kesimpulannya, keterampilan membaca dari dan menulis ke dokumen yang diperkaya yang ada dalam memori. Awalnya, dokumen yang diperkaya hanyalah konten mentah yang diekstrak dari sumber data (diartikulasikan sebagai simpul "/document" akar). Dengan setiap eksekusi keterampilan, dokumen yang diperkaya mendapatkan struktur dan substansi saat setiap keterampilan menulis outputnya sebagai simpul dalam grafik.
Setelah eksekusi skillset selesai, output dokumen yang diperkaya menemukan jalannya ke dalam indeks melalui pemetaan bidang output yang ditentukan pengguna. Konten mentah apa pun yang ingin Anda transfer secara utuh, dari sumber ke indeks, didefinisikan melalui pemetaan bidang. Sebaliknya, pemetaan bidang output mentransfer konten dalam memori (simpul) ke indeks.
Untuk mengonfigurasi AI yang diterapkan, tentukan pengaturan dalam set keterampilan dan pengindeks.
Definisi skillset
Skillset adalah array dari satu atau beberapa keterampilan yang melakukan pengayaan, seperti menerjemahkan teks atau pengenalan karakter optik (OCR) pada file gambar. Keterampilan dapat menjadi keterampilan bawaan dari Microsoft, atau keterampilan kustom untuk memproses logika yang Anda host secara eksternal. Set keterampilan menghasilkan dokumen yang diperkaya yang dikonsumsi selama pengindeksan atau diproyeksikan ke penyimpanan pengetahuan.
Keterampilan memiliki konteks, input, dan output:
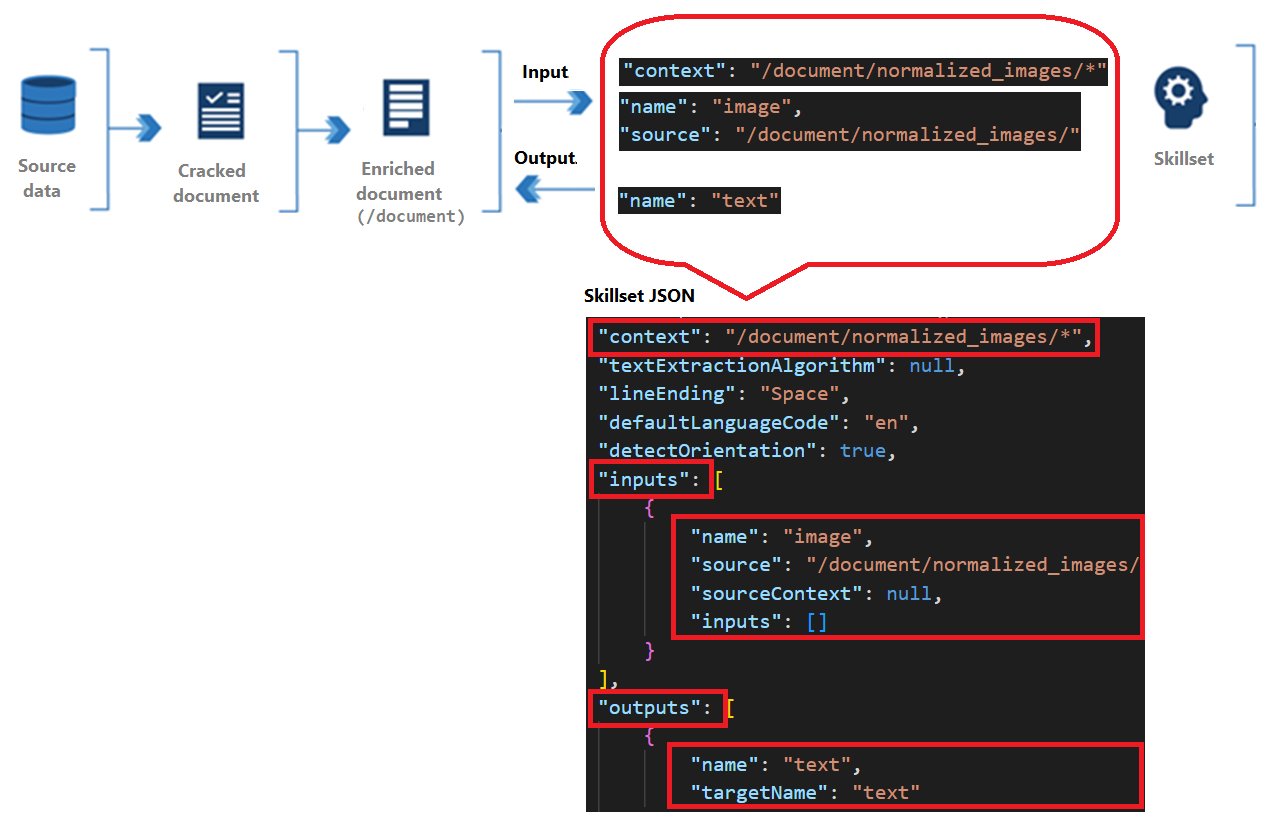
Konteks mengacu pada cakupan operasi, yang bisa sekali per dokumen atau sekali untuk setiap item dalam koleksi.
