Tutorial: Mengindeks data besar dari Apache Spark menggunakan SynapseML dan Azure AI Search
Dalam tutorial Pencarian Azure AI ini, pelajari cara mengindeks dan mengkueri data besar yang dimuat dari kluster Spark. Siapkan Jupyter Notebook yang melakukan tindakan berikut:
- Memuat berbagai formulir (faktur) ke dalam bingkai data dalam sesi Apache Spark
- Menganalisisnya untuk menentukan fitur mereka
- Merakit output yang dihasilkan ke dalam struktur data tabular
- Menulis output ke indeks pencarian yang dihosting di Azure AI Search
- Menjelajahi dan mengkueri konten yang Anda buat
Tutorial ini mengambil dependensi pada SynapseML, pustaka sumber terbuka yang mendukung pembelajaran mesin paralel secara besar-besaran melalui big data. Di SynapseML, pengindeksan pencarian dan pembelajaran mesin diekspos melalui transformator yang melakukan tugas khusus. Transformer memanfaatkan berbagai kemampuan AI. Dalam latihan ini, gunakan API AzureSearchWriter untuk analisis dan pengayaan AI.
Meskipun Azure AI Search memiliki pengayaan AI asli, tutorial ini menunjukkan kepada Anda cara mengakses kemampuan AI di luar Azure AI Search. Dengan menggunakan SynapseML alih-alih pengindeks atau keterampilan, Anda tidak tunduk pada batas data atau batasan lain yang terkait dengan objek tersebut.
Tip
Tonton video singkat demo ini di https://www.youtube.com/watch?v=iXnBLwp7f88. Video diperluas pada tutorial ini dengan lebih banyak langkah dan visual.
Prasyarat
Anda memerlukan synapseml pustaka dan beberapa sumber daya Azure. Jika memungkinkan, gunakan langganan dan wilayah yang sama untuk sumber daya Azure Anda dan masukkan semuanya ke dalam satu grup sumber daya untuk pembersihan sederhana nanti. Tautan berikut adalah untuk penginstalan portal. Data sampel diimpor dari situs publik.
- PaketSynapseML 1
- Pencarian Azure AI (tingkat apa pun) 2
- Layanan Azure AI (tingkat apa pun) 3
- Azure Databricks (tingkat apa pun) 4
1 Tautan ini menyelesaikan tutorial untuk memuat paket.
2 Anda dapat menggunakan tingkat pencarian gratis untuk mengindeks data sampel, tetapi memilih tingkat yang lebih tinggi jika volume data Anda besar. Untuk tingkat yang dapat ditagih, berikan kunci API pencarian di langkah Siapkan dependensi lebih lanjut.
3 Tutorial ini menggunakan Azure AI Document Intelligence dan Azure AI Penerjemah. Dalam instruksi berikut, berikan kunci multi-layanan dan wilayah . Kunci yang sama berfungsi untuk kedua layanan.
4 Dalam tutorial ini, Azure Databricks menyediakan platform komputasi Spark. Kami menggunakan instruksi portal untuk menyiapkan ruang kerja.
Catatan
Semua sumber daya Azure di atas mendukung fitur keamanan di platform Identitas Microsoft. Untuk kesederhanaan, tutorial ini mengasumsikan autentikasi berbasis kunci, menggunakan titik akhir dan kunci yang disalin dari halaman portal setiap layanan. Jika Anda menerapkan alur kerja ini di lingkungan produksi, atau berbagi solusi dengan orang lain, ingatlah untuk mengganti kunci yang dikodekan secara permanen dengan keamanan terintegrasi atau kunci terenkripsi.
Langkah 1: Membuat kluster dan notebook Spark
Di bagian ini, buat kluster, instal synapseml pustaka, dan buat buku catatan untuk menjalankan kode.
Di portal Azure, temukan ruang kerja Azure Databricks Anda dan pilih Luncurkan ruang kerja.
Di menu sebelah kiri, pilih Komputasi.
Pilih Buat komputasi.
Terima konfigurasi default. Dibutuhkan beberapa menit untuk membuat kluster.
synapsemlInstal pustaka setelah kluster dibuat:Pilih Pustaka dari tab di bagian atas halaman kluster.
Pilih Instal baru.
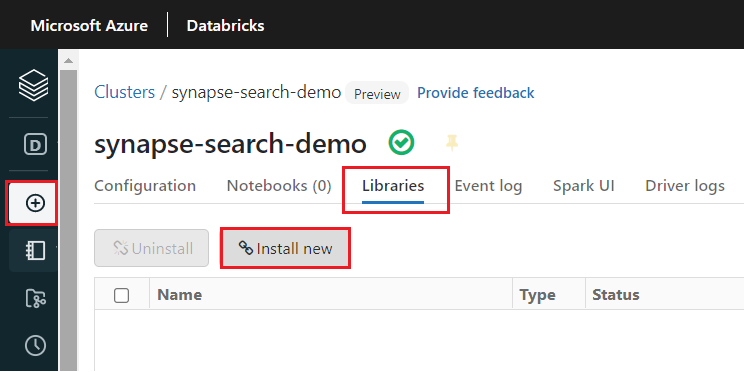
Pilih Maven.
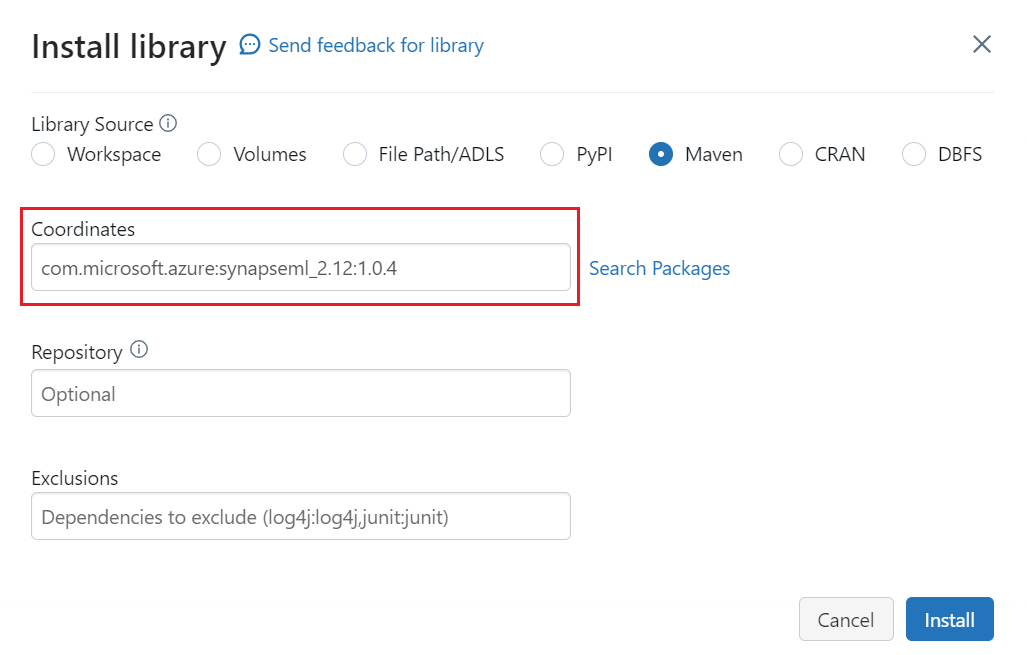
Di Koordinat, masukkan
com.microsoft.azure:synapseml_2.12:1.0.4Pilih Instal.
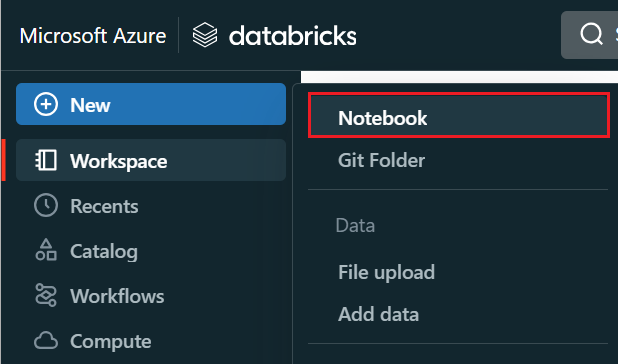
Di menu sebelah kiri, pilih Buat>Buku Catatan.
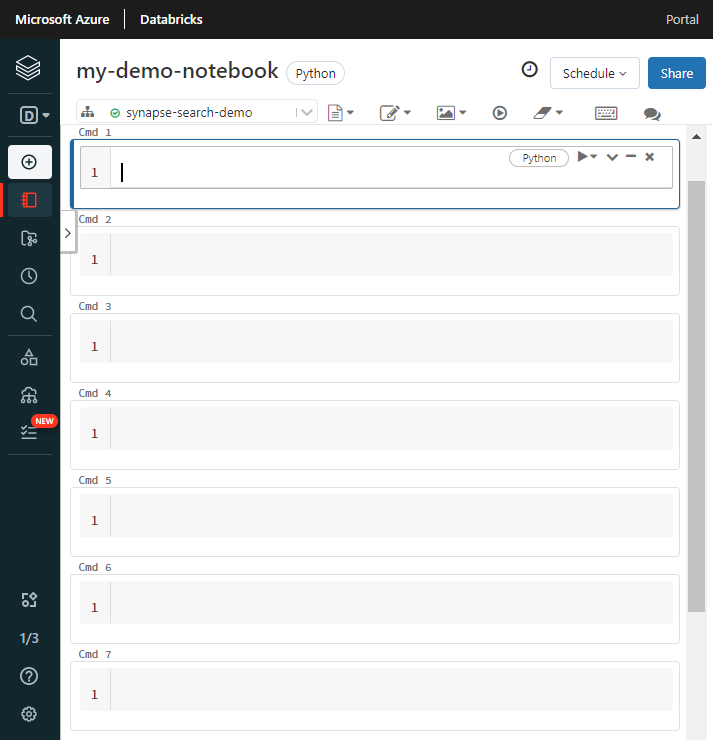
Beri nama buku catatan, pilih Python sebagai bahasa default, dan pilih kluster yang memiliki
synapsemlpustaka.Buat tujuh sel berturut-turut. Tempelkan kode ke dalam masing-masing kode.
Langkah 2: Menyiapkan dependensi
Tempelkan kode berikut ke sel pertama buku catatan Anda.
Ganti tempat penampung dengan titik akhir dan kunci akses untuk setiap sumber daya. Berikan nama untuk indeks pencarian baru. Tidak diperlukan modifikasi lain, jadi jalankan kode saat Anda siap.
Kode ini mengimpor beberapa paket dan menyiapkan akses ke sumber daya Azure yang digunakan dalam alur kerja ini.
import os
from pyspark.sql.functions import udf, trim, split, explode, col, monotonically_increasing_id, lit
from pyspark.sql.types import StringType
from synapse.ml.core.spark import FluentAPI
cognitive_services_key = "placeholder-cognitive-services-multi-service-key"
cognitive_services_region = "placeholder-cognitive-services-region"
search_service = "placeholder-search-service-name"
search_key = "placeholder-search-service-api-key"
search_index = "placeholder-search-index-name"
Langkah 3: Memuat data ke Spark
Tempelkan kode berikut ke sel kedua. Tidak diperlukan modifikasi, jadi jalankan kode saat Anda siap.
Kode ini memuat beberapa file eksternal dari akun penyimpanan Azure. File adalah berbagai faktur, dan dibaca ke dalam bingkai data.
def blob_to_url(blob):
[prefix, postfix] = blob.split("@")
container = prefix.split("/")[-1]
split_postfix = postfix.split("/")
account = split_postfix[0]
filepath = "/".join(split_postfix[1:])
return "https://{}/{}/{}".format(account, container, filepath)
df2 = (spark.read.format("binaryFile")
.load("wasbs://ignite2021@mmlsparkdemo.blob.core.windows.net/form_subset/*")
.select("path")
.limit(10)
.select(udf(blob_to_url, StringType())("path").alias("url"))
.cache())
display(df2)
Langkah 4: Menambahkan kecerdasan dokumen
Tempelkan kode berikut ke sel ketiga. Tidak diperlukan modifikasi, jadi jalankan kode saat Anda siap.
Kode ini memuat transformator AnalyzeInvoices dan meneruskan referensi ke bingkai data yang berisi faktur. Ini memanggil model faktur bawaan Azure AI Document Intelligence untuk mengekstrak informasi dari faktur.
from synapse.ml.cognitive import AnalyzeInvoices
analyzed_df = (AnalyzeInvoices()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setImageUrlCol("url")
.setOutputCol("invoices")
.setErrorCol("errors")
.setConcurrency(5)
.transform(df2)
.cache())
display(analyzed_df)
Output dari langkah ini akan terlihat mirip dengan cuplikan layar berikutnya. Perhatikan bagaimana analisis formulir dikemas ke dalam kolom terstruktur padat, yang sulit untuk dikerjakan. Transformasi berikutnya menyelesaikan masalah ini dengan mengurai kolom menjadi baris dan kolom.
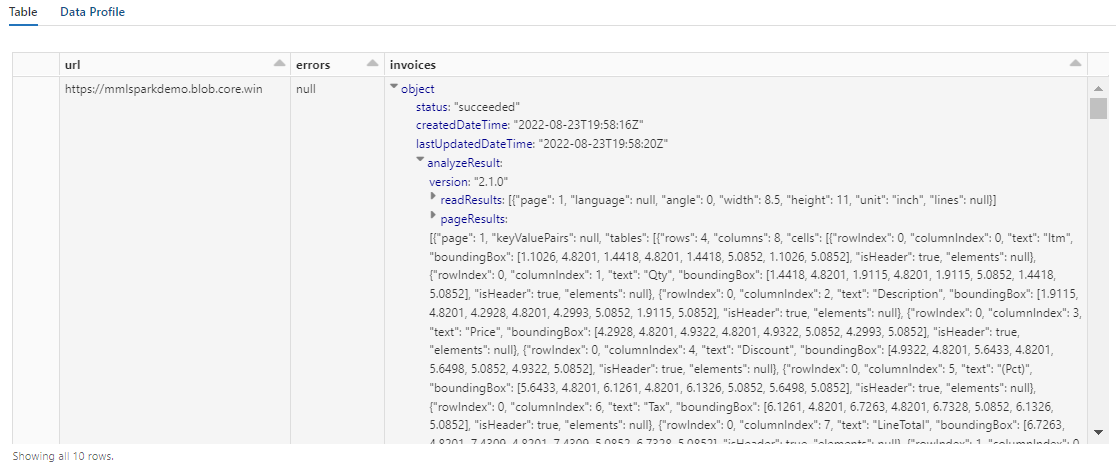
Langkah 5: Restrukturisasi output kecerdasan dokumen
Tempelkan kode berikut ke sel keempat dan jalankan. Tidak diperlukan modifikasi.
Kode ini memuat FormOntologyLearner, transformator yang menganalisis output transformator Kecerdasan Dokumen dan menyimpulkan struktur data tabular. Output AnalyzeInvoices bersifat dinamis dan bervariasi berdasarkan fitur yang terdeteksi dalam konten Anda. Selain itu, transformator mengonsolidasikan output ke dalam satu kolom. Karena outputnya dinamis dan terkonsolidasi, sulit untuk digunakan dalam transformasi hilir yang membutuhkan lebih banyak struktur.
FormOntologyLearner memperluas utilitas transformator AnalyzeInvoices dengan mencari pola yang dapat digunakan untuk membuat struktur data tabular. Mengatur output menjadi beberapa kolom dan baris membuat konten dapat dikonsumsi di transformer lain, seperti AzureSearchWriter.
from synapse.ml.cognitive import FormOntologyLearner
itemized_df = (FormOntologyLearner()
.setInputCol("invoices")
.setOutputCol("extracted")
.fit(analyzed_df)
.transform(analyzed_df)
.select("url", "extracted.*").select("*", explode(col("Items")).alias("Item"))
.drop("Items").select("Item.*", "*").drop("Item"))
display(itemized_df)
Perhatikan bagaimana transformasi ini memprakirakan ulang bidang berlapis ke dalam tabel, yang memungkinkan dua transformasi berikutnya. Cuplikan layar ini dipangkas untuk brevity. Jika Anda mengikuti di buku catatan Anda sendiri, Anda memiliki 19 kolom dan 26 baris.
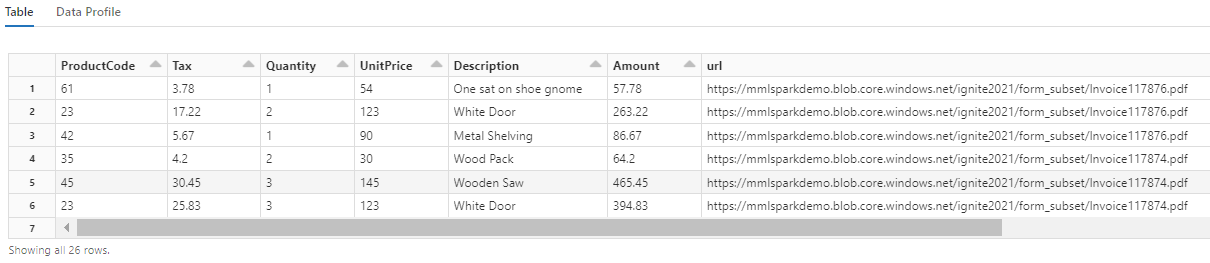
Langkah 6: Menambahkan terjemahan
Tempelkan kode berikut ke sel kelima. Tidak diperlukan modifikasi, jadi jalankan kode saat Anda siap.
Kode ini memuat Terjemahkan, transformator yang memanggil layanan azure AI Penerjemah di layanan Azure AI. Teks asli, yang dalam bahasa Inggris di kolom "Deskripsi", diterjemahkan ke dalam berbagai bahasa. Semua output dikonsolidasikan ke dalam array "output.translations".
from synapse.ml.cognitive import Translate
translated_df = (Translate()
.setSubscriptionKey(cognitive_services_key)
.setLocation(cognitive_services_region)
.setTextCol("Description")
.setErrorCol("TranslationError")
.setOutputCol("output")
.setToLanguage(["zh-Hans", "fr", "ru", "cy"])
.setConcurrency(5)
.transform(itemized_df)
.withColumn("Translations", col("output.translations")[0])
.drop("output", "TranslationError")
.cache())
display(translated_df)
Tip
Untuk memeriksa string yang diterjemahkan, gulir ke akhir baris.
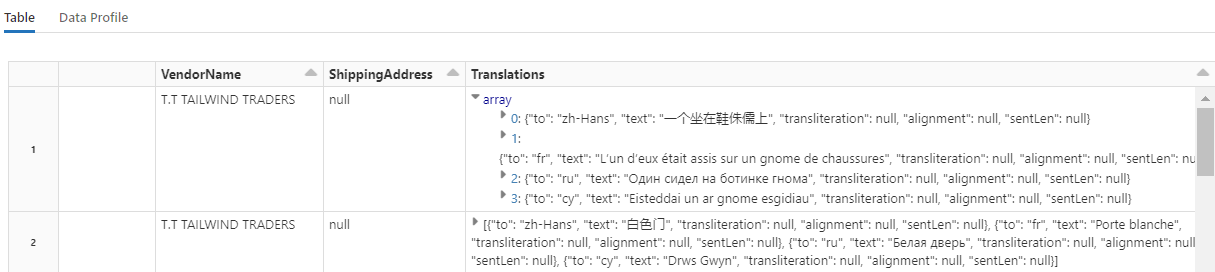
Langkah 7: Menambahkan indeks pencarian dengan AzureSearchWriter
Tempelkan kode berikut di sel keenam lalu jalankan. Tidak diperlukan modifikasi.
Kode ini memuat AzureSearchWriter. Ini menggunakan himpunan data tabular dan menyimpulkan skema indeks pencarian yang menentukan satu bidang untuk setiap kolom. Karena struktur terjemahan adalah array, struktur ini diartikulasikan dalam indeks sebagai koleksi kompleks dengan subbidang untuk setiap terjemahan bahasa. Indeks yang dihasilkan memiliki kunci dokumen dan menggunakan nilai default untuk bidang yang dibuat menggunakan Create Index REST API.
from synapse.ml.cognitive import *
(translated_df.withColumn("DocID", monotonically_increasing_id().cast("string"))
.withColumn("SearchAction", lit("upload"))
.writeToAzureSearch(
subscriptionKey=search_key,
actionCol="SearchAction",
serviceName=search_service,
indexName=search_index,
keyCol="DocID",
))
Anda dapat memeriksa halaman layanan pencarian di portal Azure untuk menjelajahi definisi indeks yang dibuat oleh AzureSearchWriter.
Catatan
Jika Anda tidak dapat menggunakan indeks pencarian default, Anda dapat memberikan definisi kustom eksternal di JSON, meneruskan URI-nya sebagai string di properti "indexJson". Buat indeks default terlebih dahulu sehingga Anda tahu bidang mana yang akan ditentukan, lalu ikuti dengan properti yang disesuaikan jika Anda memerlukan penganalisis tertentu, misalnya.
Langkah 8: Mengkueri indeks
Tempelkan kode berikut ke sel ketujuh lalu jalankan. Tidak diperlukan modifikasi, kecuali Anda mungkin ingin memvariasikan sintaks atau mencoba lebih banyak contoh untuk menjelajahi konten Anda lebih lanjut:
Tidak ada transformator atau modul yang mengeluarkan kueri. Sel ini adalah panggilan sederhana ke REST API Dokumen Pencarian.
Contoh khusus ini mencari kata "pintu" ("search": "door"). Ini juga mengembalikan "hitungan" dari jumlah dokumen yang cocok, dan hanya memilih konten bidang "Deskripsi' dan "Terjemahan" untuk hasilnya. Jika Anda ingin melihat daftar lengkap bidang, hapus parameter "pilih".
import requests
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2020-06-30".format(search_service, search_index)
requests.post(url, json={"search": "door", "count": "true", "select": "Description, Translations"}, headers={"api-key": search_key}).json()
Cuplikan layar berikut menunjukkan output sel untuk contoh skrip.
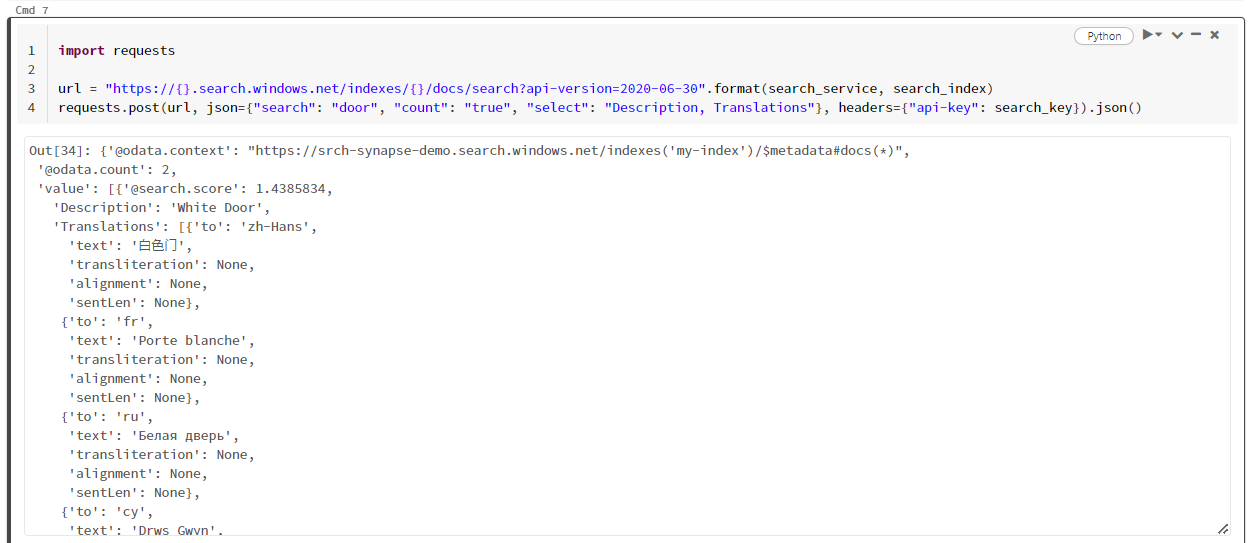
Membersihkan sumber daya
Saat Anda bekerja di langganan Anda sendiri, di akhir proyek, sebaiknya hapus sumber daya yang tidak lagi Anda butuhkan. Sumber daya yang dibiarkan berjalan dapat menghabiskan uang Anda. Anda dapat menghapus sumber daya satu per satu atau menghapus grup sumber daya untuk menghapus seluruh rangkaian sumber daya.
Anda dapat menemukan dan mengelola sumber daya di portal, menggunakan tautan Semua sumber daya atau Grup sumber daya di panel navigasi kiri.
Langkah berikutnya
Dalam tutorial ini, Anda mempelajari tentang transformator AzureSearchWriter di SynapseML, yang merupakan cara baru untuk membuat dan memuat indeks pencarian di Azure AI Search. Transformator mengambil JSON terstruktur sebagai input. FormOntologyLearner dapat menyediakan struktur yang diperlukan untuk output yang dihasilkan oleh transformator Kecerdasan Dokumen di SynapseML.
Sebagai langkah selanjutnya, tinjau tutorial SynapseML lainnya yang menghasilkan konten yang diubah yang mungkin ingin Anda jelajahi melalui Azure AI Search: