Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Artikel ini menjelaskan algoritma penilaian relevansi BM25 yang digunakan untuk menghitung skor pencarian untuk pencarian teks lengkap. Relevansi BM25 eksklusif untuk pencarian teks lengkap. Kueri filter, kueri lengkapi otomatis dan yang disarankan, pencarian kartubebas, dan kueri pencarian fuzzy tidak diberi skor atau diberi peringkat untuk relevansi.
Algoritma penilaian yang digunakan dalam pencarian teks lengkap
Azure AI Search menyediakan algoritma penilaian berikut untuk pencarian teks lengkap:
| Algoritma | Penggunaan | Rentang |
|---|---|---|
BM25Similarity |
Memperbaiki algoritma pada semua layanan pencarian yang dibuat setelah Juli 2020. Anda dapat mengonfigurasi algoritma ini, tetapi Anda tidak dapat beralih ke algoritma yang lebih lama (klasik). | Tidak terikat. |
ClassicSimilarity |
Default pada layanan pencarian lama yang lebih awal Juli 2020. Pada layanan yang lebih lama, Anda dapat ikut serta untuk BM25 dan memilih algoritma BM25 berdasarkan per indeks. | 0 < 1,00 |
Baik BM25 maupun Klasik adalah fungsi pengambilan seperti TF-IDF yang menggunakan frekuensi istilah (TF) dan frekuensi dokumen terbalik (IDF) sebagai variabel untuk menghitung skor relevansi untuk setiap pasangan kueri dokumen, yang kemudian digunakan untuk hasil peringkat. Meskipun secara konseptual mirip dengan klasik, BM25 berakar pada pengambilan informasi probabilistik yang menghasilkan kecocokan yang lebih intuitif, seperti yang diukur oleh penelitian pengguna.
BM25 menawarkan opsi kustomisasi tingkat lanjut, seperti memungkinkan pengguna memutuskan bagaimana skor relevansi diskalakan dengan frekuensi istilah istilah yang cocok.
Cara kerja peringkat BM25
Penilaian relevansi mengacu pada komputasi skor pencarian (@search.score) yang berfungsi sebagai indikator relevansi item dalam konteks kueri saat ini. Rentang tidak terbatas. Namun, semakin tinggi skornya, semakin relevan item tersebut.
Skor pencarian dihitung berdasarkan properti statistik input string dan kueri itu sendiri. Pencarian Azure AI menemukan dokumen yang cocok dengan istilah pencarian (beberapa atau semua, tergantung pada searchMode), mendukung dokumen yang berisi banyak instans istilah pencarian. Skor pencarian naik lebih tinggi lagi jika istilah tersebut jarang ditemukan di seluruh indeks data, tetapi umum dalam dokumen. Dasar pendekatan untuk menghitung relevansi ini dikenal sebagai TF-IDF atau istilah frekuensi terbalik dokumen frekuensi.
Skor pencarian dapat diulang sepanjang kumpulan hasil. Ketika beberapa hit memiliki skor pencarian yang sama, urutan item dengan skor yang sama tidak terdefinisi dan tidak stabil. Jalankan kueri lagi, dan Anda mungkin melihat posisi pergeseran item, terutama jika Anda menggunakan layanan gratis atau layanan yang dapat ditagih dengan beberapa replika. Mengingat dua item dengan skor yang identik, tidak ada jaminan bahwa satu item muncul terlebih dahulu.
Untuk memutuskan dasi di antara skor berulang, Anda dapat menambahkan klausa $orderby ke urutan pertama menurut skor, lalu mengurutkan menurut bidang lain yang dapat diurutkan (misalnya, $orderby=search.score() desc,Rating desc).
Hanya bidang yang ditandai sebagai searchable dalam indeks, atau searchFields dalam kueri, yang digunakan untuk penilaian. Hanya bidang yang ditandai sebagai retrievable, atau bidang yang ditentukan dalam select kueri, yang dikembalikan dalam hasil pencarian, bersama dengan skor pencariannya.
Catatan
A @search.score = 1 menunjukkan kumpulan hasil yang tidak diberi skor atau tidak diberi peringkat. Skor seragam di semua hasil. Hasil yang tidak dinilai terjadi ketika formulir kueri adalah pencarian fuzzy, kueri kartubebas atau regex, atau pencarian kosong (search=*, kadang-kadang dipasangkan dengan filter, di mana filter adalah sarana utama untuk mengembalikan kecocokan).
Segmen video berikut ini diteruskan dengan cepat ke penjelasan tentang algoritma peringkat yang tersedia secara umum yang digunakan dalam Azure AI Search. Anda dapat menonton video lengkap untuk latar belakang lebih lanjut.
Skor dalam hasil teks
Setiap kali hasil diberi peringkat, @search.score properti berisi nilai yang digunakan untuk mengurutkan hasil.
Tabel berikut mengidentifikasi properti penilaian, algoritma, dan rentang.
| Metode pencarian | Parameter | Algoritma penilaian | Rentang |
|---|---|---|---|
| pencarian teks lengkap | @search.score |
Algoritma BM25, menggunakan parameter yang ditentukan dalam indeks. | Tidak terikat. |
Variasi skor
Skor pencarian memberikan pengertian umum hubungan, yang mencerminkan kekuatan kecocokan relatif terhadap dokumen lain dalam tataan hasil yang sama. Tetapi skor tidak selalu konsisten dari satu kueri ke kueri berikutnya, sehingga saat Anda bekerja dengan kueri, Anda mungkin melihat perbedaan kecil dalam cara dokumen pencarian diurutkan. Ada beberapa penjelasan mengapa hal ini mungkin terjadi.
| Penyebab | Deskripsi |
|---|---|
| Skor identik | Jika beberapa dokumen memiliki skor yang sama, salah satu dari mereka mungkin muncul terlebih dahulu. |
| Volatilitas data | Konten indeks bervariasi saat Anda menambahkan, memodifikasi, atau menghapus dokumen. Frekuensi istilah akan berubah saat pembaruan indeks diproses dari waktu ke waktu, yang memengaruhi skor pencarian dokumen yang cocok. |
| Beberapa replika | Untuk layanan yang menggunakan beberapa replika, kueri dikeluarkan terhadap setiap replika secara paralel. Statistik indeks yang digunakan untuk menghitung skor pencarian dihitung berdasarkan per replika, dengan hasil digabungkan dan diurutkan dalam respons kueri. Replika sebagian besar cermin satu sama lain, tetapi statistik dapat berbeda karena perbedaan kecil dalam keadaan. Misalnya, satu replika mungkin telah menghapus dokumen yang berkontribusi pada statistiknya, yang digabungkan dari replika lain. Biasanya, perbedaan statistik per replika lebih terlihat dalam indeks yang lebih kecil. Bagian berikut ini menyediakan informasi selengkapnya tentang kondisi ini. |
Efek sharding pada hasil kueri
Pecahan adalah potongan indeks. Azure AI Search membahayakan indeks menjadi pecahan untuk membuat proses penambahan partisi lebih cepat (dengan memindahkan pecahan ke unit pencarian baru). Pada layanan pencarian, manajemen shard adalah detail implementasi dan tidak dapat dikonfigurasi, tetapi mengetahui bahwa indeks dipecah membantu memahami anomali sesekali dalam perilaku peringkat dan lengkapi otomatis:
Anomali peringkat: Skor pencarian dihitung pada tingkat pecahan terlebih dahulu, lalu dikumpulkan menjadi satu set hasil. Bergantung pada karakteristik konten pecahan, kecocokan dari satu pecahan mungkin memiliki peringkat lebih tinggi dibandingkan kecocokan di pecahan lain. Jika Anda melihat peringkat intuitif penghitung dalam hasil pencarian, kemungkinan besar karena efek sharding, terutama jika indeks kecil. Anda dapat menghindari anomali peringkat ini dengan memilih untuk menghitung skor secara global di seluruh indeks, tetapi hal itu akan dikenai penalti performa.
Anomali pelengkapan otomatis: Kueri pelengkapan otomatis, tempat kecocokan dibuat pada beberapa karakter pertama dari istilah yang dimasukkan sebagian, menerima parameter fuzzy yang memaafkan penyimpangan kecil dalam ejaan. Untuk pelengkapan otomatis, pencocokan fuzzy dibatasi untuk istilah dalam pecahan saat ini. Misalnya, jika pecahan berisi "Microsoft" dan istilah parsial "mikro" dimasukkan, mesin pencari akan cocok pada "Microsoft" dalam pecahan tersebut, tetapi tidak di pecahan lain yang menyimpan bagian indeks yang tersisa.
Diagram berikut menunjukkan hubungan antara replika, partisi, pecahan, dan unit pencarian. Diagram tersebut menunjukkan contoh bagaimana indeks tunggal tersebar di empat unit pencarian dalam layanan dengan dua replika dan dua partisi. Masing-masing dari empat unit pencarian hanya menyimpan setengah dari pecahan indeks. Unit pencarian di kolom kiri menyimpan paruh pertama pecahan, yang terdiri dari partisi pertama, sementara unit pencarian di kolom kanan menyimpan paruh kedua pecahan, yang terdiri dari partisi kedua. Karena ada dua replika, artinya ada dua salinan masing-masing pecahan indeks. Unit pencarian di baris atas menyimpan satu salinan, yang terdiri dari replika pertama, sementara unit pencarian di baris bawah menyimpan salinan lain, yang terdiri dari replika kedua.
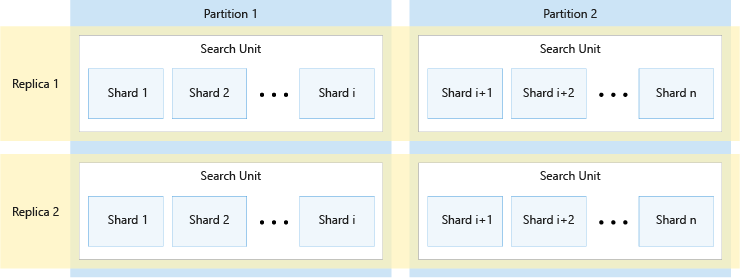
Diagram di atas hanya merupakan satu contoh. Banyak kombinasi partisi dan replika yang dapat dilakukan, hingga maksimum 36 total unit pencarian.
Catatan
Jumlah replika dan partisi dibagi secara merata menjadi 12 (khususnya, 1, 2, 3, 4, 6, 12). Azure AI Search telah membagi setiap indeks menjadi 12 pecahan sehingga dapat disebarkan dalam bagian yang sama di semua partisi. Misalnya, jika layanan memiliki tiga partisi dan Anda membuat indeks, setiap partisi akan berisi empat pecahan indeks. Bagaimana Azure AI Search memecah indeks adalah detail implementasi, dapat berubah dalam rilis mendatang. Meskipun jumlahnya adalah 12 hari ini, Anda seharusnya tidak mengharapkan jumlah itu selalu menjadi 12 di masa depan.
Statistik penilaian dan sesi lekat
Untuk skalabilitas, Azure AI Search mendistribusikan setiap indeks secara horizontal melalui proses sharding, yang berarti bahwa bagian indeks secara fisik terpisah.
Secara default, skor dokumen dihitung berdasarkan properti statistik data dalam pecahan. Pendekatan ini umumnya bukan masalah untuk korpus data yang besar, dan memberikan kinerja yang lebih baik daripada harus menghitung skor berdasarkan informasi di semua pecahan. Yang mengatakan, menggunakan optimasi kinerja ini dapat menyebabkan dua dokumen yang sangat mirip (atau bahkan dokumen yang identik) berakhir dengan skor relevansi yang berbeda jika mereka berakhir di pecahan yang berbeda.
Jika Anda lebih suka menghitung skor berdasarkan properti statistik di semua shard, Anda dapat melakukannya dengan menambahkan scoringStatistics=global sebagai parameter kueri (atau menambahkan "scoringStatistics": "global" sebagai parameter isi permintaan kueri).
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
Menggunakan scoringStatistics akan memastikan bahwa semua shard dalam replika yang sama memberikan hasil yang sama. Meskipun demikian, replika yang berbeda bisa sedikit berbeda satu sama lain karena selalu diperbarui dengan perubahan terbaru pada indeks Anda. Dalam beberapa skenario, Anda mungkin ingin pengguna mendapatkan hasil yang lebih konsisten selama "sesi kueri". Dalam skenario seperti itu, Anda dapat memberikan sessionId sebagai bagian dari kueri Anda. Hal ini sessionId adalah string unik yang Anda buat untuk merujuk ke sesi pengguna yang unik.
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
Selama hal yang sama sessionId digunakan, upaya terbaik dilakukan untuk menargetkan replika yang sama, meningkatkan konsistensi hasil yang akan dilihat pengguna Anda.
Catatan
Menggunakan kembali nilai sessionId yang sama berulang kali dapat mengganggu keseimbangan beban permintaan di seluruh replika dan berdampak buruk pada kinerja layanan pencarian. Nilai yang digunakan sebagai sessionId tidak dapat dimulai dengan karakter '_'.
Penyetelan relevansi
Di Azure AI Search, untuk pencarian kata kunci dan bagian teks kueri hibrid, Anda dapat mengonfigurasi parameter algoritma BM25 ditambah menyetel relevansi pencarian dan meningkatkan skor pencarian melalui mekanisme berikut.
| Pendekatan | implementasi | Deskripsi |
|---|---|---|
| Konfigurasi algoritma BM25 | Indeks pencarian | Konfigurasikan bagaimana panjang dokumen dan frekuensi istilah memengaruhi skor relevansi. |
| Profil Penilaian | Indeks pencarian | Berikan kriteria untuk meningkatkan skor pencarian kecocokan berdasarkan karakteristik konten. Misalnya, Anda dapat meningkatkan kecocokan berdasarkan potensi pendapatannya, mempromosikan item yang lebih baru, atau mungkin meningkatkan item yang telah terlalu lama dalam inventori. Profil penilaian adalah bagian dari definisi indeks, terdiri dari bidang, fungsi, dan parameter tertimbang. Anda dapat memperbarui indeks yang ada dengan perubahan profil penilaian, tanpa menimbulkan pembangunan ulang indeks. |
| Peringkat semantik | Permintaan kueri | Menerapkan pemahaman pembacaan mesin untuk hasil pencarian, mempromosikan hasil yang lebih relevan secara semantik ke bagian atas. |
| parameter featuresMode | Permintaan kueri | Parameter ini sebagian besar digunakan untuk membongkar skor berpangkat BM25, tetapi dapat digunakan untuk dalam kode yang menyediakan solusi penilaian kustom. |
parameter featuresMode (pratinjau)
Permintaan Dokumen Pencarian mendukung parameter featuresMode yang memberikan detail lebih lanjut tentang skor relevansi BM25 di tingkat bidang.
@searchScore Sedangkan dihitung untuk dokumen all-up (seberapa relevan dokumen ini dalam konteks kueri ini), featuresMode mengungkapkan informasi tentang bidang individual, seperti yang @search.features dinyatakan dalam struktur. Struktur berisi semua bidang yang digunakan dalam kueri (baik bidang tertentu melalui Bidangpencarian dalam kueri, atau semua bidang yang dikaitkan sebagai dapat dicari dalam indeks).
Untuk setiap bidang, @search.features berikan nilai berikut:
- Jumlah token unik yang ditemukan di lapangan
- Skor persamaan, atau ukuran seberapa mirip konten bidang, yaitu relatif terhadap istilah kueri
- Frekuensi istilah, atau berapa kali istilah kueri ditemukan pada bidang
Untuk kueri yang menargetkan bidang "deskripsi" dan "judul", respons yang menyertakan @search.features mungkin terlihat seperti ini:
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
Anda dapat mengkonsumsi titik data ini dalam solusi penilaian kustom atau menggunakan informasi untuk men-debug masalah relevansi pencarian.
Parameter featuresMode tidak didokumenkan di REST API, tetapi Anda dapat menggunakannya pada pratinjau panggilan REST API ke pencarian Dokumen Pencarian untuk teks (Kata Kunci) yang diberi peringkat BM25.
Jumlah hasil berpangkat dalam respons kueri teks lengkap
Secara default, jika Anda tidak menggunakan pagination, mesin pencari mengembalikan 50 kecocokan peringkat tertinggi teratas untuk pencarian teks lengkap. Anda dapat menggunakan top parameter untuk mengembalikan jumlah item yang lebih kecil atau lebih besar (hingga 1.000 dalam satu respons). Anda dapat menggunakan skip dan next untuk halaman hasil. Penomoran menentukan jumlah hasil pada setiap halaman logis dan mendukung navigasi konten. Untuk informasi selengkapnya, lihat Hasil pencarian bentuk.
Jika kueri teks lengkap Anda adalah bagian dari kueri hibrid, Anda bisa mengatur maxTextRecallSize untuk menambah atau mengurangi jumlah hasil dari sisi teks kueri.
Pencarian teks lengkap tunduk pada batas maksimum 1.000 kecocokan (lihat batas respons API). Setelah 1.000 kecocokan ditemukan, mesin pencari tidak lagi mencari lebih banyak.