Input berasal dari simpul dalam dokumen yang diperkaya, di mana "sumber" dan "nama" mengidentifikasi simpul tertentu.
Output dikirim kembali ke dokumen yang diperkaya sebagai simpul baru. Nilai adalah simpul "nama" dan konten simpul. Jika nama node diduplikasi, Anda dapat mengatur nama target untuk disambiguasi.
Konteks keterampilan
Setiap keterampilan memiliki konteks, yang dapat berupa seluruh dokumen (/document) atau simpul yang lebih rendah di pohon (/document/countries/*).
Konteks menentukan:
Frekuensi keterampilan dijalankan, lebih dari satu nilai (sekali per bidang, per dokumen), atau untuk koleksi, di mana menambahkan
/*hasil dalam pemanggilan keterampilan untuk setiap instans dalam koleksi.Pernyataan output, atau di mana di pohon pengayaan output keterampilan ditambahkan. {i>Output
Bentuk {i>input.
Konteks Input Bentuk {i>Input Pemanggilan Keterampilan /document/countries/*/document/countries/*/states/*/zipcodes/*Daftar semua kode pos di negara/wilayah Sekali per negara/wilayah /document/countries/*/states/*/document/countries/*/states/*/zipcodes/*Daftar kode pos di negara bagian Sekali per kombinasi negara/wilayah dan negara bagian
Dependensi keterampilan
Keterampilan dapat dijalankan secara independen dan paralel, atau secara berurutan jika Anda memberi makan output dari satu keterampilan ke keterampilan lain. Contoh berikut menunjukkan dua keterampilan bawaan yang dijalankan secara berurutan:
Keterampilan #1 adalah keterampilan Pemisahan Teks yang menerima konten bidang sumber "reviews_text" sebagai input, dan membagi konten tersebut menjadi "halaman" dari 5.000 karakter sebagai output. Memisahkan teks besar menjadi gugus yang lebih kecil dapat menghasilkan hasil yang lebih baik untuk keterampilan seperti deteksi sentimen.
Keterampilan #2 adalah keterampilan Deteksi Sentimen menerima "halaman" sebagai input, dan menghasilkan bidang baru yang disebut "Sentimen" sebagai output yang berisi hasil analisis sentimen.
Perhatikan bagaimana output keterampilan pertama ("halaman") digunakan dalam analisis sentimen, di mana "/document/reviews_text/pages/*" adalah konteks dan input. Untuk informasi selengkapnya tentang rumusan jalur, lihat Cara mereferensikan pengayaan.
{
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SentimentSkill",
"name": "#2",
"description": null,
"context": "/document/reviews_text/pages/*",
"defaultLanguageCode": "en",
"inputs": [
{
"name": "text",
"source": "/document/reviews_text/pages/*",
}
],
"outputs": [
{
"name": "sentiment",
"targetName": "sentiment"
},
{
"name": "confidenceScores",
"targetName": "confidenceScores"
},
{
"name": "sentences",
"targetName": "sentences"
}
]
}
. . .
]
}
Pohon pengayaan
Dokumen yang diperkaya adalah struktur data sementara seperti pohon yang dibuat selama eksekusi skillset yang mengumpulkan semua perubahan yang diperkenalkan melalui keterampilan. Secara kolektif, pengayaan diwakili sebagai hierarki simpul yang dapat diatasi. Simpul juga menyertakan bidang yang tidak diperkaya yang diteruskan dalam verbatim dari sumber data eksternal.
Dokumen yang diperkaya ada selama durasi eksekusi set keterampilan, tetapi dapat di-cache atau dikirim ke penyimpanan pengetahuan.
Awalnya, dokumen yang diperkaya hanyalah konten yang diekstraksi dari sumber data selama pengambilan dokumen, di mana teks dan gambar diekstraksi dari sumber dan tersedia untuk analisis bahasa atau gambar.
Konten awal adalah metadata dan simpul akar (document/content). Simpul akar biasanya merupakan seluruh dokumen atau gambar yang dinormalisasi yang diekstrak dari sumber data selama pemecahan dokumen. Bagaimana data itu diartikulasikan dalam pohon pengayaan beragam untuk masing-masing jenis sumber data. Tabel berikut ini memperlihatkan status dokumen yang masuk ke dalam alur pengayaan untuk beberapa sumber data yang didukung:
| Sumber Data\Mode Penguraian | Default | JSON, JSON Lines & CSV |
|---|---|---|
| Penyimpanan Blob | /document/content /document/normalized_images/* … |
/document/{key1} /document/{key2} … |
| Azure SQL | /document/{column1} /document/{column2} … |
T/A |
| Azure Cosmos DB | /document/{key1} /document/{key2} … |
T/A |
Saat keterampilan mengeksekusi, output ditambahkan ke pohon pengayaan sebagai simpul baru. Jika eksekusi keterampilan melebihi seluruh dokumen, simpul ditambahkan pada tingkat pertama di bawah akar.
Simpul dapat digunakan sebagai input untuk keterampilan hilir. Misalnya, keterampilan yang membuat konten, seperti string yang diterjemahkan, dapat menjadi input untuk keterampilan yang mengenali entitas atau mengekstrak frasa kunci.
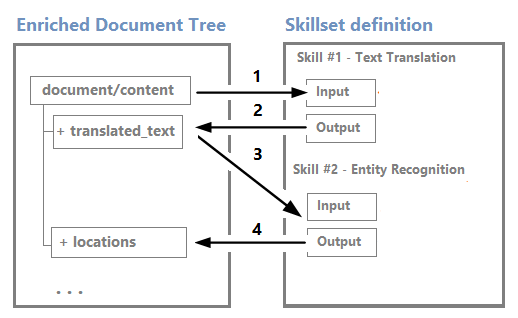
Meskipun Anda dapat memvisualisasikan dan bekerja dengan pohon pengayaan melalui editor visual Sesi Debug, sebagian besar merupakan struktur internal.
Pengayaan tidak dapat diubah: setelah dibuat, simpul tidak dapat diedit. Saat {i>skillsets
Anda dapat secara selektif hanya mempertahankan subset output pengayaan sehingga Anda hanya menyimpan apa yang ingin Anda gunakan. Pemetaan bidang output dalam definisi pengindeks Anda menentukan konten apa yang sebenarnya diserap dalam indeks pencarian. Demikian juga, jika Anda membuat penyimpanan pengetahuan, Anda dapat memetakan output ke dalam bentuk yang ditetapkan ke proyeksi.
Catatan
Format pohon pengayaan memungkinkan alur pengayaan untuk melampirkan metadata ke jenis data primitif sekalipun. Metadata tidak akan menjadi objek JSON yang valid, tetapi dapat diproyeksikan ke dalam format JSON yang valid dalam definisi proyeksi di penyimpanan pengetahuan. Untuk informasi selengkapnya, lihat Keterampilan pembentuk.
Definisi pengindeks
Pengindeks memiliki properti dan parameter yang digunakan untuk mengonfigurasi eksekusi pengindeks. Di antara properti tersebut adalah pemetaan yang mengatur jalur data ke bidang dalam indeks pencarian.

Ada dua set pemetaan:
"fieldMappings" memetakan bidang sumber ke bidang pencarian.
"outputFieldMappings" memetakan simpul dalam dokumen yang diperkaya ke bidang pencarian.
Properti "sourceFieldName" menentukan bidang di sumber data Anda atau simpul di pohon pengayaan. Properti "targetFieldName" menentukan bidang pencarian dalam indeks yang menerima konten.
Contoh pengayaan
Menggunakan skillset ulasan hotel sebagai titik referensi, contoh ini menjelaskan bagaimana pohon pengayaan berkembang melalui eksekusi keterampilan menggunakan diagram konseptual.
Contoh ini juga menunjukkan:
- Bagaimana konteks dan input keterampilan bekerja untuk menentukan berapa kali keterampilan dijalankan
- Bentuk {i>input
Dalam contoh ini, bidang sumber dari file CSV menyertakan ulasan pelanggan tentang hotel ("reviews_text") dan peringkat ("reviews_rating"). Pengindeks menambahkan bidang metadata dari penyimpanan Blob, dan keterampilan menambahkan teks terjemahan, skor sentimen, dan deteksi frasa kunci.
Dalam contoh ulasan hotel, "dokumen" dalam proses pengayaan mewakili satu ulasan hotel.
Tip
Anda dapat membuat indeks pencarian dan penyimpanan pengetahuan untuk data ini di portal Azure atau REST API. Anda juga dapat menggunakan Sesi Debug untuk wawasan mengenai komposisi skillset, dependensi, dan efek pada pohon pengayaan. Gambar dalam artikel ini ditarik dari Sesi Debug.
Secara konseptual, pohon pengayaan awal terlihat sebagai berikut:

Simpul akar untuk semua pengayaan adalah "/document". Saat Anda bekerja dengan pengindeks blob, simpul "/document" memiliki simpul anak dan "/document/content""/document/normalized_images". Ketika data adalah CSV, seperti dalam contoh ini, nama kolom dipetakan ke simpul di bawah "/document".
Keterampilan #1: Split skill (Keterampilan untuk memisah)
Ketika konten sumber terdiri dari potongan teks yang besar, sangat membantu untuk memecahnya menjadi komponen yang lebih kecil untuk vektorisasi terintegrasi, atau untuk akurasi bahasa, sentimen, dan deteksi frasa kunci yang lebih besar. Ada dua hal yang tersedia: halaman dan kalimat. Halaman terdiri dari sekitar 5.000 karakter.
Alternatif untuk memotong dengan keterampilan Split adalah melalui keterampilan Tata Letak Dokumen, tetapi keterampilan itu berada di luar cakupan untuk artikel ini.
Saat pemotongan diperlukan, keterampilan Split biasanya pertama dalam set keterampilan.
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
Dengan konteks keterampilan"/document/reviews_text", keterampilan untuk memisahkan akan dijalankan sekali untuk reviews_text. Output keterampilan adalah daftar di mana reviews_text dipotong menjadi 5.000 segmen karakter. Output dari keterampilan terpisah diberi nama pages dan ditambahkan ke pohon pengayaan. Fitur ini targetName memungkinkan Anda mengganti nama output keterampilan sebelum ditambahkan ke pohon pengayaan.
Pohon pengayaan sekarang memiliki simpul baru yang ditempatkan di bawah konteks keterampilan. Simpul ini tersedia untuk setiap pemetaan bidang keterampilan, proyeksi, atau {i>output

Untuk mengakses salah satu pengayaan yang ditambahkan ke simpul dengan keterampilan, jalur lengkap untuk pengayaan diperlukan. Misalnya, jika Anda ingin menggunakan teks dari simpul pages sebagai input ke keterampilan lain, tentukan sebagai "/document/reviews_text/pages/*". Untuk informasi selengkapnya tentang jalur, lihat Pengayaan referensi.
Keterampilan #2 Language detection (Deteksi bahasa)
Dokumen ulasan hotel mencakup tanggapan pelanggan yang dinyatakan dalam beberapa bahasa. Keterampilan deteksi bahasa menentukan bahasa mana yang digunakan. Hasilnya kemudian diteruskan ke ekstraksi frasa kunci dan deteksi sentimen (tidak ditunjukkan), dengan mempertimbangkan bahasa saat mendeteksi sentimen dan frasa.
Meskipun keterampilan deteksi bahasa adalah keterampilan ketiga (keterampilan #3) yang ditentukan dalam set keterampilan, itu adalah keterampilan berikutnya untuk dijalankan. Ini tidak memerlukan input apa pun sehingga dijalankan secara paralel dengan keterampilan sebelumnya. Seperti keterampilan memisah yang mendahuluinya, keterampilan deteksi bahasa juga digunakan satu kali untuk setiap dokumen. Pohon pengayaan sekarang memiliki simpul baru untuk bahasa.

Keterampilan#3 dan #4 (analisis sentimen dan deteksi frasa kunci)
Umpan balik pelanggan mencerminkan berbagai pengalaman positif dan negatif. Keterampilan analisis sentimen menganalisis umpan balik dan memberikan skor sepanjang kontinum angka negatif ke positif, atau netral jika sentimen tidak ditentukan. Sejalan dengan analisis sentimen, deteksi frase kunci mengidentifikasi dan mengekstrak kata-kata dan frase pendek yang tampak seperti sebab-akibat.
Mengingat konteks /document/reviews_text/pages/*, analisis sentimen dan keterampilan frasa kunci dipanggil sekali untuk setiap item dalam pages koleksi. {i>Output
Anda sekarang harus dapat melihat sisa keterampilan dalam set keterampilan dan memvisualisasikan bagaimana pohon pengayaan tumbuh dengan eksekusi setiap keterampilan. Beberapa keterampilan, seperti keterampilan menggabungkan dan keterampilan membentuk, juga membuat simpul baru tetapi hanya menggunakan data dari simpul yang ada dan tidak membuat pengayaan baru yang bersih.

Warna konektor di pohon di atas menunjukkan bahwa pengayaan dibuat oleh keterampilan yang berbeda dan simpul perlu ditangani secara individual dan tidak akan menjadi bagian dari objek yang dikembalikan saat memilih simpul induk.
Keterampilan#5 Keterampilan pembentuk
Jika output termasuk penyimpanan pengetahuan, tambahkan keterampilan Pembentuk sebagai langkah terakhir. Keterampilan Pembentuk menciptakan bentuk data dari simpul di pohon pengayaan. Misalnya, Anda mungkin ingin mengkonsolidasikan beberapa simpul menjadi satu bentuk. Anda kemudian dapat memproyeksikan bentuk ini sebagai tabel (simpul menjadi kolom dalam tabel), mengirim bentuk berdasarkan nama ke proyeksi tabel.
Keterampilan Pembentuk mudah untuk digunakan karena berfokus pada pembentukan di bawah satu keterampilan. Atau, Anda dapat memilih pembentukan sebaris dalam proyeksi individu. Keterampilan Pembentuk tidak menambahkan atau mengurangi pohon pengayaan, sehingga tidak divisualisasikan. Sebagai gantinya, Anda dapat menganggap keterampilan Shaper sebagai sarana di mana Anda menyusun ulang pohon pengayaan yang sudah Anda miliki. Secara konseptual, keterampilan ini mirip dengan membuat tampilan dari tabel dalam database.
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"description": null,
"context": "/document",
"inputs": [
{
"name": "name",
"source": "/document/name"
},
{
"name": "reviews_date",
"source": "/document/reviews_date"
},
{
"name": "reviews_rating",
"source": "/document/reviews_rating"
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "AzureSearch_DocumentKey",
"source": "/document/AzureSearch_DocumentKey"
},
{
"name": "pages",
"sourceContext": "/document/reviews_text/pages/*",
"inputs": [
{
"name": "Sentiment",
"source": "/document/reviews_text/pages/*/Sentiment"
},
{
"name": "LanguageCode",
"source": "/document/Language"
},
{
"name": "Page",
"source": "/document/reviews_text/pages/*"
},
{
"name": "keyphrase",
"sourceContext": "/document/reviews_text/pages/*/Keyphrases/*",
"inputs": [
{
"name": "Keyphrases",
"source": "/document/reviews_text/pages/*/Keyphrases/*"
}
]
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "tableprojection"
}
]
}
Langkah berikutnya
Dengan pengantar dan contoh di belakang Anda, cobalah membuat skillset pertama Anda menggunakan keterampilan bawaan.