Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Pencarian Azure AI mendukung dua metode dasar untuk mengimpor data ke dalam indeks pencarian: mendorong data Anda ke indeks secara terprogram atau menarik data Anda dengan mengarahkan pengindeks ke sumber data yang didukung.
Tutorial ini menjelaskan cara mengindeks data secara efisien menggunakan model push dengan membuat permintaan dalam batch dan menggunakan strategi coba kembali dengan backoff eksponensial. Anda dapat mengunduh dan menjalankan aplikasi sampel. Tutorial ini juga menjelaskan aspek utama aplikasi dan faktor apa yang perlu dipertimbangkan saat mengindeks data.
Dalam tutorial ini, Anda menggunakan C# dan pustaka Azure.Search.Documents dari Azure SDK untuk .NET untuk:
- Buat indeks
- Uji berbagai ukuran batch untuk menentukan ukuran yang paling efisien
- Mengindeks batch dengan asinkron
- Gunakan beberapa utas untuk meningkatkan kecepatan pengindeksan
- Gunakan strategi mundur eksponensial untuk mengulang dokumen yang gagal
Prasyarat
- Akun Azure dengan langganan aktif. Buat akun secara gratis.
- Visual Studio.
Mengunduh file
Kode sumber untuk tutorial ini berada di folder optimize-data-indexing/v11 di repositori GitHub Azure-Samples/azure-search-dotnet-scale .
Pertimbangan utama
Faktor-faktor berikut memengaruhi kecepatan pengindeksan. Untuk informasi selengkapnya, lihat Mengindeks himpunan data besar.
- Tingkat harga dan jumlah partisi/replika: Menambahkan partisi atau meningkatkan tingkat Anda meningkatkan kecepatan pengindeksan.
- Kompleksitas skema indeks: Menambahkan properti bidang dan bidang menurunkan kecepatan pengindeksan. Indeks yang lebih kecil lebih cepat untuk diindeks.
- Ukuran batch: Ukuran batch optimal bervariasi berdasarkan skema indeks dan himpunan data Anda.
- Jumlah utas/pekerja: Satu utas tidak memanfaatkan kecepatan pengindeksan sepenuhnya.
- Strategi mencoba ulang: Penggunaan strategi mencoba ulang dengan penundaan eksponensial merupakan praktik terbaik untuk pengindeksan yang optimal.
- Kecepatan transfer data jaringan: Kecepatan transfer data dapat menjadi faktor pembatas. Indeks data dari dalam lingkungan Azure Anda untuk meningkatkan kecepatan transfer data.
Membuat layanan pencarian baru
Tutorial ini memerlukan layanan Pencarian Azure AI, yang dapat Anda buat di portal Microsoft Azure. Anda juga dapat menemukan layanan yang sudah ada di langganan Anda saat ini. Untuk menguji dan mengoptimalkan kecepatan pengindeksan secara akurat, sebaiknya gunakan tingkat harga yang sama yang Anda rencanakan untuk digunakan dalam produksi.
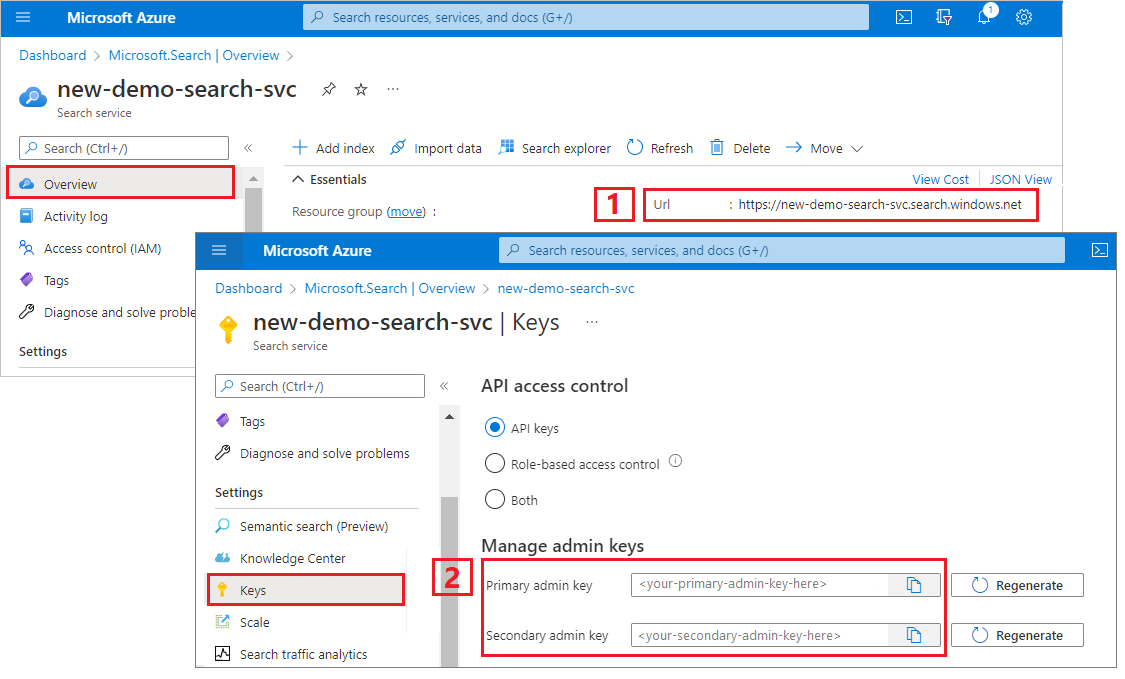
Mendapatkan kunci admin dan URL untuk Pencarian Azure AI
Tutorial ini menggunakan autentikasi berbasis kunci. Salin kunci API admin untuk ditempelkan ke appsettings.json dalam file.
Buka layanan pencarian Anda di portal Microsoft Azure.
Dari panel kiri, pilih Gambaran Umum dan salin titik akhir. Harus dalam format ini:
https://my-service.search.windows.netDari panel kiri, pilihKunci> dan salin kunci admin untuk hak penuh pada layanan. Ada dua kunci admin yang dapat dipertukarkan, disediakan untuk menjaga kelangsungan bisnis jika Anda perlu mengganti salah satunya. Anda dapat menggunakan kunci pada permintaan untuk menambahkan, mengubah, atau menghapus objek.
Atur lingkungan Anda
Buka file
OptimizeDataIndexing.slndi Visual Studio.Di Penjelajah Solusi, edit
appsettings.jsonfile dengan informasi koneksi yang Anda kumpulkan di langkah sebelumnya.{ "SearchServiceUri": "https://{service-name}.search.windows.net", "SearchServiceAdminApiKey": "", "SearchIndexName": "optimize-indexing" }
Menjelajahi kode
Setelah Anda memperbarui appsettings.json, program sampel di OptimizeDataIndexing.sln harus siap untuk membangun dan menjalankan.
Kode ini berasal dari bagian C# dari Mulai Cepat: Pencarian teks lengkap, yang menyediakan informasi terperinci tentang dasar-dasar bekerja dengan .NET SDK.
Aplikasi konsol C#/.NET sederhana ini melakukan tugas-tugas berikut:
- Membuat indeks baru berdasarkan struktur data kelas C#
Hotel(yang juga mereferensikanAddresskelas) - Menguji berbagai ukuran batch untuk menentukan ukuran yang paling efisien
- Mengindeks data secara asinkron
- Menggunakan beberapa utas untuk meningkatkan kecepatan pengindeksan
- Menggunakan strategi percobaan ulang backoff eksponensial untuk mencoba kembali item yang gagal
Sebelum Anda menjalankan program, luangkan waktu satu menit untuk mempelajari kode dan definisi indeks untuk sampel ini. Kode yang relevan ada di beberapa file:
-
Hotel.csdanAddress.csberisi skema yang menentukan indeks -
DataGenerator.csberisi kelas sederhana untuk memudahkan pembuatan data hotel dalam jumlah besar -
ExponentialBackoff.csberisi kode untuk mengoptimalkan proses pengindeksan seperti yang dijelaskan dalam artikel ini -
Program.csberisi fungsi yang membuat dan menghapus indeks Pencarian Azure AI, mengindeks batch data, dan menguji ukuran batch yang berbeda
Membuat indeks
Program sampel ini menggunakan Azure SDK untuk .NET untuk menentukan dan membuat indeks Pencarian Azure AI. Ini memanfaatkan kelas FieldBuilder untuk menghasilkan struktur indeks dari kelas model data C#.
Model data didefinisikan oleh Hotel kelas , yang juga berisi referensi ke Address kelas .
FieldBuilder menelusuri beberapa definisi kelas untuk menghasilkan struktur data yang kompleks untuk indeks. Tag metadata digunakan untuk menentukan atribut setiap bidang, seperti apakah tag dapat dicari atau dapat diurutkan.
Cuplikan berikut dari Hotel.cs file menentukan satu bidang dan referensi ke kelas model data lain.
. . .
[SearchableField(IsSortable = true)]
public string HotelName { get; set; }
. . .
public Address Address { get; set; }
. . .
Dalam file Program.cs, indeks didefinisikan dengan nama dan koleksi bidang yang dihasilkan oleh metode FieldBuilder.Build(typeof(Hotel)), lalu dibuat sebagai berikut:
private static async Task CreateIndexAsync(string indexName, SearchIndexClient indexClient)
{
// Create a new search index structure that matches the properties of the Hotel class.
// The Address class is referenced from the Hotel class. The FieldBuilder
// will enumerate these to create a complex data structure for the index.
FieldBuilder builder = new FieldBuilder();
var definition = new SearchIndex(indexName, builder.Build(typeof(Hotel)));
await indexClient.CreateIndexAsync(definition);
}
Menghasilkan data
Kelas sederhana diimplementasikan dalam DataGenerator.cs file untuk menghasilkan data untuk pengujian. Tujuan dari kelas ini adalah untuk memudahkan pembuatan sejumlah besar dokumen dengan ID unik untuk pengindeksan.
Untuk mendapatkan daftar 100.000 hotel dengan ID unik, jalankan kode berikut:
long numDocuments = 100000;
DataGenerator dg = new DataGenerator();
List<Hotel> hotels = dg.GetHotels(numDocuments, "large");
Ada dua ukuran hotel yang tersedia untuk pengujian dalam sampel ini: kecil dan besar.
Skema indeks Anda memengaruhi kecepatan pengindeksan. Setelah Anda menyelesaikan tutorial ini, pertimbangkan untuk mengonversi kelas ini untuk menghasilkan data yang paling sesuai dengan skema indeks yang Anda maksudkan.
Menguji ukuran batch
Untuk memuat satu atau beberapa dokumen ke dalam indeks, Pencarian Azure AI mendukung API berikut:
Mengindeks dokumen dalam batch secara signifikan meningkatkan performa pengindeksan. Batch ini dapat mencapai 1.000 dokumen atau hingga sekitar 16 MB per batch.
Menentukan ukuran batch optimal untuk data Anda adalah komponen kunci untuk mengoptimalkan kecepatan pengindeksan. Dua faktor utama yang memengaruhi ukuran batch yang optimal adalah:
- Skema indeks Anda
- Ukuran data Anda
Karena ukuran batch optimal tergantung pada indeks dan data Anda, pendekatan terbaik adalah menguji ukuran batch yang berbeda untuk menentukan hasil apa dalam kecepatan pengindeksan tercepat untuk skenario Anda.
Fungsi berikut menunjukkan pendekatan sederhana untuk menguji ukuran batch.
public static async Task TestBatchSizesAsync(SearchClient searchClient, int min = 100, int max = 1000, int step = 100, int numTries = 3)
{
DataGenerator dg = new DataGenerator();
Console.WriteLine("Batch Size \t Size in MB \t MB / Doc \t Time (ms) \t MB / Second");
for (int numDocs = min; numDocs <= max; numDocs += step)
{
List<TimeSpan> durations = new List<TimeSpan>();
double sizeInMb = 0.0;
for (int x = 0; x < numTries; x++)
{
List<Hotel> hotels = dg.GetHotels(numDocs, "large");
DateTime startTime = DateTime.Now;
await UploadDocumentsAsync(searchClient, hotels).ConfigureAwait(false);
DateTime endTime = DateTime.Now;
durations.Add(endTime - startTime);
sizeInMb = EstimateObjectSize(hotels);
}
var avgDuration = durations.Average(timeSpan => timeSpan.TotalMilliseconds);
var avgDurationInSeconds = avgDuration / 1000;
var mbPerSecond = sizeInMb / avgDurationInSeconds;
Console.WriteLine("{0} \t\t {1} \t\t {2} \t\t {3} \t {4}", numDocs, Math.Round(sizeInMb, 3), Math.Round(sizeInMb / numDocs, 3), Math.Round(avgDuration, 3), Math.Round(mbPerSecond, 3));
// Pausing 2 seconds to let the search service catch its breath
Thread.Sleep(2000);
}
Console.WriteLine();
}
Karena tidak semua dokumen berukuran sama (meskipun dalam sampel ini), kita memerkirakan ukuran data yang kita kirim ke layanan pencarian. Anda dapat melakukan ini dengan menggunakan fungsi berikut yang terlebih dahulu mengonversi objek ke JSON lalu menentukan ukurannya dalam byte. Teknik ini memungkinkan kita untuk menentukan ukuran batch mana yang paling efisien dalam hal kecepatan pengindeksan MB/dtk.
// Returns size of object in MB
public static double EstimateObjectSize(object data)
{
// converting object to byte[] to determine the size of the data
BinaryFormatter bf = new BinaryFormatter();
MemoryStream ms = new MemoryStream();
byte[] Array;
// converting data to json for more accurate sizing
var json = JsonSerializer.Serialize(data);
bf.Serialize(ms, json);
Array = ms.ToArray();
// converting from bytes to megabytes
double sizeInMb = (double)Array.Length / 1000000;
return sizeInMb;
}
Fungsi ini memerlukan SearchClient dan jumlah percobaan yang ingin Anda uji untuk setiap ukuran batch. Karena mungkin ada varianbilitas dalam waktu pengindeksan untuk setiap batch, coba setiap batch tiga kali secara default untuk membuat hasilnya lebih signifikan secara statistik.
await TestBatchSizesAsync(searchClient, numTries: 3);
Saat menjalankan fungsi, Anda akan melihat output di konsol yang mirip dengan contoh berikut:
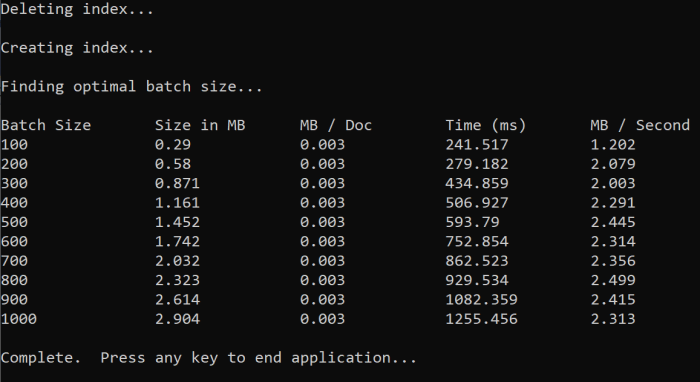
Identifikasi ukuran batch mana yang paling efisien dan gunakan ukuran batch tersebut di langkah berikutnya dari tutorial ini. Anda mungkin melihat kesetaraan dalam MB/dtk di berbagai ukuran kelompok.
Mengindeks data
Sekarang setelah Anda mengidentifikasi ukuran batch yang ingin Anda gunakan, langkah selanjutnya adalah mulai mengindeks data. Untuk mengindeks data secara efisien, sampel ini:
- Menggunakan beberapa utas/pekerja
- Menerapkan strategi penundaan ulang eksponensial
Batalkan komentar baris 41 hingga 49, lalu jalankan ulang program. Pada proses ini, sampel menghasilkan dan mengirim batch dokumen, hingga 100.000 jika Anda menjalankan kode tanpa mengubah parameter.
Menggunakan beberapa utas/pekerja
Untuk memanfaatkan kecepatan pengindeksan Pencarian Azure AI, gunakan beberapa utas untuk mengirim permintaan pengindeksan batch secara bersamaan ke layanan.
Beberapa pertimbangan utama dapat memengaruhi jumlah utas yang optimal. Anda dapat memodifikasi sampel ini, dan menguji dengan jumlah utas yang berbeda untuk menentukan jumlah utas optimal untuk skenario Anda. Namun, selama Anda memiliki beberapa utas yang berjalan bersamaan, Anda seharusnya dapat memanfaatkan sebagian besar perolehan efisiensi.
Saat Anda meningkatkan permintaan yang mencapai layanan pencarian, Anda mungkin menemukan kode status HTTP yang menunjukkan permintaan tidak sepenuhnya berhasil. Selama pengindeksan, dua kode status HTTP umum adalah:
- 503 Layanan Tidak Tersedia: Kesalahan ini berarti bahwa sistem berada di bawah beban berat dan permintaan Anda tidak dapat diproses saat ini.
- 207 Multi-Status: Kesalahan ini berarti bahwa beberapa dokumen berhasil, tetapi setidaknya satu gagal.
Menerapkan strategi pengulangan dengan penundaan eksponensial
Jika kegagalan terjadi, Anda harus mencoba ulang permintaan dengan menggunakan strategi mundur eksponensial.
.NET SDK Pencarian Azure AI secara otomatis mencoba kembali 503 dan permintaan lain yang gagal, tetapi Anda harus menerapkan logika Anda sendiri untuk mencoba kembali 207s. Alat sumber terbuka seperti Polly dapat berguna dalam strategi coba lagi.
Dalam sampel ini, kita menerapkan strategi percobaan ulang backoff eksponensial sendiri. Kita mulai dengan menentukan beberapa variabel, termasuk maxRetryAttempts dan awal delay untuk permintaan yang gagal.
// Create batch of documents for indexing
var batch = IndexDocumentsBatch.Upload(hotels);
// Create an object to hold the result
IndexDocumentsResult result = null;
// Define parameters for exponential backoff
int attempts = 0;
TimeSpan delay = delay = TimeSpan.FromSeconds(2);
int maxRetryAttempts = 5;
Hasil operasi pengindeksan disimpan dalam variabel IndexDocumentResult result. Variabel ini memungkinkan Anda untuk memeriksa apakah dokumen dalam batch gagal, seperti yang ditunjukkan dalam contoh berikut. Jika ada kegagalan parsial, batch baru dibuat berdasarkan ID dokumen yang gagal.
RequestFailedException pengecualian juga harus diperhatikan, karena menunjukkan permintaan gagal sepenuhnya, dan harus dicoba kembali.
// Implement exponential backoff
do
{
try
{
attempts++;
result = await searchClient.IndexDocumentsAsync(batch).ConfigureAwait(false);
var failedDocuments = result.Results.Where(r => r.Succeeded != true).ToList();
// handle partial failure
if (failedDocuments.Count > 0)
{
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
else
{
Console.WriteLine("[Batch starting at doc {0} had partial failure]", id);
Console.WriteLine("[Retrying {0} failed documents] \n", failedDocuments.Count);
// creating a batch of failed documents to retry
var failedDocumentKeys = failedDocuments.Select(doc => doc.Key).ToList();
hotels = hotels.Where(h => failedDocumentKeys.Contains(h.HotelId)).ToList();
batch = IndexDocumentsBatch.Upload(hotels);
Task.Delay(delay).Wait();
delay = delay * 2;
continue;
}
}
return result;
}
catch (RequestFailedException ex)
{
Console.WriteLine("[Batch starting at doc {0} failed]", id);
Console.WriteLine("[Retrying entire batch] \n");
if (attempts == maxRetryAttempts)
{
Console.WriteLine("[MAX RETRIES HIT] - Giving up on the batch starting at {0}", id);
break;
}
Task.Delay(delay).Wait();
delay = delay * 2;
}
} while (true);
Dari sini, bungkus kode backoff eksponensial ke dalam fungsi sehingga dapat dengan mudah dipanggil.
Fungsi lain kemudian dibuat untuk mengelola utas aktif. Untuk kesederhanaan, fungsi itu tidak termasuk di sini tetapi dapat ditemukan di ExponentialBackoff.cs. Anda dapat memanggil fungsi menggunakan perintah berikut, di mana hotels adalah data yang ingin kita unggah, 1000 adalah ukuran batch, dan 8 adalah jumlah utas yang berjalan secara bersamaan.
await ExponentialBackoff.IndexData(indexClient, hotels, 1000, 8);
Saat menjalankan fungsi, Anda akan melihat output yang mirip dengan contoh berikut:
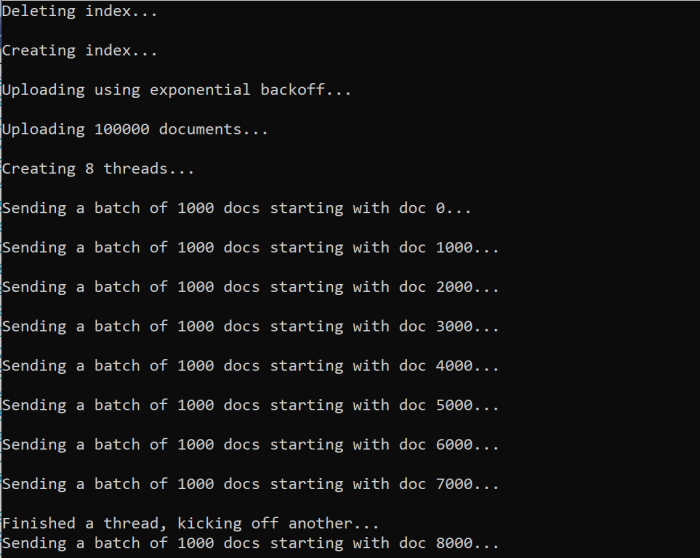
Ketika batch dokumen gagal, terjadi kesalahan yang tercetak menunjukkan kegagalan tersebut dan bahwa batch sedang diproses ulang.
[Batch starting at doc 6000 had partial failure]
[Retrying 560 failed documents]
Setelah fungsi selesai berjalan, Anda dapat memverifikasi bahwa semua dokumen ditambahkan ke indeks.
Jelajahi indeks
Setelah program selesai berjalan, Anda dapat menjelajahi indeks pencarian yang diisi baik secara terprogram atau menggunakan Penjelajah pencarian di portal Microsoft Azure.
Secara terprogram
Ada dua opsi utama untuk memeriksa jumlah dokumen dalam indeks: API Hitung Dokumen dan API Dapatkan Statistik Indeks. Kedua jalur memerlukan waktu untuk diproses, jadi jangan khawatir jika jumlah dokumen yang dikembalikan awalnya lebih rendah dari yang Anda harapkan.
Hitung Dokumen
Operasi Hitung Dokumen mengambil hitungan jumlah dokumen dalam indeks pencarian.
long indexDocCount = await searchClient.GetDocumentCountAsync();
Dapatkan Statistik Indeks
Operasi Dapatkan Statistik Indeks mengembalikan jumlah dokumen untuk indeks saat ini, ditambah penggunaan penyimpanan. Statistik indeks membutuhkan waktu lebih lama untuk diperbarui daripada jumlah dokumen.
var indexStats = await indexClient.GetIndexStatisticsAsync(indexName);
portal Azure
Di Azure portal, dari bilah kiri, temukan indeks optimize-indexing di daftar Indeks.

Jumlah Dokumen dan Ukuran Penyimpanan didasarkan pada Get Index Statistics API dan dapat memakan waktu beberapa menit untuk diperbarui.
Atur ulang dan jalankan ulang
Pada tahap pengembangan eksperimental awal, pendekatan paling praktis untuk iterasi desain adalah menghapus objek dari Pencarian Azure AI dan memungkinkan kode Anda untuk membangunnya kembali. Nama sumber daya bersifat unik. Menghapus objek memungkinkan Anda membuatnya kembali menggunakan nama yang sama.
Kode sampel untuk tutorial ini memeriksa indeks yang ada dan menghapusnya sehingga Anda dapat menjalankan ulang kode Anda.
Anda juga dapat menggunakan portal Azure untuk menghapus indeks.
Membersihkan sumber daya
Saat Anda bekerja di langganan Anda sendiri, di akhir proyek, sebaiknya hapus sumber daya yang tidak lagi Anda butuhkan. Sumber daya yang dibiarkan berjalan dapat menghabiskan uang Anda. Anda dapat menghapus sumber daya satu per satu atau menghapus grup sumber daya untuk menghapus seluruh rangkaian sumber daya.
Anda dapat menemukan dan mengelola sumber daya di portal Azure, menggunakan tautan Semua sumber daya atau Grup sumber daya di panel navigasi kiri.
Langkah selanjutnya
Untuk mempelajari selengkapnya tentang mengindeks data dalam jumlah besar, coba tutorial berikut: