Memperkirakan dan mengelola kapasitas layanan pencarian
Di Azure AI Search, kapasitas didasarkan pada replika dan partisi yang dapat diskalakan ke beban kerja Anda. Replika adalah salinan dari mesin cari. Partisi adalah unit penyimpanan. Setiap layanan pencarian baru dimulai dengan satu masing-masing, tetapi Anda dapat menambahkan atau menghapus replika dan partisi secara independen untuk mengakomodasi beban kerja yang berfluktuasi. Menambahkan kapasitas meningkatkan biaya menjalankan layanan pencarian.
Karakteristik fisik replika dan partisi, seperti kecepatan pemrosesan dan IO disk, bervariasi menurut tingkat layanan. Pada layanan pencarian standar, replika dan partisi lebih cepat dan lebih besar dari yang ada di layanan dasar.
Mengubah kapasitas tidak seketika. Dibutuhkan waktu hingga satu jam untuk mengaktifkan atau menonaktifkan partisi, terutama pada layanan dengan jumlah data yang besar.
Saat menskalakan layanan pencarian, Anda dapat memilih dari alat dan pendekatan berikut:
Catatan
Partisi kapasitas yang lebih tinggi tersedia pada tingkat penagihan yang sama pada layanan yang lebih baru yang dibuat setelah April dan Mei 2024. Untuk informasi selengkapnya, lihat Batas layanan untuk peningkatan ukuran partisi.
Konsep: unit pencarian, replika, partisi
Kapasitas dinyatakan dalam unit pencarian yang dapat dialokasikan dalam kombinasi partisi dan replika.
| Konsep | Definisi |
|---|---|
| Unit pencarian | Kenaikan tunggal dari total kapasitas yang tersedia (36 unit). Ini juga merupakan unit penagihan untuk layanan Pencarian Azure AI. Diperlukan minimal satu unit untuk menjalankan layanan. |
| Replika | Instans layanan pencarian digunakan terutama untuk menyeimbangkan beban operasi kueri. Setiap replika menghosting satu salinan indeks. Jika Anda mengalokasikan tiga replika, Anda memiliki tiga salinan indeks yang tersedia untuk melayani permintaan kueri. |
| Partisi | Penyimpanan fisik dan I/O untuk operasi baca/tulis (misalnya, saat membangun kembali atau menyegarkan indeks). Setiap partisi memiliki potongan indeks total. Jika Anda mengalokasikan tiga partisi, indeks Anda akan dibagi menjadi sepertiga. |
Tinjau tabel partisi dan replika untuk kemungkinan kombinasi yang tetap berada di bawah batas 36 unit.
Waktu untuk menambahkan kapasitas
Awalnya, layanan mendapat alokasi tingkat sumber daya minimal yang terdiri dari satu partisi dan satu replika. Tingkat yang Anda pilih menentukan ukuran dan kecepatan partisi, dan setiap tingkat dioptimalkan di sekitar serangkaian karakteristik yang sesuai dengan berbagai skenario. Jika memilih tingkat kelas atas, Anda mungkin memerlukan lebih sedikit partisi daripada jika Anda menggunakan S1. Salah satu pertanyaan yang perlu Anda jawab melalui pengujian mandiri adalah apakah partisi yang lebih besar dan lebih mahal menghasilkan performa yang lebih baik dibandingkan dua partisi yang lebih murah pada layanan yang diprovisikan di tingkat yang lebih rendah.
Satu layanan harus memiliki sumber daya yang memadai untuk menangani semua beban kerja (pengindeksan dan kueri). Tidak ada beban kerja yang berjalan di latar belakang. Anda dapat menjadwalkan pengindeksan untuk waktu ketika permintaan kueri secara alami lebih jarang, tetapi layanan tidak akan memprioritaskan satu tugas ke tugas lain. Selain itu, sejumlah redundansi akan memuluskan performa kueri ketika layanan atau simpul diperbarui secara internal.
Beberapa pedoman untuk menentukan apakah akan menambah kapasitas meliputi:
- Memenuhi kriteria ketersediaan tinggi untuk perjanjian tingkat layanan
- Frekuensi kesalahan HTTP 503 meningkat
- Volume kueri besar diharapkan
Sebagai aturan umum, aplikasi pencarian cenderung membutuhkan lebih banyak replika daripada partisi, terutama ketika operasi layanan bias terhadap beban kerja kueri. Setiap replika adalah salinan indeks Anda, yang memungkinkan layanan menyeimbangkan beban permintaan terhadap beberapa salinan. Semua penyeimbangan beban dan replikasi indeks dikelola oleh Azure AI Search dan Anda dapat mengubah jumlah replika yang dialokasikan untuk layanan Anda kapan saja. Anda dapat mengalokasikan hingga 12 replika dalam layanan pencarian Standar dan 3 replika dalam layanan pencarian Dasar. Alokasi replika dapat dilakukan baik dari portal Azure atau salah satu opsi terprogram.
Partisi tambahan sangat membantu untuk beban kerja pengindeksan intensif. Partisi tambahan menyebarkan operasi baca/tulis di sejumlah besar sumber daya komputasi.
Terakhir, indeks yang lebih besar membutuhkan waktu lebih lama untuk kueri. Dengan demikian, Anda mungkin menemukan bahwa setiap peningkatan partisi inkremental membutuhkan peningkatan replika yang lebih kecil tetapi proporsional. Kompleksitas kueri dan volume kueri Anda akan memperhitungkan seberapa cepat eksekusi kueri diselesaikan.
Catatan
Menambahkan lebih banyak replika atau partisi akan meningkatkan biaya operasi layanan, dan dapat memunculkan sedikit variasi terkait bagaimana hasil dipesan. Pastikan untuk memeriksa kalkulator harga untuk memahami implikasi penagihan untuk menambahkan lebih banyak simpul. Bagan di bawah dapat membantu Anda mereferensikan silang jumlah unit pencarian yang diperlukan untuk konfigurasi tertentu. Untuk informasi selengkapnya tentang bagaimana replika tambahan memengaruhi pemrosesan kueri, lihat Hasil pemesanan.
Cara mengubah kapasitas
Untuk menambah atau mengurangi kapasitas layanan pencarian Anda, tambahkan atau hapus partisi dan replika.
Masuk ke portal Azure lalu pilih layanan pencarian.
Di bagian Pengaturan, buka halaman Skala untuk memodifikasi replika dan partisi.
Cuplikan layar berikut menunjukkan layanan Standar yang disediakan dengan satu replika dan partisi. Rumus di bagian bawah menunjukkan berapa banyak unit pencarian yang digunakan (1). Jika harga satuan adalah $100 (bukan harga riil), biaya bulanan untuk menjalankan layanan ini rata-rata akan menjadi $100.
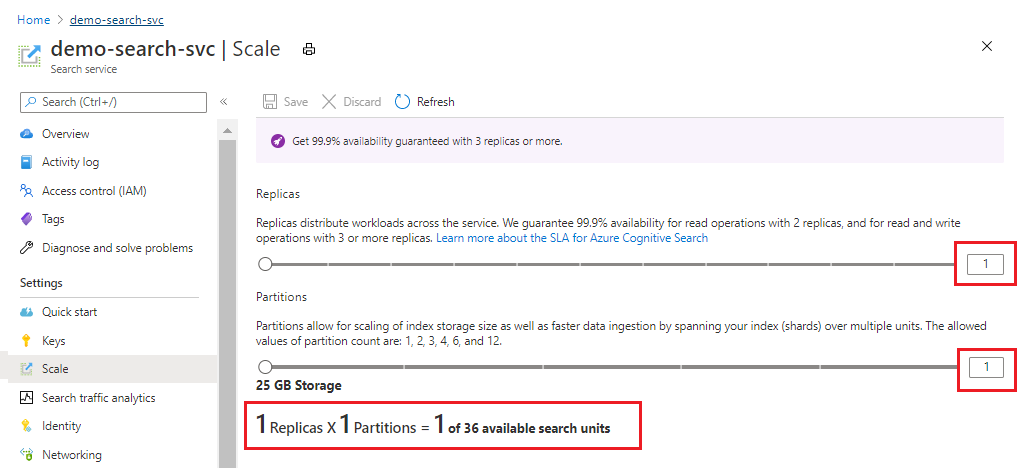
Gunakan penggeser untuk menambah atau mengurangi jumlah partisi. Pilih Simpan.
Contoh ini menambahkan replika dan partisi kedua. Perhatikan jumlah unit pencarian; sekarang menjadi empat karena rumus penagihan adalah replika dikalikan dengan partisi (2 x 2). Menggandakan kapasitas lebih dari itu akan menggandakan biaya operasi layanan. Jika biaya unit pencarian adalah $100, tagihan bulanan baru kini akan menjadi $400.
Untuk biaya per unit saat ini dari setiap tingkatan, kunjungi halaman Harga.
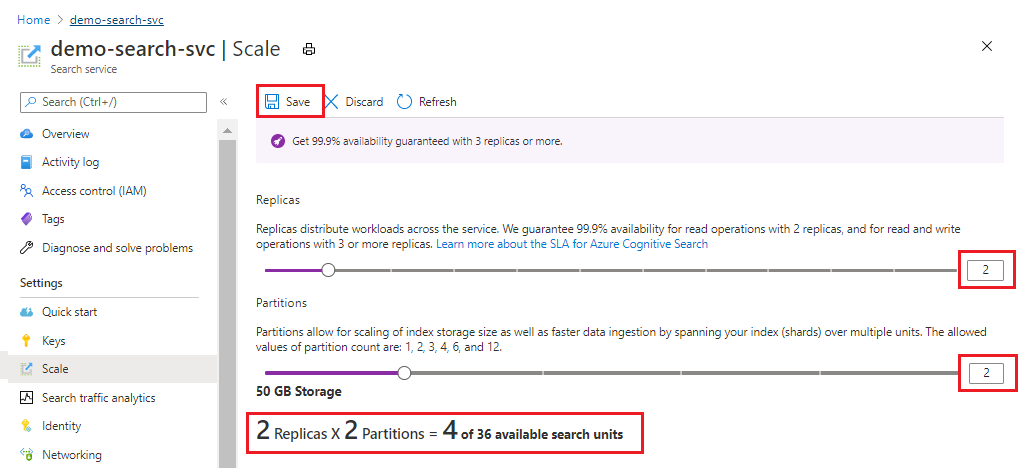
Setelah menyimpan, Anda dapat memeriksa pemberitahuan untuk memastikan bahwa tindakan berhasil.
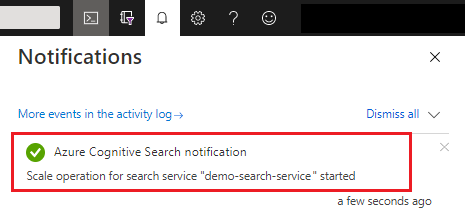
Perubahan kapasitas dapat berlangsung dari 15 menit hingga beberapa jam untuk diselesaikan. Anda tidak dapat membatalkan setelah proses dimulai dan tidak ada pemantauan real time untuk penyesuaian replika dan partisi. Namun, pesan berikut tetap terlihat saat perubahan sedang berlangsung.

Catatan
Setelah diprovisikan, layanan tidak dapat ditingkatkan ke tingkat yang lebih tinggi. Anda harus membuat layanan pencarian di tingkat baru dan memuat ulang indeks. Lihat Membuat layanan Pencarian Azure AI di portal untuk bantuan terkait provisi layanan.
Bagaimana permintaan skala ditangani
Setelah menerima permintaan skala, layanan pencarian:
- Memeriksa apakah permintaan itu valid.
- Mulai mencadangkan data dan informasi sistem.
- Memeriksa apakah layanan sudah dalam status penyediaan (sedang menambahkan atau menghilangkan replika atau partisi).
- Mulai proses penyediaan.
Penskalaan layanan dapat memakan waktu hanya 15 menit atau lebih dari satu jam, tergantung pada ukuran layanan dan cakupan permintaan. Pencadangan dapat memakan waktu beberapa menit, tergantung pada jumlah data dan jumlah partisi dan replika.
Langkah-langkah di atas tidak sepenuhnya berturut-turut. Misalnya, sistem mulai menyediakan ketika dapat dengan aman melakukannya, yang bisa saat cadangan mereda.
Kesalahan selama penskalaan
Pesan kesalahan "Operasi pembaruan layanan saat ini tidak diizinkan karena kami memproses permintaan sebelumnya" disebabkan oleh mengulangi permintaan untuk menurunkan atau meningkatkan skala ketika layanan sudah memproses permintaan sebelumnya.
Atasi kesalahan ini dengan memeriksa status layanan untuk memverifikasi status penyediaan:
- Gunakan REST API Manajemen, Azure PowerShell, atau Azure CLI untuk mendapatkan status layanan.
- Panggil Get Service (REST) atau setara untuk PowerShell atau CLI.
- Cek respons untuk "provisioningState": "penyediaan"
Jika statusnya adalah "Provisi", tunggu hingga permintaan selesai. Status harus "Berhasil" atau "Gagal" sebelum permintaan lain dicoba. Tidak ada status untuk pencadangan. Pencadangan adalah operasi internal dan tidak menjadi faktor dalam gangguan pada proses skala.
Jika layanan pencarian Anda tampaknya terhenti dalam status provisi, periksa indeks yatim piatu yang tidak dapat digunakan, dengan volume kueri nol dan tidak ada pembaruan indeks. Indeks yang tidak dapat digunakan dapat memblokir perubahan pada kapasitas layanan. Secara khusus, cari indeks yang dienkripsi CMK, yang kuncinya tidak lagi valid. Anda harus menghapus indeks atau memulihkan kunci untuk membuat indeks kembali online dan membuka blokir operasi skala Anda.
Kombinasi partisi dan replika
Bagan berikut berlaku untuk tingkat Standar dan yang lebih tinggi. Ini menunjukkan semua kemungkinan kombinasi partisi dan replika, tunduk pada maksimum 36 unit pencarian per layanan.
| 1 partisi | 2 partisi | 3 partisi | 4 partisi | 6 partisi | 12 partisi | |
|---|---|---|---|---|---|---|
| 1 replika | 1 SU | 2 SU | 3 SU | 4 SU | 6 SU | 12 SU |
| 2 replika | 2 SU | 4 SU | 6 SU | 8 SU | 12 SU | 24 SU |
| 3 replika | 3 SU | 6 SU | 9 SU | 12 SU | 18 SU | 36 SU |
| 4 replika | 4 SU | 8 SU | 12 SU | 16 SU | 24 SU | T/A |
| 5 replika | 5 SU | 10 SU | 15 SU | 20 SU | 30 SU | T/A |
| 6 replika | 6 SU | 12 SU | 18 SU | 24 SU | 36 SU | T/A |
| 12 replika | 12 SU | 24 SU | 36 SU | T/A | T/A | T/A |
Layanan pencarian dasar memiliki jumlah unit pencarian yang lebih rendah.
Pada layanan pencarian yang dibuat sebelum 3 April 2024, layanan pencarian dasar dapat memiliki tepat satu partisi dan hingga tiga replika, untuk batas maksimum tiga SU. Satu-satunya sumber daya yang dapat disesuaikan adalah replika.
Pada layanan pencarian yang dibuat setelah 3 April 2024 di wilayah yang didukung, layanan dasar dapat memiliki hingga tiga partisi dan tiga replika. Batas SU maksimum adalah sembilan untuk mendukung pelengkap penuh partisi dan replika.
Untuk layanan pencarian pada tingkat yang dapat ditagih, terlepas dari tanggal pembuatan, Anda memerlukan minimal dua replika untuk ketersediaan tinggi pada kueri.
Untuk tarif penagihan per tingkat dan mata uang, lihat halaman harga Azure AI Search.
Memperkirakan kapasitas menggunakan tingkat yang dapat ditagih
Kebutuhan penyimpanan ditentukan oleh ukuran indeks yang ingin Anda bangun. Tidak ada heuristik padat atau umum yang membantu dengan perkiraan. Satu-satunya cara untuk menentukan ukuran indeks adalah membangunnya. Ukurannya didasarkan pada tokenisasi dan penyematan, dan apakah Anda mengaktifkan pemberi saran, pemfilteran, dan pengurutan, atau dapat memanfaatkan kompresi vektor.
Sebaiknya perkirakan pada tingkat yang dapat ditagih, Dasar, atau di atasnya. Tingkat Gratis berjalan pada sumber daya fisik yang dibagikan oleh beberapa pelanggan dan tunduk pada faktor-faktor di luar kendali Anda. Hanya sumber daya khusus dari layanan pencarian yang dapat ditagih yang dapat mengakomodasi waktu pengambilan sampel dan pemrosesan yang lebih besar untuk perkiraan jumlah, ukuran, dan volume kueri indeks yang lebih realistis selama pengembangan.
Tinjau batas layanan di setiap tingkatan untuk menentukan apakah tingkatan yang lebih rendah dapat mendukung jumlah indeks yang Anda butuhkan. Pertimbangkan apakah Anda memerlukan beberapa salinan indeks untuk pengembangan, pengujian, dan produksi aktif.
Layanan pencarian tunduk pada batas objek (jumlah maksimum indeks, pengindeks, set keterampilan, dll.) dan batas penyimpanan. Batas mana pun yang tercapai terlebih dahulu adalah batas efektif.
Membuat layanan pada tingkat yang dapat ditagih. Tingkatan dioptimalkan untuk beban kerja tertentu. Misalnya, tingkat Storage Optimized memiliki batas 10 indeks karena dirancang untuk mendukung jumlah indeks yang sangat besar.
Mulai dari rendah, di Dasar atau S1, jika Anda tidak yakin tentang beban yang diproyeksikan.
Mulai dari tinggi, pada S2 atau bahkan S3, jika pengujian mencakup beban pengindeksan dan kueri berskala besar.
Mulai dengan Penyimpanan Dioptimalkan, di L1 atau L2, jika Anda mengindeks sejumlah besar data dan beban kueri relatif rendah, seperti halnya aplikasi bisnis internal.
Buat indeks awal untuk menentukan bagaimana data sumber diterjemahkan ke indeks. Ini adalah satu-satunya cara untuk memperkirakan ukuran indeks. Atribut pada definisi bidang memengaruhi persyaratan penyimpanan fisik:
Untuk pencarian kata kunci, menandai bidang sebagai dapat difilter dan dapat diurutkan meningkatkan ukuran indeks.
Untuk pencarian vektor, Anda dapat mengatur parameter untuk mengurangi penyimpanan.
Pantau penyimpanan, batas layanan, volume kueri, dan latensi di portal. Portal memperlihatkan kueri per detik, kueri yang dibatasi, dan latensi pencarian. Semua nilai tersebut dapat membantu Anda memutuskan apakah Anda memilih tingkat yang tepat.
Tambahkan replika untuk ketersediaan tinggi atau untuk mengurangi performa kueri yang lambat.
Tidak ada panduan tentang berapa banyak replika yang diperlukan untuk mengakomodasi beban kueri. Performa kueri bergantung pada kompleksitas kueri dan beban kerja yang bersaing. Meskipun menambahkan replika dengan jelas menghasilkan performa yang lebih baik, hasilnya tidak linier secara ketat: menambahkan tiga replika tidak menjamin throughput tiga kali lipat. Untuk panduan dalam memperkirakan QPS untuk solusi Anda, lihat Menganalisis performadan Memantau kueri.
Untuk indeks terbalik, ukuran, dan kompleksitas ditentukan oleh konten, tidak harus dengan jumlah data yang Anda umpankan ke dalamnya. Sumber data besar dengan redundansi tinggi dapat menghasilkan indeks yang lebih kecil daripada himpunan data yang lebih kecil yang berisi konten yang sangat bervariasi. Jadi, hampir tidak mungkin untuk menyimpulkan ukuran indeks berdasarkan ukuran himpunan data asli.
Persyaratan penyimpanan dapat meningkat jika Anda menyertakan data yang tidak akan pernah dicari. Idealnya, dokumen hanya berisi data yang Anda butuhkan untuk pengalaman pencarian.
Pertimbangan perjanjian tingkat layanan
Fitur tingkat gratis dan pratinjau tidak tercakup oleh perjanjian tingkat layanan (SLA). Untuk semua tingkatan yang dapat ditagih, SLA berlaku ketika Anda memprovisikan redundansi yang cukup untuk layanan Anda.
Dua atau beberapa replika memenuhi SLA kueri (baca).
Tiga replika atau lebih memenuhi SLA kueri dan pengindeksan (baca-tulis).
Jumlah partisi tidak memengaruhi SLA.
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk