Cara membentuk hasil di Azure AI Search
Artikel ini menjelaskan cara bekerja dengan respons kueri di Azure AI Search. Struktur respons ditentukan oleh parameter dalam kueri itu sendiri, seperti yang dijelaskan dalam Dokumen Pencarian (REST) atau Kelas SearchResults (Azure untuk .NET).
Parameter pada kueri menentukan:
- Pilihan bidang
- Jumlah kecocokan yang ditemukan dalam indeks untuk kueri
- Penomoran
- Jumlah hasil dalam respons (hingga 50, secara default)
- Susunan urutan
- Penyorotan istilah dalam hasil, cocok pada seluruh atau sebagian istilah dalam isi
Komposisi hasil
Hasilnya bersifat tabular, terdiri dari bidang dari semua bidang "dapat diambil", atau terbatas hanya pada bidang yang ditentukan dalam $select parameter. Baris adalah dokumen yang cocok.
Anda dapat memilih bidang mana yang ada di hasil pencarian. Meskipun dokumen pencarian mungkin memiliki sejumlah besar bidang, biasanya hanya beberapa yang diperlukan untuk mewakili setiap dokumen dalam hasil. Pada permintaan kueri, tambahkan $select=<field list> untuk menentukan bidang "dapat diambil" mana yang akan muncul dalam respons.
Pilih bidang yang menawarkan kontras dan diferensiasi di antara dokumen, memberikan informasi yang memadai untuk mengundang respons klik-taut di bagian pengguna. Di situs e-commerce, mungkin nama produk, deskripsi, merek, warna, ukuran, harga, dan peringkat. Untuk indeks sampel hotel bawaan, mungkin bidang "pilih" dalam contoh berikut:
POST /indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City"
"count": true
}
Kesalahan atau Hasil Tak Terduga
Terkadang, konten hasil seaarch tidak terduga. Misalnya, Anda mungkin menemukan bahwa beberapa hasil tampaknya duplikat, atau hasil yang akan muncul di dekat bagian atas diposisikan lebih rendah dalam hasil. Saat hasil kueri tidak terduga, Anda bisa mencoba modifikasi kueri ini untuk melihat apakah hasilnya meningkat:
Mengubah
searchMode=any(default)searchMode=allharus memerlukan kecocokan pada semua kriteria, bukan salah satu kriteria. Ini terutama berlaku ketika operator boolean disertakan kueri.Bereksperimenlah dengan penganalisis leksikal atau penganalisis khusus yang berbeda untuk melihat apakah itu mengubah hasil kueri. Penganalisis default memecah kata-kata yang dihubungkan dan mengurangi kata-kata menjadi bentuk akar, yang biasanya meningkatkan ketahanan respons kueri. Namun, jika Anda perlu mempertahankan tanda hubung, atau jika string menyertakan karakter khusus, Anda mungkin perlu mengonfigurasi penganalisis kustom untuk memastikan indeks berisi token dalam format yang tepat. Untuk informasi selengkapnya, lihat Pencarian dan pola istilah parsial dengan karakter khusus.
Menghitung kecocokan
Parameter hitungan mengembalikan jumlah dokumen dalam indeks yang dianggap cocok untuk kueri. Untuk mengembalikan jumlah, tambahkan $count=true ke permintaan kueri. Tidak ada nilai maksimum yang diberlakukan oleh layanan pencarian. Bergantung pada kueri dan konten dokumen Anda, jumlahnya bisa sama tingginya dengan setiap dokumen dalam indeks.
Hitungan akurat ketika indeks stabil. Jika sistem secara aktif menambahkan, memperbarui, atau menghapus dokumen, jumlahnya akan menjadi perkiraan, tidak termasuk dokumen apa pun yang tidak sepenuhnya diindeks.
Jumlah tidak akan terpengaruh oleh pemeliharaan rutin atau beban kerja lain pada layanan pencarian. Namun jika Anda memiliki beberapa partisi dan satu replika, Anda dapat mengalami fluktuasi jangka pendek dalam jumlah dokumen (beberapa menit) saat partisi dimulai ulang.
Tip
Untuk memeriksa operasi pengindeksan, Anda dapat mengonfirmasi apakah indeks berisi jumlah dokumen yang diharapkan dengan menambahkan $count=true kueri pencarian search=* kosong. Hasilnya adalah jumlah lengkap dokumen dalam indeks Anda.
Saat menguji sintaks kueri, $count=true dapat dengan cepat memberi tahu Anda apakah modifikasi Anda mengembalikan hasil yang lebih besar atau lebih sedikit, yang dapat menjadi umpan balik yang berguna.
Hasil penomoran
Secara default, mesin pencari mengembalikan hingga 50 kecocokan pertama. 50 teratas ditentukan oleh skor pencarian, dengan asumsi kueri adalah pencarian teks lengkap atau semantik. Jika tidak, 50 teratas adalah urutan arbitrer untuk kueri kecocokan yang tepat (dengan seragam "@searchScore=1,0" menunjukkan peringkat arbitrer).
Batas atas adalah 1.000 dokumen yang dikembalikan per halaman hasil pencarian, sehingga Anda dapat mengatur bagian atas untuk mengembalikan hingga 1000 dokumen dalam hasil pertama. Di API pratinjau yang lebih baru, jika Anda menggunakan kueri hibrid, Anda dapat menentukan maxTextRecallSize untuk mengembalikan hingga 10.000 dokumen.
Untuk mengontrol halaman semua dokumen yang dikembalikan dalam kumpulan hasil, tambahkan $top dan $skip parameter ke permintaan kueri GET, atau top dan skip ke permintaan kueri POST. Daftar berikut menjelaskan logikanya.
Kembalikan set pertama dari 15 dokumen yang cocok ditambah jumlah total kecocokan:
GET /indexes/<INDEX-NAME>/docs?search=<QUERY STRING>&$top=15&$skip=0&$count=trueKembalikan set kedua, lewati 15 pertama untuk mendapatkan 15 berikutnya:
$top=15&$skip=15. Ulangi untuk set ketiga 15:$top=15&$skip=30
Hasil kueri paginated tidak dijamin stabil jika indeks yang mendasarinya berubah. Halaman mengubah nilai $skip untuk setiap halaman, tetapi setiap kueri independen dan beroperasi pada tampilan data saat ini seperti yang ada dalam indeks pada waktu kueri (dengan kata lain, tidak ada penembolokan atau rekam jepret hasil, seperti yang ditemukan dalam database tujuan umum).
Berikut ini adalah contoh bagaimana Anda mungkin mendapatkan duplikat. Asumsikan indeks dengan empat dokumen:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
Sekarang asumsikan Anda ingin hasil dikembalikan dua sekaligus, diurutkan berdasarkan peringkat. Anda akan menjalankan kueri ini untuk mendapatkan halaman pertama hasil: $top=2&$skip=0&$orderby=rating desc, menghasilkan hasil berikut:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
Pada layanan, anggaplah dokumen kelima ditambahkan ke indeks di antara panggilan kueri: { "id": "5", "rating": 4 }. Tak lama kemudian, Anda menjalankan kueri untuk mengambil halaman kedua: $top=2&$skip=2&$orderby=rating desc, dan mendapatkan hasil ini:
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
Perhatikan bahwa dokumen 2 diambil dua kali. Ini karena dokumen baru 5 memiliki nilai peringkat yang lebih besar, sehingga mengurutkan sebelum dokumen 2 dan menempati di halaman pertama. Meskipun perilaku ini mungkin tidak terduga, ini merupakan ciri khas bagaimana mesin pencari berperilaku.
Penomoran melalui sejumlah besar hasil
Menggunakan $top dan $skip memungkinkan kueri pencarian ke halaman hingga 100.000 hasil, tetapi bagaimana jika hasilnya lebih besar dari 100.000? Untuk halaman melalui respons yang besar ini, gunakan urutan pengurutan dan filter rentang sebagai solusi untuk $skip.
Dalam solusi ini, urutkan dan filter diterapkan ke bidang ID dokumen atau bidang lain yang unik untuk setiap dokumen. Bidang unik harus memiliki filterable dan sortable atribusi dalam indeks pencarian.
Terbitkan kueri untuk mengembalikan halaman lengkap hasil yang diurutkan.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }Pilih hasil terakhir yang dikembalikan oleh kueri pencarian. Contoh hasil dengan hanya nilai "id" yang ditampilkan di sini.
{ "id": "50" }Gunakan nilai "id" tersebut dalam kueri rentang untuk mengambil halaman hasil berikutnya. Bidang "id" ini harus memiliki nilai unik, jika tidak, penomoran halaman dapat mencakup hasil duplikat.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }Penomoran halaman berakhir saat kueri mengembalikan hasil nol.
Catatan
Atribut "dapat difilter" dan "dapat diurutkan" hanya dapat diaktifkan ketika bidang pertama kali ditambahkan ke indeks, atribut tersebut tidak dapat diaktifkan pada bidang yang ada.
Hasil pengurutan
Dalam kueri pencarian teks lengkap, hasil dapat diberi peringkat dengan:
- skor pencarian
- skor reranker semantik
- urutan pengurutan pada bidang "dapat diurutkan"
Anda juga dapat meningkatkan kecocokan apa pun yang ditemukan di bidang tertentu dengan menambahkan profil penilaian.
Urutan berdasarkan skor pencarian
Untuk kueri pencarian teks lengkap, hasil secara otomatis diberi peringkat oleh skor pencarian, dihitung berdasarkan frekuensi istilah dan kedekatan dalam dokumen (berasal dari TF-IDF), dengan skor yang lebih tinggi akan dokumen memiliki kecocokan yang lebih atau lebih kuat pada istilah pencarian.
Rentang "@search.score" tidak terbatas, atau 0 hingga (tetapi tidak termasuk) 1,00 pada layanan yang lebih lama.
Untuk salah satu algoritma, "@search.score" sama dengan 1,00 menunjukkan tataan hasil yang tidak dikoreksi atau tidak dikelola, di mana skor 1.0 seragam di semua hasil. Hasil yang tidak ditandai terjadi ketika formulir kueri adalah pencarian fuzzy, kueri kartubebas atau regex, atau pencarian kosong (search=*). Jika Anda perlu memaksakan struktur peringkat atas hasil yang $orderby tidak dikoreksi, pertimbangkan ekspresi untuk mencapai tujuan tersebut.
Urutan oleh reranker semantik
Jika Anda menggunakan peringkat semantik, "@search.rerankerScore" menentukan urutan pengurutan hasil Anda.
Rentang "@search.rerankerScore" adalah 1 hingga 4,00, di mana skor yang lebih tinggi menunjukkan pertandingan semantik yang lebih kuat.
Pesan dengan $orderby
Jika pemesanan yang konsisten adalah persyaratan aplikasi, Anda dapat menentukan $orderby ekspresi pada bidang. Hanya bidang yang diindeks sebagai "dapat diurutkan" yang dapat digunakan untuk mengurutkan hasil.
Bidang yang umum digunakan dalam $orderby meliputi peringkat, tanggal, dan lokasi. Pemfilteran menurut lokasi mengharuskan ekspresi filter memanggil geo.distance() fungsi, selain nama bidang.
Bidang numerik (Edm.Double, Edm.Int32, Edm.Int64) diurutkan dalam urutan numerik (misalnya, 1, 2, 10, 11, 20).
Bidang string (Edm.String, sub-bidang Edm.ComplexType) diurutkan dalam urutan pengurutan ASCII atau urutan pengurutan Unicode, tergantung pada bahasanya. Anda tidak dapat mengurutkan koleksi jenis apa pun.
Konten numerik dalam bidang string diurutkan menurut abjad (1, 10, 11, 2, 20).
String huruf besar diurutkan di depan huruf kecil (APPLE, Apple, PISANG, Pisang, apel, pisang). Anda dapat menetapkan normalizer teks untuk melakukan praproses teks sebelum mengurutkan untuk mengubah perilaku ini. Menggunakan tokenizer huruf kecil pada bidang tidak akan berpengaruh pada perilaku pengurutan karena Azure AI Search mengurutkan salinan bidang yang tidak dianalisis.
String yang mengarah dengan diakritik muncul terakhir (Äpfel, Öffnen, Üben)
Meningkatkan relevansi menggunakan profil penilaian
Pendekatan lain yang mempromosikan konsistensi pesanan adalah menggunakan profil penilaian kustom. Profil penilaian memberi Anda kontrol lebih besar atas peringkat item dalam hasil pencarian, dengan kemampuan untuk meningkatkan kecocokan yang ditemukan di bidang tertentu. Logika penilaian tambahan dapat membantu mengambil alih perbedaan kecil di antara replika karena skor pencarian untuk setiap dokumen lebih jauh. Kami merekomendasikan algoritma peringkat untuk pendekatan ini.
Penyorotan hit
Penyorotan klik mengacu pada pemformatan teks (seperti sorotan tebal atau kuning) yang diterapkan pada istilah yang cocok, sehingga mudah untuk menemukan kecocokan. Penyorotan berguna untuk bidang konten yang lebih panjang, seperti bidang deskripsi, di mana kecocokan tidak segera jelas.
Perhatikan bahwa penyorotan diterapkan pada istilah individual. Tidak ada kemampuan sorotan untuk konten seluruh bidang. Jika Anda ingin menyoroti frasa, Anda harus memberikan istilah yang cocok (atau frasa) dalam string kueri yang diapit kutipan. Teknik ini dijelaskan lebih lanjut di bagian ini.
Petunjuk penyorotan hit disediakan pada permintaan kueri. Kueri yang memicu ekspansi kueri di komputer, seperti pencarian fuzzy dan kartubebas, memiliki dukungan terbatas untuk penyorotan klik.
Persyaratan untuk penyorotan hit
- Bidang harus
Edm.StringatauCollection(Edm.String) - Bidang harus diatribusikan saat dapat dicari
Tentukan penyorotan dalam permintaan
Untuk mengembalikan istilah yang disorot, sertakan parameter "sorotan" dalam permintaan kueri. Parameter diatur ke daftar bidang yang dibatasi koma.
Secara default, mark up format adalah <em>, tetapi Anda dapat mengambil alih tag menggunakan highlightPreTag parameter dan highlightPostTag . Kode klien Anda menangani respons (misalnya, menerapkan font tebal atau latar belakang kuning).
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
Secara default, Azure AI Search mengembalikan hingga lima sorotan per bidang. Anda dapat menyesuaikan angka ini dengan menambahkan tanda hubung diikuti dengan bilangan bulat. Misalnya, "highlight": "description-10" mengembalikan hingga 10 istilah yang disorot pada konten yang cocok di bidang "deskripsi".
Hasil yang disorot
Saat penyorotan ditambahkan ke kueri, respons menyertakan "@search.highlights" untuk setiap hasil sehingga kode aplikasi Anda dapat menargetkan struktur tersebut. Daftar bidang yang ditentukan untuk "sorotan" disertakan dalam respons.
Dalam pencarian kata kunci, setiap istilah dipindai secara independen. Kueri untuk "rahasia ilahi" akan mengembalikan kecocokan pada dokumen apa pun yang berisi salah satu istilah.
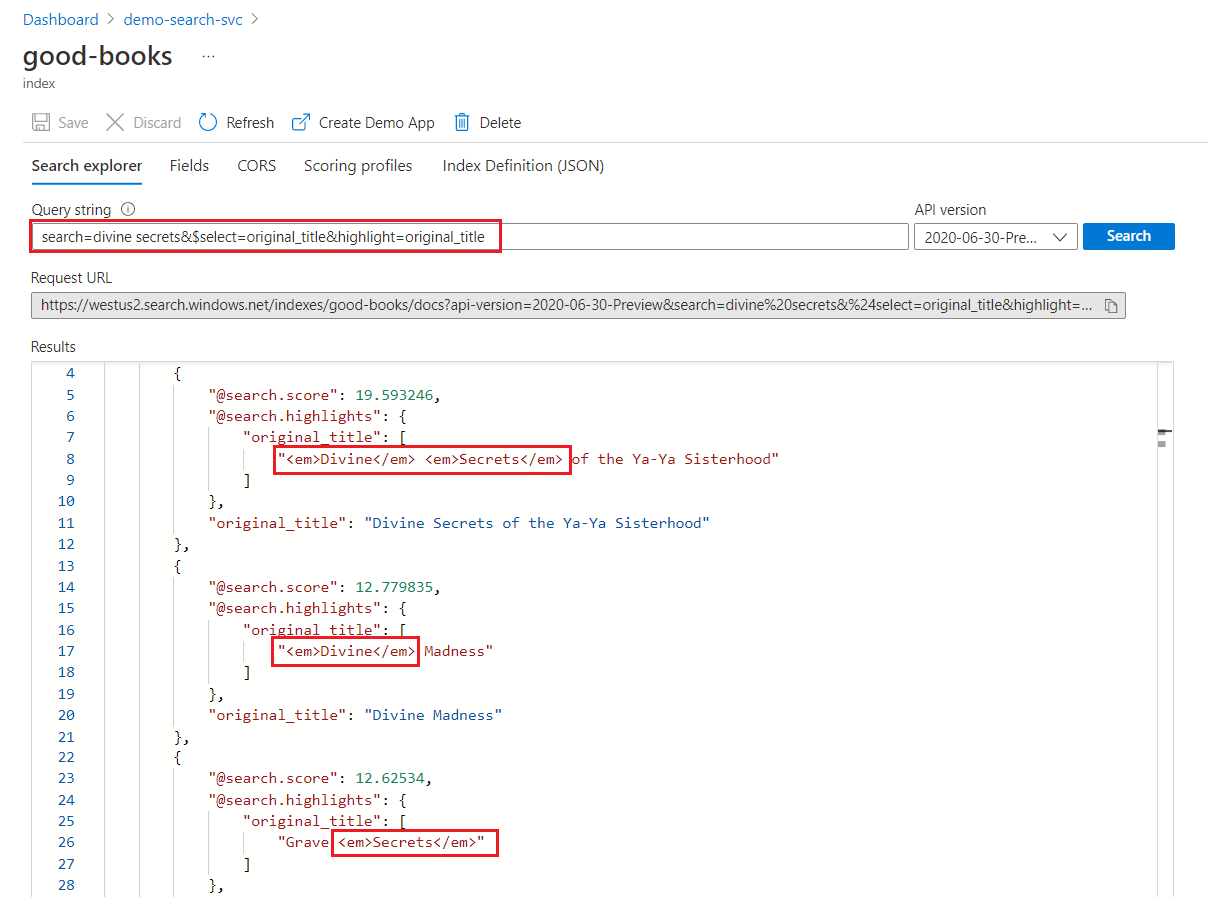
Penyorotan pencarian kata kunci
Dalam bidang yang disorot, pemformatan diterapkan ke seluruh istilah. Misalnya, pada pertandingan melawan "Rahasia Ilahi dari Ya-Ya Sisterhood", pemformatan diterapkan ke setiap istilah secara terpisah, meskipun berturut-turut.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
Penyorotan pencarian frasa
Pemformatan seluruh istilah berlaku bahkan pada pencarian frasa, di mana beberapa istilah diapit dalam tanda kutip ganda. Contoh berikut adalah kueri yang sama, kecuali bahwa "rahasia ilahi" dikirimkan sebagai frasa yang diapit kutipan (beberapa klien REST mengharuskan Anda keluar dari tanda kutip interior dengan garis miring \"terbalik ):
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
Karena kriteria sekarang memiliki kedua istilah, hanya satu kecocokan yang ditemukan dalam indeks pencarian. Respons terhadap kueri di atas terlihat seperti ini:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
Penyorotan frasa pada layanan yang lebih lama
layanan Pencarian yang dibuat sebelum 15 Juli 2020 menerapkan pengalaman penyorotan yang berbeda untuk kueri frasa.
Untuk contoh berikut, asumsikan string kueri yang menyertakan frasa yang diapit kutipan "super bowl". Sebelum Juli 2020, istilah apa pun dalam frasa disorot:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
Untuk layanan pencarian yang dibuat setelah Juli 2020, hanya frasa yang cocok dengan kueri frasa lengkap yang akan dikembalikan dalam "@search.highlights":
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
Langkah berikutnya
Untuk membuat halaman pencarian klien Anda dengan cepat, pertimbangkan opsi ini:
Membuat aplikasi demo, di portal, membuat halaman HTML dengan bilah pencarian, navigasi tersaring, dan area hasil yang menyertakan gambar.
Menambahkan pencarian ke aplikasi ASP.NET Core (MVC) adalah tutorial dan sampel kode yang membangun klien fungsional.
Menambahkan pencarian ke aplikasi web adalah tutorial dan sampel kode yang menggunakan pustaka React JavaScript untuk pengalaman pengguna. Aplikasi ini disebarkan menggunakan Azure Static Web Apps.