Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Dalam solusi pencarian, string yang memiliki pola kompleks atau karakter khusus dapat menantang untuk dikerjakan karena penganalisis default menghapus atau salah menafsirkan bagian pola yang bermakna. Ini menghasilkan pengalaman pencarian yang buruk di mana pengguna tidak dapat menemukan informasi yang mereka harapkan. Nomor telepon adalah contoh klasik string yang sulit dianalisis. Mereka datang dalam berbagai format dan menyertakan karakter khusus yang diabaikan penganalisis default.
Dengan nomor telepon sebagai subjeknya, tutorial ini menunjukkan kepada Anda cara menyelesaikan masalah data berpola menggunakan penganalisis kustom. Pendekatan ini dapat digunakan apa adanya untuk nomor telepon atau disesuaikan untuk bidang dengan karakteristik yang sama (berpola dengan karakter khusus), seperti URL, email, kode pos, dan tanggal.
Dalam tutorial ini, Anda menggunakan klien REST dan REST API Azure AI Search untuk:
- Memahami masalahnya
- Mengembangkan penganalisis kustom awal untuk menangani nomor telepon
- Menguji penganalisis kustom
- Iterasi pada desain penganalisis kustom untuk meningkatkan hasil lebih lanjut
Prasyarat
Sebuah akun Azure dengan langganan aktif. Buat akun secara gratis.
Azure AI Pencarian Buat layanan atau temukan layanan yang sudah ada di langganan Anda saat ini. Untuk tutorial ini, Anda dapat menggunakan layanan gratis.
Visual Studio Code dengan klien REST.
Mengunduh file
Kode sumber untuk tutorial ini ada dalam file custom-analyzer.rest di repositori GitHub Azure-Samples/azure-search-rest-samples .
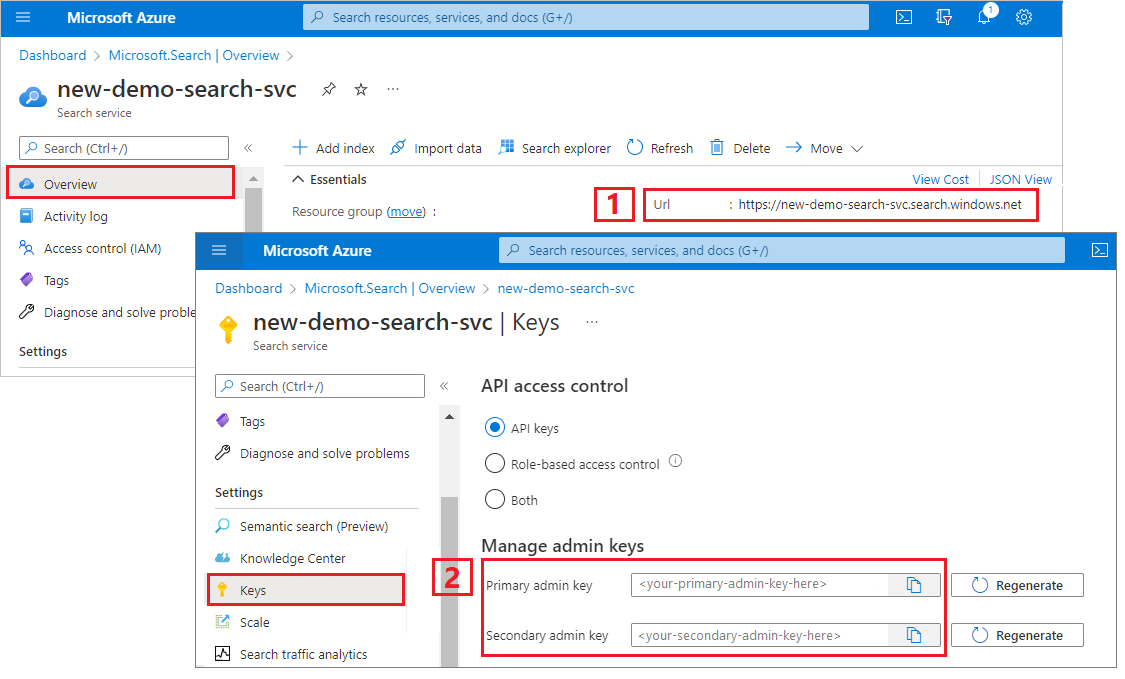
Menyalin kunci admin dan URL
Panggilan REST dalam tutorial ini memerlukan titik akhir layanan pencarian dan kunci API admin. Anda bisa mendapatkan nilai-nilai ini dari portal Azure.
Masuk ke portal Microsoft Azure, buka halaman Gambaran Umum , dan salin URL. Contoh titik akhir mungkin terlihat seperti
https://mydemo.search.windows.net.Di bawah Kunci Pengaturan>, salin kunci admin. Kunci admin digunakan untuk menambahkan, memodifikasi, dan menghapus objek. Ada dua kunci admin yang dapat dipertukarkan. Salin salah satu.
Kunci API yang valid menetapkan kepercayaan, berdasarkan per permintaan, antara aplikasi yang mengirim permintaan dan layanan pencarian yang menanganinya.
Membuat indeks awal
Buka file teks baru di Visual Studio Code.
Atur variabel ke titik akhir pencarian dan kunci API yang Anda kumpulkan di bagian sebelumnya.
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERESimpan file dengan
.restekstensi file.Tempelkan contoh berikut untuk membuat indeks kecil yang disebut
phone-numbers-indexdengan dua bidang:iddanphone_number. Anda belum menentukan penganalisis, sehingga penganalisisstandard.lucenedigunakan secara default.### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }Pilih Kirim Permintaan. Anda harus memiliki
HTTP/1.1 201 Createdrespons, dan isi respons harus menyertakan representasi JSON dari skema indeks.Muat data ke dalam indeks, menggunakan dokumen yang berisi berbagai format nomor telepon. Ini adalah data pengujian Anda.
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }Coba pertanyaan yang mirip dengan apa yang mungkin diketik pengguna. Misalnya, pengguna mungkin mencari
(425) 555-0100dalam sejumlah format dan masih mengharapkan hasil dikembalikan. Mulailah dengan mencari(425) 555-0100.### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=(425) 555-0100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}Kueri mengembalikan tiga dari empat hasil yang diharapkan tetapi juga mengembalikan dua hasil yang tidak terduga.
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }Coba lagi tanpa pemformatan apa pun:
4255550100.### Search for a phone number GET {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2024-07-01&search=4255550100 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}}Kueri ini bahkan lebih buruk karena hanya mengembalikan satu dari empat kecocokan yang benar.
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
Jika menurut Anda hasil ini membingungkan, Anda tidak sendirian. Bagian berikutnya menjelaskan mengapa Anda mendapatkan hasil ini.
Tinjau cara kerja penganalisis
Untuk memahami hasil pencarian ini, Anda harus memahami apa yang dilakukan penganalisis. Dari sana, Anda dapat menguji penganalisis default menggunakan Analyze API, menyediakan fondasi untuk merancang penganalisis yang lebih memenuhi kebutuhan Anda.
Penganalisis adalah komponen mesin pencari teks lengkap yang bertanggung jawab untuk memproses teks dalam string kueri dan dokumen terindeks. Analis yang berbeda memanipulasi teks dengan cara yang berbeda bergantung pada skenarionya. Untuk skenario ini, kita perlu membangun penganalisis yang disesuaikan untuk nomor telepon.
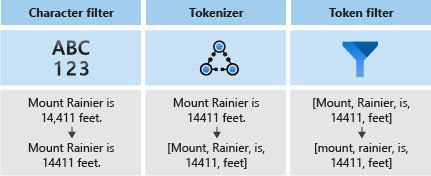
Penganalisis terdiri dari tiga komponen:
- Filter karakter yang menghapus atau mengganti karakter individual dari teks input.
- Tokenizer yang memecah teks input menjadi token, yang menjadi kunci dalam indeks pencarian.
- Filter token yang memanipulasi token yang dihasilkan oleh tokenizer.
Diagram berikut menunjukkan cara ketiga komponen ini bekerja sama untuk tokenisasi kalimat.
Token ini kemudian disimpan dalam indeks terbalik, yang memungkinkan pencarian teks lengkap yang cepat. Indeks terbalik memungkinkan pencarian teks lengkap dengan memetakan semua istilah unik yang diekstrak selama analisis leksikal ke dokumen tempatnya terjadi. Anda dapat melihat contoh dalam diagram berikut:

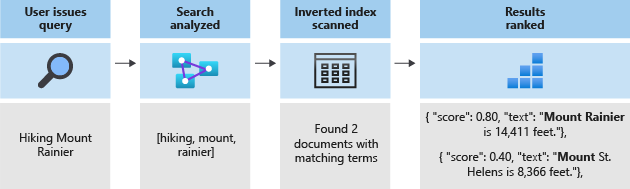
Semua pencarian berujung pada pencarian istilah yang disimpan dalam indeks terbalik. Saat pengguna mengajukan kueri
- Kueri tersebut diurai dan istilah kueri dianalisis.
- Indeks invert dipindai untuk mencari dokumen yang memiliki istilah yang sesuai.
- Algoritma penilaian memberi peringkat dokumen yang diambil.
Jika istilah kueri tidak cocok dengan istilah dalam indeks terbalik Anda, hasil tidak dikembalikan. Untuk mempelajari selengkapnya tentang cara kerja kueri, lihat Pencarian teks lengkap di Pencarian Azure AI.
Catatan
Kueri istilah parsial adalah pengecualian penting untuk aturan ini. Tidak seperti kueri istilah reguler, kueri ini (kueri prefiks, kueri wildcard, dan kueri regex) melewati proses analisis leksikal. Istilah parsial hanya ditulis dengan huruf kecil sebelum dicocokkan dengan istilah dalam indeks. Jika penganalisis tidak dikonfigurasi untuk mendukung jenis kueri ini, Anda sering menerima hasil yang tidak terduga karena istilah yang cocok tidak ada dalam indeks.
Menguji penganalisis menggunakan Analyze API
Azure AI Search menyediakan Analyze API yang memungkinkan Anda menguji penganalisis untuk memahami cara mereka memproses teks.
Panggil Analyze API menggunakan permintaan berikut:
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
API mengembalikan token yang diekstrak dari teks, menggunakan penganalisis yang Anda tentukan. Penganalisis Lucene standar membagi nomor telepon menjadi tiga token terpisah.
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
Sebaliknya, nomor telepon 4255550100 yang diformat tanpa tanda baca ditokenisasi menjadi satu token.
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
Respons:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
Perlu diingat bahwa istilah kueri dan dokumen terindeks menjalani analisis. Berpikir kembali ke hasil pencarian dari langkah sebelumnya, Anda dapat mulai melihat mengapa hasil tersebut dikembalikan.
Dalam kueri pertama, nomor telepon tak terduga dikembalikan karena salah satu tokennya, 555, cocok dengan salah satu istilah yang Anda cari. Di kueri kedua, hanya satu angka yang dikembalikan karena satu-satunya rekaman yang memiliki token 4255550100 cocok.
Membuat penganalisis kustom
Sekarang setelah Anda memahami hasil yang Anda lihat, buat penganalisis kustom untuk meningkatkan logika tokenisasi.
Tujuannya adalah untuk memberikan pencarian intuitif terhadap nomor telepon terlepas dari format kueri atau string terindeks. Untuk mencapai hasil ini, tentukan filter karakter, tokenizer, dan filter token.
Filter karakter
Filter karakter memproses teks sebelum disalurkan ke tokenizer. Penggunaan umum filter karakter adalah memfilter elemen HTML dan mengganti karakter khusus.
Untuk nomor telepon, Anda ingin menghapus spasi kosong dan karakter khusus karena tidak semua format nomor telepon berisi karakter dan spasi khusus yang sama.
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
Filter menghapus -()+. dan spasi dari input.
| Masukan | Keluaran |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Tokenizer
Tokenizer membagi teks menjadi token dan membuang beberapa karakter, seperti tanda baca, dalam prosesnya. Dalam banyak kasus, tujuan tokenisasi adalah untuk membagi kalimat menjadi kata-kata individu.
Untuk skenario ini, gunakan tokenisasi kata kunci, keyword_v2, untuk mengambil nomor telepon dalam satu istilah. Ini bukan satu-satunya cara untuk menyelesaikan masalah ini, seperti yang dijelaskan di bagian Pendekatan alternatif .
Tokenizer kata kunci selalu menghasilkan teks yang sama dengan yang diberikan sebagai satu istilah.
| Masukan | Keluaran |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
Filter token
Filter token memodifikasi atau memfilter token yang dihasilkan oleh tokenizer. Salah satu penggunaan umum filter token adalah untuk mengubah semua karakter menjadi huruf kecil menggunakan filter token huruf kecil. Penggunaan umum lainnya adalah memfilter stopword, seperti the, and, atau is.
Meskipun Anda tidak perlu menggunakan salah satu filter tersebut untuk skenario ini, gunakan filter token nGram untuk memungkinkan pencarian parsial nomor telepon.
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
Filter nGram_v2 token membagi token menjadi n-gram dari ukuran tertentu berdasarkan parameter minGram dan maxGram.
Untuk penganalisis telepon, minGram diatur ke 3 karena itulah substring terpendek yang diharapkan pengguna untuk dicari.
maxGram diatur ke 20 untuk memastikan bahwa semua nomor telepon, termasuk ekstensi, masuk ke dalam satu n-gram.
Efek samping yang tidak menguntungkan dari n-gram adalah bahwa beberapa positif palsu dikembalikan. Anda memperbaikinya di langkah selanjutnya dengan membangun penganalisis terpisah untuk pencarian yang tidak menyertakan filter token n-gram.
| Masukan | Keluaran |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Penganalisis
Dengan filter karakter, tokenizer, dan filter token di tempat, Anda siap untuk menentukan penganalisis.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
Dari Analyze API, dengan input berikut, output dari penganalisis kustom adalah sebagai berikut:
| Masukan | Keluaran |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
Semua token dalam kolom output ada dalam indeks. Jika kueri Anda menyertakan salah satu istilah tersebut, nomor telepon akan dikembalikan.
Membangun kembali menggunakan penganalisis baru
Hapus indeks saat ini.
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2024-07-01 HTTP/1.1 api-key: {{apiKey}}Buat ulang indeks menggunakan penganalisis baru. Skema indeks ini menambahkan definisi penganalisis kustom dan penetapan penganalisis kustom pada bidang nomor telepon.
### Create a new index POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
Menguji penganalisis kustom
Setelah Anda membuat ulang indeks, uji penganalisis menggunakan permintaan berikut:
POST {{baseUrl}}/indexes/tutorial-first-analyzer/analyze?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
Anda sekarang akan melihat pengumpulan token yang dihasilkan dari nomor telepon.
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
Merevisi penganalisis kustom untuk menangani positif palsu
Setelah menggunakan penganalisis kustom untuk membuat kueri sampel terhadap indeks, Anda akan melihat bahwa recall telah meningkat dan semua nomor telepon yang cocok sekarang ditampilkan. Namun, filter token n-gram juga menyebabkan beberapa positif palsu dikembalikan. Ini adalah efek samping umum dari filter token n-gram.
Untuk mencegah positif palsu, buat penganalisis terpisah untuk kueri. Penganalisis ini identik dengan yang sebelumnya, kecuali bahwa menghilangkan custom_ngram_filter.
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
Dalam definisi indeks, tentukan indexAnalyzer dan searchAnalyzer.
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
Dengan perubahan ini, Anda sudah siap. Berikut adalah langkah Anda berikutnya:
Hapus indeks.
Buat ulang indeks setelah Anda menambahkan penganalisis kustom baru (
phone_analyzer-search) dan menetapkan penganalisis tersebut ke propertiphone-numberdari bidangsearchAnalyzer.Muat ulang data.
Coba lagi kueri untuk memverifikasi bahwa pencarian berfungsi seperti yang diharapkan. Jika Anda menggunakan file sampel, langkah ini akan membuat indeks ketiga bernama
phone-number-index-3.
Pendekatan alternatif
Penganalisis yang dijelaskan di bagian sebelumnya dirancang untuk memaksimalkan fleksibilitas untuk pencarian. Namun, itu melakukannya dengan menyimpan banyak istilah yang mungkin tidak penting dalam indeks.
Contoh berikut menunjukkan penganalisis alternatif yang lebih efisien dalam tokenisasi, tetapi memiliki kelemahan.
Mengingat input , 14255550100penganalisis tidak dapat secara logis memotong nomor telepon. Misalnya, kode negara tidak dapat dipisahkan, 1, dari kode area, 425. Perbedaan ini menyebabkan nomor telepon tidak dikembalikan jika pengguna tidak menyertakan kode negara dalam pencarian mereka.
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
Dalam contoh berikut, nomor telepon dibagi menjadi potongan yang biasanya Anda harapkan untuk dicari pengguna.
| Masukan | Keluaran |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
Tergantung pada kebutuhan Anda, ini mungkin pendekatan yang lebih efisien untuk masalah tersebut.
Poin-poin penting
Tutorial ini menunjukkan proses membangun dan menguji penganalisis kustom. Anda membuat indeks, data terindeks, lalu mengkueri terhadap indeks untuk melihat hasil pencarian apa yang ditampilkan. Dari sana, Anda menggunakan Analyze API untuk melihat proses analisis leksikal yang sedang berjalan.
Meskipun penganalisis yang ditentukan dalam tutorial ini menawarkan solusi mudah untuk mencari nomor telepon, proses yang sama ini dapat digunakan untuk membangun penganalisis kustom untuk skenario apa pun yang berbagi karakteristik serupa.
Membersihkan sumber daya
Saat Anda bekerja di langganan Anda sendiri, sebaiknya hapus sumber daya yang tidak lagi Anda butuhkan di akhir proyek. Sumber daya yang dibiarkan berjalan dapat merugikan Anda secara finansial. Anda dapat menghapus sumber daya satu per satu atau menghapus grup sumber daya untuk menghapus seluruh rangkaian sumber daya.
Anda dapat menemukan dan mengelola sumber daya di portal Azure, menggunakan tautan Semua sumber daya atau Grup sumber daya di panel navigasi kiri.
Langkah berikutnya
Sekarang setelah Anda tahu cara membuat penganalisis kustom, lihat semua filter, tokenizer, dan penganalisis yang berbeda yang tersedia untuk membangun pengalaman pencarian yang kaya: