Ukuran indeks vektor dan tetap di bawah batas
Untuk setiap bidang vektor, Azure AI Search membuat indeks vektor internal menggunakan parameter algoritma yang ditentukan pada bidang . Karena Azure AI Search memberlakukan kuota pada ukuran indeks vektor, Anda harus tahu cara memperkirakan dan memantau ukuran vektor untuk memastikan Anda tetap di bawah batas.
Catatan
Catatan tentang terminologi. Secara internal, struktur data fisik indeks pencarian mencakup konten mentah (digunakan untuk pola pengambilan yang memerlukan konten yang tidak ditokenisasi), indeks terbalik (digunakan untuk bidang teks yang dapat dicari), dan indeks vektor (digunakan untuk bidang vektor yang dapat dicari). Artikel ini menjelaskan batasan untuk indeks vektor internal yang mendukung setiap bidang vektor Anda.
Tip
Kuantisasi vektor dan konfigurasi penyimpanan sekarang dalam pratinjau. Gunakan kemampuan seperti jenis data sempit, kuantisasi skalar, dan penghapusan penyimpanan redundan untuk tetap berada di bawah kuota vektor dan kuota penyimpanan.
Poin utama tentang ukuran indeks kuota dan vektor
Ukuran indeks vektor diukur dalam byte.
Kuota vektor didasarkan pada batasan memori. Semua indeks vektor yang dapat dicari harus dimuat ke dalam memori. Pada saat yang sama, juga harus ada memori yang cukup untuk operasi runtime lainnya. Kuota vektor ada untuk memastikan bahwa sistem keseluruhan tetap stabil dan seimbang untuk semua beban kerja.
Indeks vektor juga tunduk pada kuota disk, dalam arti semua indeks adalah kuota disk subjek. Tidak ada kuota disk terpisah untuk indeks vektor.
Kuota vektor diberlakukan pada layanan pencarian secara keseluruhan, per partisi, yang berarti bahwa jika Anda menambahkan partisi, kuota vektor naik. Kuota vektor per partisi lebih tinggi pada layanan yang lebih baru:
Cara memeriksa ukuran dan kuantitas partisi
Jika Anda tidak yakin apa batas layanan pencarian Anda, berikut adalah dua cara untuk mendapatkan informasi tersebut:
Di portal Azure, di halaman Gambaran Umum layanan pencarian, tab Properti dan tab Penggunaan memperlihatkan ukuran dan penyimpanan partisi, dan juga kuota vektor dan ukuran indeks vektor.
Di portal Azure, di halaman Skala, Anda dapat meninjau jumlah dan ukuran partisi.
Cara memeriksa tanggal pembuatan layanan
Layanan yang lebih baru yang dibuat setelah 3 April 2024 menawarkan penyimpanan vektor lima hingga sepuluh kali lebih banyak sebagai yang lebih lama pada tingkat penagihan tingkat yang sama. Jika layanan Anda lebih lama, pertimbangkan untuk membuat layanan baru dan memigrasikan konten Anda.
Di portal Azure, buka grup sumber daya yang berisi layanan pencarian Anda.
Di panel paling kiri, di bawah Pengaturan, pilih Penyebaran.
Temukan penyebaran layanan pencarian Anda. Jika ada banyak penyebaran, gunakan filter untuk mencari "pencarian".
Memilih penyebaran. Jika Anda memiliki lebih dari satu, klik untuk melihat apakah itu diselesaikan ke layanan pencarian Anda.
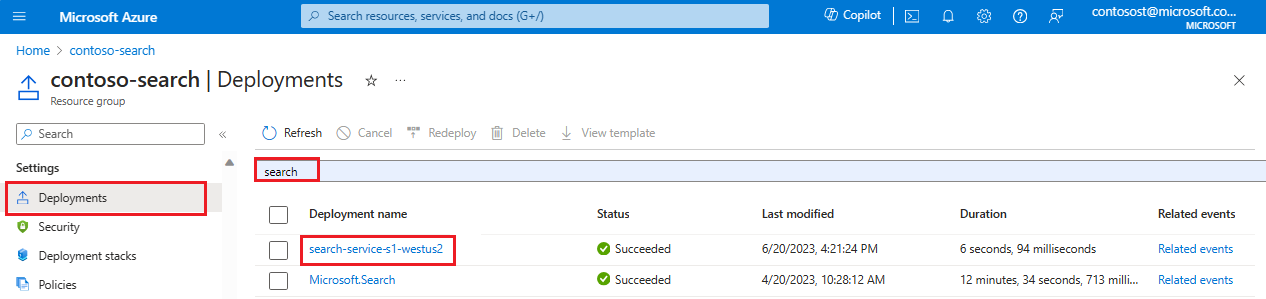
Luaskan detail penyebaran. Anda akan melihat Dibuat dan tanggal pembuatan.
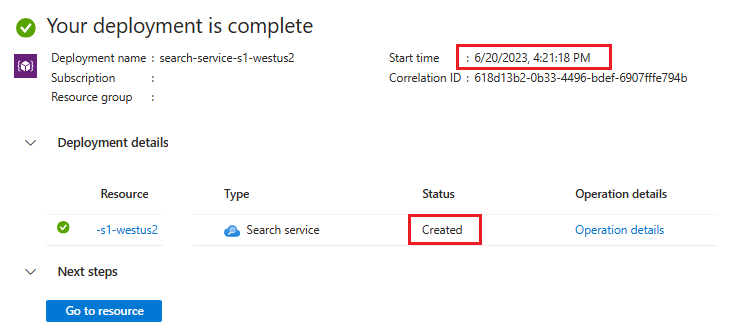
Sekarang setelah Anda mengetahui usia layanan pencarian Anda, tinjau batas kuota vektor berdasarkan pembuatan layanan:
Cara mendapatkan ukuran indeks vektor
Permintaan metrik vektor adalah operasi sarana data. Anda dapat menggunakan portal Azure, REST API, atau Azure SDK untuk mendapatkan penggunaan vektor di tingkat layanan melalui statistik layanan dan untuk indeks individual.
Informasi penggunaan dapat ditemukan di tab Penggunaan halaman Gambaran Umum. Halaman portal di-refresh setiap beberapa menit jadi jika Anda baru saja memperbarui indeks, tunggu sebentar sebelum memeriksa hasil.
Cuplikan layar berikut adalah untuk layanan pencarian Standar 1 (S1) yang lebih lama, dikonfigurasi untuk satu partisi dan satu replika.
- Kuota penyimpanan adalah batasan disk, dan termasuk semua indeks (vektor dan nonvektor) pada layanan pencarian.
- Kuota ukuran indeks vektor adalah batasan memori. Ini adalah jumlah memori yang diperlukan untuk memuat semua indeks vektor internal yang dibuat untuk setiap bidang vektor pada layanan pencarian.
Cuplikan layar menunjukkan bahwa indeks (vektor dan nonvektor) mengonsumsi hampir 460 megabyte penyimpanan disk yang tersedia. Indeks vektor mengonsumsi hampir 93 megabyte memori di tingkat layanan.

Kuota untuk penyimpanan dan ukuran indeks vektor meningkat atau berkurang saat Anda menambahkan atau menghapus partisi. Jika Anda mengubah jumlah partisi, petak peta menunjukkan perubahan yang sesuai dalam penyimpanan dan kuota vektor.
Catatan
Pada disk, indeks vektor tidak 93 megabyte. Indeks vektor pada disk memakan waktu sekitar tiga kali lebih banyak ruang daripada indeks vektor dalam memori. Lihat Bagaimana bidang vektor memengaruhi penyimpanan disk untuk detailnya.
Faktor-faktor yang memengaruhi ukuran indeks vektor
Ada tiga komponen utama yang memengaruhi ukuran indeks vektor internal Anda:
- Ukuran data mentah
- Overhead dari algoritma yang dipilih
- Overhead dari menghapus atau memperbarui dokumen dalam indeks
Ukuran data mentah
Setiap vektor biasanya merupakan array angka floating-point presisi tunggal, dalam bidang jenis Collection(Edm.Single).
Struktur data vektor memerlukan penyimpanan, yang diwakili dalam perhitungan berikut sebagai "ukuran mentah" data Anda. Gunakan ukuran mentah ini untuk memperkirakan persyaratan ukuran indeks vektor bidang vektor Anda.
Ukuran penyimpanan satu vektor ditentukan oleh dimensinya. Kalikan ukuran satu vektor dengan jumlah dokumen yang berisi bidang vektor tersebut untuk mendapatkan ukuran mentah:
raw size = (number of documents) * (dimensions of vector field) * (size of data type)
| Jenis data EDM | Ukuran tipe data |
|---|---|
Collection(Edm.Single) |
4 byte |
Collection(Edm.Half) |
2 byte |
Collection(Edm.Int16) |
2 byte |
Collection(Edm.SByte) |
1 byte |
Overhead memori dari algoritma yang dipilih
Setiap perkiraan algoritma tetangga terdekat (ANN) menghasilkan struktur data tambahan dalam memori untuk memungkinkan pencarian yang efisien. Struktur ini mengonsumsi ruang ekstra dalam memori.
Untuk algoritma HNSW, overhead memori berkisar antara 1% dan 20%.
Overhead memori lebih rendah untuk dimensi yang lebih tinggi karena ukuran mentah vektor meningkat, sementara struktur data tambahan tetap berukuran tetap karena menyimpan informasi pada konektivitas dalam grafik. Akibatnya, kontribusi struktur data tambahan merupakan bagian yang lebih kecil dari ukuran keseluruhan.
Overhead memori lebih tinggi untuk nilai yang lebih besar dari parameter mHNSW , yang menentukan jumlah tautan dua arah yang dibuat untuk setiap vektor baru selama konstruksi indeks. Ini karena m berkontribusi sekitar 8 byte hingga 10 byte per dokumen dikalikan dengan m.
Tabel berikut ini meringkas persentase overhead yang diamati dalam pengujian internal:
| Dimensi | Parameter HNSW (m) | Persentase Overhead |
|---|---|---|
| 96 | 4 | 20% |
| 200 | 4 | 8% |
| 768 | 4 | %2 |
| 1536 | 4 | %1 |
| 3072 | 4 | 0,5% |
Hasil ini menunjukkan hubungan antara dimensi, parameter mHNSW, dan overhead memori untuk algoritma HNSW.
Overhead dari menghapus atau memperbarui dokumen dalam indeks
Saat dokumen dengan bidang vektor dihapus atau diperbarui (pembaruan diwakili secara internal sebagai operasi hapus dan sisipkan), dokumen yang mendasarinya ditandai sebagai dihapus dan dilewati selama kueri berikutnya. Saat dokumen baru diindeks dan indeks vektor internal tumbuh, sistem membersihkan dokumen yang dihapus ini dan mengklaim kembali sumber daya. Ini berarti Anda kemungkinan akan mengamati jeda antara menghapus dokumen dan sumber daya yang mendasar yang dibeberkan.
Kami menyebutnya sebagai rasio dokumen yang dihapus. Karena rasio dokumen yang dihapus tergantung pada karakteristik pengindeksan layanan Anda, tidak ada heuristik universal untuk memperkirakan parameter ini, dan tidak ada API atau skrip yang mengembalikan rasio yang berlaku untuk layanan Anda. Kami mengamati bahwa setengah dari pelanggan kami memiliki rasio dokumen yang dihapus kurang dari 10%. Jika Anda cenderung melakukan penghapusan atau pembaruan frekuensi tinggi, maka Anda mungkin mengamati rasio dokumen yang dihapus lebih tinggi.
Ini adalah faktor lain yang memengaruhi ukuran indeks vektor Anda. Sayangnya, kami tidak memiliki mekanisme untuk memunculkan rasio dokumen Anda yang dihapus saat ini.
Memperkirakan ukuran total untuk data Anda dalam memori
Mempertimbangkan faktor-faktor yang dijelaskan sebelumnya, untuk memperkirakan ukuran total indeks vektor Anda, gunakan perhitungan berikut:
(raw_size) * (1 + algorithm_overhead (in percent)) * (1 + deleted_docs_ratio (in percent))
Misalnya, untuk menghitung raw_size, mari kita asumsikan Anda menggunakan model Azure OpenAI populer, text-embedding-ada-002 dengan 1.536 dimensi. Ini berarti satu dokumen akan mengonsumsi 1.536 Edm.Single (float), atau 6.144 byte karena masing-masing Edm.Single adalah 4 byte. 1.000 dokumen dengan bidang vektor 1.536 dimensi tunggal akan digunakan dalam total 1000 dokumen x 1536 float/doc = 1.536.000 float, atau 6.144.000 byte.
Jika Anda memiliki beberapa bidang vektor, Anda perlu melakukan perhitungan ini untuk setiap bidang vektor dalam indeks Anda dan menambahkan semuanya bersama-sama. Misalnya, 1.000 dokumen dengan dua bidang vektor 1.536 dimensi, mengonsumsi 1000 dokumen x 2 bidang x 1536 float/doc x 4 byte/float = 12.288.000 byte.
Untuk mendapatkan ukuran indeks vektor, kalikan raw_size ini dengan overhead algoritma dan rasio dokumen yang dihapus. Jika overhead algoritma Anda untuk parameter HNSW yang Anda pilih adalah 10% dan rasio dokumen Anda yang dihapus adalah 10%, maka kami mendapatkan: 6.144 MB * (1 + 0.10) * (1 + 0.10) = 7.434 MB.
Bagaimana bidang vektor memengaruhi penyimpanan disk
Sebagian besar artikel ini menyediakan informasi tentang ukuran vektor dalam memori. Jika Anda ingin tahu tentang ukuran vektor pada disk, konsumsi disk untuk data vektor kira-kira tiga kali ukuran indeks vektor dalam memori. Misalnya, jika penggunaan Anda vectorIndexSize berada di 100 megabyte (10 juta byte), Anda akan menggunakan setidaknya 300 megabyte storageSize kuota untuk mengakomodasi indeks vektor Anda.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk