Tips untuk performa yang lebih baik di Azure AI Search
Artikel ini adalah kumpulan tips dan praktik terbaik untuk meningkatkan performa kueri dan pengindeksan untuk pencarian kata kunci. Mengetahui faktor mana yang paling mungkin memengaruhi performa pencarian dapat membantu Anda menghindari inefisiensi dan memaksimalkan layanan pencarian Anda. Beberapa faktor utama meliputi:
- Komposisi indeks (skema dan ukuran)
- Desain kueri
- Kapasitas layanan (tingkat, dan jumlah replika dan partisi)
Catatan
Mencari strategi pengindeksan volume tinggi? Lihat Mengindeks himpunan data besar di Azure AI Search.
Ukuran indeks dan skema
Kueri berjalan lebih cepat pada indeks yang lebih kecil. Ini sebagian merupakan fungsi dari memiliki lebih sedikit bidang untuk dipindai, tetapi juga karena bagaimana sistem menyimpan konten untuk kueri di masa mendatang. Setelah kueri pertama, beberapa konten tetap dalam memori di mana dapat dicari secara lebih efisien. Karena ukuran indeks cenderung tumbuh dari waktu ke waktu, salah satu praktik terbaik adalah mengunjungi kembali komposisi indeks secara berkala, baik skema maupun dokumen, untuk mencari peluang pengurangan konten. Namun, jika indeks sudah berukuran tepat, satu-satunya kalibrasi lain yang dapat Anda buat adalah meningkatkan kapasitas: baik dengan menambahkan replika atau memperbaiki tingkat layanan. Bagian "Tip: Tingkatkan ke tingkat S2 Standar" membahas keputusan peningkatan skala versus peluasan skala.
Kompleksitas skema juga dapat berdampak buruk pada pengindeksan dan performa kueri. Atribusi bidang yang berlebihan menimbulkan keterbatasan dan persyaratan pemrosesan. Jenis kompleks membutuhkan waktu lebih lama untuk mengindeks dan membuat kueri. Beberapa bagian berikutnya mengeksplorasi setiap kondisi.
Tips: Selektif dalam atribusi lapangan
Kesalahan umum yang dilakukan administrator dan pengembang saat membuat indeks pencarian adalah memilih semua properti yang tersedia untuk bidang, dibandingkan hanya memilih properti yang diperlukan. Misalnya, jika suatu bidang tidak perlu dapat dicari teks lengkap, lewati bidang tersebut saat mengatur atribut yang dapat dicari.
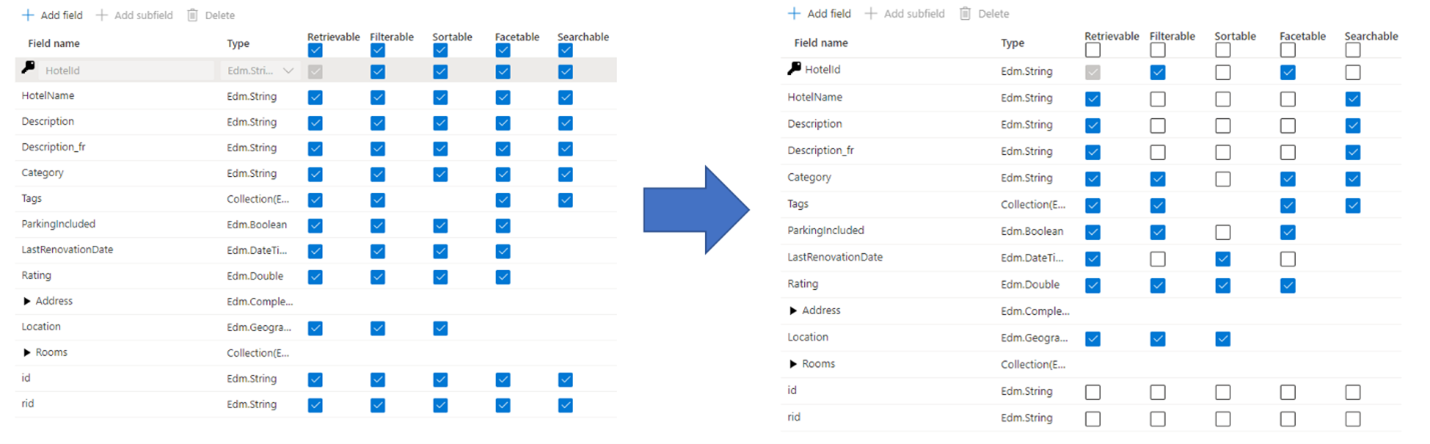
Dukungan untuk filter, faset, dan pengurutan dapat melipatgandakan persyaratan penyimpanan. Jika Anda menambahkan saran, persyaratan penyimpanan akan naik lebih banyak lagi. Untuk ilustrasi tentang dampak atribut pada penyimpanan, lihat Atribut dan ukuran indeks.
Dirangkum, konsekuensi atribusi berlebihan meliputi:
Degradasi performa pengindeksan karena beban kerja ekstra yang diperlukan untuk memproses konten di bidang tersebut, dan kemudian menyimpannya dalam indeks terbalik pencarian (atur atribut "dapat dicari" hanya pada bidang yang berisi konten yang dapat dicari).
Membuat permukaan yang lebih besar yang harus dicakup setiap kueri. Semua bidang yang ditandai sebagai dapat dicari dipindai dalam pencarian teks lengkap.
Meningkatkan biaya operasional karena penyimpanan ekstra. Pemfilteran dan pengurutan memerlukan ruang tambahan untuk menyimpan untai (karakter) asli (tidak dianalisis). Hindari membuat pengaturan dapat difilter atau dapat diurutkan pada bidang yang tidak memerlukannya.
Dalam banyak kasus, atribusi berlebih membatasi kemampuan bidang. Misalnya, jika bidang dapat difasetkan, dapat difilter, dan dapat dicari, Anda hanya dapat menyimpan 16 KB teks dalam suatu bidang, sedangkan bidang yang dapat dicari dapat menahan hingga 16 MB teks.
Catatan
Hanya atribusi yang tidak perlu yang harus dihindari. Filter dan faset seringkali penting untuk pengalaman pencarian, dan dalam kasus di mana filter digunakan, Anda seringkali perlu pengurutan sehingga Anda dapat memesan hasilnya (filter sendiri kembali dalam set yang tidak diurutkan).
Tips: Pertimbangkan alternatif untuk jenis yang kompleks
Jenis data kompleks berguna saat data memiliki struktur berlapis yang rumit, seperti elemen induk-anak yang ditemukan dalam dokumen JSON. Kelemahan dari jenis yang kompleks adalah persyaratan penyimpanan tambahan dan sumber daya tambahan yang diperlukan untuk mengindeks konten, dibandingkan dengan jenis data yang tidak kompleks.
Dalam beberapa kasus, Anda dapat menghindari tradeoff ini dengan memetakan struktur data yang kompleks ke jenis bidang yang lebih sederhana, seperti Koleksi. Atau, Anda dapat memilih untuk meratakan hierarki bidang ke bidang tingkat akar individual.

Desain kueri
Komposisi dan kompleksitas kueri adalah salah satu faktor terpenting untuk performa, dan pengoptimalan kueri dapat meningkatkan performa secara drastis. Saat mendesain kueri, pikirkan tentang poin berikut:
Jumlah bidang yang dapat dicari. Setiap bidang tambahan yang dapat dicari menghasilkan lebih banyak pekerjaan untuk layanan pencarian. Anda dapat membatasi bidang yang sedang dicari pada waktu kueri menggunakan parameter "searchFields". Sebaiknya tentukan hanya bidang yang Anda minati untuk meningkatkan performa.
Jumlah data yang dikembalikan. Mengambil konten dalam jumlah besar dapat membuat kueri lebih lambat. Saat menyusun kueri, kembalikan hanya bidang yang Anda perlukan untuk merender halaman hasil, lalu ambil bidang yang tersisa menggunakan Lookup API setelah pengguna memilih kecocokan.
Penggunaan pencarian istilah parsial. Pencarian istilah parsial, seperti pencarian awalan, pencarian fuzzy, dan pencarian ekspresi reguler, lebih mahal secara komputasi daripada pencarian kata kunci umum, karena memerlukan pemindaian indeks penuh untuk menghasilkan hasil.
Jumlah faset. Menambahkan faset ke kueri memerlukan agregasi untuk setiap kueri. Meminta "jumlah" yang lebih tinggi untuk suatu faset juga membutuhkan kerja ekstra oleh layanan. Secara umum, hanya tambahkan faset yang Anda rencanakan untuk dirender di aplikasi Anda dan hindari meminta jumlah faset yang tinggi kecuali diperlukan.
Nilai lompatan tinggi. Mengatur parameter
$skipke nilai yang tinggi (misalnya dalam ribuan) akan meningkatkan latensi pencarian karena mesin mengambil dan memberi peringkat pada volume dokumen yang lebih besar untuk setiap permintaan. Demi alasan performa, sebaiknya menghindari nilai$skipyang tinggi. Gunakan teknik lain, seperti pemfilteran, untuk mengambil dokumen dalam jumlah besar.Batasi bidang kardinalitas tinggi. Bidang kardinalitas tinggi mengacu pada bidang yang dapat difaset atau dapat difilter yang memiliki sejumlah besar nilai unik, dan akibatnya, mengkonsumsi sumber daya yang signifikan saat menghitung hasil. Misalnya, menetapkan ID Produk atau bidang Deskripsi sebagai facetable dan filterable akan dihitung sebagai kardinalitas tinggi karena sebagian besar nilai dari dokumen ke dokumen unik.
Tips: Menggunakan fungsi pencarian alih-alih membebani kriteria filter
Saat kueri menggunakan kriteria filter yang semakin kompleks, performa kueri pencarian akan menurun. Pertimbangkan contoh berikut yang menunjukkan penggunaan filter untuk memangkas hasil berdasarkan identitas pengguna:
$filter= userid eq 123 or userid eq 234 or userid eq 345 or userid eq 456 or userid eq 567
Dalam kasus ini, ekspresi filter digunakan untuk memeriksa apakah satu bidang di setiap dokumen sama dengan salah satu dari banyak nilai yang mungkin dari identitas pengguna. Anda kemungkinan besar menemukan pola ini dalam aplikasi yang menerapkan pemangkasan keamanan (memeriksa bidang yang berisi satu atau beberapa ID utama terhadap daftar ID utama yang mewakili pengguna yang mengeluarkan kueri).
Cara yang lebih efisien untuk menjalankan filter yang berisi sejumlah besar nilai adalah dengan menggunakan search.in fungsi, seperti yang ditunjukkan dalam contoh ini:
search.in(userid, '123,234,345,456,567', ',')
Tips: Menambahkan partisi untuk kueri individual yang lambat
Ketika performa kueri melambat secara umum, menambahkan lebih banyak replika sering memecahkan masalah ini. Tapi bagaimana jika masalahnya adalah satu kueri yang membutuhkan waktu terlalu lama untuk diselesaikan? Dalam skenario ini, menambahkan replika tidak akan membantu, tetapi mungkin lebih banyak partisi. Partisi membagi data di seluruh sumber daya komputasi ekstra. Dua partisi membagi data menjadi dua, partisi ketiga membaginya menjadi sepertiga, dan seterusnya.
Salah satu efek samping positif dari penambahan partisi adalah bahwa kueri yang lebih lambat kadang-kadang mempunyai performa lebih cepat akibat komputasi paralel. Kami telah mencatat paralelisasi pada kueri selektivitas rendah, seperti kueri yang cocok dengan banyak dokumen, atau faset yang menyediakan hitungan atas sejumlah besar dokumen. Karena komputasi yang signifikan diperlukan untuk menilai relevansi dokumen, atau untuk menghitung jumlah dokumen, menambahkan partisi tambahan membantu kueri selesai lebih cepat.
Untuk menambahkan partisi, gunakan portal Microsoft Azure, PowerShell, Azure CLI, atau SDK manajemen.
Kapasitas layanan
Layanan terbebani secara berlebih ketika kueri terlalu lama atau ketika layanan mulai menghilangkan permintaan. Jika ini terjadi, Anda dapat mengatasi masalah dengan meningkatkan layanan atau dengan menambahkan kapasitas.
Tingkat layanan pencarian Anda dan jumlah replika/partisi juga berdampak besar pada performa. Setiap tingkat yang semakin tinggi memberikan CPU yang lebih cepat dan lebih banyak memori, yang keduanya memiliki dampak positif pada performa.
Tips: Membuat layanan pencarian kapasitas tinggi baru
Layanan dasar dan standar yang dibuat di wilayah yang didukung setelah 3 April 2024 memiliki lebih banyak penyimpanan per partisi daripada layanan yang lebih lama. Sebelum meningkatkan ke tingkat yang lebih tinggi dan tarif yang dapat ditagih yang lebih tinggi, kunjungi kembali batas layanan tingkat untuk melihat apakah tingkat yang sama pada layanan yang lebih baru memberi Anda penyimpanan yang diperlukan.
Tips: Tingkatkan ke tingkat S2 Standar
Tingkat pencarian S1 Standar seringkali merupakan tempat pelanggan memulai. Pola umum untuk layanan S1 adalah bahwa indeks tumbuh dari waktu ke waktu, yang membutuhkan lebih banyak partisi. Lebih banyak partisi menyebabkan waktu respons yang lebih lambat, sehingga lebih banyak replika ditambahkan untuk menangani beban kueri. Seperti yang dapat Anda bayangkan, biaya menjalankan layanan S1 sekarang telah berkembang ke tingkat di luar konfigurasi awal.
Pada titik ini, pertanyaan penting untuk ditanyakan adalah apakah akan bermanfaat untuk pindah ke tingkat yang lebih tinggi, dibandingkan dengan meningkatkan jumlah partisi atau replika layanan saat ini secara progresif.
Pertimbangkan topologi berikut sebagai contoh layanan yang mengalami peningkatan kapasitas:
- Tingkat S1 standar
- Ukuran Indeks: 190 GB
- Jumlah Partisi: 8 (pada S1, ukuran partisi adalah 25 GB per partisi)
- Jumlah replika: 2
- Total Unit Pencarian: 16 (8 partisi x 2 replika)
- Harga Eceran Hipotetis: ~$4.000 USD / bulan (asumsikan 250 USD x 16 unit pencarian)
Misalkan administrator layanan masih melihat tingkat latensi yang lebih tinggi dan sedang mempertimbangkan untuk menambahkan replika lain. Ini akan mengubah jumlah replika dari 2 menjadi 3 dan akibatnya mengubah jumlah Unit Pencarian menjadi 24 dan harga yang dihasilkan $6.000 USD/bulan.
Namun, jika administrator memilih untuk pindah ke tingkat S2 Standar, topologi akan terlihat seperti:
- Tingkat S2 Standar
- Ukuran Indeks: 190 GB
- Jumlah Partisi: 2 (pada S2, ukuran partisi adalah 100 GB per partisi)
- Jumlah replika: 2
- Total Unit Pencarian: 4 (2 partisi x 2 replika)
- Harga Eceran Hipotetis: ~$4.000 USD / bulan (1.000 USD x 4 unit pencarian)
Seperti yang digambarkan oleh skenario hipotetis ini, Anda dapat memiliki konfigurasi pada tingkat yang lebih rendah yang menghasilkan biaya serupa dengan jika Anda memilih tingkat yang lebih tinggi sejak awal. Namun, tingkat yang lebih tinggi dilengkapi dengan penyimpanan premium, yang membuat pengindeksan lebih cepat. Tingkat yang lebih tinggi juga memiliki kekuatan komputasi yang jauh lebih banyak, serta memori ekstra. Dengan biaya yang sama, Anda bisa memiliki infrastruktur yang lebih kuat yang mendukung indeks yang sama.
Manfaat penting dari memori tambahan adalah bahwa lebih banyak indeks dapat disimpan di cache, menghasilkan latensi pencarian yang lebih rendah, dan jumlah kueri yang lebih besar per detik. Dengan kekuatan ekstra ini, administrator mungkin bahkan tidak perlu meningkatkan jumlah replika dan berpotensi membayar lebih sedikit daripada dengan tetap menggunakan layanan S1.
Tips: Pertimbangkan alternatif untuk kueri ekspresi reguler
Kueri atau regex ekspresi reguler bisa sangat mahal. Meskipun dapat sangat berguna untuk pencarian tingkat lanjut, eksekusi dapat membutuhkan banyak daya pemrosesan, terutama jika ekspresi reguler rumit atau jika Anda mencari melalui sejumlah besar data. Semua faktor ini berkontribusi pada latensi pencarian yang tinggi. Sebagai mitigasi, cobalah untuk menyederhanakan ekspresi reguler atau memecah kueri kompleks menjadi kueri yang lebih kecil dan lebih mudah dikelola.
Langkah berikutnya
Tinjau artikel lain ini yang terkait dengan performa layanan: