Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pencarian teks lengkap adalah pendekatan dalam pengambilan informasi yang cocok pada teks biasa yang disimpan dalam indeks. Misalnya, mengingat string kueri "hotel di San Diego di pantai", mesin pencari mencari string yang ditokenisasi berdasarkan istilah-istilah tersebut. Untuk membuat pemindaian lebih efisien, string kueri menjalani analisis leksikal: huruf kecil semua istilah, menghapus kata berhenti seperti "the", dan mengurangi istilah ke bentuk akar primitif. Saat istilah yang cocok ditemukan, mesin pencari mengambil dokumen, memberi peringkat dalam urutan relevansi, dan mengembalikan hasil teratas.
Eksekusi kueri bisa kompleks. Artikel ini untuk pengembang yang membutuhkan pemahaman yang lebih mendalam tentang cara kerja pencarian teks lengkap di Azure AI Search. Untuk kueri teks, Azure AI Search dengan mulus memberikan hasil yang diharapkan dalam sebagian besar skenario, tetapi terkadang Anda mungkin mendapatkan hasil yang tampaknya "tidak aktif" entah bagaimana. Dalam situasi ini, memiliki latar belakang dalam empat tahap eksekusi kueri Lucene (penguraian kueri, analisis leksikal, pencocokan dokumen, penilaian) dapat membantu Anda mengidentifikasi perubahan khusus pada parameter kueri atau konfigurasi indeks yang menghasilkan hasil yang diinginkan.
Catatan
Azure AI Search menggunakan Apache Lucene untuk pencarian teks lengkap, tetapi integrasi Lucene tidak lengkap. Kami secara selektif mengekspos dan memperluas fungsionalitas Lucene untuk mengaktifkan skenario penting untuk Azure AI Search.
Diagram dan ringkasan arsitektur
Eksekusi kueri memiliki empat tahap:
- Penguraian kueri
- Analisis leksikal
- Pengambilan dokumen
- Penilaian
Kueri pencarian teks lengkap dimulai dengan mengurai teks kueri untuk mengekstrak istilah dan operator pencarian. Ada dua pengurai sehingga Anda dapat memilih antara kecepatan dan kompleksitas. Fase analisis berikutnya, di mana istilah kueri individual terkadang dipecah dan direkonstitusi menjadi formulir baru. Langkah ini membantu melemparkan jaring yang lebih luas atas apa yang dapat dianggap sebagai potensi kecocokan. Mesin pencari kemudian memindai indeks untuk menemukan dokumen dengan istilah dan skor yang cocok setiap kecocokan. Tataan hasil kemudian diurutkan berdasarkan skor relevansi yang ditetapkan untuk setiap dokumen yang cocok. Dokumen yang berada di bagian atas daftar peringkat dikembalikan ke aplikasi panggilan.
Diagram di bawah ini mengilustrasikan komponen yang digunakan untuk memproses permintaan pencarian.
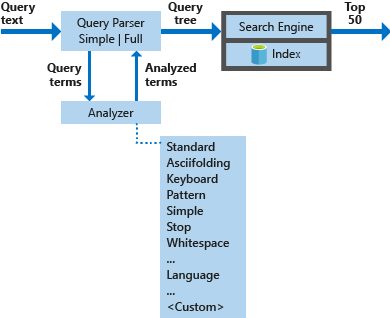
| Komponen utama | Deskripsi fungsi |
|---|---|
| Parser kueri | Pisahkan istilah kueri dari operator kueri dan buat struktur kueri (pohon kueri) untuk dikirim ke mesin cari. |
| Penganalisis | Lakukan analisis leksikal pada istilah kueri. Proses ini dapat melibatkan transformasi, penghapusan, atau perluasan istilah kueri. |
| Index | Struktur data yang efisien digunakan untuk menyimpan dan menyusun istilah yang dapat dicari yang diekstrak dari dokumen terindeks. |
| Mesin cari | Mengambil dan memberi skor dokumen yang cocok berdasarkan konten indeks terbalik. |
Anatomi permintaan pencarian
Permintaan pencarian adalah spesifikasi lengkap terkait hal yang harus ditampilkan dalam tataan hasil. Dalam bentuk paling sederhana, ini adalah kueri kosong tanpa kriteria apa pun. Contoh yang lebih realistis mencakup parameter, beberapa istilah kueri, mungkin dicakup ke bidang tertentu, dengan kemungkinan ekspresi filter dan aturan pengurutan.
Contoh berikut adalah permintaan pencarian yang mungkin Anda kirim ke Azure AI Search menggunakan REST API.
POST /indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
Untuk permintaan ini, mesin pencari melakukan operasi berikut:
Menemukan dokumen di mana harganya setidaknya $60 dan kurang dari $300.
Menjalankan kueri. Dalam contoh ini, kueri pencarian terdiri dari frasa dan istilah:
"Spacious, air-condition* +\"Ocean view\""(pengguna biasanya tidak memasukkan tanda baca, tetapi mencantumkannya dalam contoh akan memungkinkan kami menjelaskan cara penganalisis menanganinya).Untuk kueri ini, mesin pencari memindai deskripsi dan bidang judul yang ditentukan dalam "searchFields" untuk dokumen yang berisi
"Ocean view", dan juga pada istilah"spacious", atau pada istilah yang dimulai dengan awalan"air-condition". Parameter "searchMode" digunakan untuk mencocokkan istilah apa pun (default) atau semuanya, untuk kasus di mana istilah tidak diperlukan secara eksplisit (+).Memesan set hotel yang dihasilkan berdasarkan kedekatan dengan lokasi geografi tertentu, lalu mengembalikan hasilnya ke aplikasi panggilan.
Sebagian besar artikel ini adalah tentang pemrosesan kueri pencarian: "Spacious, air-condition* +\"Ocean view\"". Pemfilteran dan pemesanan di luar cakupan. Untuk informasi selengkapnya, lihat Dokumentasi referensi Search API.
Tahap 1: Penguraian kueri
Seperti yang diketahui, string kueri adalah baris pertama permintaan:
"search": "Spacious, air-condition* +\"Ocean view\"",
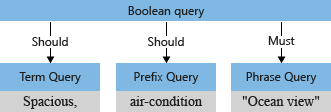
Parser kueri memisahkan operator (seperti * dan + dalam contoh) dari istilah pencarian, dan mendekonstruksi kueri pencarian menjadi subkueri dari jenis yang didukung:
- kueri istilah untuk istilah mandiri (seperti luas)
- kueri frasa untuk istilah yang dikutip (seperti pemandangan laut)
-
kueri awalan untuk istilah yang diikuti oleh
*operator prefiks (seperti ac)
Untuk daftar lengkap jenis kueri yang didukung, lihat Sintaks kueri Lucene
Operator yang terkait dengan subkueri menentukan apakah kueri "wajib" atau "harus" dipenuhi agar dokumen dianggap cocok. Misalnya, +"Ocean view" "harus" karena operator +.
Parser kueri merestrukturisasi subkueri ke dalam pohon kueri (struktur internal yang merepresentasikan kueri) yang diteruskan ke mesin cari. Pada tahap pertama penguraian kueri, pohon kueri terlihat seperti ini.
Parser yang didukung: Lucene Sederhana dan Lengkap
Azure AI Search mengekspos dua bahasa kueri yang berbeda, simple (default) dan full. Dengan mengatur parameter queryType pada permintaan pencarian, Anda memberi tahu parser kueri bahasa kueri mana yang Anda pilih sehingga tahu cara menafsirkan operator dan sintaks.
Bahasa kueri sederhana intuitif dan kuat, sering kali cocok untuk menafsirkan input pengguna apa adanya tanpa pemrosesan pihak klien. Ini mendukung operator kueri yang familier dari mesin cari web.
Bahasa kueri Lucene Lengkap, yang Anda dapatkan dengan mengatur
queryType=full, memperluas bahasa kueri Sederhana default dengan menambahkan dukungan untuk lebih banyak operator dan jenis kueri seperti kartubebas, fuzzy, regex, dan kueri yang dicakup bidang. Misalnya, regex yang dikirim dalam sintaks kueri Sederhana akan ditafsirkan sebagai string kueri dan bukan ekspresi. Contoh permintaan dalam artikel ini menggunakan bahasa kueri Lucene Lengkap.
Dampak searchMode pada parser
Parameter permintaan pencarian lain yang memengaruhi penguraian adalah parameter "searchMode". Parameter ini mengontrol operator default untuk kueri Boolean: setiap (default) atau semua.
Ketika "searchMode=any", yang merupakan default, pemisah ruang antara luas dan ac adalah OR (||), membuat teks kueri sampel setara dengan:
Spacious,||air-condition*+"Ocean view"
Operator eksplisit, seperti + dalam +"Ocean view", tidak ambigu dalam susunan kueri boolean (istilah harus cocok). Yang kurang jelas adalah bagaimana menafsirkan istilah yang tersisa: luas dan ac. Haruskah mesin cari menemukan kecocokan terkait pemandangan laut dan luas serta ac? Atau haruskah mesin cari menemukan pemandangan laut plus salah satu dari istilah yang tersisa?
Secara default ("searchMode=any"), mesin pencari mengasumsikan interpretasi yang lebih luas. Salah satu bidang harus dicocokkan, yang mencerminkan semantik "atau". Pohon kueri awal yang diilustrasikan sebelumnya, dengan dua operasi "harus", menunjukkan default.
Misalkan kita sekarang mengatur "searchMode=all". Dalam hal ini, spasi diinterpretasikan sebagai operasi "dan". Setiap istilah yang tersisa harus ada dalam dokumen untuk memenuhi syarat sebagai kecocokan. Kueri sampel yang dihasilkan akan ditafsirkan sebagai berikut:
+Spacious,+air-condition*+"Ocean view"
Pohon kueri yang dimodifikasi untuk kueri ini adalah sebagai berikut, di mana dokumen yang cocok adalah persimpangan ketiga subkueri:

Catatan
Memilih "searchMode=any" daripada "searchMode=all" adalah keputusan yang paling tepat dengan menjalankan kueri perwakilan. Pengguna yang cenderung menyertakan operator (umum saat mencari penyimpanan dokumen) mungkin menemukan hasil yang lebih intuitif jika "searchMode=all" menginformasikan konstruksi kueri boolean. Untuk informasi selengkapnya tentang interplay antara "searchMode" dan operator, lihat Sintaks kueri sederhana.
Tahap 2: Analisis leksikal
Penganalisis leksikal memproses kueri istilah dan kueri frasa setelah struktur kueri disusun. Penganalisis menerima input teks yang diberikan oleh parser, memproses teks, lalu mengirim kembali istilah yang diberi token untuk dimasukkan ke dalam pohon kueri.
Bentuk analisis leksikal yang paling umum adalah *analisis linguistik yang mengubah istilah kueri berdasarkan aturan khusus untuk bahasa tertentu:
- Mengurangi istilah kueri ke bentuk akar kata
- Menghapus kata-kata tidak penting (stopword, seperti "the" atau "and" dalam bahasa Inggris)
- Memecah kata komposit menjadi bagian komponen
- Mengganti huruf kecil kata berhuruf besar
Semua operasi ini cenderung menghapus perbedaan antara input teks yang disediakan oleh pengguna dan istilah yang tersimpan dalam indeks. Operasi semacam itu melampaui pemrosesan teks dan membutuhkan pengetahuan mendalam tentang bahasa itu sendiri. Untuk menambahkan lapisan kesadaran linguistik ini, Azure AI Search mendukung daftar panjang penganalisis bahasa dari Lucene dan Microsoft.
Catatan
Persyaratan analisis dapat berkisar dari minimal hingga rumit tergantung skenario Anda. Anda dapat mengontrol kompleksitas analisis leksikal dengan memilih salah satu penganalisis yang telah ditentukan atau dengan membuat penganalisis kustom Anda sendiri. Penganalisis dicakup ke bidang yang dapat dicari dan ditentukan sebagai bagian dari definisi bidang. Ini memungkinkan Anda memvariasikan analisis leksikal berdasarkan per bidang. Tidak ditentukan, penganalisis Lucene standar digunakan.
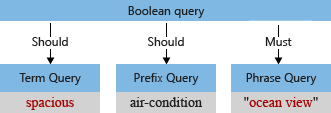
Dalam contoh kami, sebelum analisis, pohon kueri awal memiliki istilah "Luas," dengan huruf besar "S" dan koma yang ditafsirkan pengurai kueri sebagai bagian dari istilah kueri (koma tidak dianggap sebagai operator bahasa kueri).
Jika penganalisis default memproses istilah, penganalisis tersebut akan menggunakan huruf kecil pada "pemandangan laut" dan "luas", kemudian menghapus karakter koma. Pohon kueri yang dimodifikasi terlihat seperti:
Menguji perilaku penganalisis
Perilaku penganalisis dapat diuji menggunakan Analyze API. Berikan teks yang ingin Anda analisis untuk melihat istilah apa yang dihasilkan penganalisis yang diberikan. Misalnya, untuk mengetahui bagaimana penganalisis standar akan memproses teks "ac", Anda dapat mengeluarkan permintaan berikut:
{
"text": "air-condition",
"analyzer": "standard"
}
Penganalisis standar membagi teks input menjadi dua token berikut. menganotasinya dengan atribut seperti offset awal dan akhir (digunakan untuk penyorotan temuan) serta posisinya (digunakan untuk pencocokan frasa):
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
Pengecualian untuk analisis leksikal
Analisis leksikal hanya berlaku untuk jenis kueri yang memerlukan istilah lengkap – baik kueri istilah maupun kueri frasa. Ini tidak berlaku untuk jenis kueri dengan istilah yang tidak lengkap - kueri prefiks, kueri kartubebas, kueri regex - atau hingga kueri fuzzy. Jenis kueri tersebut, termasuk kueri prefiks dengan istilah air-condition* dalam contoh kami, ditambahkan langsung ke pohon kueri, dengan melewati tahap analisis. Satu-satunya transformasi yang dilakukan pada istilah kueri dari jenis tersebut adalah huruf kecil.
Tahap 3: Pengambilan dokumen
Pengambilan dokumen mengacu pada penemuan dokumen dengan istilah yang cocok dalam indeks. Tahap ini paling baik dipahami melalui contoh. Mari kita mulai dengan indeks hotel yang memiliki skema sederhana berikut:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Asumsikan lebih lanjut bahwa indeks ini berisi empat dokumen berikut:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
Bagaimana istilah diindeks
Untuk memahami pengambilan, hal ini membantu mengetahui beberapa dasar tentang pengindeksan. Unit penyimpanan adalah indeks terbalik, satu untuk setiap bidang yang dapat dicari. Dalam indeks terbalik adalah daftar semua istilah yang diurutkan dari semua dokumen. Setiap istilah dipetakan ke daftar dokumen tempat istilah tersebut muncul, seperti yang terlihat pada contoh di bawah ini.
Untuk menghasilkan istilah dalam indeks terbalik, mesin cari melakukan analisis leksikal atas konten dokumen, mirip dengan yang terjadi selama pemrosesan kueri:
- Input teks diteruskan ke penganalisis, diganti huruf kecil, tanda baca dihilangkan, dan sebagainya, bergantung pada konfigurasi penganalisis.
- Token adalah output analisis leksikal.
- Istilah ditambahkan ke indeks.
Umum, tetapi tidak diharuskan, untuk menggunakan penganalisis yang sama untuk operasi pencarian dan pengindeksan sehingga istilah kueri lebih terlihat seperti istilah di dalam indeks.
Catatan
Azure AI Search memungkinkan Anda menentukan penganalisis yang berbeda untuk pengindeksan dan pencarian melalui parameter bidang dan searchAnalyzer tambahanindexAnalyzer. Jika tidak ditentukan, penganalisis yang ditetapkan dengan properti analyzer digunakan untuk pengindeksan dan pencarian.
Indeks terbalik untuk dokumen contoh
Kembali ke contoh kami, untuk bidang judul, indeks terbalik terlihat seperti ini:
| Istilah | Daftar dokumen |
|---|---|
| atman | 1 |
| pantai | 2 |
| hotel | 1, 3 |
| laut | 4 |
| playa | 3 |
| resor | 3 |
| area | 4 |
Di bidang judul, hanya hotel yang muncul di dua dokumen: 1, 3.
Untuk bidang deskripsi, indeks-nya adalah sebagai berikut:
| Istilah | Daftar dokumen |
|---|---|
| air | 3 |
| dan | 4 |
| pantai | 1 |
| ber-ac | 3 |
| nyaman | 3 |
| jarak | 1 |
| pulau | 2 |
| kauaʻi | 2 |
| terletak | 2 |
| utara | 2 |
| laut | 1, 2, 3 |
| Tengah | 2 |
| aktif | 2 |
| tenang | 4 |
| kamar | 1, 3 |
| terpencil | 4 |
| pantai | 2 |
| luas | 1 |
| Sebuah | 1, 2 |
| ke | 1 |
| view | 1, 2, 3 |
| jalan kaki | 1 |
| dengan | 3 |
Mencocokkan istilah kueri dengan istilah terindeks
Mengingat indeks terbalik di atas, mari kita kembali ke kueri sampel dan melihat bagaimana dokumen yang cocok ditemukan untuk kueri contoh kami. Ingat bahwa pohon kueri akhir terlihat seperti ini:
Selama eksekusi kueri, kueri individual dijalankan pada bidang yang dapat dicari secara independen.
TermQuery, "luas", cocok dengan dokumen 1 (Hotel Atman).
PrefixQuery, "ac*",tidak cocok dengan dokumen apa pun.
Ini adalah perilaku yang terkadang membingungkan pengembang. Meskipun istilah ac ada dalam dokumen, istilah ini dibagi menjadi dua istilah oleh penganalisis default. Ingat bahwa kueri awalan, yang berisi istilah parsial, tidak dianalisis. Oleh karena itu, istilah dengan awalan "AC" dicari dalam indeks terbalik dan tidak ditemukan.
PhraseQuery, "pemandangan laut", mencari istilah "laut" dan "pemandangan" serta memeriksa kedekatan istilah dalam dokumen asli. Dokumen 1, 2, dan 3 cocok dengan kueri ini di bidang deskripsi. Dokumen pemberitahuan 4 memiliki istilah laut dalam judul tetapi tidak dianggap cocok, karena kita mencari frasa "pemandangan laut", bukan kata individu.
Catatan
Kueri pencarian dijalankan secara independen terhadap semua bidang yang dapat dicari di indeks Pencarian Azure AI kecuali Anda membatasi bidang yang diatur dengan searchFields parameter , seperti yang diilustrasikan dalam contoh permintaan pencarian. Dokumen yang cocok dengan salah satu bidang yang dipilih akan ditampilkan.
Secara keseluruhan, untuk kueri yang dimaksud, dokumen yang cocok adalah 1, 2, 3.
Tahap 4: Penskoran
Setiap dokumen dalam tataan hasil pencarian diberi skor relevansi. Fungsi dari skor relevansi adalah untuk memberi peringkat lebih tinggi pada dokumen yang paling menjawab pertanyaan pengguna seperti yang dinyatakan oleh kueri pencarian. Skor dihitung berdasarkan properti statistik istilah yang cocok. Inti dari rumus penskoran adalah TF/IDF (frekuensi istilah-frekuensi dokumen terbalik). Dalam kueri yang berisi istilah langka dan umum, TF/IDF mempromosikan hasil yang berisi istilah langka. Misalnya, dalam indeks hipotesis pada semua artikel Wikipedia, dari dokumen yang cocok dengan kueri presiden, dokumen yang cocok dengan presiden dianggap lebih relevan daripada dokumen yang cocok dengan.
Contoh penskoran
Ingat tiga dokumen yang cocok dengan kueri contoh kami:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
Dokumen 1 paling cocok dengan kueri karena istilah luas dan frasa pemandangan laut yang diperlukan muncul di bidang deskripsi. Dua dokumen berikutnya hanya cocok dengan frasa pemandangan laut. Mungkin mengejutkan bahwa skor relevansi untuk dokumen 2 dan 3 berbeda meskipun keduanya cocok dengan kueri dengan cara yang sama. Pasalnya, rumus penskoran memiliki komponen yang lebih banyak daripada TF/IDF. Dalam hal ini, dokumen 3 diberi skor yang sedikit lebih tinggi karena deskripsinya lebih pendek. Pelajari tentang Rumus Penskoran Praktis Lucene untuk mengetahui bagaimana panjang bidang dan faktor-faktor lain dapat memengaruhi skor relevansi.
Beberapa jenis kueri (kartu bebas, prefiks, regex) selalu menyumbang skor konstan untuk skor dokumen keseluruhan. Ini memungkinkan kecocokan yang ditemukan melalui perluasan kueri untuk disertakan dalam hasil, tetapi tanpa mempengaruhi peringkat.
Contoh menggambarkan mengapa ini penting. Pencarian kartubebas, termasuk pencarian prefiks, menurut definisinya ambigu karena inputnya adalah string parsial dengan potensi kecocokan pada sejumlah besar istilah yang berbeda (pertimbangkan input "tur*", dengan kecocokan yang ditemukan pada “tour”, “tourettes”, dan “tourmaline”). Mengingat sifat hasil ini, tidak ada cara untuk secara wajar menyimpulkan istilah mana yang lebih berharga daripada yang lain. Karena alasan ini, kami mengabaikan frekuensi istilah saat memberi skor hasil kueri jenis kartubebas, prefiks, dan regex. Dalam permintaan pencarian multibagian yang mencakup istilah parsial dan lengkap, hasil dari input parsial digabungkan dengan skor konstan untuk menghindari bias terhadap kemungkinan kecocokan yang tidak terduga.
Penyetelan relevansi
Ada dua cara untuk menyetel skor relevansi di Azure AI Search:
Profil penskoran mempromosikan dokumen dalam daftar peringkat hasil berdasarkan seperangkat aturan. Dalam contoh kami, kami dapat menganggap dokumen yang cocok di bidang judul lebih relevan daripada dokumen yang cocok di bidang deskripsi. Selain itu, jika indeks kami memiliki bidang harga untuk setiap hotel, kami dapat mempromosikan dokumen dengan harga lebih rendah. Pelajari selengkapnya tentang menambahkan profil penilaian ke indeks pencarian.
Peningkatan istilah (hanya tersedia pada sintaks kueri Lucene Lengkap) memberikan operator peningkatan
^yang dapat diterapkan ke bagian mana pun di pohon kueri. Dalam contoh kami, daripada mencari air-condition* di awalan, seseorang dapat mencari istilah air-condition atau prefiks yang tepat, tetapi dokumen yang cocok dengan istilah yang tepat diberi peringkat lebih tinggi dengan menerapkan peningkatan pada kueri istilah: air-condition^2||air-condition*. Pelajari selengkapnya tentang peningkatan istilah dalam kueri.
Memberi skor dalam indeks terdistribusi
Semua indeks di Azure AI Search secara otomatis dibagi menjadi beberapa pecahan, memungkinkan kami mendistribusikan indeks dengan cepat di antara beberapa simpul selama peningkatan atau penurunan skala layanan. Saat permintaan pencarian dikeluarkan, permintaan tersebut dikeluarkan untuk setiap shard secara independen. Hasil dari setiap shard kemudian digabungkan dan diurutkan menurut skor (jika tidak ada urutan lain yang ditentukan). Penting untuk diketahui bahwa fungsi penilaian membebani frekuensi istilah kueri terhadap frekuensi dokumen terbalik di semua dokumen dalam pecahan, tidak di semua pecahan!
Ini berarti skor relevansi dapat berbeda untuk dokumen yang identik jika berada dalam shard yang berbeda. Untungnya, perbedaan tersebut akan menghilang seiring bertambahnya jumlah dokumen dalam indeks karena distribusi istilah yang lebih merata. Bukanlah hal yang memungkinkan untuk mengasumsikan shard dokumen tertentu mana yang akan ditempatkan. Namun, dengan asumsi kunci dokumen tidak berubah, skor akan selalu ditetapkan ke shard yang sama.
Secara umum, skor dokumen bukan atribut terbaik untuk mengurutkan dokumen jika stabilitas pesanan penting. Misalnya, diberikan dua dokumen dengan skor yang identik, tidak ada jaminan bahwa dokumen muncul terlebih dahulu dalam eksekusi berikutnya dari kueri yang sama. Skor dokumen seharusnya hanya memberikan skor relevansi dokumen umum yang relatif terhadap dokumen lain dalam tataan hasil.
Kesimpulan
Keberhasilan mesin pencari komersial telah memunculkan harapan untuk pencarian teks lengkap melalui data privat. Untuk hampir semua jenis pengalaman pencarian, kini kita berharap mesin cari tersebut memahami maksud kita, meskipun terdapat salah eja atau kata yang tidak lengkap pada istilah. Kita bahkan mungkin mengharapkan kecocokan berdasarkan istilah atau sinonim yang hampir setara yang tidak pernah kita tentukan.
Dari segi teknis, pencarian teks lengkap sangatlah kompleks, karena memerlukan analisis kebahasaan yang rumit dan pendekatan sistematis terhadap pemrosesan dengan cara menyaring, memperbanyak, dan mengubah istilah kueri untuk menampilkan hasil yang relevan. Mengingat kompleksitas yang melekat, ada banyak faktor yang dapat memengaruhi hasil kueri. Karena alasan inilah, meluangkan waktu untuk memahami mekanisme pencarian teks lengkap menawarkan manfaat yang nyata saat mencoba memecahkan masalah hasil yang tak terduga.
Artikel ini menjelajahi pencarian teks lengkap dalam konteks Pencarian Azure AI. Dengan artikel ini, kami berharap Anda lebih memahami potensi penyebab dan solusi untuk mengatasi masalah kueri umum.
Langkah berikutnya
Buat indeks sampel, coba kueri yang berbeda, dan tinjau hasilnya. Untuk petunjuknya, lihat Membuat dan mengkueri indeks di portal Azure.
Coba sintaks kueri lain dari bagian contoh Dokumen Pencarian atau dari sintaks kueri Sederhana di Penjelajah pencarian di portal Azure.
Tinjau profil penskoran jika Anda ingin menyesuaikan peringkat di aplikasi pencarian Anda.
Pelajari cara menerapkan penganalisis leksikal spesifik bahasa.
Konfigurasikan penganalisis kustom untuk pemrosesan minimal atau pemrosesan khusus pada bidang tertentu.